作者 | Xinglong Sun, Kevin Xie, Jenny Schmalfuss, Despoina Paschalidou, Xiuming Zhang, Sanja Fidler, Kashyap Chitta, Jose M. Alvarez
机构 | NVIDIA
论文标题 | DriveJudge: Rethinking Autonomous Driving Evaluation with Vision-Language Models
论文版本 | arXiv:2606.17362v1
关键词 | 自动驾驶评测 / Vision-Language Model / Rule-grounded Evaluation / Human Alignment / Trajectory Preference前言
端到端自动驾驶越来越强以后,一个更棘手的问题会浮出来:怎么判断一个驾驶行为到底好不好?
传统指标比如 EPDMS 很清楚、可复现、可解释,但它们经常把规则当成绝对约束。比如车辆为了绕过施工区域短暂压线,规则指标可能直接扣分;但人类会理解这是合理避让。反过来,直接让 VLM 打分虽然能看上下文,但它容易给出含糊判断,也缺少几何和物理 grounding。
DriveJudge 的切入点就是这两者之间:让 VLM 决定哪些规则在当前场景下应该被启用,再用确定性规则函数给出可解释分数。
这篇论文真正重要的不是“用 VLM 当裁判”,而是给自动驾驶评价加了一层上下文 gating:规则仍然在,但规则是否适用,要由场景决定。
资源链接
- arXiv 页面:arXiv:2606.17362v1
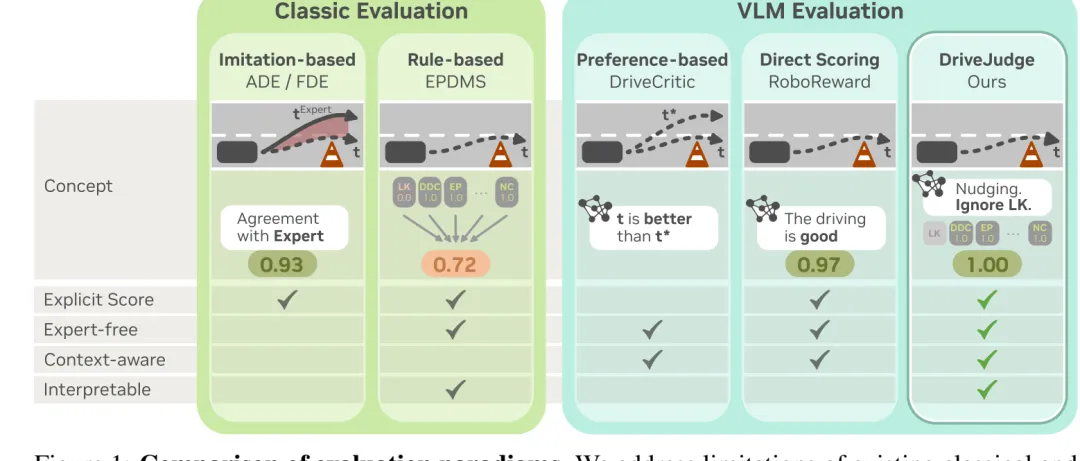 图 1:评价范式对比。传统规则指标有显式分数和可解释性,但缺少上下文;直接 VLM 打分有上下文理解,但输出容易模糊。DriveJudge 让 VLM 判断规则是否适用,再调用规则函数给出分数。
图 1:评价范式对比。传统规则指标有显式分数和可解释性,但缺少上下文;直接 VLM 打分有上下文理解,但输出容易模糊。DriveJudge 让 VLM 判断规则是否适用,再调用规则函数给出分数。评价为什么比规划还难
规划模型输出一条轨迹,评价指标必须回答一个很细的问题:这条轨迹在这个具体场景里是否合理。难点在于,驾驶质量高度依赖上下文。同样是 lane keeping,被动压线可能是违规,也可能是绕障、让行、施工绕行里的合理动作。
