自动驾驶系统已经能处理绝大多数标准驾驶任务。摄像头和激光雷达感知环境,检测模型圈出行人、车辆和信号灯,预测模块推算未来几秒的运动轨迹,规划算法再据此生成转向和加减速指令。
这套流程在常规道路上足够流畅,但真实的全球道路从来不是铁板一块。
日本的红绿灯前不允许右转闯红灯,而在中国和美国,多数路口可以在确保安全的前提下右转通过。新加坡的公交专用道分时段严格限行,印度的摩托车和机动三轮车则在车流中见缝插针。英国用红色边框三角牌警示学校区域,美国的学校警告标志则是荧光黄绿的五边形。
这些差异不是测试环节里的边角料。
它们恰恰决定了自动驾驶系统能否跨越国界,真正可靠地运行在不同文化的道路之上。
论文标题GEO DRIVE-BENCH: Benchmarking Region-Specific Multimodal Reasoning in Autonomous Driving
项目地址https://github.com/gray311/CulturalDrive-Bench
论文地址https://arxiv.org/pdf/2606.02774
来自威斯康星大学麦迪逊分校和约翰·霍普金斯大学的研究团队注意到一个被普遍忽略的问题:当前主流的驾驶视觉语言模型,几乎全部使用来自少数几个国家的数据训练和评估。nuScenes来自新加坡和美国,Waymo来自美国,ONCE来自中国——这些数据集的场景分布,悄悄将一套“默认交通规则”刻进了模型的行为偏好里。
但真实世界没有默认交通规则。
研究团队为此提出了 GEO DRIVE -BENCH,一个专门评估视觉语言模型在驾驶场景中进行地域文化推理能力的基准。
为什么现有基准不够用
过去几年,自动驾驶 VLM 评测基准层出不穷。DriveLM 覆盖感知、预测和规划三类任务,NuScenes-QA 构建了大规模问答对,CODA-LM 着眼于长尾 corner case,DriveAction 关注人类化的驾驶决策。
但纵观这些工作,一个共同的暗线假设贯穿始终:交规是通用的。
表1的对比非常直观——几乎所有已有基准的“交通规则”和“文化推理”两列都标着叉号。即使是覆盖了多个国家的数据集,也几乎不要求模型基于视觉线索推断所在地域,更不会检验模型是否掌握了该地域的具体交规。
曾有一项名为 LLaDA-AV 的工作尝试探索跨区域策略适应,但它仅提供小规模的开环规划评估,而且直接将区域标签作为输入提供给模型。
