世界模型时代下的自动驾驶:为什么未来的核心可能不是激光雷达,而是智能本身?
世界模型时代下的自动驾驶:为什么未来的核心可能不是激光雷达,而是智能本身?
当前自动驾驶领域存在两条主要技术路线:一条是以Tesla FSD为代表的“纯视觉+端到端神经网络+世界模型”路线;另一条是以Waymo等公司为代表的“激光雷达+毫米波雷达+多传感器融合”路线。从技术发展的长期趋势来看,决定无人驾驶最终能否实现的关键,可能不是传感器数量,而是人工智能是否具备足够强大的世界模型能力。
一、激光雷达解决的是“看见”,世界模型解决的是“理解”
激光雷达最大的优势是能够精确测量距离和构建三维空间信息,它解决的是“前方有什么、距离多远”的问题。但自动驾驶真正困难的部分并非感知,而是理解和预测。
例如,激光雷达能够发现前方有一个物体,却无法判断这个物体是塑料袋、行人还是即将横穿马路的小孩。真正决定驾驶行为的不是测量结果,而是对未来的预测能力。
世界模型则不同。它不仅识别物体,还能够理解环境、推测因果关系、预测未来变化。例如看到校车停下,即使看不到孩子,也会提前减速,因为系统能够预测孩子可能突然出现。这种能力才是接近人类驾驶本质的能力。
二、多传感器融合可能提高感知精度,却增加系统复杂度
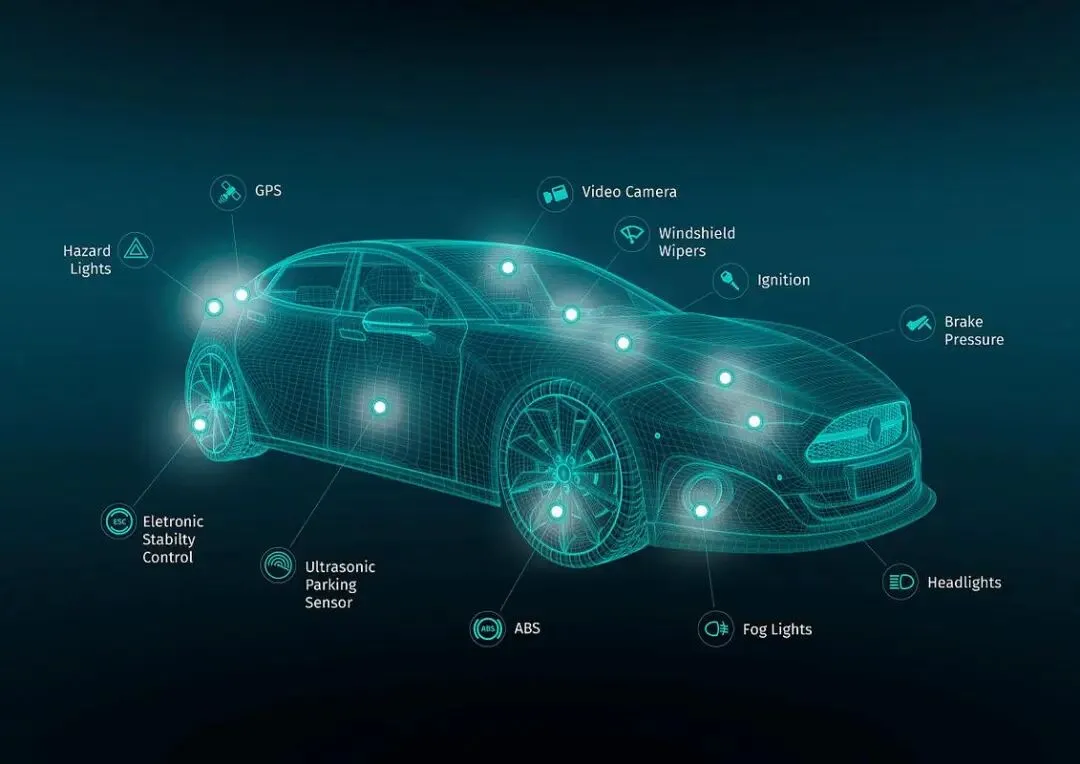
激光雷达、毫米波雷达和摄像头同时工作时,需要进行复杂的传感器融合。
系统必须解决:
然后才能进入决策阶段。
从人工智能发展历史来看,统一输入往往优于复杂融合。例如大语言模型之所以成功,很重要的原因是采用统一的Token体系,而不是为不同知识建立不同规则系统。
Tesla的逻辑也是如此:既然人类驾驶主要依靠视觉,那么让神经网络直接从视频学习三维空间、速度、运动规律和驾驶决策,可能比人为设计复杂的多传感器融合系统更有效。
自动驾驶可以分为四个层次:
1. 传感器——看见世界;
2. 感知系统——识别世界;
3. 世界模型——理解世界;
4. 决策规划——预测未来并采取行动。
激光雷达属于第一层能力,而世界模型属于第三层能力。
未来无人驾驶最大的挑战并不是获取更多信息,而是如何理解信息、预测风险和处理长尾场景。因此,世界模型决定的是自动驾驶的上限,而传感器更多决定系统的基础能力。
未来AI的发展越来越依赖海量数据训练。
Tesla拥有数百万辆汽车每天产生的视频数据,这些真实世界数据能够持续训练视觉模型和世界模型。
相比之下,激光雷达成本高、部署规模有限、数据量远远小于视觉数据。
如果未来自动驾驶的发展路径类似于大模型的发展路径,那么决定竞争力的核心将是数据规模和模型能力,而不是单个传感器的精度。
Waymo等公司并非不重视世界模型,而是认为现实世界存在大量极端情况:
* 暴雨;
* 暴雪;
* 浓雾;
* 夜间无照明道路;
* 强逆光环境。
在这些场景下,视觉系统可能退化,而激光雷达能够提供额外的安全冗余。
因此,多传感器路线的优势主要体现在短期安全性和监管认可度上。
从长期技术趋势看,无人驾驶最终解决的不是“感知问题”,而是“智能问题”。激光雷达和毫米波雷达能够帮助系统更准确地看见世界,但无法直接赋予系统理解世界、预测未来和进行复杂推理的能力。
未来真正决定无人驾驶水平的核心,很可能是“视觉感知+世界模型+端到端神经网络”的组合。随着世界模型不断接近人类认知能力,传感器的重要性将逐渐下降,而智能的重要性将持续上升。因此,世界模型决定无人驾驶的上限,激光雷达更多决定无人驾驶的安全下限。从更长远的角度看,纯视觉与世界模型深度融合的路线,确实更有可能成为通向真正通用无人驾驶的终极方向。
作者提示:文章作者系 贾君新-深圳市新恒利达资本管理有限公司董事长,任何复制、转发、引用请注明出处。
































 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