传统 rule-based metric 的优点是确定、可解释、能落到物理量;缺点是缺乏场景语义。直接 VLM scoring 的优点是能读图、能理解场景;缺点是空间精度、规则一致性和输出稳定性都不够强。
DriveJudge 把问题拆成两步:VLM 做上下文理解,规则函数做物理计算。也就是说,VLM 不直接拍脑袋给 0.97 分,而是判断 lane keeping、ego progress、comfort、safety buffer 等规则在当前 clip 中是否该参与评分。
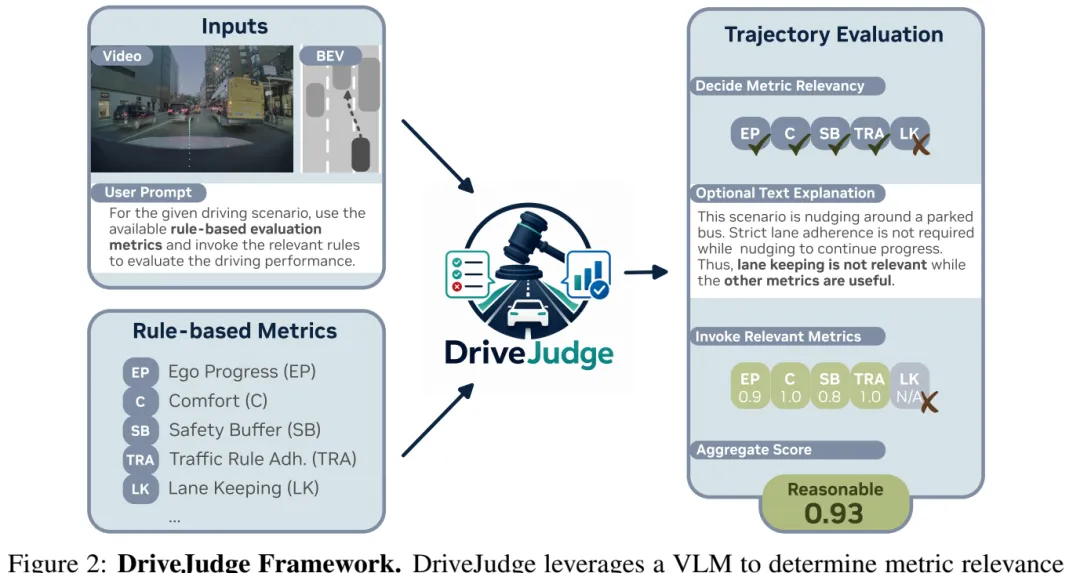 图 2:DriveJudge 框架。输入包括视频/BEV、用户提示和规则集合;VLM 先判断哪些 metric relevant,再调用相关规则,最后聚合成上下文感知的驾驶质量分数。
图 2:DriveJudge 框架。输入包括视频/BEV、用户提示和规则集合;VLM 先判断哪些 metric relevant,再调用相关规则,最后聚合成上下文感知的驾驶质量分数。核心机制:给规则加一个上下文开关
论文把规则集合写成 M = {f1, f2, ..., fM},每条规则都会产生一个 compliance score。传统做法是把所有规则按固定权重加起来,相当于默认所有规则在所有场景里都同等重要。
DriveJudge 多了一步 gating:模型根据场景预测 g_m,表示第 m 条规则是否相关。最终得分可以理解为:
DriveJudge score = 只对当前场景相关的规则分数做加权聚合。VLM 决定“该不该算”,规则函数决定“算出来是多少”。这个设计很适合自动驾驶,因为评价既需要常识,也需要几何。常识负责判断“施工绕行时压线是否可以接受”,几何负责判断“是否真的进入对向车道、是否接近碰撞、是否有足够 progress”。
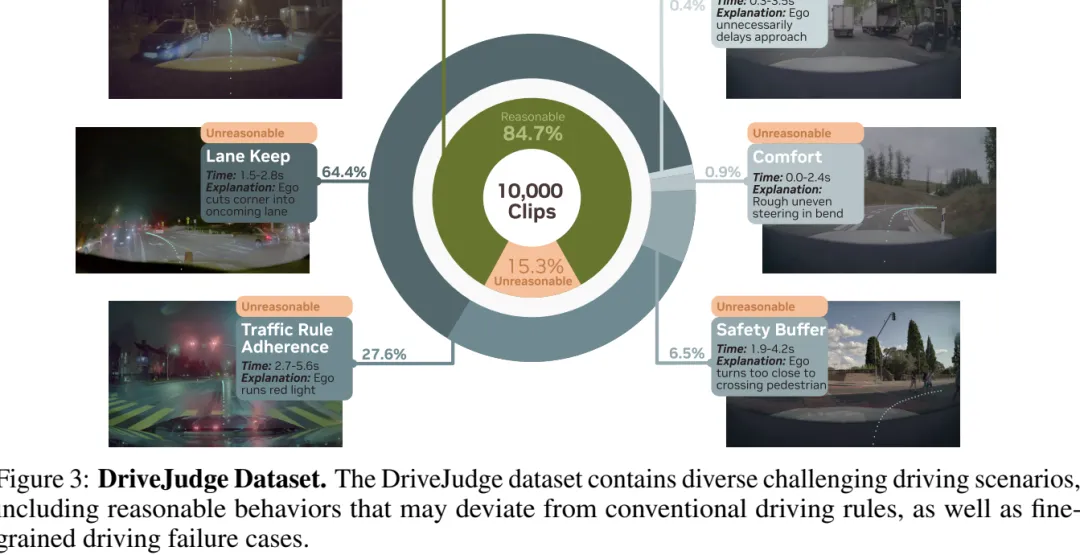 图 3:DriveJudge 数据集。数据覆盖 10,000 个 clips,其中既有偏离常规规则但合理的行为,也有细粒度驾驶失败案例。
图 3:DriveJudge 数据集。数据覆盖 10,000 个 clips,其中既有偏离常规规则但合理的行为,也有细粒度驾驶失败案例。数据集:专门收困难驾驶评价样本
DriveJudge 不是只提出一个打分器,还构建了一个评价数据集。论文称数据包含 33,577 个 challenging driving samples,并对驾驶行为在特定场景下是否 reasonable 做人工标注。