研究团队的研究员指出,这本质上是一个检索任务,而非推理任务。一个仅仅拿到“日本”这个单词就去查手册的模型,并没有展示真正的视觉-文化推理能力。
GEO DRIVE-BENCH 的构建思路
G EO D RIVE -B ENCH 的设计原则非常明确:绝不向模型透露国家标签。
模型必须从场景中自行推断所在地域——通过道路标识的样式、车牌的颜色、车道线的画法、路旁建筑的风格,甚至机动车和非机动车混行的特征。
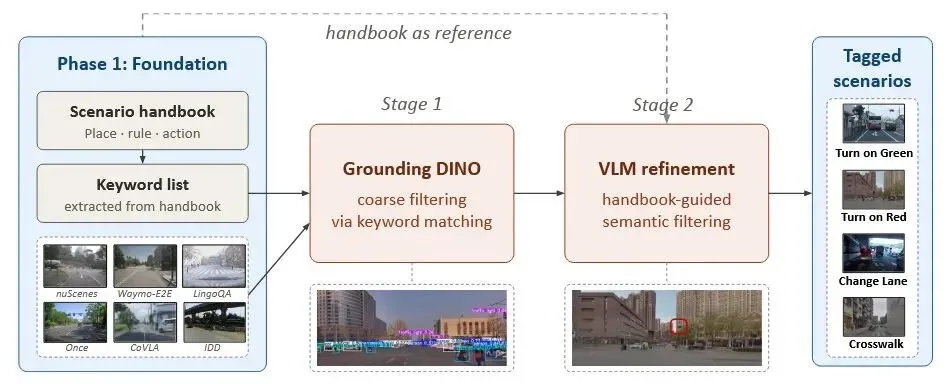
数据集构建从六个公共驾驶数据集出发,横跨六个国家:中国的 ONCE、日本的 CoVLA、新加坡的 nuScenes、英国的 LingoQA、印度的 IDD 和美国的 Waymo。
这六个国家覆盖了左舵与右舵、东亚和西方的交通管制传统,是目前能够获得足够场景多样性的最大区域集合。
研究团队手动定义了 13 类具有文化差异性的驾驶场景,包括红灯右转、无信号灯人行横道、公交专用道、环岛通行优先级、黄格线区域、校区间速度限制等。每一类型仅在至少有一个国家的法规在一项维度上与他国产生实质性分歧时才会被保留——无论是动作本身的合法性、执法的严格程度,还是基础设施的配置方式。
场景挖掘采用两阶段级联方式。第一阶段使用开源词表检测器 Grounding DINO,根据从交通手册中提取的关键词(如“红绿灯”“停止线”“转弯箭头”)进行粗筛选。第二阶段用 Qwen3-VL-235B 进行语义精炼,此时模型会获得场景的国家标签和手册条目——这是为了确保挖掘过程本身足够可靠,让筛选而非模型评测受益于这些额外信息。
四个任务维度
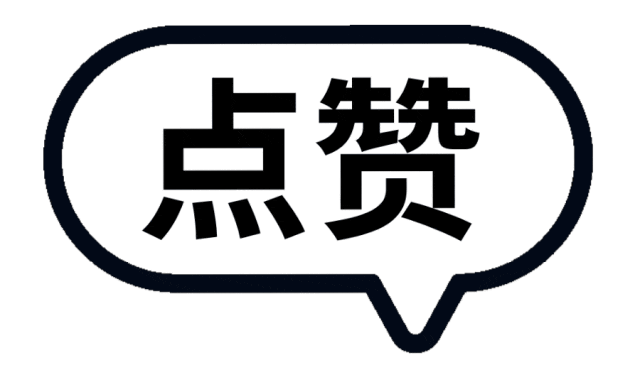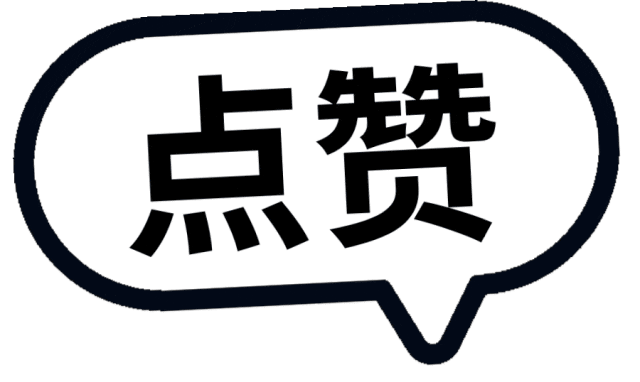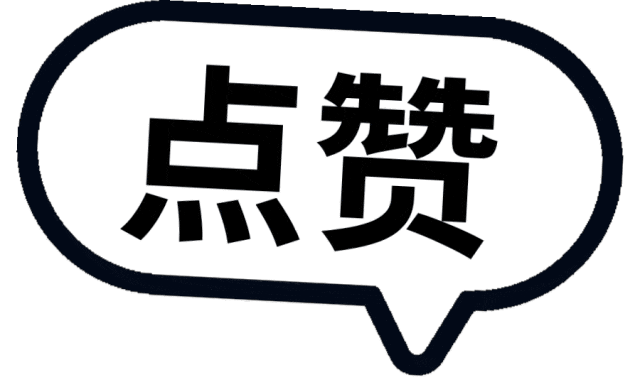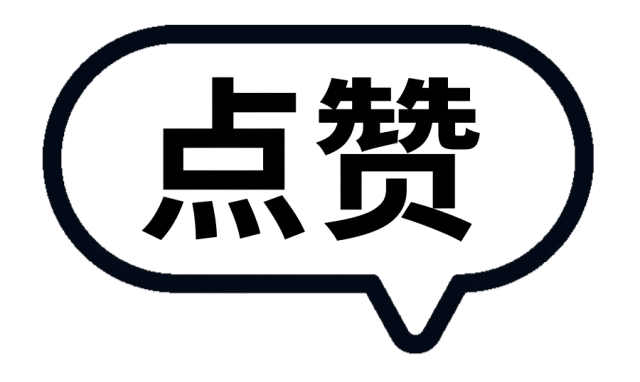
构建完成的 G EO D RIVE -B ENCH 包含 5,053 道人工验证的多选题,均匀分布在四个任务类别上。
感知任务占比约 30%,考查模型是否看懂了场景中的关键信息——车牌颜色是什么、交通标志的形状和符号、信号灯状态。
预测任务占比约 22%,要求模型判断场景中其他交通参与者接下来会做什么。行人在信号灯变红后会过马路吗?前方车辆会减速让行还是加速通过?
