面向自动驾驶个性化决策的人类引导持续学习方法
标题: Human-Guided Continual Learning for Personalized Decision-Making of Autonomous Driving
作者: Haohan Yang,Yanxin Zhou,Jingda Wu,Haochen Liu,Lie Yang,Chen Lv
发表期刊: IEEE Transactions on Intelligent Transportation Systems
发表日期: 2025年
这篇文献主要研究自动驾驶中的个性化决策问题。传统自动驾驶策略通常是面向多数驾驶场景训练出来的通用策略,但不同驾驶人有不同偏好。有些驾驶人更喜欢平稳驾驶,有些驾驶人更重视通行效率。因此,一个固定的通用决策策略很难同时满足所有驾驶人的需求。
针对这一问题,作者提出了一种人类引导的持续学习框架。当自动驾驶车辆的决策不符合驾驶人偏好时,驾驶人可以实时接管车辆,并给出人工示范。系统会自动收集这些示范数据,并在不重新训练整个模型的情况下,对已有自动驾驶策略进行更新,使其逐渐适应某一驾驶人的决策风格。
文中还提出了PEM-EWC方法,用于避免模型在学习少量人工示范后发生过拟合,同时防止模型遗忘原本已经学到的基本驾驶能力。作者通过驾驶人在环仿真和真实无人车实验验证了该方法。实验结果表明,该方法在安全性、类人性和训练效率之间取得了较好的平衡。
自动驾驶导航过程通常包括行为决策、运动规划和轨迹控制。其中,行为决策处在较高层级,例如换道、超车、让行等,它直接影响后续规划和控制结果。因此,决策层是自动驾驶系统中的关键部分。现有自动驾驶决策方法大致可以分为两类:一类是规则方法,另一类是学习方法。规则方法可解释性较强,但面对复杂交通环境时,规则设计会越来越困难。学习方法可以通过大量交互数据自动优化策略,但训练成本较高,而且对数据质量要求较高。驾驶人之间存在明显差异。有人偏保守,有人偏激进,有人重视舒适性,有人重视效率。通用自动驾驶策略很难满足所有人的偏好。如果为每个驾驶人重新训练一个模型,成本太高;如果只用少量数据微调,又容易造成模型遗忘原有驾驶能力。基于此,作者提出了“人类引导+持续学习”的思路。
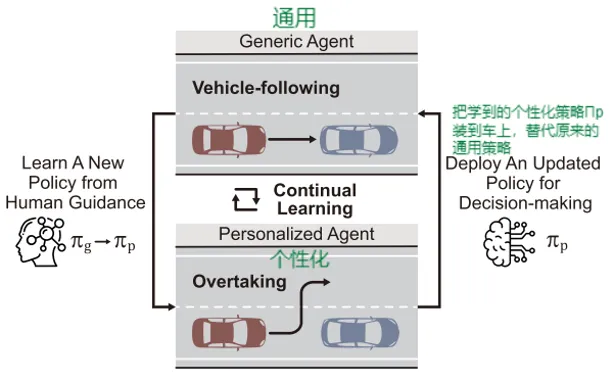
自动驾驶车辆原本使用通用策略,当驾驶人接管并提供示范后,系统学习得到个性化策略。例如,某驾驶人更倾向于超车而不是跟车,车辆就会逐渐学习这种偏好。这上图说明了文章的核心思想:不是重新训练一个模型,而是在原有模型基础上不断适应驾驶人。
1.总体框架
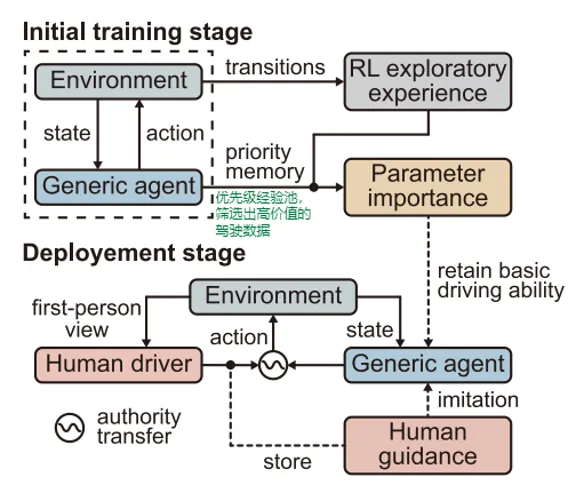
