自动驾驶世界模型已经成为端到端智驾的必争之地。给定当前前视相机画面和一串自车动作,模型能否预测出8秒后的真实街景?这决定了规划系统能不能在仿真中"脑补"未来。
但斯坦福团队在这篇论文里戳破了一个行业潜规则:当前主流的评估指标——余弦相似度、SSIM、L2——系统性奖励回归模型塌陷到模糊条件均值,而掩盖了扩散模型在真实分布上的巨大优势。他们用一套基于Stable Diffusion VAE的紧凑DiT(仅5.4M参数),在nuScenes 150个 held-out 场景上实锤:扩散模型的KID比直接回归好4.8倍,且方向盘输入与场景位移的Spearman相关系数高达0.81。更反直觉的是,一个1.7M参数的"跳跃"链式模型,通过重新锚定机制,找回了被单步模型丢失的完整前向运动幅度。
论文链接:https://arxiv.org/pdf/2606.12987
自动驾驶世界模型的两大灵魂拷问:在哪预测?怎么预测?
世界模型的核心任务,是给定当前前视相机帧和一段自车动作序列,预测未来的场景表征。这个预测结果既要喂给下游规划器做推演,也要在仿真器中渲染成可视化画面。但在动手搭模型之前,有两个根本问题必须回答:第一,在哪个表征空间里做预测?第二,在这个空间里,生成式模型真的比确定性回归模型更有价值吗?
论文选取了nuScenes v1.0-trainval数据集作为实验场,包含850个驾驶场景,每个约20秒,以2Hz的关键帧频率采集,覆盖波士顿和新加坡的多样化城市场景。数据被严格按场景切分:630个训练、70个验证、150个测试,确保没有任何场景跨集泄露。自车动作从CAN-bus提取,包括转向角和加速度,经过训练集统计的z-score标准化。
