别再给VLM硬上自动驾驶了!OpenDriveVLA用BEVFormer+四阶段训练,直接把VLA从2D“看图说话”拽回3D空间
点击下方卡片,关注“人工智能AI与算法”公众号
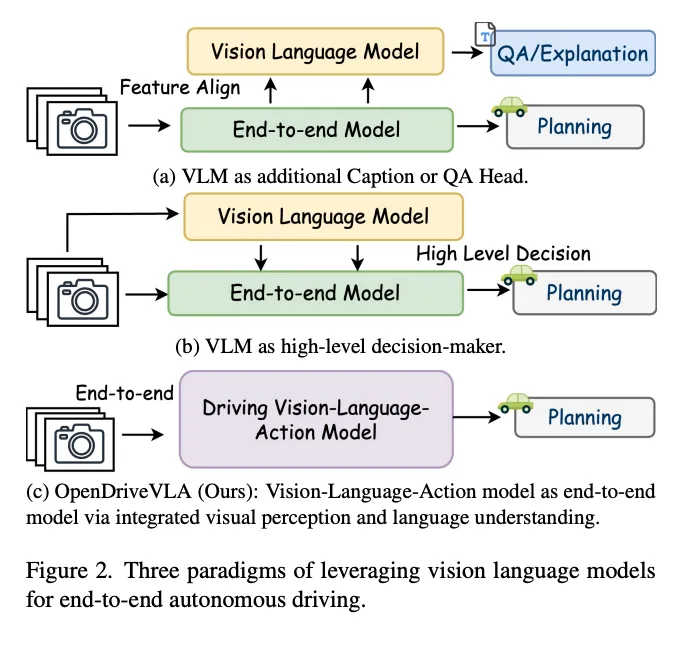
OpenDriveVLA是目前把VLA往车端落地方向拉得最正的一篇论文。
现在自动驾驶圈的VLA研究,很多都是在给车装一个“会看图的聊天模型”——告诉它“你看到什么了”,模型能答出来,然后就没有然后了。但OpenDriveVLA这篇论文,把问题意识从“模型会不会说话”拉回了自动驾驶最原始的那个问题:模型规划的轨迹到底靠不靠谱?
这不只是论文层面的改进,是整个技术假设层面的调整。
传统VLM做自动驾驶的硬伤:在2D图片上做3D空间决策OpenDriveVLA的出发点很直接。现在的VLM主要在互联网图文上训练,天然不擅长3D驾驶场景。一辆车在你左前方8米还是18米,对普通问答差别不大,但对规划就是完全不同的动作。
论文直接点出两个风险:
2D静态图像理解迁移到动态3D场景时,空间推理会显著弱化
VLM容易产生幻觉——把交通场景里的某些对象说错、漏掉,甚至过度自信
在自动驾驶里,幻觉不是小毛病。模型漏看一个行人,或者把车道线位置理解错,后面积累出来的轨迹就全歪了。
怎么解决?OpenDriveVLA的解法很务实:不指望LLM自己从2D图片里“悟”出3D结构,而是直接把自动驾驶领域已经成熟的BEV感知体系接进来。 这个选择本身就说明了一个问题:作者们不相信“大力出奇迹”那套。
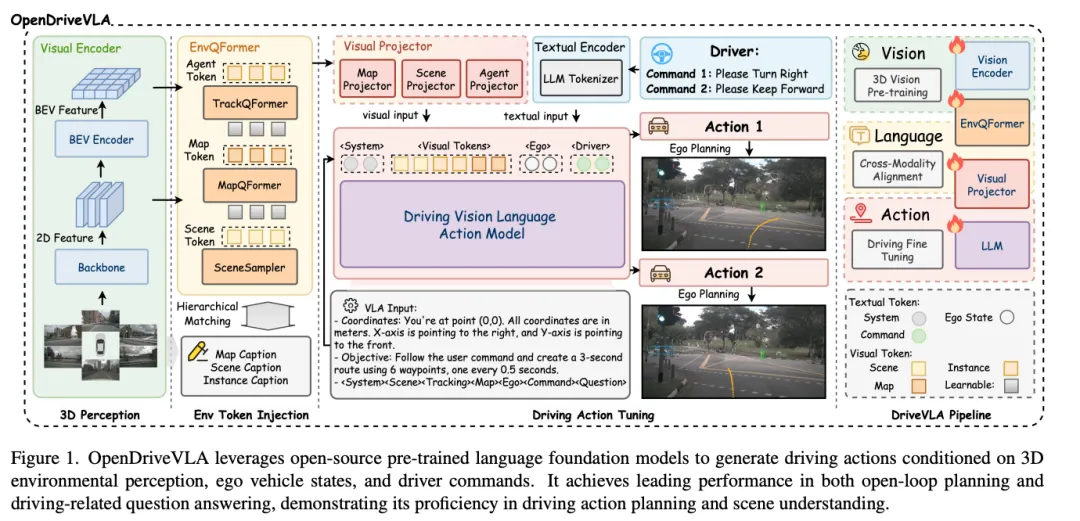
架构亮点:不是全局Embedding,是这三类TokenOpenDriveVLA的架构图值得细看。左边是多视角图像输入,经过ResNet-101 + FPN做2D特征提取,然后通过BEVFormer做2D→3D变换,得到BEV feature map(空间分辨率200×200)。
最核心的设计在于:它没有把场景压成一个全局embedding,而是分成三类独立token:
| Token类型 | Query数量 | 监督来源 | 解决的问题 |
|---|
| Scene Token | 90个 | 场景级caption | 全局上下文理解 |
| Agent Token | 900个 | 3D检测+跟踪 | 动态交通参与者建模 |
| Map Token | 300个 | BEV语义分割 | 静态道路结构提取 |
这个拆法的工程直觉很老道:车、路、自己、目标这几件事,最好不要糊在一起让模型去猜。 Agent token和map token都可以直接用感知任务监督,相当于给LLM喂进去的不再是原始图像,而是已经经过充分验证的3D结构化信息。
OpenDriveVLA的训练流程比架构本身更值得关注。分四个阶段,每个阶段冻结的模块各不相同——这背后是对“把所有loss混在一起端到端训练可能学歪”的清醒认知。、