规划任务占比约 23%,聚焦于自车应该采取什么动作。可以在红灯时右转吗?应该在第几车道行驶?
区域推理任务占比约 25%,这是 G EO D RIVE -B ENCH 最具特色的设计。此类问题要求模型先推断出所在国家,再回答一个关于该国交规的问题——而答案本身未必能从图像中直接读出。例如,在不展示任何学校标志的情况下,问“该国用什么格式的标志警示前方有学校”,需要模型结合从其他视觉线索推断出的国家身份,调取正确的交规知识。
每一道题的干扰选项都经过精心设计。研究团队采用反事实验证机制:固定场景不变,逐一替换其他五个国家的交规,确保至少在一个国家中,同样的场景会产生不同的正确答案。不满足这一条件的题目会被剔除,因为它们反映的是通用驾驶常识而非特定文化规则。
D RIVE OPD:内化地域知识
评测不是终点。
实验发现,当给模型提供正确的当地交规片段时,准确率大幅提升——尤其是在文化差异最显著的场景中。这表明模型的短板不在于视觉理解,而在于缺乏对当地交规的参数化掌握。
研究团队因此提出了 DRIVE OPD(Drive On-Policy Distillation),一个规则条件化的自蒸馏算法。
核心想法非常优雅:让同一个 VLM 同时扮演教师和学生。教师接收匿名的国家交通手册作为额外输入,学生只能看到场景和问题本身。学生沿着自己采样的推理路径进行训练,目标是最小化自身输出分布与教师输出的 KL 散度。
关键设计在于,手册中所有国家的名称都被替换为“这个国家”的占位符——教师获得的是纯粹的规则知识,而非一个可以直接查表的国名标签。这确保了学生必须在训练过程中将地域知识真正吸收进模型参数,而不能依赖外部检索。
实验揭示了什么
研究团队在 GEO DRIVE -BENCH 上评测了 九款主流开源 VLM,包括 LLaVA-1.6-7B、Qwen2.5-VL-7B、Qwen3-VL-8B、InternVL3-8B、InternVL3.5-8B、Llama-3.2-11B-Vision 和 Gemma3-12B,覆盖了不同的视觉编码器、语言骨架和训练配方。