在图像编码侧,论文没有拍脑袋选一个编码器,而是系统测试了四个表征家族的六款冻结编码器:监督学习的ViT-S/16、自监督图像的DINOv2-S/14、视觉-语言对比的CLIP-ViT-B/32、自监督视频的V-JEPA2(单帧rep1和16帧clip rep64)、以及重建导向的VQ-VAE Tracker。对于世界模型本身,当前帧通过冻结的Stable Diffusion VAE编码为32×32×4的latent网格,再patchify为8×8=64个空间token。动作则通过64个学习频率的Fourier特征嵌入,与timestep和当前帧表征一起作为条件输入。
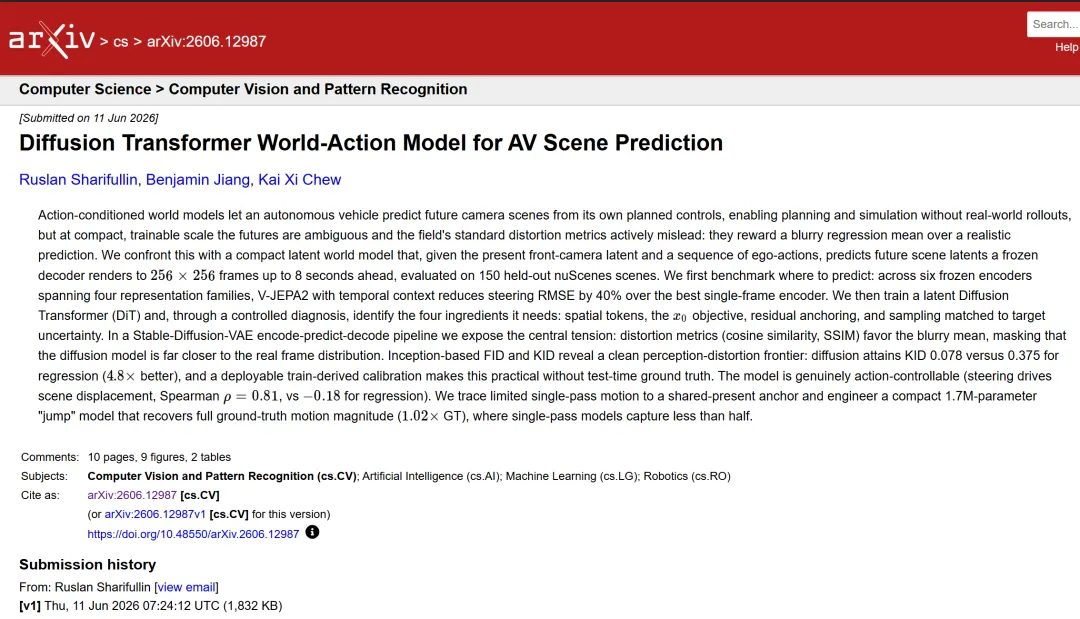
Figure 1 : 单步架构总览:SD-VAE编码当前帧,Fourier嵌入动作,锚定DiT预测未来latent,VAE解码为256x256帧
上图展示了整个pipeline的骨架:冻结编码器负责把原始输入压缩到latent空间,4层DiT块在这个空间里做预测,最后冻结VAE解码器把latent还原为256×256的画面。这个设计刻意保持紧凑,世界模型本身只有约5.4M参数,目的是在受控规模下做精确诊断,而非直接堆参数炫技。
六编码器横评:时序视频表征碾压单帧,V-JEPA2 steering RMSE砍40%
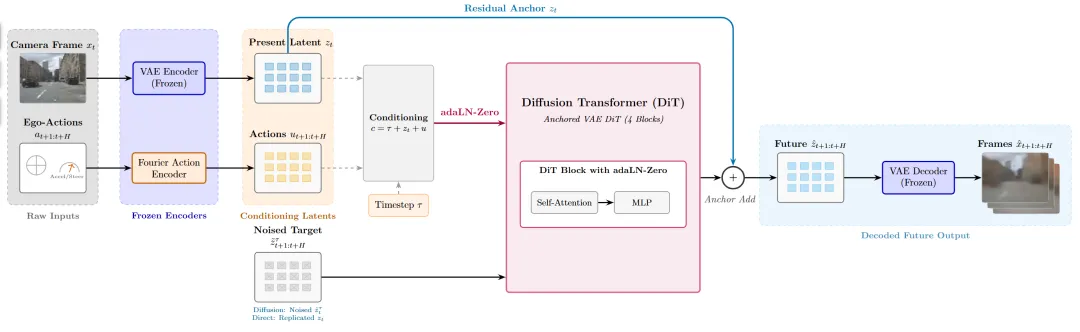
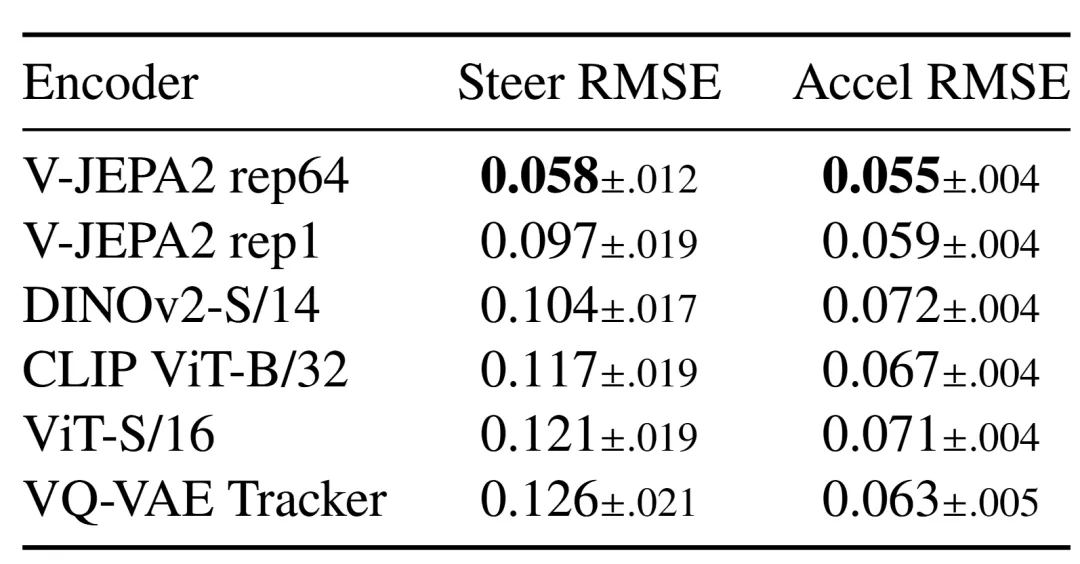
在正式训练世界模型之前,论文先做了一个编码器benchmark:用六款冻结编码器的输出特征,接一个共享的2层MLP探针,预测转向角和加速度。这个探针在训练集上训练50轮,在150个测试场景上报告场景级别的RMSE。