阶段1:分层视觉语言对齐├── 冻结:视觉encoder + LLM├── 训练:投影器└── 数据:2D/3D caption(53.6万条)阶段2:驾驶指令微调├── 冻结:视觉encoder├── 训练:投影器 + LLM└── 数据:QA对(56.6万条,含nuScenesQA等)阶段2.5:Agent-Env-Ego交互建模├── 目标:让模型学会预测其他agent的未来运动├── 效果:消融显示,这一段对碰撞率改善最明显└── 数据:轨迹预测标注(45.9万条)阶段3:轨迹规划微调├── 目标:生成自车未来3秒轨迹├── 数据:2.8万条轨迹标注└── 输出:6个waypoints,间隔0.5秒
阶段2.5是全文最耐人寻味的设计。模型不能只知道对象在哪,还得知道对象会怎么动、会不会影响自车。这是从“静态感知”走向“动态交互推理”的关键一步,也是很多VLM方法直接跳过去的部分。 论文的消融实验明确显示,这一段对碰撞率的改善非常显著——说明作者们是真正做了工程取舍验证的。
最后落在规划上。OpenDriveVLA输出的本质是一条轨迹:未来3秒,6个waypoints,每个waypoint是二维坐标。格式大概是<traj_start>[(x1,y1),...,(x6,y6)]<traj_end>,由LLM自回归生成。
这条路的好处是统一:QA、场景解释、轨迹生成都在同一个自回归框架里。模型不用额外接一个planner head,也不用把输出变成完全不同的连续回归任务。
代价也很现实:
| 模型 | 单张A100/bf16延迟 |
|---|
| 0.5B | 1.36秒 |
| 3B | 1.85秒 |
| 7B | 1.74秒 |
拿这个速度做开环benchmark没问题,但离真实车端高频闭环还有距离。这个延迟数据敢公开,说明作者们没有玩花活——他们知道LLM做规划的工程瓶颈在哪。
nuScenes开环规划,L2误差和碰撞率都做到了SOTA。3B和7B版本平均L2误差0.33米,碰撞率0.10。对比数据:DriveVLM L2误差0.31米碰撞率0.10,Senna L2误差0.29米(碰撞率未公布)。
但说实话,这项工作的真正价值不在benchmark排名,而是:
这套“BEV感知 + Scene/Agent/Map Token + 多阶段训练 + 自回归轨迹生成”的组合本身,比任何单一指标都更有启发性。
OpenDriveVLA做的其实是一件很“老派”的事:它没追求结构上的花哨,而是在“怎么把靠谱的3D感知和LLM连接起来”这条线上做了扎实的系统设计。
几个值得工程师们细品的结论:
不要指望VLM自己从2D图片里学会3D空间推理——给它喂结构化的3D感知结果是更务实的做法
多阶段训练比端到端一把梭更可靠——尤其是在感知任务和规划任务天然不同频的自动驾驶场景里
阶段2.5(agent运动预测)的设计很关键——碰撞率改善最大的不是最后的规划微调,而是这个“中介任务”
轨迹离散化这条路精度有上限,延迟也摆在那——想量产落地,LLM推理效率是绕不开的硬约束
在自动驾驶VLA这个赛道上,大家都在做,但做得好的不多。OpenDriveVLA至少是一个值得认真读、仔细抄思路的工程范本。这个方向迟早会从学术benchmark走向真车闭环,而这篇论文留下的那个“推理延迟1.7秒”的问题,才是下一个真正值得追的方向。