在自动驾驶视觉感知领域,小目标检测一直是公认的技术难题——交通标志、远处的骑行者、小型车辆等小目标像素占比低、特征稀疏,传统检测方法极易漏检;而开放词汇检测的兴起,又要求模型能识别未见过的目标类别,这让小目标检测难上加难。近期,一篇聚焦自动驾驶场景级联式开放词汇小目标检测的论文《Cas-OVD: Cascaded Open-Vocabulary Detection of Small Objects Using Multi-Refined Region Proposal Network in Autonomous Driving》给出了全新解决方案,不仅填补了开放词汇小目标检测的研究空白,还在多个数据集上实现了性能大幅超越!
论文信息
题目:Cas-OVD: Cascaded Open-Vocabulary Detection of Small Objects Using Multi-Refined Region Proposal Network in Autonomous Driving
Cas-OVD:基于多精炼区域提议网络的自动驾驶场景级联式开放词汇小目标检测
作者:Zhenyu Fang, Yulong Wu, Jinchang Ren, Jiangbin Zheng, Yijun Yan, Lixiang Zhang
一、痛点直击:开放词汇小目标检测的两大核心难题
传统开放词汇检测(OVD)模型虽能借助CLIP等图文预训练模型识别未知类别,但在小目标检测上却力不从心:
- 区域提议易漏检:传统RPN的锚点采样策略会过滤掉大量小目标锚点,导致小目标候选区域生成不足,尤其是未见过的新类别小目标,几乎无法被捕捉;
- 图文对齐不精准:小目标视觉特征稀疏,难以与文本描述建立稳健的语义关联,容易出现“图文匹配失败”,产生假阴性检测结果。
更关键的是,现有通用数据集中小目标样本少、类别不平衡,进一步削弱了模型在小目标检测任务中的表现。针对这些问题,研究团队提出了Cas-OVD框架,从提议生成到特征对齐全流程优化,精准攻克小目标检测痛点。
二、核心创新:Cas-OVD的四大突破点
1. 首创级联式开放词汇检测框架,聚焦小目标图文细粒度对齐