结果非常清晰。V-JEPA2 rep64(使用完整视频transformer处理16帧clip)的转向RMSE为0.058,而V-JEPA2 rep1(仅使用单帧空间编码器)为0.097。这意味着,引入时序上下文后,转向预测误差直接砍掉了40%。在Figure 2的柱状图中,V-JEPA2 rep64的蓝色柱子明显低于所有单帧竞争对手。
Table 1 : 六款冻结编码器在nuScenes测试场景上的steering与acceleration RMSE,V-JEPA2 rep64显著优于所有单帧编码器
Figure 2 : 六编码器steering RMSE对比柱状图,V-JEPA2 rep64比最佳单帧编码器低40%
排在其后的单帧编码器依次是DINOv2(0.104)、CLIP(0.117)、ViT-S/16(0.121)和VQ-VAE Tracker(0.126)。值得注意的是,自监督方法(DINOv2、V-JEPA2 rep1)在转向预测上优于监督ViT和语言对齐的CLIP,说明自监督特征捕捉了更丰富的几何结构。而VQ-VAE Tracker垫底,暗示优化图像重建的编码器更关注外观而非与动作相关的动态信息。加速度RMSE的差距较小(0.055 vs 0.059),因为加速度从单帧推断相对更容易。
这个benchmark的结论是:如果你在世界模型里用单帧编码器做预测,本质上是在让模型"盲猜"ego-motion动态和车道曲率,而时序视频表征把这些信息直接编码进了特征里。
回归模型的"清晰陷阱":CosSim越高,离真实世界越远