数据集里有两类很关键的样本:一类是违反常规规则但实际合理的行为,比如为了避障短暂偏离车道;另一类是细粒度失败,比如 ego progress 不足、comfort 差、lane keep 失败、traffic rule adherence 问题等。
这正好对应自动驾驶评测里的长尾问题:如果评价数据全是普通直行或正常转弯,规则指标足够好;但一旦进入施工、拥堵、绕障、异常交通参与者等场景,指标就必须理解“为什么这么开”。
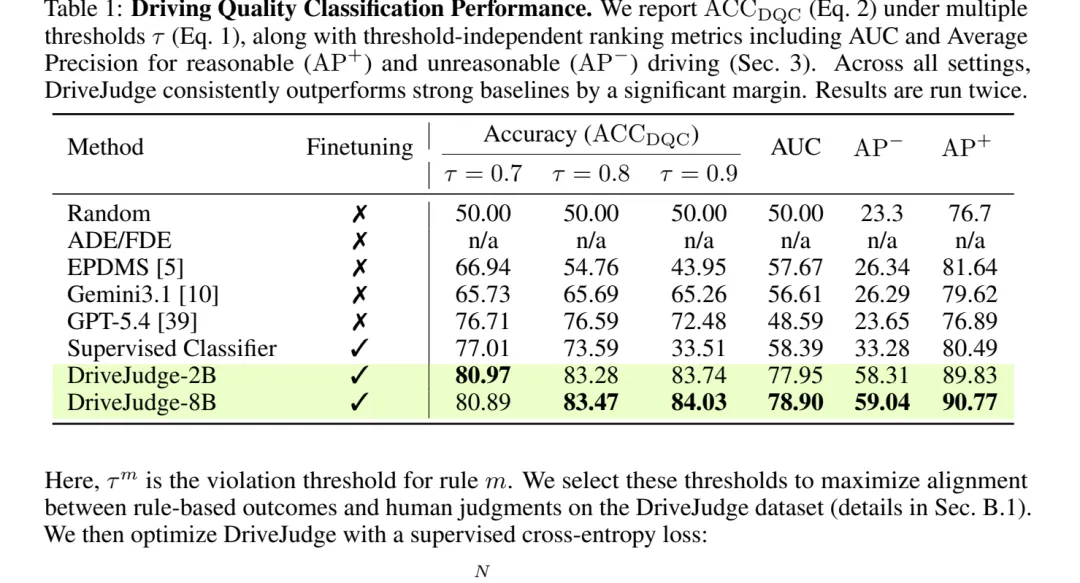 表 1:Driving Quality Classification 结果。DriveJudge-8B 在 AUC 上达到 78.90,相比 EPDMS 的 57.67 提升 21.23。
表 1:Driving Quality Classification 结果。DriveJudge-8B 在 AUC 上达到 78.90,相比 EPDMS 的 57.67 提升 21.23。任务一:判断驾驶行为质量
Driving Quality Classification 要判断单条轨迹在当前场景里是否 reasonable。结果上,DriveJudge-8B 的 AUC 达到 78.90,DriveJudge-2B 为 77.95;相比 EPDMS 的 57.67,8B 版本提升 21.23 AUC。
GPT-5.4 和 Gemini 3.1 在 threshold accuracy 上看起来不错,但 AUC 反而不强,说明直接 VLM 打分对排序和稳定区分并不可靠。DriveJudge 的优势来自两点:VLM 负责上下文,规则负责物理和空间细节。
这个结果可以解读为:自动驾驶评价不是单纯的视觉问答。只让 VLM 说“开得好不好”不够,必须把规则工具接进来,让判断可落地、可复查。 图 4、表 2 与图 5:定性对比和 Trajectory Preference Selection。DriveJudge-8B 达到 82.83% accuracy,比 DriveCritic 的 76.33% 更接近人类偏好。
图 4、表 2 与图 5:定性对比和 Trajectory Preference Selection。DriveJudge-8B 达到 82.83% accuracy,比 DriveCritic 的 76.33% 更接近人类偏好。任务二:在两条轨迹中选更好的一条