文献提出的人类引导持续学习框架如上图所示。整个过程可以分为两个阶段。
第一阶段是初始训练阶段。系统先通过强化学习训练一个通用自动驾驶决策模型。与此同时,根据模型的历史经验计算各个参数对基本驾驶能力的重要性。
第二阶段是部署学习阶段。车辆实际运行时,如果驾驶人认为自动驾驶决策不符合自己的偏好,就可以实时接管。系统会记录驾驶人的动作,并把这些示范数据用于更新策略,使车辆逐渐学习个性化决策风格。上图左上部分表示初始训练,环境与通用智能体交互并形成强化学习经验;左下部分表示部署阶段,驾驶人可以通过权限切换介入车辆决策;右侧则表示系统在学习驾驶人示范的同时,保留原来的基本驾驶能力。
2.状态空间和动作空间
文献将自动驾驶决策问题建模为马尔可夫决策过程,即:
其中,S表示状态空间,A表示动作空间,P表示状态转移概率,r表示奖励函数。
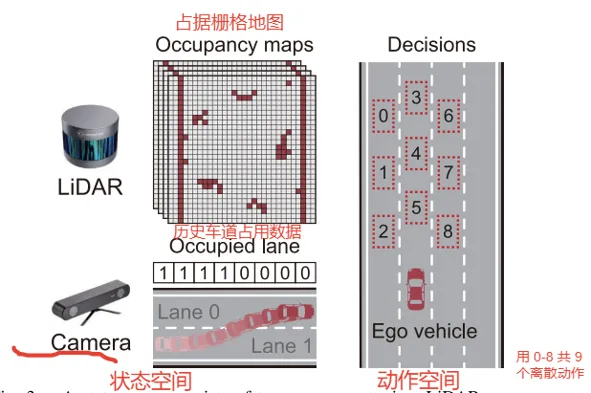
上图中,状态空间由两部分组成:一部分是LiDAR占据栅格图,用来表示周围车辆、道路边界等障碍物;另一部分是历史车道占用信息,用来表示自车过去一段时间所在的车道。动作空间包括 9 个离散动作,对应保持车道、左换道、右换道、加速、减速以及组合动作等。
文献中的状态空间公式为:
其中,表示Sobs由激光雷达占据图提取的环境特征,Slane表示车辆所在车道的历史信息。
动作空间定义为:
这说明车辆不是直接输出方向盘转角或加速度,而是先输出高层行为决策,例如“左换道”“保持车道”“减速右换道”等。
3.奖励函数设计
文献将奖励函数分为三部分:任务完成奖励、碰撞惩罚和平顺性奖励。
任务完成奖励为:
碰撞惩罚为:
平顺性奖励为:
总奖励为:
这里可以理解为:车辆不仅要完成任务,还要避免碰撞,同时不能频繁改变决策,否则会影响驾驶平顺性。
4.个性化策略学习目标
文献的核心目标是:让通用策略通过驾驶人示范数据变成个性化策略。
对应公式为:
其中,fCL持续学习方法。它的作用是利用驾驶人示范数据对原有策略进行更新。
作者提出两个约束目标。
第一个目标是避免灾难性遗忘。也就是说,模型学习驾驶人偏好后,不能把原来的安全驾驶能力忘掉。
第二个目标是学习驾驶人偏好。也就是说,更新后的策略应该比原来的通用策略更接近驾驶人的决策。
这两个公式体现了文章的关键思想:既要学会驾驶人的个性,又不能丢掉原来的安全能力。
5.PEM-EWC方法
为了防止模型遗忘原有知识,作者提出了PEM-EWC方法。EWC的基本思想是:对于那些对原有驾驶能力很重要的参数,不允许它们在学习新示范时发生太大变化。
参数重要性计算公式为:
其中,γi表示第i个参数的重要性。重要性越大,说明这个参数越关键,更新时就越要谨慎。
文献还引入TD误差来计算经验优先级:
采样概率为:
这部分可以理解为:系统优先利用那些更稳定、更有代表性的经验来判断哪些参数重要,从而更好地保留原有驾驶能力。
6.Dual-Hug人类引导学习模式
作者还提出了Dual-Hug 模式,主要包括两个部分。
第一,驾驶人可以实时接管车辆。对应公式为:
当λ=0时,由自动驾驶策略控制;当λ=1时,由驾驶人控制。
第二,模型通过行为克隆项学习驾驶人动作。综合后的损失函数为:
这个公式由三部分组成:原始强化学习损失、模仿驾驶人的损失、防止遗忘的正则项。它是全文方法部分最关键的公式。
1.实验场景
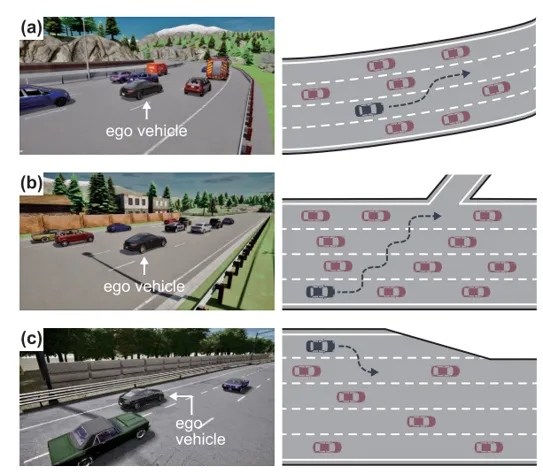
文献设置了三类典型驾驶场景,如上图所示。 图(a)是弯道超车场景,车辆需要在多车道弯道中完成超车决策。图(b)是高速公路匝道驶出场景,车辆需要多次换道并到达出口区域。图(c)是车道汇入场景,车辆需要在存在交互车辆的情况下完成并线。这三个场景都和自动驾驶决策密切相关,尤其是换道、超车、汇入等行为,比较适合验证个性化决策方法。
2.对比方法
为了验证本文方法的效果,作者设置了多种对比方法。通用策略用于表示车辆原本的自动驾驶决策能力,驾驶人示范用于表示真实的个性化驾驶偏好。RMfD方法通过驾驶人示范设计奖励函数,再训练个性化强化学习策略;IEP方法利用专家示范约束强化学习过程,使车辆行为更接近人类驾驶;Hug方法允许驾驶人实时接管车辆,并利用接管数据更新策略;Hug+MAS则在 Hug的基础上加入防遗忘机制,减少模型在学习新偏好时对原有驾驶能力的遗忘。通过这些方法的比较,文献主要考察本文方法在安全性、类人性和训练效率方面是否具有优势。
3.实验平台
文献既做了仿真实验,也做了真实无人车实验。

上图展示了真实无人车平台。车辆上安装了LiDAR、Camera、IMU和计算单元。LiDAR和相机用于获取环境信息,计算单元根据高层决策生成速度和转向控制命令。
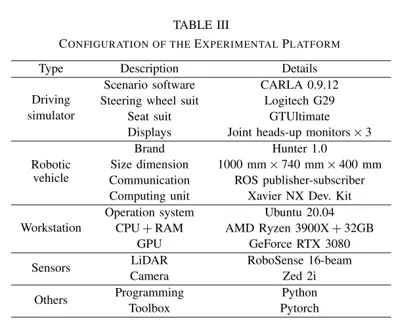
上表给出了实验平台的软硬件配置。
4.实验评价指标
仿真实验主要从两个角度评价。
①安全性,包括成功率S.R.和平均奖励A.R.。
②类人性,包括纵向速度L.S.和横向加速度L.A.。
真实无人车实验主要使用两个指标。
①安全到达频率S.A.。
②主动汇入频率P.M.。
简单来说,作者既看车辆是否安全完成任务,也看车辆是否真的学到了驾驶人的风格。
5.主要实验结果
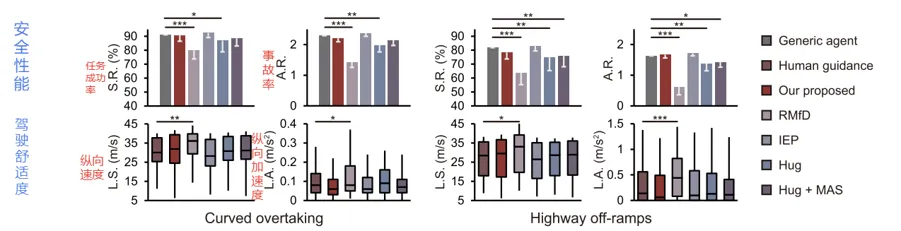
