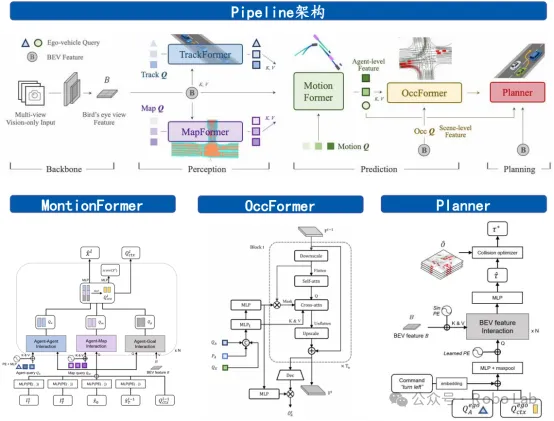
在智驾圈,华为 ADS 3.0 的登场常被比作“暴力美学”向“类人灵魂”的惊险一跃。当全国车主惊叹于问界、享界在窄路博弈中展现出的“老司机”直觉时,一场关于自动驾驶大脑的深层重构正在发生。长期以来,感知层面的堆料已边际递减,真正决定智驾天花板的,是深藏在代码底层的“规控算法(P&C)”。这种从“死板规则”到“端到端博弈”的代际跨越,不仅是华为自研算力的爆发,更是其身后方案商元戎启行(DeepRoute.ai)多年 L4 级算法沉淀的降维输出。今天,我们将以工程化的视角拆解这套封神算法的底层逻辑,看看这位智驾界的“扫地僧”是如何定义 2026 年智驾新标准的。从“看得见”到“走得好”:规控算法重要性凸显
1.1 自动驾驶技术栈回顾:规控最早为什么是“配角”?
在自动驾驶产业早期(特别是 L2–L2+ 辅助驾驶阶段),技术路线的技术重心基本落在了感知系统的性能提升上。这一阶段主机厂和 Tier-1 供应商普遍认为:
“看清楚”才是智能驾驶的第一步,即尽可能准确识别道路上的车辆、行人、标志线等目标;
因此,行业研发资源高度倾向于感知技术,例如摄像头、毫米波雷达、激光雷达的数据融合与分类算法优化;
自动驾驶能否安全运行,很大程度上被定义为感知模块的识别率、召回率和 mAP(mean Average Precision)指标能否达到高标准。
传统的技术栈结构因此被大致认为是:
感知(Perception)——判定场景信息↓预测(Prediction)——判断动态对象未来状态↓规划与控制(Planning & Control)——生成安全、可执行路径↓执行(Actuation)——将路径转为动作
在当时,规控算法往往被视作“感知输出的执行器”,因为多数场景仅限于高速公路或封闭测试场地,这类场景下行为决策较简单,车辆只需安全跟随、变道或超车即可,不需要复杂的博弈逻辑和策略推演。
行业背景原因也决定了这一阶段规控的“配角”定位:
(1)传感器成本高早期多传感器(多激光雷达 + 多摄像头)的方案,会让整车成本大幅上升;而汽车行业对成本敏感,导致不少厂商仍试图通过视觉+雷达的混合方案压低价格。
(2)车载算力受限到 2025 年数据表明,车规级 SoC(系统级芯片)算力仍不足以支撑复杂的实时规划与博弈推理模型——因此很多算法团队把可支撑的算力优先用于 感知深度网络推理。
(3)场景单一且相对简单早期高速路的运行场景相对规则,障碍物和干扰较少,规控算法围绕 longitudinal control(纵向控制)和 lateral control(横向控制)即可满足大多数需求,这也让规划控制在整体技术栈中并未获得足够重视。
因此,在 2020–2022 年间,主流报告和统计也几乎都聚焦在感知性能的提升上,而对规划控制的细粒度指标关注较少。
1.2 技术拐点:为什么2023–2026年,规控开始决定上限?
1.2.1 城市场景成为主战场
1.2.2 行业共识变化
从 2023 年开始,自动驾驶行业进入了一个非常清晰的技术分水岭期:过去单一强调感知能力提升的增长曲线开始出现边际收益递减,而 规划与控制(Planning & Control)能力成为体验好坏的核心决定因素。
1.2.1 城市场景成为主战场——复杂性暴涨
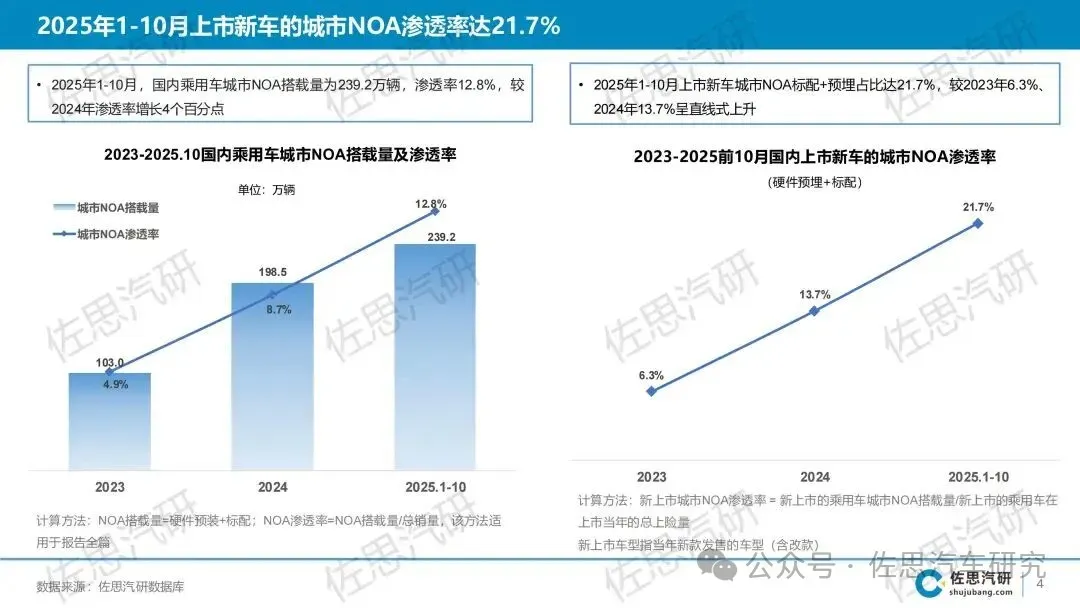
根据第三方智能驾驶产业数据,截至 2025 年底,国内乘用车城市NOA(Navigate on Autopilot)功能装车量达 239.2 万辆,同比增长 62.8%,标志着城市级自动驾驶场景已从试验阶段进入规模化落地阶段。
城市道路比高速更难:
这也反映在主流 2025 年城市 NOA 试驾报告 中:各车企在秋季路测中体现出显著差异,尤其是在复杂路口与场景切换中的接管频率、判断时机与行为连贯性上出现明显分层,这充分说明感知之外的行为决策层正在成为体验差异的主要来源。
1.2.2 感知性能边际收益递减
感知技术(例如目标识别精度、召回率、mAP 指标)的提升对自动驾驶系统的作用在 2023–2025 年依然重要,但在城市高阶场景中,这类性能提升已不再显著改善用户体验。虽然多传感器融合方案在静态物体识别上表现优异(例如激光雷达 + 摄像头组合的环境感知),但当交通参与者行为不可预测时,静态感知指标已无法评价系统的决策水准。
可以想象,高精度感知系统仍然需要对复杂场景做出安全与合理的行为选择,包括:
这些行为是规控层决策逻辑的直接输出。因此,感知堆叠再好,如果无法产生正确行为,又或行为反应过度保守(例如在安全边界内“犹豫不前”),对用户体验的价值实际上有限。
1.2.3 用户抱怨集中在规控层而非感知层
最新的用户体验调查报告指出:智能驾驶遇到最多抱怨的并非识别错误,而是车辆行为上的不自然或不稳定,具体表现为:
犹豫不前:车辆在复杂交通断点反复停顿,无法顺利通过路口
急刹车:识别到潜在风险时反应过度,导致急减速影响舒适性
不敢走:过度规避风险,安全边界设定过高影响通行效率
例如 2025 年的全场景智驾用户体验调查显示,尽管 71% 的用户认可智能驾驶功能可以减轻驾驶疲劳,但在城区复杂场景下的评价仅得分最低(安全性 NSR 27%),其中就包括大量关于 急刹、犹豫与不敢走 的投诉。这说明即便感知“看得清楚”,却无法使系统在行为上做出“像好司机一样的决策”。
1.2.4 行业共识的转变:从“看得见”走向“走得好”
2023–2026 年间,自动驾驶研发团队、主机厂与调查机构达成了几乎一致的行业认识:
在复杂城市环境中,单靠提高感知指标无法显著提升用户体验;真正决定体验上限的是如何将感知结果转化为稳定、合理、连续的行为策略。(行业专家研判)
比如在最新的主流试驾报告中,车企规划控制层的表现已经成为评价车辆智能驾驶技术水平的重要维度,与感知硬件选择(激光雷达 vs 纯视觉)同等重要。
总结:➡️ 从 2023 年开始,自动驾驶的增长路径从“感知 → 体验”的线性增强模式,向“规划与控制决定体验上限”的多维优化转变;➡️ 城市场景的复杂性、用户反馈中的核心痛点,以及 NOA 规模化落地的数据变化,共同证明了规控层在整体系统表现中的核心作用。
这就是为什么现在再谈自动驾驶技术,绝不能只看“能不能识别”,而一定要问:“在复杂交通博弈下,它能不能做出正确、连贯与人性化的决策?”
