华科 & 小米 DriveLaw:让自动驾驶兼具场景想象力与行驶稳定性
- 2026-07-15 12:50:46

点击上方蓝字加入我们


论文链接:https://arxiv.org/pdf/2512.23421
每天早晚高峰,当你看着路口的自动驾驶测试车在车流中穿梭,是否会好奇:它如何预判下一秒是否有行人横穿、前车是否会变道?又如何根据这些预判规划出安全又高效的路线?
现实中,自动驾驶的“预判”和“决策”往往是“两张皮”:视频生成模块能想象未来场景,却无法将场景中的物理规律、车辆动态等关键信息有效传递给规划模块;规划模块只能基于当下感知做决策,缺乏对未来场景的深度理解。这就导致自动驾驶系统在常规路况下表现尚可,一旦遇到突发状况(比如路口突然冲出的电动车、暴雨天模糊的车道线),就容易“判断失误”,闭环行驶稳定性大打折扣——这正是当前自动驾驶技术的核心痛点。
华中科技大学与小米汽车联合提出的 DriveLaW 方案,彻底打破了这一壁垒。它将视频生成与轨迹规划统一在同一个 latent 空间,让规划模块直接“读懂”视频生成的场景语义,实现高保真场景预测与可靠轨迹规划的天生一致性,在两大核心任务上均创下 SOTA 性能。
一、引言:自动驾驶的“想象力”与“决策力”如何协同?
1. 现有技术的三大局限
当前自动驾驶的世界模型在规划任务中,始终未能实现“预判”与“决策”的深度协同,主要分为三类局限:
「模拟辅助型」:仅用世界模型生成数据或搭建闭环仿真环境,间接指导政策学习,无法将物理理解传递给规划器; 「监督辅助型」:预测未来视觉信号或可行驶区域,为规划提供监督信号,但规划逻辑仍独立于场景预测; 「并行统一型」:虽能同时生成视频和轨迹,但两者是独立输出流,规划轨迹并未基于视频生成的内部特征,存在表征脱节。
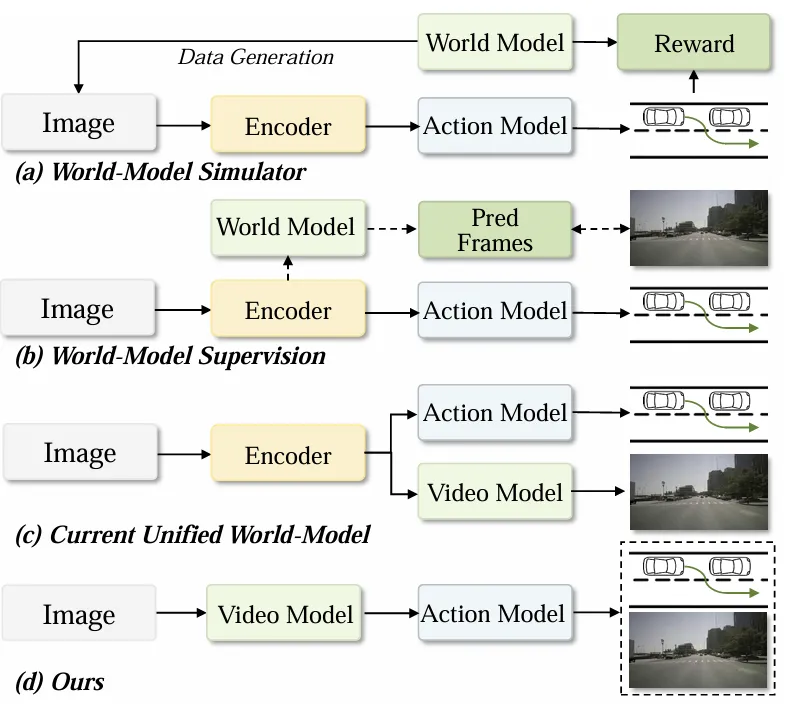
图1所示。不同世界模式范式的比较。
2. DriveLaW的核心突破
DriveLaW 提出“链式联动”范式:将视频生成模块学到的驾驶世界知识(场景语义、车辆动力学、物理规律),通过 latent 特征直接注入规划模块,实现“预测-规划”的端到端协同。这种设计不仅避免了两者的梯度干扰,更确保了生成场景与规划轨迹的一致性,从根源上解决了“想象力”与“决策力”脱节的问题。