进入SD-VAE的latent空间后,论文构建了一个锚定VAE DiT(4层transformer块,adaLN-Zero条件化),同时训练了一个直接回归基线作为对照。两者共享相同的架构和条件输入,区别仅在于回归基线不做扩散去噪,而是直接单步前向预测未来latent。
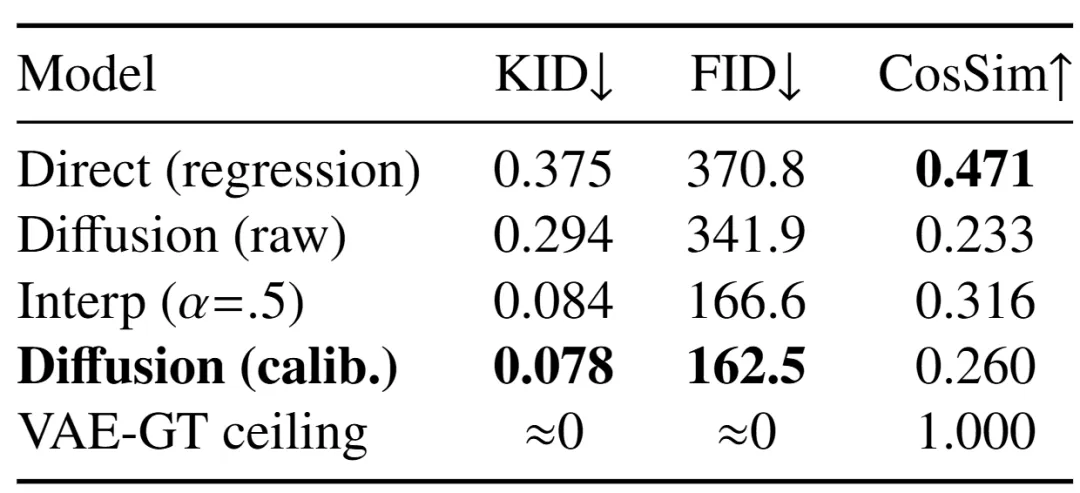
在评估阶段,一件极其反直觉的事情发生了:直接回归模型在每一项失真指标上都完胜扩散模型。它的余弦相似度(CosSim)达到0.471,而扩散模型(训练校准后)只有0.260;它的SSIM更高、L2更低。如果只看到这些数字,你会以为回归模型是个更好的世界模型。
但论文指出,这恰恰是感知-失真权衡(perception-distortion tradeoff)在自动驾驶领域的典型表现。回归模型通过最小化逐像素损失,塌陷到了条件均值——一个统计上"最安全"但视觉上模糊的答案。它输出的画面看起来像是涂了一层奶油,车辆轮廓和车道线都糊成一团,因为模型在平均所有可能的未来。
Table 2 : 分布指标与失真指标对比:扩散模型KID 0.078 vs 回归0.375,FID 162.5 vs 370.8
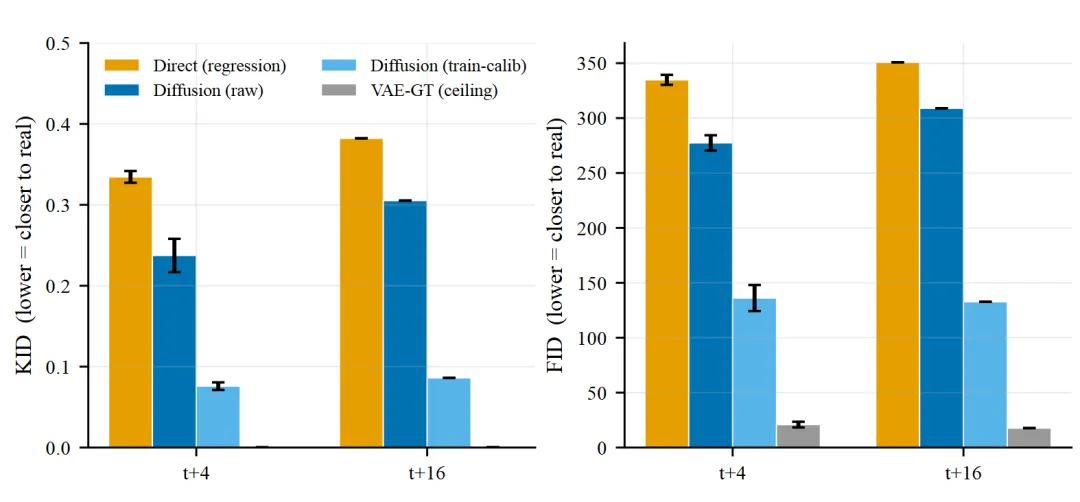
当换用分布指标评估时,真相浮出水面。论文使用Inception-v3特征的FID和KID(对样本量小的场景更稳健)来衡量预测帧分布与真实帧分布的距离。直接回归的KID高达0.375,FID高达370.8;而经过训练集校准的扩散模型,KID仅为0.078,FID为162.5。扩散模型在KID上实现了4.8倍的优势。
Figure 4 : t+4与t+16的FID/KID对比,训练校准后的扩散模型显著接近真实帧分布