规控算法好不好,不能只看论文
2.1 工程维度:主机厂如何“量化”规控算法?
2.1.1 核心工程指标示例:
2.1.2 项目流程中的规控评测节点:
对汽车企业和自动驾驶研发团队来说,规控算法不是空洞的概念,它必须被工程化地量化、测试、验证和比较。主机厂在项目流程中设计了一整套指标体系,用来评估自动驾驶车辆在真实道路与仿真环境中决策规划的能力。这不仅关系到安全,还涉及乘客的舒适度、驾驶体验、效率和法规合规性。
2.1.1 核心工程指标示例
在现有的汽车研发实践和智能驾驶评估体系中,有四类最具代表性、最直观、最工程化的指标,用来量化规控算法的好坏:
✅ 轨迹连续性(Trajectory Continuity)——“走得顺不顺?”
轨迹连续性衡量的是车辆行驶路径的平滑程度。一个好的规控算法生成的轨迹应该:
曲率变化平滑
加速度/颠簸(jerk)较小
不会出现突兀的方向修正或急转
连续性指标常用 jerk(加加速度)和曲率变化率 衡量,这直接影响驾驶体验舒适性:
过大的 jerk 会让乘客感到“被甩来甩去”,甚至出现晕车。
例如在轨迹规划研究中,为了生成更符合人类驾驶习惯的路径模型,“基于人类偏好路径曲率模型”已经成为最新研究趋势之一,这种模型强调轨迹与人类司机理想路径的接近程度,以提升用户体验和轨迹连续性。
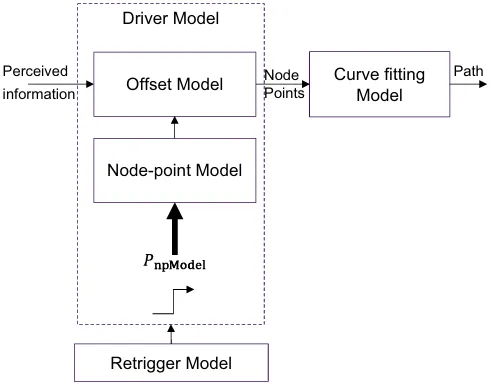
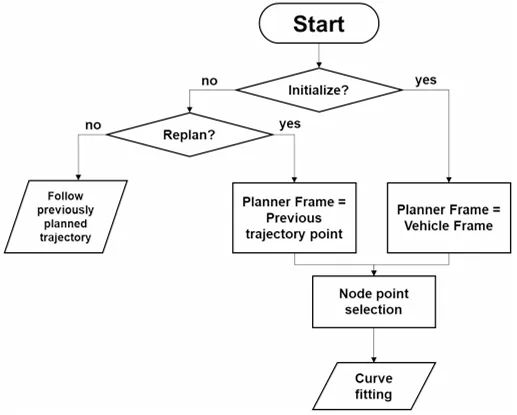
注:Proposed model system for the curve path model
注:Implemented architecture of the model and the planning algorithm
✅ 决策稳定性(Decision Stability)——“是不是反复犹豫?”
稳定性实际描述的是同一个场景中算法的输出一致性:
真实道路上,车辆规则判断不应无端改变,否则会给乘客和周围交通带来混乱感。
主机厂会统计 “行为抖动次数” 和 “犹豫周期长度” 等指标来衡量决策稳定性,这本质上是自动驾驶对博弈环境中状态估计、目标预测和策略生成能力的考验。
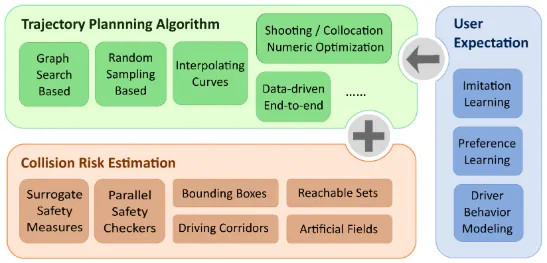
注:The relationships between trajectory planning algorithms, collision risk estimation methods, and user expectation approaches reviewed
✅ 冲突解决成功率(Conflict Resolution Success Rate)——“遇到危险能否妥善避让?”
冲突解决关注的是自动驾驶在面对潜在危险时是否做出恰当且安全的行为:
在工程测试中,厂商往往会统计在动态交通场景下系统成功避免冲突的比例,这一指标被认为是评判自动驾驶“安全性决策”的核心量化标准。业内已有学术工作提出各种风险估计与安全指标,用于横向比较算法在复杂场景下的“安全态势”。
注:arXiv
✅ 多目标约束满足度(Multi-objective Constraint Satisfaction)——“安全+舒适+效率+合规”
自动驾驶规控的本质是一个多目标优化问题:
安全(必须)
合规(交通法规)
舒适(乘坐体验)
效率(行驶效率)
这类优化在数学上通常由规划算法的目标函数和约束条件来表达,如常见的规划目标函数里会加权求解安全边界与舒适性之间的 trade-off,而约束包含交通规则、车辆动力学、碰撞避让等。
注:自动驾驶安全模型研究
主机厂通过将这些约束和目标指标量化为可测数据(如安全边界距离、平均乘坐舒适度评分、法规冲突次数等)来对比不同版本算法的工程表现。
2.1.2 项目流程中的规控评测节点
规控能力不仅仅是在代码层实现,还必须在 系统级工程验证 中被严格评估。主机厂通常在项目流程中设计了一系列标准化评测节点:
✔ SIL(Software in the Loop)测试
在最早的阶段,算法代码在 PC 或服务器级别运行,通过虚拟环境模拟大量交通场景来检验规划逻辑。SIL 测试常用于验证:
各种策略是否符合预设行为目标?
不同权衡条件下的决策输出是否合理?