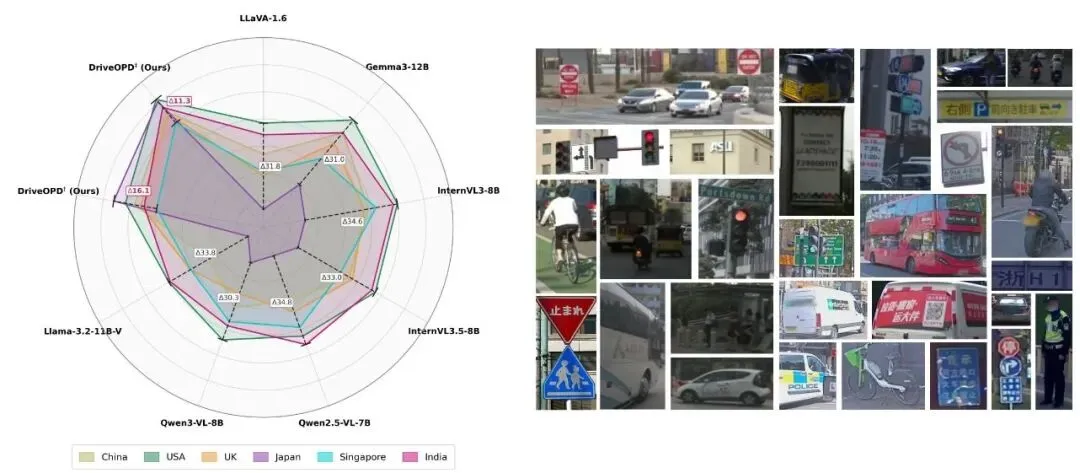
第一项发现令人警醒:所有开源 VLM 都表现出显著的国家间不平衡。
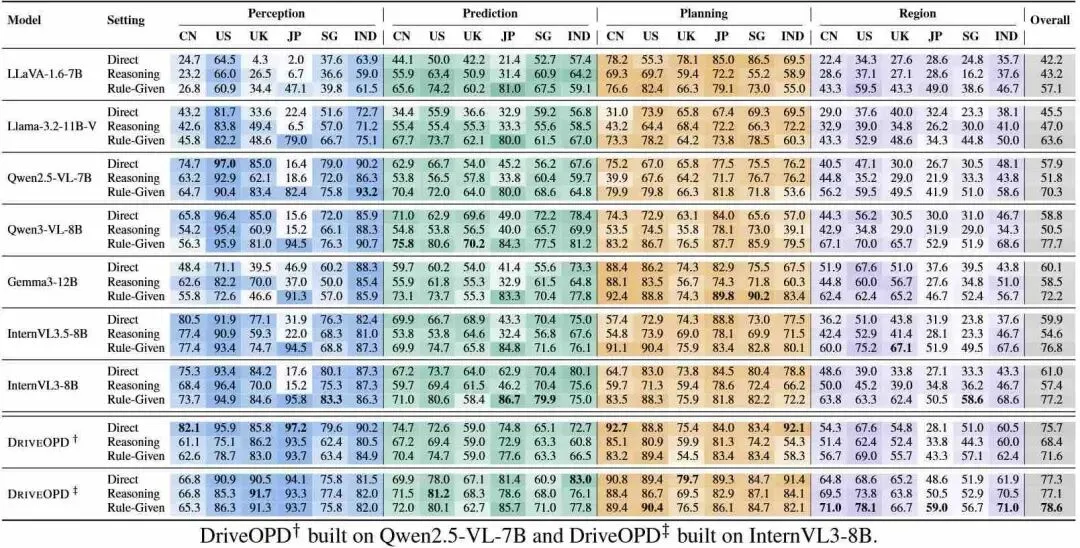
以 Qwen2.5-VL-7B 在直接提示设置下的表现为例——美国感知任务准确率高达 97.0%,日本却断崖式跌到 16.4%。Qwen3-VL-8B 亦然,美日之间 96.4% 与 15.6% 的差距触目惊心。
跨国家准确率的标准差整体落在 8% 到 12% 之间。模型不是均匀失败——它们在自己预训练数据偏好的区域表现尚可,在文化特征截然不同的区域则几乎失效。
第二项发现定位了瓶颈所在。
当研究团队将正确的交规片段作为上下文提供给模型时,日本感知任务的准确率从 16.4% 飙升至 82.4%(Qwen2.5-VL-7B),甚至达到 95.8%(InternVL3-8B)。这表明模型其实看到了场景中的关键视觉线索——比如日本独有的倒三角停止标志——但未能将其与正确的当地规则建立起关联。
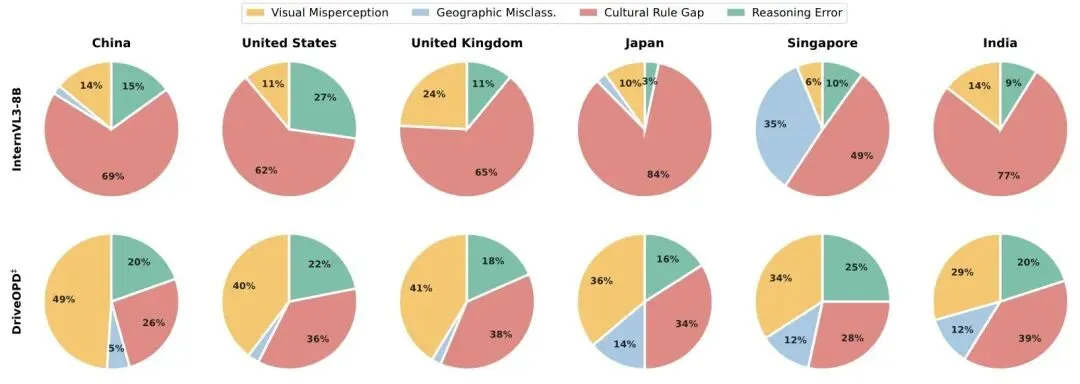
错误分析进一步证实这一判断。InternVL3-8B 在日本和印度的采样错误中,文化规则缺口分别占 84% 和 77%——模型识别出了场景,却套用了错误的规则。
有趣的是,自由形式的思维链推理并非良药。Qwen3-VL-8B 在英国规划任务上原本直接回答准确率 63.1%,加入推理链条后反而暴跌至 35.8%。研究团队认为,缺乏正确规则锚定的无约束推理,反而放大了模型预训练中积累的错误先验。
第三项发现指向解决方案。
DRIVE OPD 在 Qwen2.5-VL-7B 上的总体准确率从 57.9% 提升至 75.7%,InternVL3-8B 从 61.0% 提升至 77.3%。更关键的是,跨国家标准差从 8-12% 锐减至 5% 以下。
尤其值得注意,DRIVE OPD 在直接提示下达到了与基座模型在“规则给定”条件下相当甚至更优的表现——说明区域知识被真正内化进模型参数,不再依赖推理时的外部规则输入。