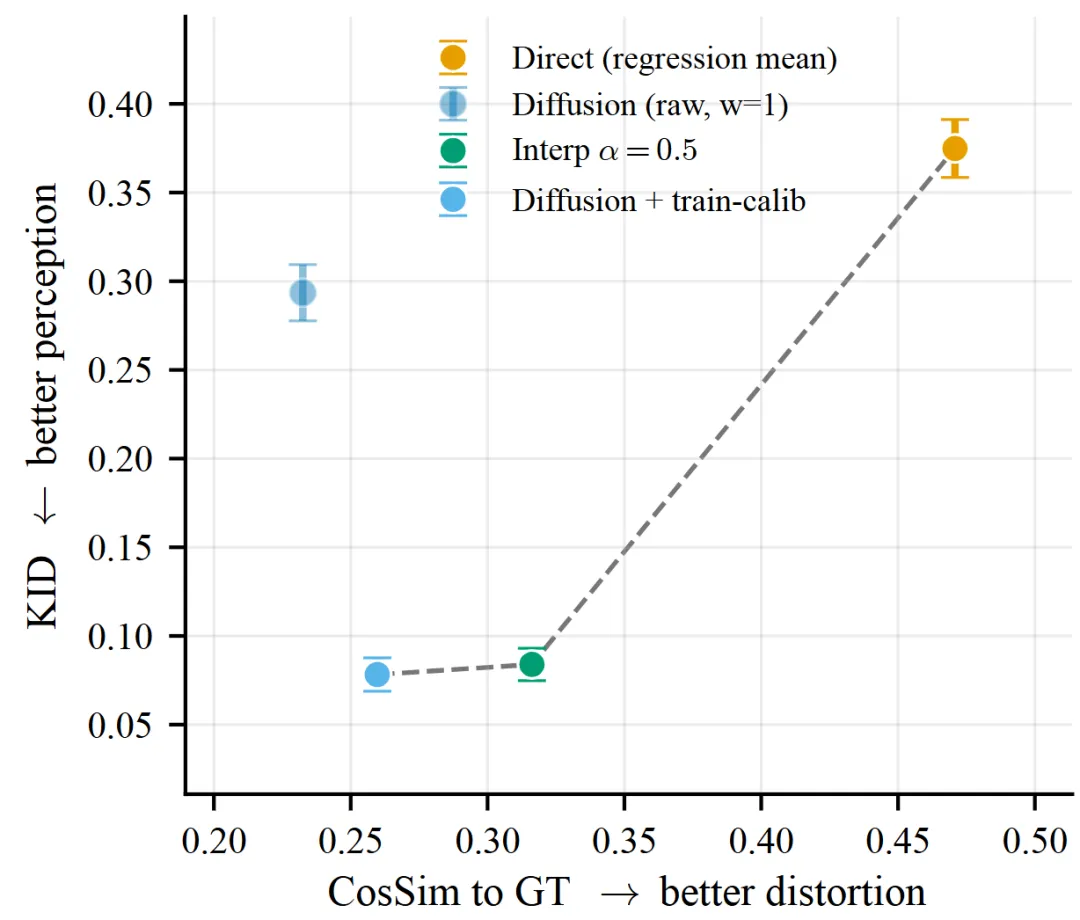
Figure 5 : 感知-失真经验前沿:CosSim为横轴,KID为纵轴,扩散模型占据高真实感区域
Figure 5的散点图清晰描绘了这条经验前沿:回归模型位于高失真、低真实感(高KID)的右下角;扩散模型位于低失真、高真实感的左上角。两者之间的插值点(latent interpolation)提供了可部署的中间操作点。论文强调,这个校准完全基于训练数据统计,测试时无需接触真实帧,因此是可部署的而非测试时作弊。
扩散模型的四味真火:x0目标、空间token、残差锚定、采样匹配
为什么同样是DiT架构,有些配置能工作,有些却直接崩溃?论文设计了一条受控诊断链,逐一检验四个假设。
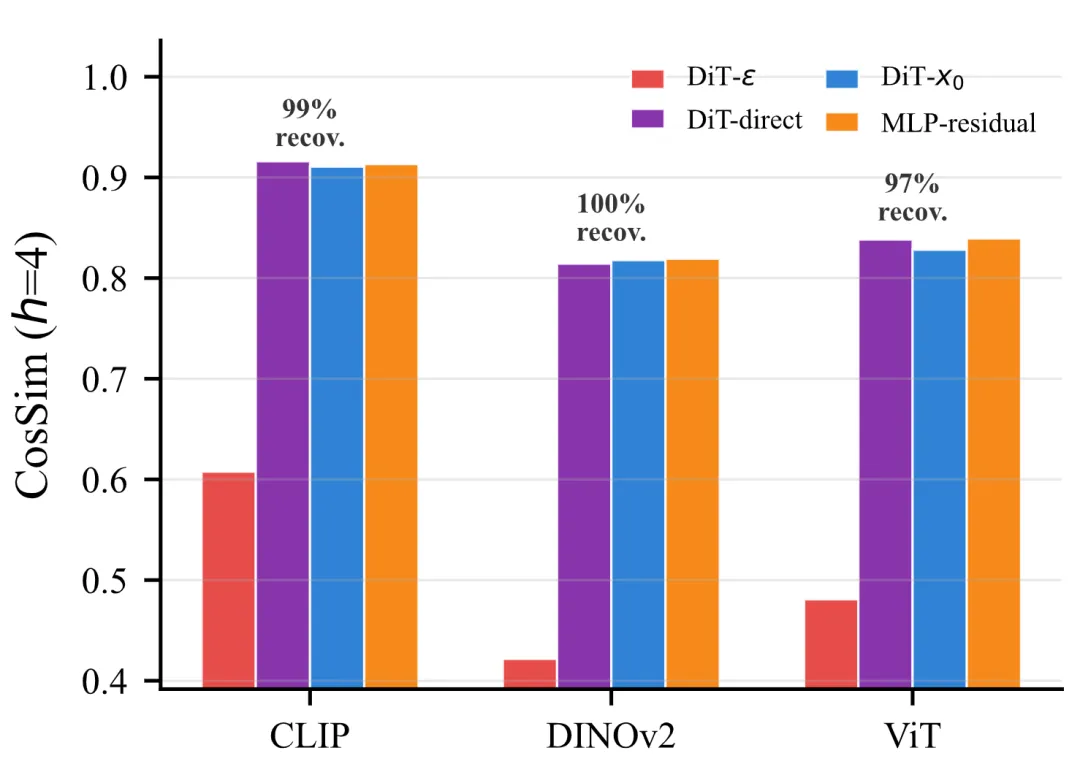
H1(容量假设):DiT架构本身是否不够强?答案是否定的。当去掉扩散、只做直接预测时(DiT-direct),DiT与同等参数量的MLP-residual基线表现持平,说明transformer架构不是瓶颈。
H2(目标函数假设):扩散预测目标的选择至关重要。论文发现,使用ε-预测目标在紧凑latent空间中会导致模型几乎塌陷为复制当前帧,而切换到x0-预测目标后,性能恢复了88.5%的差距。这是因为在VAE latent空间里,x0目标更稳定。
H3(horizon假设):更长的预测horizon是否天然有利于扩散?答案是否定的。在2Hz、有真实动作条件的情况下,未来分布接近单峰,horizon长度不是扩散优势的主要来源。
H4(动作序列假设):每步动作序列的条件化对DiT更有利。自注意力机制能够利用跨时间步的动作交互,这在MLP中不存在。