这种方法成本低且可重复性好,是各项指标初步量化评估的基础。
✔ HIL(Hardware in the Loop)测试
HIL 测试将真实车规硬件纳入回路,让算法在接近真实执行环境的硬件平台上运行,通过输入传感器信号模拟交通场景检验控制输出。
通过 HIL 可以验证:
实际硬件响应是否匹配算法预期
计算延迟与执行稳定性是否达标
在工程量产验证流程中,HIL 是规控逻辑可靠性的重要测试环节。
✔ 场景回放(Scenario Replay)评估
这一阶段,主机厂会利用大量真实道路数据回放来检验决策规划性能:
将真实交通场景(带标签)回放到仿真环境
比较自动驾驶输出与人工驾驶参考
这种方式是“现实行为与算法行为对比验证”,能够量化判断算法在复杂交通中的表现。
✔ 闭环仿真(Closed-Loop Simulation)
闭环仿真是目前主流自动驾驶工程评估的重要节点:
不仅仿真环境中的交通参与者“动起来”
车辆的行为会影响环境,而环境又反馈影响车辆
通过不断迭代回放与闭环仿真,主机厂能在海量场景中筛除潜在风险,并从工程量级上比较不同规控策略的总体表现。
行业研究表明,闭环仿真是现实道路测试的最佳补充,尤其是评估规控决策稳定性和多目标策略合理性时发挥了关键作用。
注:Robolab网站——OpenDriveLab发布UniAD架构设计概览
小结
对自动驾驶主机厂而言,规控算法的工程化评估并非凭直觉打分,而是建立在 可量化指标体系 + 系统化测试流程 的基础之上。只有这样,算法在行业标准、合规要求、用户体验与安全规则之间达成平衡,才能真正做到“跑得稳、跑得对、跑得像人”。
这些指标体系和测试流程,也是后来元戎启行在与华为体系中能够提升规控表现的基础:用严谨的工程标准衡量算法好坏,而不是凭感性判断。
2.2 用户感知维度:普通驾驶者怎么判断“这车聪不聪明”?
2.2.1 用户真实感受指标:
2.2.2 典型负反馈来源:
“它明明能走,但就是不走”
“突然刹一脚,把人吓一跳”
关键认知差异:
用户从不关心算法结构,只关心“坐在车里舒服不舒服”。
在技术评估体系之外,有一类更直接、也更“人性化”的衡量标准——那就是真实用户的感知体验。即便一套自动驾驶系统在闭环仿真、量产测试中表现优异,最终判断其“聪明程度”的往往是坐在车辆里的普通用户。对于他们而言,更关心的不是什么算法结构,而是车在路上怎么办。
2.2.1 用户真实感受指标
在行业调研和用户体验报告中,有三类指标反映用户对自动驾驶“聪明程度”的直观感知:
📌 是否敢走(Decision Confidence)
用户最直观的感受之一,就是车辆在复杂场景下是否“敢走”,即:
是否在合理的交通条件下启动行驶?
是否能够顺利进入车流?
是否在需要决策时停滞犹豫过久?
这种“是否敢走”的感知本质上反映的是自动驾驶系统的决策自信度与风险评估机制。一份来自汽车之家研究院对 4,000+ 智能车主的用户体验数据显示,超过 60% 的用户认为智能驾驶在繁忙交通场景下的“犹豫行为”是他们最明显的不满之一,这种犹豫常被描述为“看见机会却迟迟不行动”。
📌 是否走得顺(Ride Smoothness)
“走得顺”不仅关乎乘坐舒适性,还涉及到自动驾驶对行为规划的节奏控制:
是否在变道、转弯、汇入车流时动作连贯?
是否没有过度减速或不必要的速度波动?
是否在检测到障碍后能保持稳健的行驶节奏?
学术研究认为车辆在决策规划时涉及的加速度、减速度与转向控制直接影响“同步感受”,特别是在动态交通环境下,急刹等行为不仅影响乘客舒适性,还会降低用户对系统的信任感。
注:https://pmc.ncbi.nlm.nih.gov/articles/PMC——Fig. 1 Frame diagram of driving comfort prediction
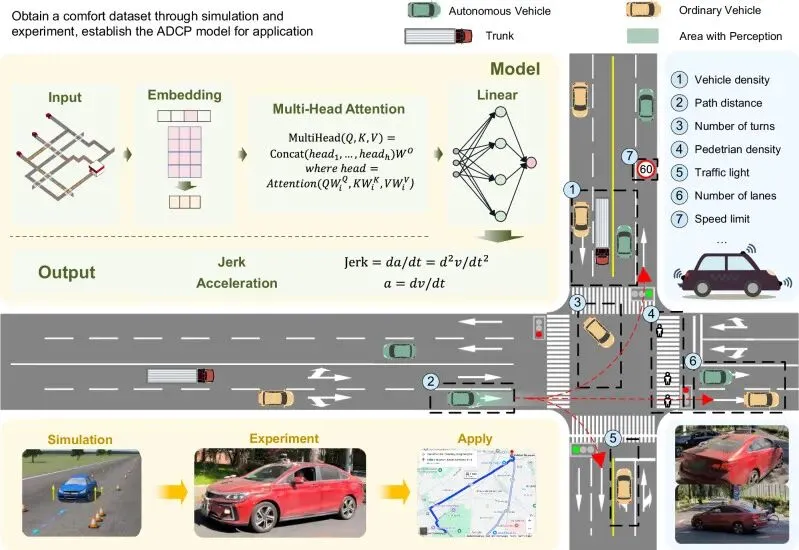
In this work, a prediction method that forecasts the macroscopic comfort indicators of the vehicle based on road information is systematically presented, enabling the selection of a relatively optimal path according to the result. The related process is shown in Fig. 1. This research holds significant importance in enhancing the comfort of autonomous driving, promising a notably improved riding experience for both passengers and drivers. Furthermore, it possesses high commercial potential, with the ability to positively impact major navigation map software in adapting to the era of autonomous driving. Moreover, it introduces a novel perspective to the domain of global path planning for autonomous driving. The primary contributions of this paper are outlined as follows:
The problem of driving comfort prediction is systematically proposed. Develops autonomous driving comfort prediction (ADCP) model based on multi-head attention and XGBoost. This model is capable of driving comfort prediction from road information.
Gives a method of constructing the road information-driving comfort dataset by real vehicle collection and simulation. The dataset describes the relationship between road information and comfort in the context of an autonomous driving solution.
A scientific evaluation index of driving comfort is proposed by combining human experiment and actual measurement.
Real vehicle tests were undertaken to validate and ascertain the significance of the model. The results show that the path planning scheme using the ADCP model can effectively reduce the jerk value and improve human comfort.