图的上半部分是安全性指标,下半部分是类人性指标。结果表明,Hug方法虽然能较好模仿驾驶人,但容易过拟合少量示范,导致安全性下降。RMfD在复杂多车交互场景中表现较差。IEP和本文方法都能兼顾安全性和类人性,但IEP需要从头训练,成本更高。本文方法在保持安全性的同时,能够较快学习个性化决策风格。
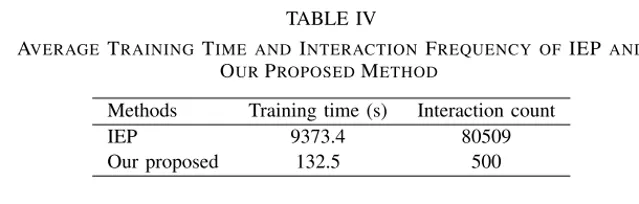
从上表可以看出,本文方法所需训练时间和交互次数远低于IEP。这说明本文方法更适合实际车辆部署,因为它不需要为每个驾驶人重新训练完整模型。
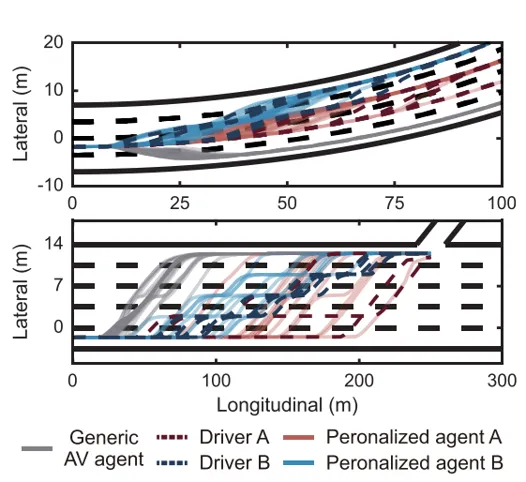
上图展示了不同驾驶人的轨迹差异。通用策略更保守,而驾驶人A更倾向于主动换道和超车,驾驶人B则更平稳。经过学习后,个性化智能体能够表现出接近对应驾驶人的轨迹风格。
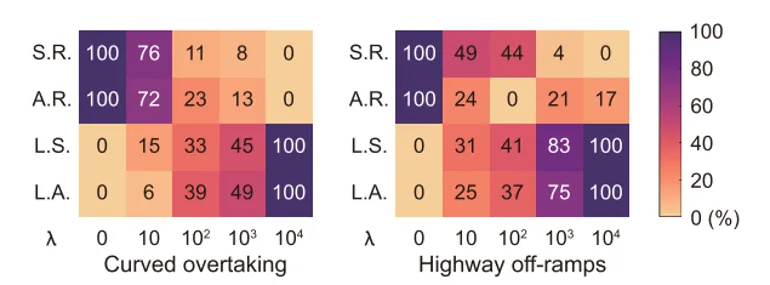
上图说明,损失权重会影响安全性和个性化之间的平衡。当λ太小时,模型容易过度模仿驾驶人,安全性下降;当λ太大时,模型更新受限,个性化学习能力变弱。
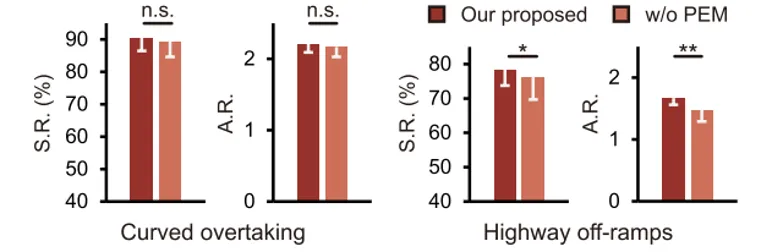
上图表明,加入PEM机制后,模型在复杂的高速匝道驶出场景中安全性更好。这说明PEM对防止灾难性遗忘有帮助。
这篇文献提出了一种面向自动驾驶个性化决策的人类引导持续学习方法。它的主要思想是:车辆先具备一个通用决策能力,在实际运行中再根据驾驶人的接管示范进行持续更新,从而逐渐形成个性化策略。
文献的创新点主要有三个。
①提出了PEM-EWC方法,用于防止模型在学习驾驶人示范时遗忘原有驾驶能力。
②设计了Dual-Hug人类引导学习模式,使驾驶人可以实时接管并提供示范。
③通过仿真实验和真实无人车实验验证了方法的有效性。
实验结果表明,本文方法相比其他方法,在安全性、类人性和训练效率之间取得了较好的平衡。尤其是与IEP方法相比,本文方法训练时间从9373.4s降低到132.5s,交互次数从80509次降低到500次,说明其具有较好的实际应用潜力。
这篇文献提出了人类引导的持续学习框架,用于解决自动驾驶个性化决策问题。该方法允许驾驶人在车辆决策不符合个人偏好时实时接管,并让模型从接管示范中学习驾驶风格。同时,作者引入PEM-EWC方法,减少模型在学习新偏好时对原有安全驾驶能力的遗忘。其优点是训练成本低,不需要为每个驾驶人重新训练模型,并且能在安全性、类人性和训练效率之间取得较好平衡。
但该方法也有一定局限。它比较依赖驾驶人示范的质量,如果驾驶人接管时操作不合理,模型可能学到错误偏好。同时,文章主要从驾驶行为层面学习个性化特征,对驾驶人背后的认知因素,如风险感知、信任程度和认知负荷等解释不足。因此,它更偏向工程应用,对驾驶人认知决策机理的分析还不够深入。