Figure 3 : 诊断链:ε预测塌陷,x0目标恢复88.5%差距;添加空间token后DiT匹敌MLP
当恢复空间token结构(而非池化向量)并加入残差锚定后,DiT在ViT和DINOv2编码器上均击败了匹配参数量的MLP。残差锚定的设计很简洁:模型不预测绝对未来latent,而是预测相对于当前帧zt的残差delta,即 z_{t+k} = z_t + Δ_k。这确保了模型在早期训练阶段稳定,且最差情况下会优雅地退化为复制当前帧,而非输出随机噪声。
最终,四个要素被确认为必要且联合充分:空间token、x0预测目标、残差锚定、以及与目标不确定性匹配的采样(DDIM 50步确定性采样 + classifier-free guidance)。
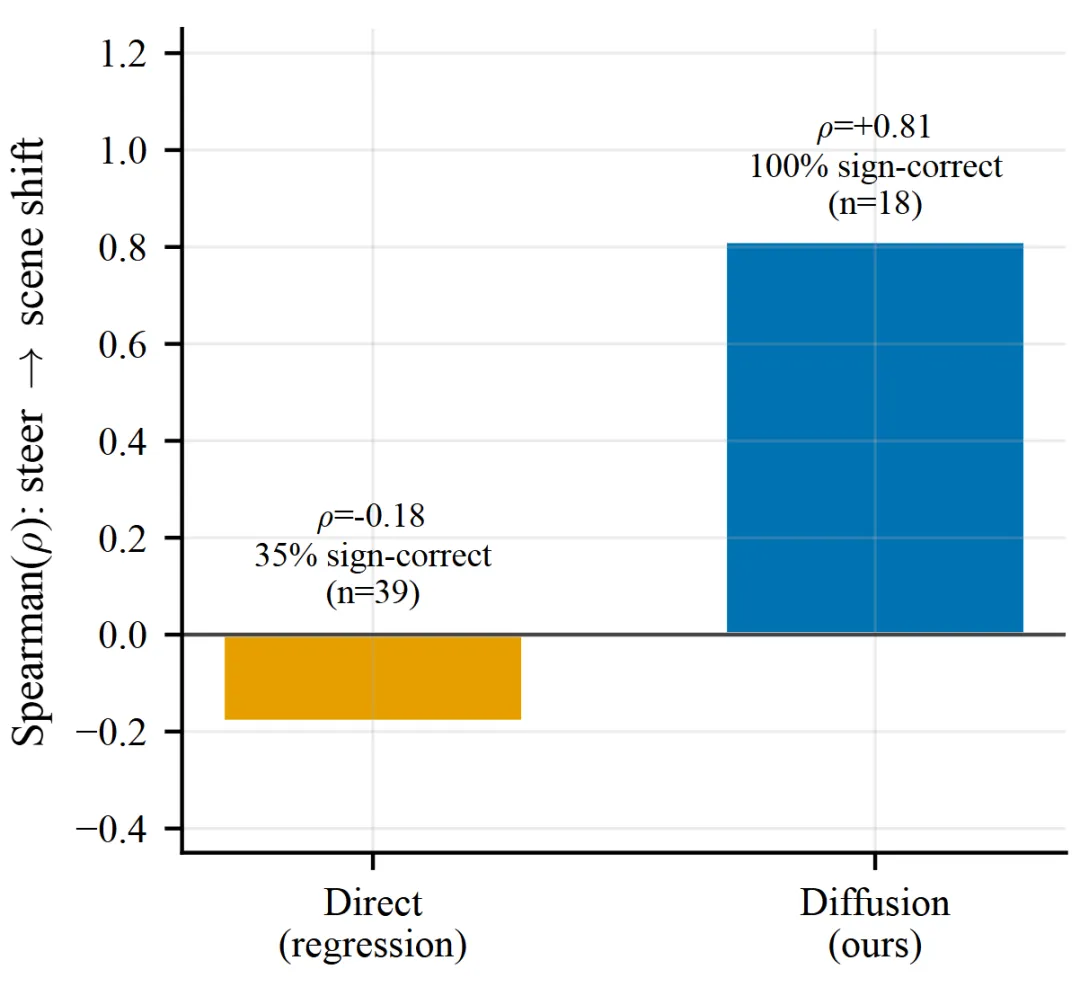
动作可控性实锤:方向盘与场景位移的Spearman ρ=0.81
一个世界模型如果只生成"看起来合理"的视频,却无法响应动作输入,那它对规划系统毫无价值。论文设计了一个严格的动作可控性测试:在固定扩散噪声的前提下,将转向输入从训练分布的5th到95th百分位扫描,测量t+15时刻预测场景的水平位移。
结果堪称分水岭。扩散模型的转向角与场景位移的Spearman相关系数达到+0.81,在40个测试场景中,有18个场景产生了超过检测阈值的位移,且这18个场景的符号正确率为100%——即方向盘往左打,场景就往右移;往右打,场景就往左移。这是符合物理直觉的。
Figure 9 : 动作可控性:扩散模型steering与场景位移Spearman ρ=0.81,回归基线ρ=-0.18