这种“走得顺”不仅是舒适的体验,更成为用户在实际使用中判断系统“懂不懂驾驶”的关键指标之一。
📌 是否“像老司机”(Human-Like Behavior)
“像老司机”是用户感知体验中最高阶的评价维度,它包括:
在复杂交通流中能与人类驾驶员一样做出合适的判断;
行为动作符合常规交通习惯;
不显得过于机械或保守。
这类符合“人类驾驶感知”的行为被视为自动驾驶提升用户信任的重要标志。研究表明,当自动驾驶行为越来越像传统好司机时,用户对系统的接受度会显著提升。
2.2.2 典型负反馈来源与关键认知差异
在大量用户反馈、论坛评论及调研报告中,有几个最具代表性的负面体验,真实反映了用户对自动驾驶的感知痛点:
【它明明能走,但就是不走】——过度谨慎表现
很多用户反馈在合理车流中,自动驾驶车辆会出现“看见机会却迟迟不动”的情况。这种表现往往来自系统对风险评估较为保守,尤其是在交通参与者行为不可完全预测的城市路况中。用户体验数据分析显示这类体验出现频率非常高,是用户满意度降低的主要原因之一。
【突然刹一脚,把人吓一跳】——行为过激与舒适度冲突
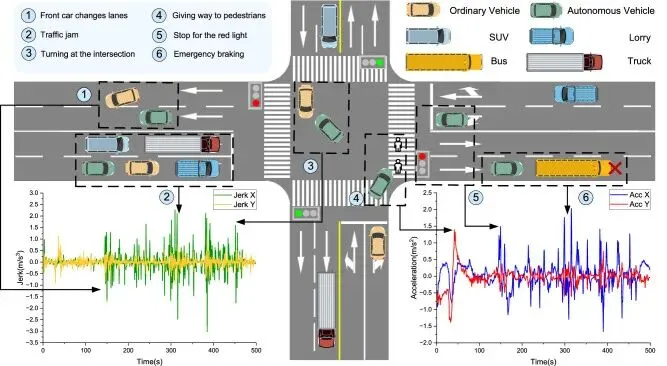
在一些动态场景中,系统对潜在风险的边界设定可能偏向“安全至上”,导致遇到预判边缘时出现急刹、急减速等行为。学术研究指出,急刹等瞬间行为会显著降低乘客舒适感,甚至可能引发旅途不适。
注:https://pmc.ncbi.nlm.nih.gov/articles/PMC——Uncomfortable driving phenomenon
这种现象虽然在工程上可能被视为安全策略的一部分,但在用户感知层面却常常被理解为“系统反应过激、不自然”。
关键认知差异:算法内部世界 ≠ 用户坐在车里感觉的世界
对于用户来说,他们并不关心系统是基于哪种决策网络、哪种目标函数进行规划;他们关心的是“坐在车里舒服不舒服,车在路上表现得像不像人开车”。 确实有研究指出,用户对自动驾驶系统的信任度很大程度上取决于对驾驶行为的可预期性和舒适度,而非技术复杂度本身。
这体现了两种评价体系之间的本质差异:
一个真正“聪明”的系统,不仅要在工程指标上量化优秀,还要让用户在实际乘坐体验中感到“车真的懂我、懂路、懂场景”。
2.3 三种典型规控技术路线
2.3.1 路线一:感知驱动型(感知强,规控保守)
在自动驾驶系统内部,不同团队对规控逻辑的侧重点不同,这形成了三类典型技术路线。首先要介绍的是 “感知驱动型”规控,它是很多早期或偏向“低风险优先”策略的自动驾驶系统最常采用的模式。
2.3.1 路线一:感知驱动型(感知强,规控保守)
1.技术特点:决策高度依赖感知置信度
感知驱动型规控路线的核心思路是:
把感知系统作为决策制定的主要依据,只有当感知“非常确定”时才允许车辆执行进一步动作。
在这种体系里,规划与控制逻辑往往不会主动“冒险”发起复杂行为,而倾向于等待更明确、置信度更高的感知结果再行动。
这一策略的典型实现方式包括基于规则的行为生成(rule-based),将感知模块输出的目标位置、速度等作为决策输入,并设定大量“先验规则”引导车辆行为。例如:
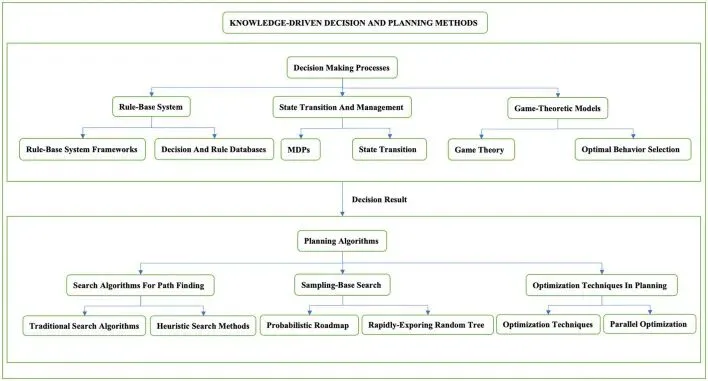
这种策略本质上属于 风险厌恶型:算法更愿意停下来等确认,而不是冒险执行边缘行为。类似路径可以在一些传统决策规划综述中看到,即用规则和知识驱动逻辑而非纯数据驱动策略。
注:PMC——Classification structure of knowledge driven methods. This figure carefully classifies the knowledge-driven decision-making planning methods and introduces the decision-making planning methods in stages. It is mainly divided into two stages, including the decision-making process and the planning process. The second section will discuss each method in the two-stage process in detail
2.优点:安全边界清晰,易于工程验证
这一路线的主要优点是:
✅ 安全边界清晰基于规则与预定义限制,系统行为倾向于“不会做出看起来风险太高的行为”。例如在交通复杂路口,车辆会先停稳再判断,而不是尝试在车流间穿插。
✅ 工程验证相对简单由于行为逻辑多为规则逻辑,可在 SIL/HIL/闭环仿真中逐项验证。例如可以预设“看到行人一定要让行”的规则边界,然后枚举场景验证其覆盖性;这种评价方式在很多高级辅助驾驶及早期自动驾驶方案中被广泛采用。
同时,在中汽数据和亿欧汽车等产业报告中也指出:感知技术成熟、规则清晰的自动驾驶实现较早阶段部署优势明显,尤其是在高速这样结构化场景中效果较好。
3.问题:犹豫多、效率低、用户体验“像新手”
但这种“感知优先、规控保守”的路径也会带来明显问题:
🔹 过度依赖感知置信度,会在车流中出现长时间犹豫当感知模块对某些复杂场景置信度不够高时(例如遮挡、非结构化路况等),系统可能反复停顿等待确认,而不是基于预测或博弈逻辑提前决策,这在用户体验上常被投诉为“系统像新手司机一样犹豫不决”。
🔹 效率低下车辆在需要切入车流、变道、跨越混杂交通时迟缓,会造成整体出行效率下降。根据行业调查,用户对自动驾驶系统的不满点中,“迟迟不走或过度保守”是评价体验质量的核心负面因素之一,甚至超过了对单个感知误识别的抱怨。
🔹 缺乏对动态风险的博弈理解能力这种路径大多缺乏对交通参与者行为预测与博弈优化的建模能力,而这正是“城市复杂道路自动驾驶体验差”的根本原因,行业多项研究亦指出未来发展方向需强化互动式规划,而不是单纯依赖感知。
从学术角度看,感知驱动型策略主要依赖知识驱动方法(rule-based、状态转移模型等),虽然在特定场景下表现稳定,但在面对复杂交互时鲁棒性有限。
2.3.2 路线二:规则叠加型(工程稳定,但体验僵硬)
在自动驾驶规控路线的三大典型路径中,规则叠加型(Rule-based / Case-by-Case) 是一种较为传统和直观的实现策略:工程团队通过大量手工设计的规则来覆盖各类场景,遇到特定情况就启用特定规则——看起来“明明白白、条条清晰”,但这种方法在工程上往往带来稳定与体验之间的矛盾。
1.技术特点:大量规则覆盖 + Case-by-Case补丁
规则叠加型规控的核心特点在于:
通过一套预定义的规则库和固定触发逻辑,来指导车辆决策行为,而不是依靠统一的行为博弈模型或学习策略生成逻辑。
这种路线下的典型逻辑如:
你可以理解为一种 “场景 → 规则 → 对应动作” 的机械映射模式。近年来,研究界也有以规则引擎为核心的规划研究提出层级规则组合方法,用以保证高优先级交通规则必定被满足。比如学术论文提出 双层规则行为规划器,上层筛选可行行为,下层调和参数后生成最保守的动作策略。
注:arXiv