二、创新方法详解:DriveLaW的“双核心+三阶段”架构
DriveLaW 由两大核心组件(DriveLaW-Video 视频生成器、DriveLaW-Act 扩散规划器)和一套三阶段渐进式训练策略构成,每个部分都暗藏精妙设计:
1. 核心组件一:DriveLaW-Video——高保真时空世界生成器
负责“精准想象未来”,生成高保真、时序一致的驾驶场景视频,同时输出富含场景信息的 latent 特征。
(1)时空VAE:极致压缩+因果编码
采用高压缩比时空VAE,将视频序列编码为 32×32×8 时空分辨率、128 通道的 latent 向量,像素与token比达 1:8192,总压缩比 1:192(远超常规的 1:48 或 1:96)。这种极致压缩让模型在有限算力下,能处理更长时间跨度的场景(如交通灯切换、长距离车道保持)。
编码器采用 3D 因果卷积,确保每个时间步只依赖过去和当前帧,避免未来信息泄露,完美契合自动驾驶的时序预测需求。
(2)混合解码策略:兼顾效率与细节
不同于传统纯 latent 空间去噪,DriveLaW-Video 采用“latent 去噪+像素级精修”混合策略: 在整流流调度后期(t=t₁),通过 VAE 解码器直接在像素空间完成最终去噪,公式如下:
其中 D 是时间条件去噪解码器,通过像素级损失训练。这种设计无需额外超分模块,就能恢复道路纹理、交通标志反光等高频细节,且仅增加少量计算开销。
(3)视频Transformer:全时空建模+灵活条件注入
采用基于 PixArt-α 改进的 3D Transformer,包含 28 个自注意力+交叉注意力块,通过:
自注意力:建模全局时空依赖(如车辆与车道线的相对位置变化); 交叉注意力:融合导航指令、视觉线索等任务特定条件; 旋转位置编码(RoPE):确保不同分辨率、帧率下的一致性。
(4)噪声重注入机制:解决高速场景失真
高速行驶时,长距离运动易导致视频模糊、物体结构不一致、出现伪影(如图3所示)。DriveLaW-Video 针对性设计噪声重注入机制:
每个去噪步骤前,先预测干净 latent ,并解码为像素图像 ; 对图像做灰度转换和拉普拉斯滤波,生成高频区域掩码 M: 仅向高频区域注入可控噪声,迫使模型主动生成细节而非平滑处理:
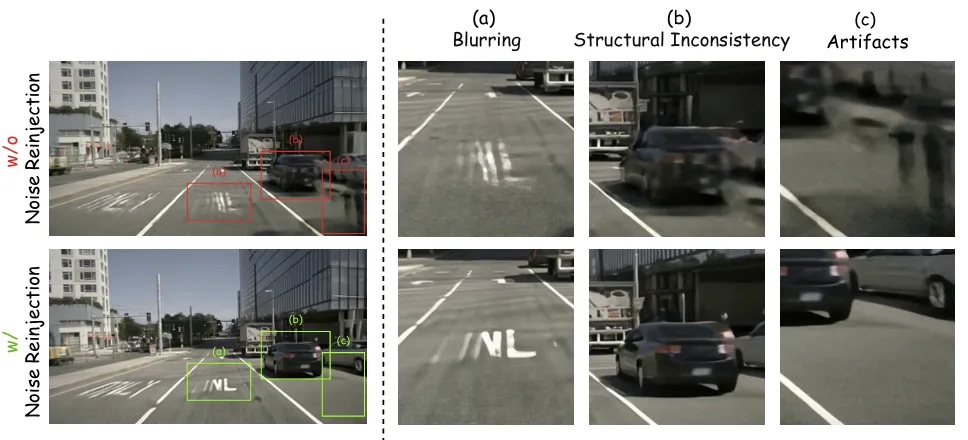
图3。通过噪声重注入恢复结构和时间一致性。
2. 核心组件二:DriveLaW-Act——基于扩散模型的轨迹规划器
负责“基于想象做决策”,以 DriveLaW-Video 的 latent 特征为条件,生成平滑、可靠的轨迹。
(1)输入编码与条件注入
动作编码:将带噪声的动作 编码为 ;上下文编码:将 ego 车辆状态(速度、姿态)和高层指令(直行、转弯)编码为; 视频 latent 注入:缓存 Video-DiT 第一阶段去噪的所有 Transformer 块特征 ,作为规划器的交叉注意力条件。
(2)扩散规划与流匹配训练
采用轻量级扩散 Transformer(133M 参数),通过流匹配目标训练,确保轨迹平滑性:
模型预测 2Hz 轨迹点,覆盖未来 4秒规划 horizon,且推理时无需解码视频,仅在 latent 空间运算,效率极高。
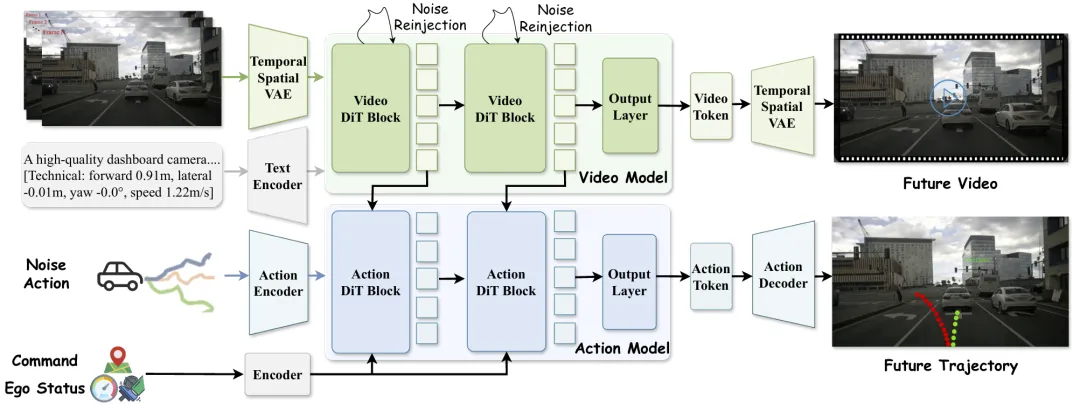
图2。DriveLaW的整体架构概述。
3. 三阶段渐进式训练:平衡生成质量与规划稳定性
为解决高保真视频生成与实时稳定规划的内在矛盾,DriveLaW 设计三阶段训练策略:
第一阶段:低分辨率(740×352)+长序列(121帧)训练,优先学习长时域运动模式(如车道保持、转弯、速度调节); 第二阶段:高分辨率(1280×704)+短序列(25帧)训练,提升空间细节保真度(如车道线、车辆轮廓); 第三阶段:将 Video-DiT 的 latent 特征接入 DriveLaW-Act,联合训练轨迹规划,实现“生成-规划”协同。
三、实验效果验证:双任务均创SOTA
论文在 nuScenes(视频生成)和 NAVSIM(轨迹规划)两大权威基准上做了全面验证,结果远超现有方法。
1. 视频生成:刷新FID和FVD纪录
在 nuScenes 单视角视频生成任务中,DriveLaW 以显著优势超越所有基线方法,FID 降低 33.3%,FVD 降低 1.8%:

表1。NuScenes验证集上视频生成的定量评价。
定性效果上,与SOTA方法 Epona 相比,DriveLaW 生成的视频:①车辆细节更清晰、结构更稳定;②行人形状完整可识别;③不易察觉的物体(如黄色货车)能准确还原位置和外观(如图4所示)。

图4。与最先进的驾驶世界模型的定性比较。
2. 轨迹规划:NAVSIM基准新纪录
在 NAVSIM 闭环规划任务中,DriveLaW 无需强化学习(RL)后训练或评分器后处理,PDMS 得分达 89.1,超越所有传统端到端方法和世界模型方法:
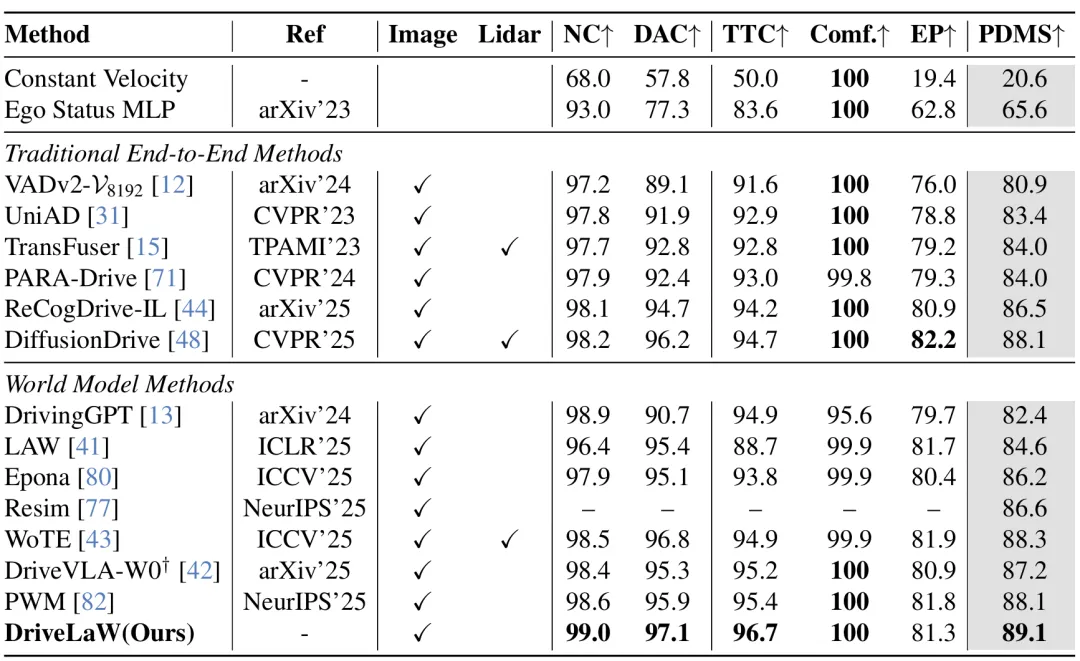
表2。使用闭环指标的NAVSIM Navtest性能比较。
3. 关键 ablation 实验:验证核心设计有效性
视频预训练规模:7.6M 预训练样本比从零训练提升 3.2 PDMS,证明大规模视频学习的物理规律对规划的价值(表3); 表征对比:视频 latent 比 BEV 特征、VLM 隐藏态分别提升 5.0、2.6 PDMS,且可视化显示视频 latent 语义更连贯、空间结构更清晰(表4、图5); 去噪步骤选择:第一阶段去噪的 latent 作为条件最优,后期去噪 latent 因冗余信息增多导致性能下降(表5); 三阶段训练:缺失任一阶段都会导致 FID/FVD 上升,证明训练策略的合理性(表6); 噪声重注入:启用后 FID 从 6.1 降至 4.6,FVD 从 102.1 降至 81.3,有效解决高速场景失真(表8)。
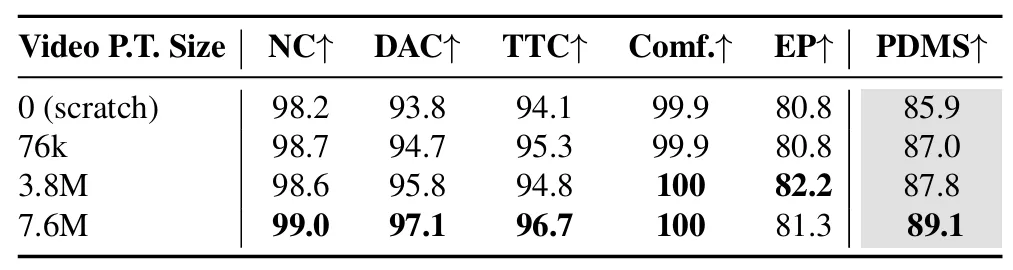
表3。缩放视频预训练改进了NAVSIM Navtest的规划。
4. 效率验证:实时性优势显著
在单 NVIDIA 4090 GPU 上,DriveLaW 生成 1024×512 分辨率视频仅需 0.18s/帧,1280×704 分辨率也仅需 0.39s/帧,是 Epona(0.88s/帧)的 2 倍以上(表7)。
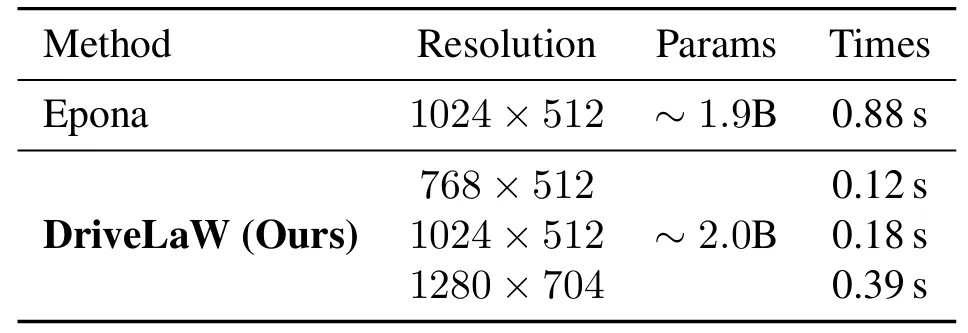