而直接回归模型的表现令人大跌眼镜:Spearman ρ = -0.18,符号正确率仅35%,几乎等同于随机。这意味着回归模型输出的"清晰"画面,其实与输入动作几乎没有因果关系。
更进一步的逆控制探针(inverse-control probe)显示:给定一个预测的未来帧,扩散模型能够以0.67倍随机误差的精度恢复出生成它的目标转向角;而回归模型比随机猜测还差。这说明扩散模型学到的latent动态确实编码了动作语义,具备支撑下游规划系统的潜力。
运动模糊不是能力问题,是锚定问题:1.7M jump模型找回完整前向运动
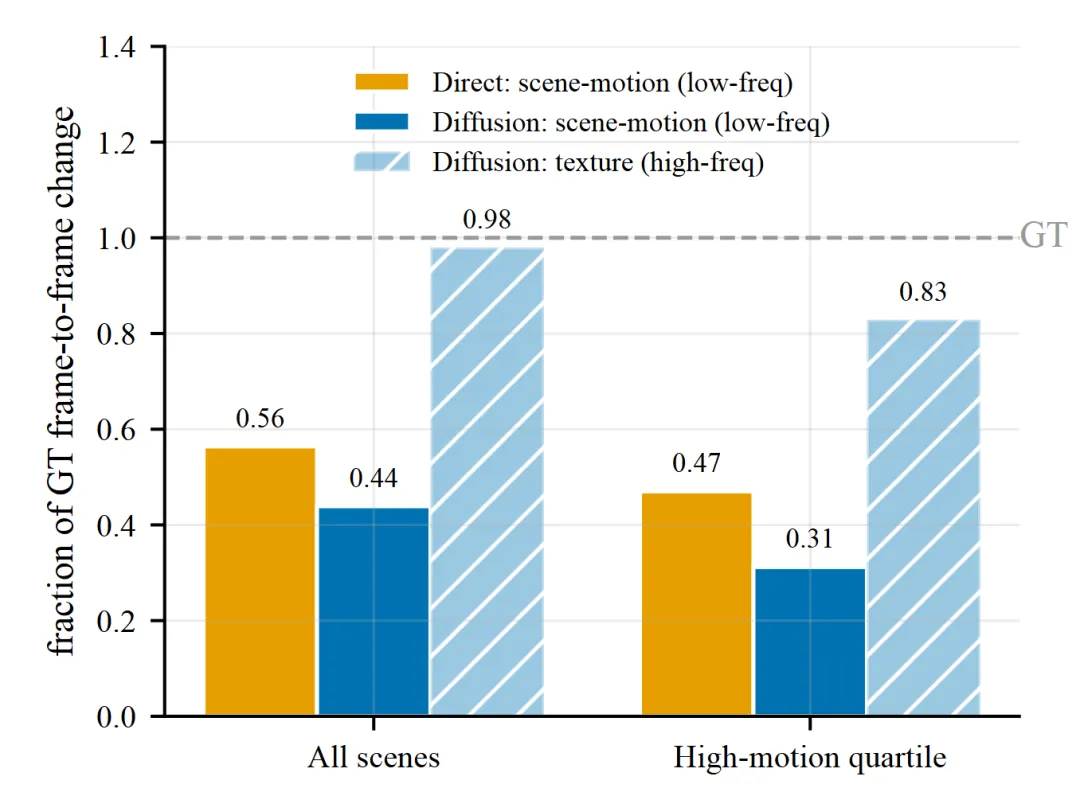
单步扩散模型虽然画面真实,但存在一个明显缺陷:时序运动不足。论文将连续帧差分解为低频(相干场景结构变化)和高频(纹理变化)成分。结果发现,单步扩散模型的低频运动幅度仅为真实值的0.44倍,而高频纹理变化却达到0.98倍。换句话说,模型在重绘纹理,但没有真正推动场景前进。
直接回归模型在低频运动上稍好(0.56倍),但代价是整体模糊。问题的根源被诊断为共享当前锚定(shared-present anchor):单步模型中,所有未来时刻的预测都基于同一个zt计算残差,这天然倾向于在当前布局上做局部调整,而非累积ego-motion带来的前向位移。
Figure 6 : 运动保真度诊断:扩散模型纹理接近GT但 coherent motion 仅0.44x,jump模型恢复至1.02x
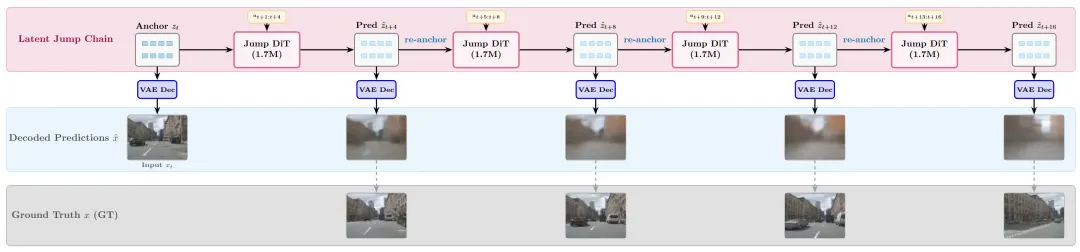
解决方案是一个极简的重新参数化:一个仅1.7M参数(比5.4M基线小3倍)的"跳跃"DiT,预测Δt=4的跳转,然后在推理时以4步开环链式重新锚定——每一步都基于自己的输出作为新的锚点,而非一直挂在最初的zt上。