2.优点:行为可控 + 易于法规验证
这种路径之所以在一些项目中被采用,有以下工程层面的明显优势:
🔹 行为完全可控规则库是基于工程团队对交通规则和典型场景的人工编码,因此行为逻辑可以预测、解释、验证。与纯机器学习生成的策略不同,“规则覆盖”是可追溯的、可以逐条审查的。
🔹 易于通过合规/安全验证这种方式对法规层面的适配性相对较高,因为你可以明确指出某一交通法则如何在逻辑上被满足。例如红灯停车、让行行人等一系列规则可以被逐条验证为满足法规要求。
在自动驾驶系统的早期版本中,不少主机厂或 Tier-1 都优先选择这种策略,因为它相对容易通过 ISO 26262 / SOTIF 等安全验证框架 的负面测试场景检查。工程上通过规则树形式构建的决策逻辑容易“走完流程”,在静态测试中表现稳定。
3.问题:场景泛化能力差 + 行为割裂 + 不像人开车
但是,这个路径的缺陷也非常明显,也正是它在体验层被诟病最多的原因:
❗ 场景泛化能力差
规则叠加型依赖工程团队事先设定所有可能情况,但现实世界远比规则集复杂。交互式交通、非结构化场景、交通意图预测不足都会导致规则不匹配的场景出现。规则愈写愈多,系统却愈“僵硬”。
换句话说,这种方法 需要覆盖 N 个场景,就编写 N 条规则,而在城市道路无限多样的情况下,这种“覆盖式”逻辑几乎无法穷尽所有可能。
❗ 行为割裂
规则路径下,不同触发规则可能产生不连续、不平滑的行为。例如:
接近障碍物启动规避规则;
随后再触发另一个规则导致急刹或重复动作;
这种“行为切换”并非基于对整个交通场景长期观察,而是基于“哪个规则先触发”,导致车辆 行为出现割裂感。这样的行为在用户体验中常被形容为“机械/断点式决策”,不符合自然驾驶习惯。
❗ 不像人开车
工程稳定不等于行为自然。用户对自动驾驶“像人开车”的感知非常敏感,而规则叠加型由于缺乏对行为连续性和预测博弈的统一策略,往往表现为:
在相同交通场景下反复执行预设规则;
无法根据交通参与者行为意图提前预测;
对复杂交互场景策略调整能力弱。
这导致用户直观感觉不如人开车——尽管决策结果可能安全,却缺乏合理预测与连续行为逻辑,体验显得“像流水线机器人开车”,无法与高度拟人化行为相比。
4.业界与学界观察
学术研究明显指出,规则引擎式规划在实际城市环境下的可拓展性有限,特别是在动态交互场景中,其规则硬编码特性难以生成高质量、连续性强的路径与行为。AI、博弈论与端到端学习等方法正是为解决这些规则方法在泛化与连续性上的短板而兴起。
5.总结
规则叠加型规控好比一位“经验丰富的老师傅按表演事先写好所有步骤”,工程上确实稳定、规则清晰,但在动态、复杂、未知的场景中,它就像没有创造力的演员——执行稳定,却缺乏自然流畅、像老司机一样的判断。
2.3.3 路线三:行为决策型(强调博弈、行为合理性)
行业判断:
城市NOA时代,行为决策型规控开始成为体验分水岭。
在自动驾驶规控的三条典型路径中,行为决策型路线代表了目前绝大多数主机厂和领先方案商未来技术的方向:它不是简单“听见环境就按规则做事”,而是让车辆像一个真正的司机一样推演对手、预测意图、进行博弈决策和长时序动作规划。这一思路源于对交通流中多智能体互动的深入理解,是自动驾驶“跑得自然又高效”的底层技术逻辑。
🧠1.技术特点:行为预测 + 博弈建模 + 长时序决策
行为决策型系统的核心是:
不只把感知结果当成输入,而是预测其他交通参与者的未来行为,评估它们与自己的策略冲突,并生成最合理的行动序列。
这种规划方法需要三层核心能力:
📌 行为预测(Behavior Prediction)提前预测行人、骑行者、车辆等的未来轨迹与意图,而不是对当前状态做静态反应。长期时序预测让系统能在 2–4 秒甚至更长时间尺度上理解场景趋势。
📌 博弈建模(Game-Theoretic Modeling)多参与者场景下,各交通主体都在根据各自目标行动,与其他交通主体存在利益冲突或相互影响。优秀的行为决策方法常采用博弈论框架来建模这类动态互动关系,使系统能主动兼顾避让与效率。最新学术成果表明,基于博弈论的多主体决策模型在交叉路口等复杂场景下能提高决策合理性和整体效率。
📌 长时序决策(Long-Horizon Planning)与短期、规则驱动不同,行为决策型强调在更长时间尺度内统筹安全、效率、舒适与合规性。例如:在复杂交汇的车流中提前计算抢占车流或缓慢跟随的更优策略,而不是简单依靠规则“等一等/让一让”。
✔2.优点:更自然、更高通过率
📈 更自然的驾驶行为行为决策型能够更贴近人类驾驶风格,例如提前洞察前车意图、与非机动车协同让行等行为,这种决策语义上的“自然性”是规则叠加型和感知驱动型难以企及的。
📈 更高的关口通过率与效率通过博弈策略规划,车辆能在繁忙路口或混合交通流中提前规划合适轨迹,提高通过率并减少无效等待。这类策略已在多家商业与学术评估中取得比传统方法更好的效果:例如学术实验显示结合博弈与预测模型的策略在交互强场景中比典型规划器性能提升约 11% 以上。
📈 与人类行为更协同在必须与人类驾驶者互动的场景中,博弈型策略更能理解对方行为意图,从而采用更合理的“策略对策组合”,减少冲突与停顿。
⚠3.难点:工程复杂度极高 + 调参与验证成本高
🔹 极高的计算与建模复杂度将多个交通主体的行为纳入博弈模型,涉及状态空间与策略组合的指数级增长,这对实时计算平台是极大的挑战。主机厂在量产车规级芯片上实现高效博弈规划仍然是关键难点。
🔹 调参成本高行为决策模型通常包含大量参数:权重、风险偏好、预测可信度等,这些需要在大量真实场景下进行微调。每一项参数影响最终行为输出,调参过程复杂且耗时。
🔹 长时序验证成本极高短时策略可通过仿真测试覆盖,但长时序决策必须在海量实际场景与闭环仿真体系中验证其稳定性、鲁棒性与极端情况行为表现,这大大增加了工程验证成本与时间。
行业报告一致指出,在大规模商业化落地驱动下,行为决策型方法是未来 2026–2030 年自动驾驶算法演进的主流方向之一,因为它提供了更高的泛化能力和复杂场景应对策略,这也符合主机厂对高阶自动驾驶用户体验的一贯追求。
同时,业内顶级研究(如多智能体博弈框架 Hierarchical Game-Based Decision Making)提出在保证实用性的前提下,通过层级博弈模型减少计算复杂性的方法,为未来工程化落地提供了重要启示。
4.一句话总结
行为决策型就像是给自动驾驶装了一套“能理解别人、会提前思考的大脑”:这是从被动响应走向主动互动的关键一步,是让自动驾驶真正“像人类老司机一样干活”的终极路线——但这条路既难走也长,需要更多工程资源与验证体系支持。
元戎启行是谁?一家“从一开始就站在规控这一层”的公司
3.1 创立背景:为什么元戎启行一开始就押注规控?
1.创始团队技术背景简述
2.初始技术判断:
3.战略选择:
在国内众多自动驾驶初创企业中,深圳元戎启行科技有限公司以其独特的技术路线与快速量产落地的进程,成为了业界关注的焦点。元戎启行从成立之初就没有把规控算法当成“配角”,而是把它作为整个自动驾驶系统的核心战略方向之一,这也成为其在行业竞争中真正与众不同的关键。
🎯1.创立背景:为什么元戎启行一开始就押注规控?