消融实验也颇具启发性。基座模型在被给予错误规则时准确率骤降,表明它们倾向于将提示中的规则当作权威遵从,而非与场景进行交叉验证。DRIVE OPD 在错误规则条件下的下降幅度则明显更小——内化后的知识提供了稳定的先验,不易被噪声覆盖。
案例分析:学校标志的文化密码
论文展示了一个生动的例子。
面对“该国用什么格式的标志警示学校区域”这道题,InternVL3-8B 能准确推断出日本(通过日文文字)、英国(通过街道布局)、印度(通过机动三轮车)和中国(通过车牌上的汉字)。
但在规则应用环节,它却对四个国家都套用了“黄色菱形”模板——这恰好是美国的规范。
日本使用红边三角板,英国同样是红边三角,中国是黄底黑边三角形,只有美国使用黄色的五边形荧光黄绿标志。模型的“认知”和“行动”之间出现了系统性断裂。
DRIVE OPD 训练后,这一断裂被大幅弥合。模型开始准确调用各国的 S18 手册条目——日本的红边三角、英国的红边三角、美国的五边形、印度的红边三角儿童标志。
从评测到部署的路径
GEO DRIVE -B ENCH 目前覆盖六个国家,受限于公开驾驶数据集的可用性。评估形式为选择题,尚未直接测量低级别的驾驶规划行为。
但这项工作的意义远不止于基准本身。
它揭示了一个在 VLM 发展中容易被忽视的结构性问题:表面能力的聚合得分可能掩盖深层的区域盲点。一个在美国和新加坡达到 90% 以上准确率的模型,可能在日本的同一类任务上只剩不到 20%——如果只看总分,这个致命的短板永远不会暴露。
研究团队通过 GEO DRIVE -B ENCH 和 DRIVE OPD 证明了两件事:一是这种文化性规则推理缺失在现有模型中普遍存在且可以通过精心设计的数据诊断出来,二是通过规则条件化的自蒸馏,这种能力可以在一定程度上被内化进模型参数。
对于正在推动 VLM 驾驶系统走向多国部署的从业者来说,这是一条值得认真对待的技术路径。那些看不见的、藏在交通标志和车道线背后的文化规则,正在成为决定系统能否真正“走出去”的关键变量。




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