Figure 8 : 链式锚定jump模型在held-out场景上的4步开环展开,逐步重新锚定自身输出
这个compact jump模型在30个held-out测试场景上,低频运动幅度达到真实值的1.02倍,图像平面运动方向与真实值的相关性为0.48,超过了单步大模型(0.41)。Figure 7的可视化叠加显示,jump模型成功捕捉了相干场景运动的空间分布模式,尽管解码画面仍带有回归模糊。这证明运动缺失不是模型容量问题,而是锚定设计问题。
结语
这篇论文给自动驾驶世界模型领域留下了两个无法回避的教训。
第一,评估指标决定你看到什么。如果行业继续只用CosSim和SSIM来评估世界模型,就会系统性偏爱那些输出"清晰假象"的回归模型,而忽视真正接近真实分布的生成式方法。FID和KID应该成为标准配置。
第二,紧凑规模下的受控诊断比盲目堆参数更有价值。在5.4M参数上,论文精确分离了x0目标、残差锚定、空间token和采样策略四个要素的贡献;在1.7M参数上,证明了运动缺失可以通过链式重新锚定解决。这些设计原则——包括可部署的校准策略和跳跃重参数化——可以直接迁移到更大规模的系统(如GAIA-1或Cosmos)中。
当扩散模型能让方向盘一转、场景就跟着动,且动得符合物理规律时,世界模型才真正从"视频生成玩具"变成了"规划系统的仿真大脑"。下一步,就是把这种coarse motion方向,通过更大容量和更强时序监督,转化为可识别的高保真多秒预测。
持续关注本公众号【赛博雷达】,我们会第一时间拆解更多前沿开源模型、本地AI实战和Agent最新进展。喜欢这篇文章就点个关注+转发给正在专注AI的朋友,把这份思考分享给更多AI爱好者。
感谢阅读,我们下期见~