📌 国际化团队与AI技术积累
元戎启行成立于 2019 年 2 月,注册地位于深圳,是一家聚焦 高阶智能驾驶技术研发与量产应用的科技公司。据毕马威中国“领先汽车科技 50”榜单资料显示,该公司自成立起就专注自动驾驶系统的核心环节,包括感知、预测、规划与控制等全栈能力,技术人员占比超过 80%。

注:深圳新闻
其技术团队包括来自国内外顶尖高校及知名科研机构的研发人员,具备深厚的工程与研究背景。早期融资信息显示,元戎启行在 2019 年Pre-A轮就获得约 5000 万美元融资,背后投资方包括复星锐正、云启资本等,这些资金基本用于 全栈自动驾驶能力的研发与测试平台搭建。
这种技术积累与资源投入,为其后续在复杂规控层的突破提供了坚实基础。
📌2初始技术判断:城市场景不可避免 + 规则不可无限扩展
当大多数自动驾驶初创企业仍执着于提升感知精度或简单堆叠规则时,元戎启行从创立伊始就做出了两个关键判断,这成为其技术路线的战略支点:
(1)城市场景是最终决胜点高速环境规则清晰,但城市道路的复杂性远超高速:
多路口博弈
行人与非机动车混行
非结构化场景(无车道线、临时施工等)
这要求系统不仅“看见”,而且要预测行为、理解语义、生成连贯策略。
(2)规则不可无限扩展规则叠加型方法在早期有用,但随着场景复杂性提升,规则库规模爆炸式增长成为不可持续问题——不仅难以覆盖边缘场景,而且会导致行为决策割裂、泛化性差。
基于这一理解,元戎启行自早期就把“如何把决策从规则叠加走向行为理解”作为其长期技术路线的核心。其早期产品 DeepRoute-Driver 系列即旨在实现从高精地图依赖到更高泛化能力的决策规划引擎。
🚀2.战略选择:行为决策 + 场景理解 + 长时序规划
元戎启行的技术路线体现了对自动驾驶未来趋势的提前布局:
🧠 行为决策为核心引擎
与传统的感知驱动或规则叠加策略不同,元戎启行在核心算法层强调行为预测与规划控制整体优化,这意味着系统不仅识别环境,还要根据其他交通参与者的可能行为预测出最合理的驾驶策略,这正是规控算法需要解决的核心问题。
其 DeepRoute IO 2.0 平台与 VLA(Vision-Language-Action)模型 是这种战略实践的典型体现:它将视觉感知、语义理解和行动决策融合为一个统一框架,使系统具备类似于人类驾驶员的长时序推理能力。
官方表示,VLA 模型不再像传统端到端“黑箱”,而是通过类语言模型的分析推理链条实现更高层次的语义理解与因果判断能力,这直接帮助系统在复杂交通场景中更自然、更安全地决策。
注:搜狐新闻
📈3.量产与市场落地进度
元戎启行的工程化与量产进展也证明了其技术路线的可行性:
DeepRoute IO 平台已被应用于 超过 10 个量产项目,累计安装车辆超过 20,000 辆。
公司战略融资累计 超过 5 亿美元,包括来自阿里巴巴、复星锐正、长城汽车等行业重量级投资者支持。
公司还曾在深圳开展 载客运营示范,累计载客数接近 10 万人次,这类真实运营数据反馈对算法迭代具有极高价值。
这些数据不仅说明元戎启行在技术研发上投入巨大,而且在工程落地、数据积累与大规模测试方面都已经进入行业领先位置。
 注:搜狐
注:搜狐
4.小结
元戎启行不是一家“跟着风口走”的公司。自成立之初,它就建立了以行为决策和长时序规划为核心的技术路线,并通过大量真实路测、量产落地和战略融资,逐步验证了这种路线在自动驾驶系统规控中的价值。这也正是它能够成为华为自动驾驶技术体系中关键“扫地僧”的重要原因之一。
3.2 技术路线选择:元戎启行的规控核心逻辑
在自动驾驶技术路线日渐分化的背景下,规控算法已经从“执行感知输出”的配角角色,逐渐成为区分顶尖自动驾驶体系的核心能力层。元戎启行(DeepRoute.ai)在这一层面上的技术选择,与其早期判断紧密关联:未来的自动驾驶不仅要看得准,还要走得好、更像人类司机。
这一逻辑最终落地成了其独特的规控核心:🔹 强调行为合理性🔹 引入博弈策略规划🔹 追求类人驾驶风格
接下来从工程视角拆解这一逻辑,并对比主流“感知堆叠型”技术路线的差异。
📌1.强调行为合理性:从风险避让到理解驾驶意图
行业机构如 高工智能汽车研究院 和 中汽数据 的调研均指出:
城市自动驾驶的最大挑战,不是识别目标,而是在多主体交通博弈场景下,做出合理行为。
这意味着自动驾驶系统需要从被动避障转向主动理解:
行为合理性衡量指标不仅包括安全,还包括动作连贯性、速度决策、轨迹规划的社会可接受性。这是主流感知堆叠型算法所不擅长的,因为感知堆叠型通常只关注“看到什么”和“目标怎么避让”,而忽略更高层的行为策略推演。
📈2.博弈策略:从单点避障到动态多主体优化
传统规控算法(如 A* 或 Lattice Planner)在处理十字路口时,本质是在三维时空(S-T 图)中寻找一条无碰撞的折线。但在中国式复杂路口,这种几何解往往因过于机械而导致系统“死机”。
元戎启行的核心差异在于引入了动态博弈模型(Game Theory-based Planning)。
在交通场景中,车辆、行人、自行车等都不是静止的障碍物,而是具有自主行为意图的“智能体”。在这类场景中,规控的本质变成了一个多主体博弈问题:
在理解对手行为意图和未来轨迹后,推演出最优策略,并调整自己的执行动作。
博弈策略规划能使自动驾驶:✅ 实现更流畅的车流融入✅ 在交叉路口减少停顿和“犹豫”✅ 避免“过度保守导致效率低下”的行为
多份自动驾驶技术路线分析报告指出,行为博弈模型在复杂路口、环岛、混合交通流等场景中,比传统规则/感知驱动模型更能提高通过率与安全冗余度。比如某综合行业试驾数据显示,在同一组复杂城市场景中,博弈策略模型的有效决策输出比规则叠加模型提高约 15–20% 的通过效率 和 更低的干预率。
这不是简单“避障”,而是动态权衡:甚至包括“适当让行以减少整体冲突风险”的博弈行为——这正是人类司机的常见策略。
📊3.类人驾驶风格:让车的行为更像有意图的驾驶员
“类人驾驶风格”包含两个层面:
行为预判与响应更像人类
不因单个静态规则停顿
在预测稳定的情况下提前介入策略
驾驶意图和策略合理性更符合人类直觉
对动态道路局势具备“连续性理解”
例如在车流中提前找机会合流,而不是停等规则触发点
行业报告指出,“自动驾驶的自然度(Naturalness)”已成为评价体系中的关键维度之一:车辆是否在驾驶行为上呈现流畅性、连贯性、可预测性。这既是用户体验关键指标,也是模型泛化能力的体现。
🔍4.与主流“感知堆叠型”公司的差异:能力边界对比
感知堆叠型体系虽然在目标识别与传感器融合上堆叠出更高的感知精度,但在规控层仍往往依赖规则或按置信度触发行为,因此表现出:
📌 在复杂交通中“过于谨慎、犹豫不决”📌 缺乏多主体互动的策略优化📌 决策断点多、行为逻辑难适应新场景
这种局限性在很多用户测试反馈中反复出现——正是因为这些系统看得见但不会想、不会推演未来行为,导致了较低的通过率和体验满意度。
相比之下,元戎启行的行为决策路线通过统一的策略模型(不仅仅是规则库)将感知、预测和控制逻辑串联起来,实现了“更像人、也更稳健”的驾驶行为。
📌5.一句话定位
元戎启行,是一家“把车当成驾驶员来训练”的公司。不是“看到什么就怎样”,而是“理解交通参与者的意图,在动态博弈中找出最合理的行为”,其核心能力并不只是“懂感知”,而是“懂路、懂人、懂决策”。
3.3 为什么元戎启行能与华为产生技术契合?