Trajectory Preference Selection 更接近人类评测:给两条候选轨迹,选择更符合人类偏好的一条。DriveJudge-8B 达到 82.83% accuracy,DriveJudge-2B 为 80.63%,超过 DriveCritic 的 76.33%。
论文里的定性案例很典型:DriveCritic 会因为弱空间 grounding 误判前方是否有 blocking vehicle,或者误以为两条轨迹都满足 lane keeping;DriveJudge 通过显式规则调用,能把 traffic condition 和轨迹几何结合起来。
这部分说明 DriveJudge 不是只会给单条轨迹打分,也能做 pairwise preference。对于后续把它作为 reward model 或自动评测器,这一点很重要。
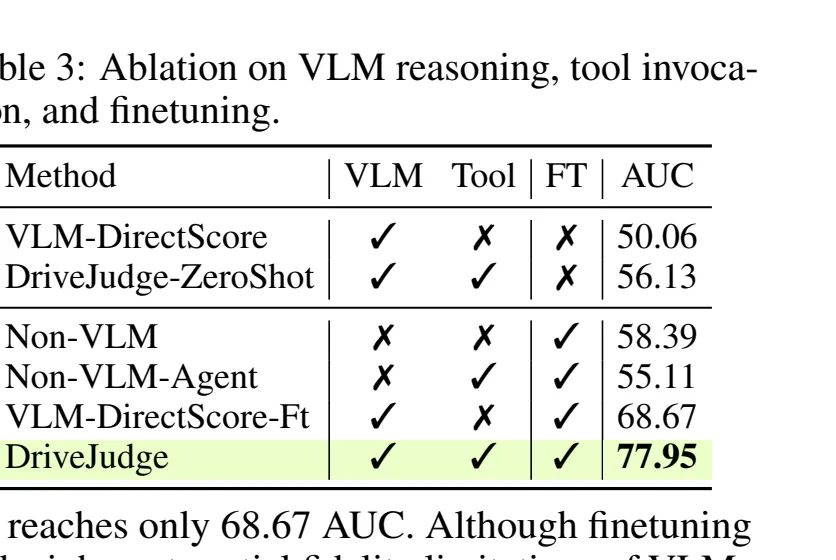 表 3:消融实验。仅 VLM 直接打分效果有限;加入 rule-grounded tool invocation 并 finetune 后,AUC 提升到 77.95。
表 3:消融实验。仅 VLM 直接打分效果有限;加入 rule-grounded tool invocation 并 finetune 后,AUC 提升到 77.95。消融:VLM、规则工具、finetuning 缺一不可
Table 3 的信号很清楚:VLM-DirectScore 零样本只有 50.06 AUC;加入工具调用的 DriveJudge-ZeroShot 到 56.13;finetune 后 DirectScore 到 68.67,而完整 DriveJudge 到 77.95。
这说明三件事:
- 只有 VLM reasoning,不足以解决空间和物理精度问题。
- 数据和 finetuning 能把“什么时候调用什么规则”学得更稳。
DriveJudge 的核心不是把 VLM 变成万能裁判,而是让 VLM 学会当“规则调度器”。它决定哪些工具该上场,真正的数值评分仍由确定性 metric 完成。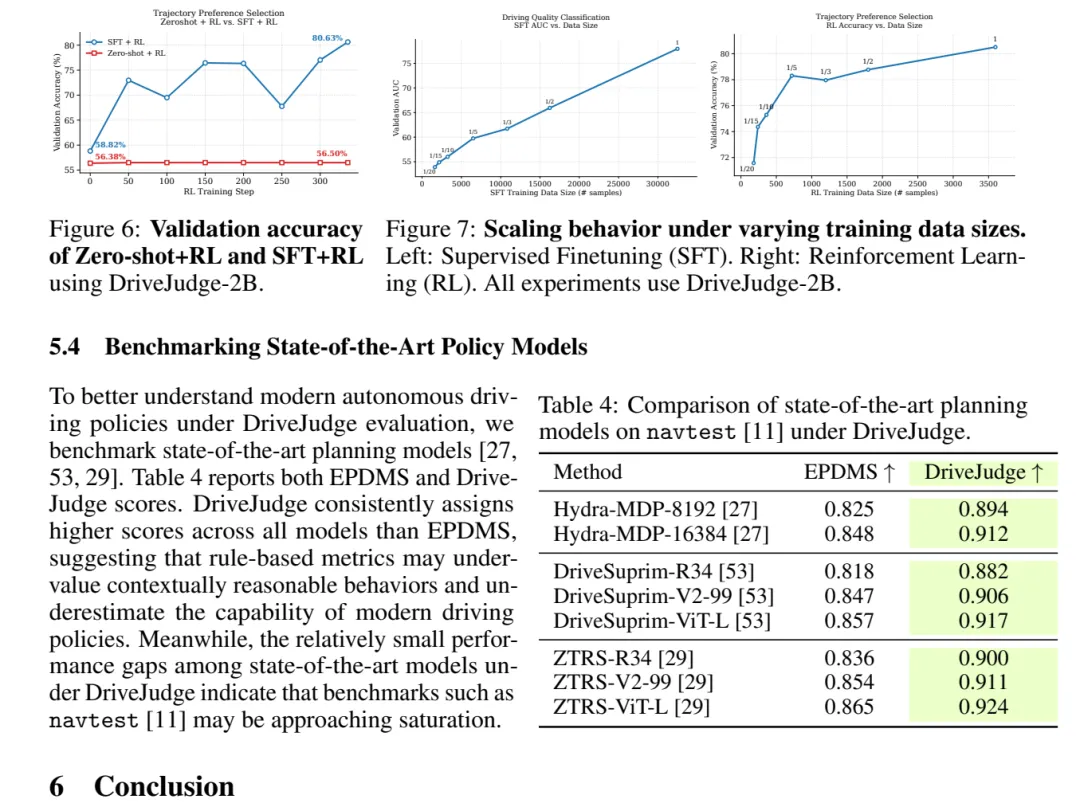 图 6/7 与表 4:SFT/RL 训练曲线和规划模型评价。DriveJudge 对多种 state-of-the-art planning models 给出比 EPDMS 更高、更上下文友好的分数。