表7所示。在单个NVIDIA 4090 GPU上每帧视频生成速度,30 DiT采样步骤。
四、总结思考:自动驾驶“端到端”的新方向
DriveLaW 的核心贡献,在于首次实现了视频生成与轨迹规划的“深度协同”——不是简单的并行输出,而是让规划模块直接复用视频生成学到的场景语义和物理规律,从根源上提升了自动驾驶的泛化能力和闭环稳定性。
其关键启示在于:大规模驾驶视频中蕴含的物理规律、场景动态,是比 BEV、VLM 更适合自动驾驶规划的表征资源。通过“链式联动”架构和三阶段训练,既能保留高保真视频生成的优势,又能让规划模块高效利用这些宝贵的“世界知识”。
未来,随着视频生成模型能力的进一步提升,以及多模态信息(如 LiDAR、地图)的融合,DriveLaW 范式有望让自动驾驶系统在更复杂的长尾场景中,具备接近人类司机的“预判-决策”能力,推动端到端自动驾驶技术的落地。
自动驾驶的终极目标,是比人类更安全。而AD-R1告诉我们:通往这一目标的道路,需要让模型“敢想危险、能懂危险、会避危险”。

END
澳大 & 理想 & 中山等 AD-R1:闭环强化学习框架,让自动驾驶 “预见危险”!
KTH & 科大讯飞 & 南洋理工 SparScene: 用稀疏图让自动驾驶 “看清” 复杂路况,毫秒级搞定千车轨迹!
北京大学 KnowVal:融合知识图谱与价值模型,碰撞率骤降还懂 “人情世故”
港理工 UrbanV2X 多传感器车路协同数据集:3 大场景、含 7 类车载 + 3 类路侧设备,破解城市峡谷自动驾驶定位难题
清华 & 小米 DVGT:让自动驾驶“看”懂3D世界,跨场景通用还超精准
复旦&Nvidia&密歇根 ZTRS:首个纯RL端到端框架,纯奖励驱动闭环
【T-PAMI】浙大&华为&图宾根 HUGSIM:3D 高斯泼溅+闭环仿真,实现实时、超拟真、全闭环的自动驾驶模拟器
中科院&北航&北交UrbanNav:让机器人像人类一样 "City Walk"基于海量网络视频的语言引导城市导航
NVIDIA开源自动驾驶VLA模型Alpamayo-R1:用因果链推理攻克“长尾场景”最后堡垒

分享

收藏

点赞

在看