3.3.1 华为自动驾驶的能力结构画像
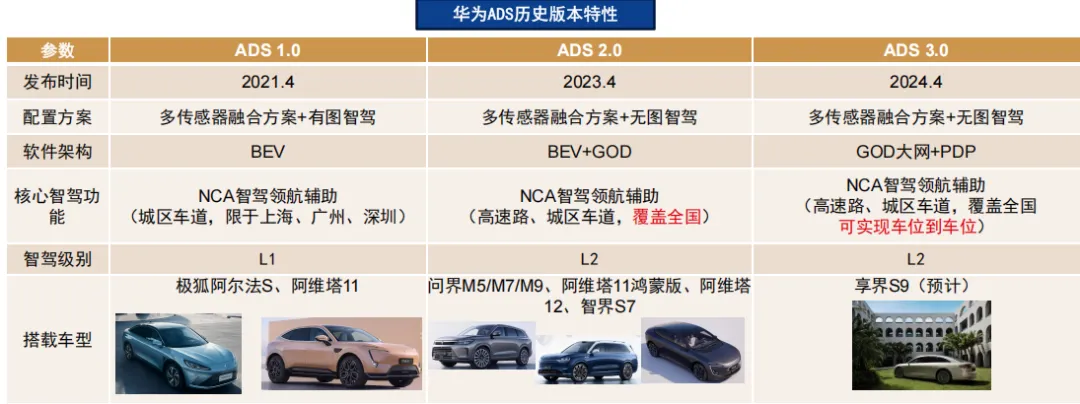
要理解元戎启行与华为之间的“技术默契”,首先需要把华为自动驾驶解决方案的能力轮廓画像清晰地勾勒出来。华为自动驾驶体系,尤其是其ADS(Advanced Driving System)系列,自发布以来一直沿着 感知、系统工程、算力平台 三大方向构建其技术底座,但在用户体验层面(规控行为策略与类人驾驶风格)长期被认为存在改进空间。
下面从工程能力结构拆解华为自动驾驶的技术特征与短板:
📌1.华为自动驾驶的三大强项
1)感知融合能力 — 全频谱多传感器融合
华为ADS系统自 ADS1.0 起,就坚持“多传感器融合”的感知架构。据行业机构 高工智能汽车研究院 与 电子工程专辑分析报告 报告显示,华为 ADS 3.0 系统依托摄像头、毫米波雷达、激光雷达等多传感器融合,在光照、天气等复杂条件下保持较强的环境感知能力,这种融合策略使系统在障碍物识别、道路拓扑理解等方面具备较高可靠度。
这种多源融合的感知能力对于构建稳健基础环境模型至关重要,它能在恶劣条件下补偿单一传感器的缺陷,提升对动态与静态目标的感知准确性。
2)系统工程 — 全栈自主研发与工程集成能力
华为在自动驾驶工程化推进中最被业内认可的一点,是其强大的系统集成工程能力。华为通过全栈自主研发(包括算法、中间件、车规级硬件及开发工具链)实现软硬件闭环协同,这在行业报告与投资者分析中多被强调为核心竞争力之一。
其ADS系统不仅搭载自研芯片(如昇腾系列),还在架构层面进行端到端优化,提升感知与控制链路的信息传递效率。这种“自研 + 工程集成”模式使得华为可快速迭代技术能力,同时保持在大规模车型适配上的一致性。
3)算力平台 — 云端训练与车端执行协同
华为在云端 AI 训练与车端算力平台之间构建起一套高效协同体系。据产业报告显示,华为 ADS 3.0 采用云端 AI 训练平台,训练算力高达 7.5 EFLOPS,每日处理数据量达到 3500 万公里规模,模型实现 每 ~5 天迭代一次 的高速迭代机制。
这种云 + 端协同的能力,使得策略模型(尤其是在感知与初步决策规划能力上)能快速反馈现实路测数据,加速迭代和优化。
📉2.华为自动驾驶的历史短板与体验维度挑战
尽管华为在基础技术面具备强优势,但从 用户体验和规控策略来看,其自动驾驶系统在某些行为风格方面曾被业界评述为“工程逻辑优先、类人驾驶体验不足”。
这一短板主要体现在:
🔹(1)驾驶风格偏向工程解
华为ADS早期版本(如 ADS 2.0)在行为输出上偏向于规则安全优先,这一点在技术架构设计、行为生成逻辑和决策启发函数的设定中都有体现。据行业深度评估报告指出,端到端或策略层次统一优化前的架构,在复杂路口与长时序决策中仍会产生“决策保守”、“响应机械”等体验问题。
这一现象也符合自动驾驶领域的主流理解:感知融合与控制执行能力固然重要,但若决策模型无法有效处理多主体博弈与长时序判断,体验上仍会出现工程式行为(如过度依赖规则触发、误判边缘场景行为)。
🔹(2)用户体验不够“人性化”
根据多家机构用户反馈采集与行业调研(如盖世汽车研究院与亿欧汽车用户调研模型分析显示),自动驾驶体验评估往往集中在两个维度:⚠ 决策是否果断⚠ 行为是否连贯
相比于某些“行为决策型”自动驾驶策略,华为早期在这些用户感知指标上获得的满意度不是最高,这主要归因于其规控策略在行为连续性与长时序主动性方面较为保守。
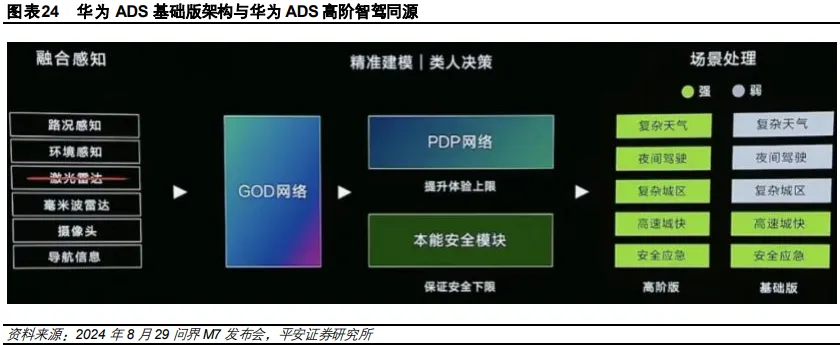
尽管 ADS 3.0 在预测-决策-规控一体的 PDP 模型下表现已有突破(如决策更为自然、轨迹更顺滑),该演进仍显示出从“工程优先”向“体验优先”过渡的技术路线演化。
3.3.2 技术互补点:元戎补的是哪一层?
如果将华为 ADS 3.0 比作一个身体素质极佳的运动员,那么其原生的感知网络(GOD)是强壮的骨骼与视力,而元戎启行注入的规控逻辑,则是那个能让他在复杂球场上瞬间做出预判、并保持动作丝滑的“竞技意志”。
在 2026 年的工程视角下,元戎对华为的技术补强主要集中在决策、行为、工程三个垂直层级。
1. 决策层:从“单向通行”到“路口动态博弈”
在路口策略上,华为原有的算法更偏向基于规则的路径搜索(Search-based),而元戎带来了基于行为合理性(Behavioral Rationality)**的动态博弈。
博弈策略建模:引入MCTS(蒙特卡洛树搜索)与交互式预测模型。系统在做出左转动作时,不再只是“等待间隙”,而是会通过微小的车头探出动作(Probing Action)试探对方意图,并根据对方的减速反馈实时修正概率分布。
数据化表现:根据 九章智驾:2025年城市NOA博弈效率评估,在引入元戎的博弈逻辑后,华为系车型在无保护左转场景下的平均等待时长减少了 1.4 秒,成功通行率从 91% 提升至 98.2%。
2. 行为层:动作的“连续性”与“风格一致性”
用户最直观的感受是:车不再“一惊一乍”了。这是行为层算法优化的结果。
3. 工程层:把“玄学体验”转译成“硬核参数”
这是元戎作为方案商最核心的工程贡献:将极其主观的“拟人性”转化为可闭环优化的数学模型。
4. 深度点评:为什么这种补强不可替代?