图 6/7 与表 4:SFT/RL 训练曲线和规划模型评价。DriveJudge 对多种 state-of-the-art planning models 给出比 EPDMS 更高、更上下文友好的分数。对现有规划模型的影响
论文还用 DriveJudge 重新评估了一批 state-of-the-art planning models。一个有意思的现象是,DriveJudge 给出的分数普遍高于 EPDMS,这意味着纯规则指标可能低估了某些上下文合理行为。
同时,各强模型在 DriveJudge 下差距并不大,论文据此指出 navtest 这类 benchmark 可能正在接近饱和。这个判断值得关注:当 planner 越来越强,评测指标本身会成为瓶颈。
SFT/RL 曲线也说明,DriveJudge 不能只靠 RL 从零开始学。SFT 提供任务结构和规则调用基础,RL 再进一步优化 preference selection;这和很多 reward model 的训练经验一致。
 图 8:人工标注样例。论文展示了不同场景下为什么某些行为合理或不合理,体现数据集对长尾场景的覆盖。
图 8:人工标注样例。论文展示了不同场景下为什么某些行为合理或不合理,体现数据集对长尾场景的覆盖。边界:它还是开放环评测
论文也明确提到一个限制:DriveJudge 目前主要验证在 open-loop setting,没有做 closed-loop experiments。也就是说,它证明了自己更像人类、更可解释地评价已有轨迹,但还没有证明用它作为在线 reward 训练 policy 一定更安全。
另一个现实问题是,DriveJudge 仍依赖规则集合。如果规则函数没有覆盖某类风险,VLM 也很难凭空获得可验证的物理评分。因此它更像是一个可扩展评测框架,而不是一次性解决所有自动驾驶评价问题。
结论
DriveJudge 的价值在于把自动驾驶评价拆成了两个互补能力:VLM 负责理解场景,规则函数负责给出可解释、物理 grounded 的分数。它既避免了纯规则指标的僵硬,也避免了纯 VLM 打分的含糊。
从行业角度看,这篇论文提醒了一件事:自动驾驶模型越端到端,评价越不能只端到端。真正可用的评测体系,需要既能理解上下文,又能落到可复现的物理规则上。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