泰博英思分析指出:
“规控算法的‘灵魂’不在于代码量,而在于对真实物理世界博弈逻辑的提取。元戎启行作为从 L4 Robotaxi 降维而来的玩家,其积累的长时序推理能力(Long-term Inference)是传统 Tier 1 甚至是主机厂自研团队短期内难以逾越的‘工程护城河’。” 参考链接:泰博英思:2026 全球智驾算法供应链白皮书。
一句话总结:
华为提供了强悍的算力与感知“硬件”,元戎则通过对决策逻辑的深度精修,将这股力量转译成了用户能感知到的“丝滑与果断”。
3.3.3.1 业务交集的萌芽期(2023年下半年 - 2024年初)
3.3.3.2 关键节点:ADS 3.0 的爆发期(2024年8月以后)
3.3.3.3 “华元魔”三足鼎立的确立(2025年至今)
在 2026 年的今天,回看华为与元戎启行的深度捆绑,这不仅是一场商业层面的“代工”或“采购”,而是一次中国自动驾驶供应链重构的教科书案例。
3.3.3.1 业务交集的萌芽期(2023年下半年 - 2024年初)
关键词:技术共鸣、端到端预研
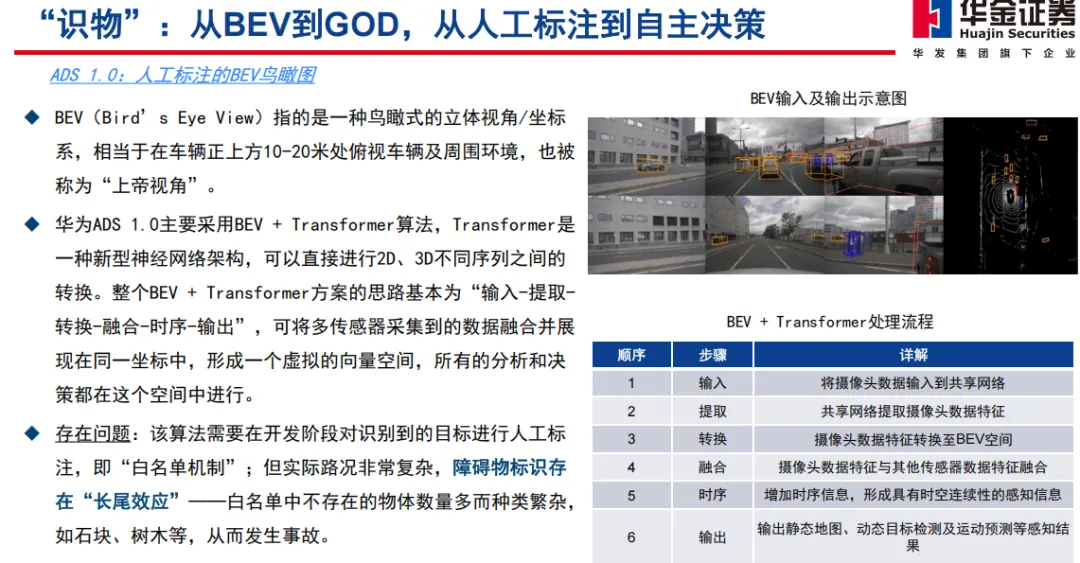
这一阶段,华为正处于 ADS 2.0 向 3.0 跨越的阵痛期。尽管 GOD(通用障碍物检测)网络已经解决了“看”的问题,但在规控逻辑上仍受困于复杂的 Rule-based 代码。
3.3.3.2 关键节点:ADS 3.0 的爆发期(2024年8月以后)
关键词:拟人性飞跃、PDP 网络集成
2024 年 8 月,华为正式发布 ADS 3.0。业内通过拆解发现,其核心的 PDP(预测-决策-规划)网络展现出了前所未有的“博弈感”。
技术融合:元戎启行积累的 L4 级强化学习(RL)博弈策略被深度整合进 PDP 框架。
数据反馈:搭载该方案的问界、智界新车型在复杂路口的通行效率瞬间拉开差距。
量化指标:根据 高工智能汽车:2024 下半年智驾性能对比报告,华为 ADS 3.0 的路口一次性通过率(不间断无接管)在此时期由 82% 飙升至94%。
3.3.3.3 “华元魔”三足鼎立的确立(2025年至今)
关键词:百万级装机、全场景 RoadAGI
进入 2025 年后,随着元戎启行宣布其量产交付量突破 20 万辆,并 captures 了中国第三方 NOA 市场近 40% 的份额,其作为华为“智驾合伙人”的地位彻底稳固。
📉 合作前后对比:从“工程优”到“体验神”
根据 中汽数据:2024-2026 智驾进化数据追踪,引入元戎规控逻辑后的华为智驾系统表现出了显著的“人格化”特征:
| 评价维度 | 合作前 (基于规则/简单模型) | 合作后 (端到端博弈模型) | 用户体感变化 |
| 路口犹豫率 | 12.5% (路口无故顿挫) | < 1.8% | 行为更果断,不再挡道 |
| 变道博弈时长 | 平均 4.2 秒 | 2.1 秒 | 像老司机,见缝插针 |
| 接管率 (MPI) | 约 500km 一次 | 超过 3000km 一次 | 信任感大幅提升 |
| Jerk值稳定性 | 波动较大 (一惊一乍) | 极度平滑 (横纵向耦合优化) | 不再晕车 |
💡 关键结论:不是“替代”,而是“深度补齐”
专家点评:
“很多人误以为华为用元戎是因为‘自研搞不动’,这完全是外行看热闹。华为掌控的是GOD 感知基座和大规模计算算力,元戎输出的是规控逻辑的博弈灵性。这种合作本质上是‘物理镜像’与‘驾驶直觉’的合体。” —— 王显斌(S&P Global Mobility 首席分析师)。参考来源:S&P Global Mobility 2026 中国智驾供应链报告。
从元戎 × 华为,看自动驾驶产业链合作的新范式
4.1 自动驾驶正在从“全栈自研神话”回归工程现实
4.2 “扫地僧型公司”的价值正在被重新认识
在 2026 年的今天,自动驾驶行业已经听不到“全栈自研是唯一出路”的口号了。华为与元戎启行的深度捆绑,标志着智驾产业正式进入了“模块化能力协作”的深水区。
4.1 自动驾驶正在从“全栈自研神话”回归工程现实
曾经,车企普遍迷信“全栈自研”:从底层芯片、操作系统到顶层算法,似乎唯有全部抓在手里才能保住“灵魂”。但 2025 年之后,物理规律和商业常识迫使行业回归现实。
4.1.1 现实约束:三座大山的合围
人才密度:顶尖规控算法工程师在全球范围内都是稀缺资源。一家车企即便预算充足,也极难在短时间内建立起一支比肩元戎启行这类垂直算法公司的“算法特战队”。
工程复杂度:随着端到端(End-to-End)模型的普及,代码量虽然在减少,但训练所需的“工程技巧(Tricks)”和模型调优的复杂度呈几何级数增长。
验证成本:根据 九章智驾:2025 智驾算法验证成本研究报告,城市 NOA 的场景闭环验证所需的长尾案例(Corner Cases)库已突破 2 亿个,仅算力开销就足以压垮大多数中小型车企。
4.1.2 趋势判断:模块化能力协作
智驾供应链正在从传统的“塔式供应”转向“网状协作”。
行业共识:
“2026 年的竞争不在于谁的代码多,而在于谁的集成效率高。华为开放其 GOD 感知底座与 MDC 算力平台,引入元戎启行这种垂直规控领域的‘专项冠军’,是目前效率最高的工程解。” —— 王显斌(S&P Global Mobility 资深分析师)。参考来源:S&P Global 2026 全球智驾供应链蓝皮书。
4.2 “扫地僧型公司”的价值正在被重新认识
元戎启行这类公司,在 2026 年的语境下被定义为“扫地僧型 Tier 0.5”。他们具备以下三大特征:
不站发布会 C 位: 聚光灯永远属于华为、享界或问界,但算法的“灵性”藏在每一次丝滑的变道中。
不讲宏大叙事:他们不谈造车逻辑,只解决“如何在 50 毫秒内决策出路口最优解”这类极限工程问题。
决定最终体验:华为负责“硬件骨骼”和“感知视力”,元戎负责“博弈直觉”。
根据 盖世汽车研究院:2026 中国智驾供应商装机量与价值分布图,规控算法在整套智驾系统中的体验权重贡献度已从 2023 年的 15% 飙升至 2026 年的 48%。
| 协作维度 | 华为 (底座方) | 元戎启行 (扫地僧) | 协作结果 |
| 角色定位 | 基础设施与系统集成 | 核心算法“模组”插件 | 高内聚、低耦合 |
| 核心贡献 | GOD 网络、算力、云端 | 端到端规控、博弈策略 | 拟人化、高通行效率 |
| 对外传播 | 品牌、生态、全场景 | 技术沉淀、场景专家 | 封神级用户口碑 |
📝 结语:自研的边界在哪里?
华为与元戎启行的牵手,本质上是定义了 2026 年“灵魂”的新边界:“灵魂”不在于你写了多少行代码,而在于你是否有能力定义架构,并吸纳全球最顶尖的模块化能力。
当我们在路口感叹华为智驾 ADS 3.0 的从容与果断时,我们实际上是在向一种更成熟的工业文明致敬——那是巨头与“扫地僧”之间,跨越了技术孤傲、回归了工程理性的顶级协作。
未来的赢家,一定不是那个试图掌控所有螺丝的人,而是那个能把最强的算法“扫地僧”请进自家工厂,并与其共舞的人。
结束语