Cas-OVD是首个专门针对自动驾驶场景开放词汇小目标检测设计的级联框架,基于多阶段检测流水线构建,将“文本-视觉对齐”定位为提升小目标检测性能的核心,通过迭代精炼的方式,逐步缩小小目标视觉特征与文本描述的差距,填补了开放词汇小目标检测的研究空白。
2. 多精炼RPN(MR-RPN):让小目标锚点“一个都不少”
传统RPN会通过采样筛选锚点,导致小目标锚点被大量丢弃。MR-RPN采用非采样锚点策略,保留完整锚点集(),确保每个小目标都有足够的候选区域;同时设计特征转换模块(基于可变形卷积),能根据小目标的形状、尺寸动态调整特征提取过程,自适应捕捉小目标的空间变形特征,大幅提升提议质量和召回率。
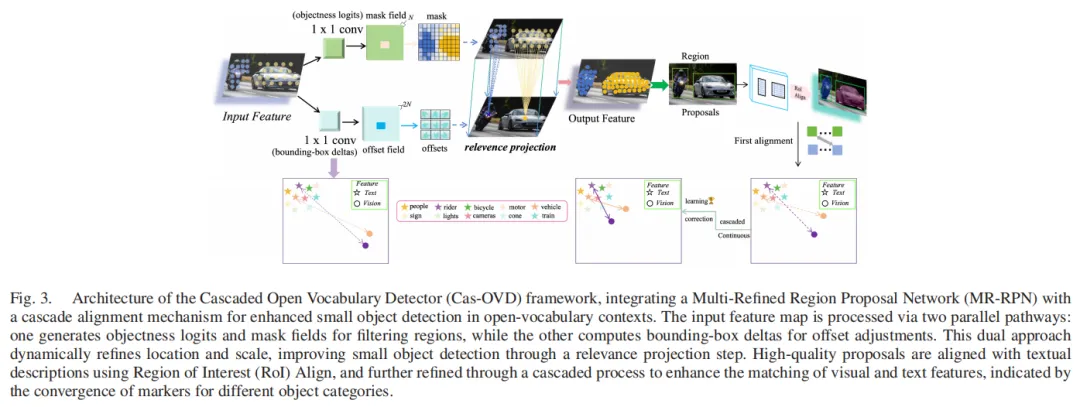 图3:特征转换模块结构,可变形卷积根据锚点动态调整偏移量,适配小目标形状尺寸
图3:特征转换模块结构,可变形卷积根据锚点动态调整偏移量,适配小目标形状尺寸
3. 级联对齐机制:迭代精炼图文特征关联
不同于现有方法依赖粗粒度图文匹配,Cas-OVD引入级联对齐机制,每一个阶段都基于前一阶段的结果优化图像区域与文本描述的特征关联。通过连续的误差修正,逐步增强小目标的语义表示,同时降低背景噪声干扰,让模型对小目标的适应性显著提升。
4. 多元验证数据集:补齐小目标样本短板
研究团队将BDD100K与SODA-D、KITTI与VisDrone数据集分别融合,构建了两个全新的自动驾驶小目标检测数据集。融合后的数据集丰富了不同场景(城市/乡村、不同天气)、不同视角下的小目标实例,让模型训练更充分,验证结果更具说服力。
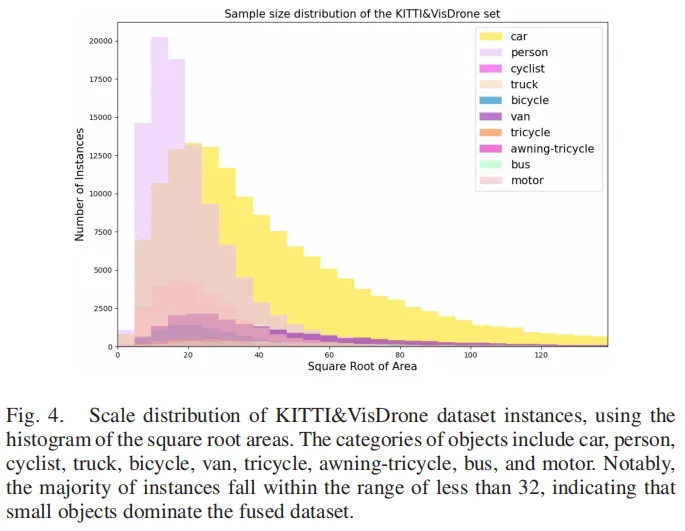 图4:KITTI和VisDrone2019数据集的实例分布,融合后显著提升小目标样本多样性
图4:KITTI和VisDrone2019数据集的实例分布,融合后显著提升小目标样本多样性
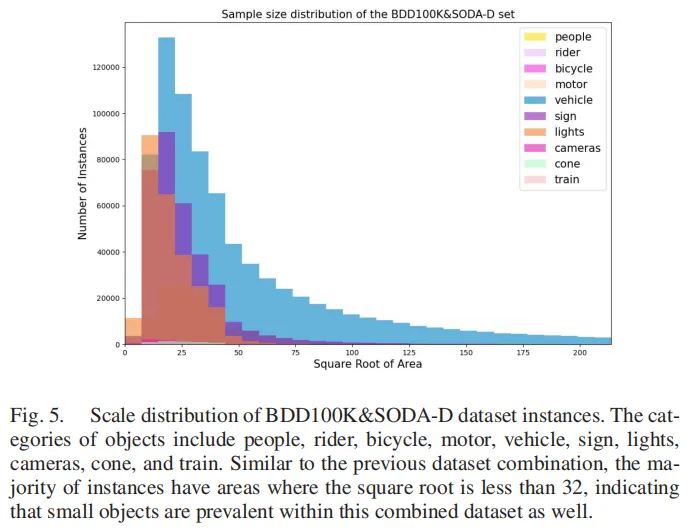 图5:BDD100K和SODA-D数据集融合后的实例分布,覆盖更多自动驾驶场景小目标
图5:BDD100K和SODA-D数据集融合后的实例分布,覆盖更多自动驾驶场景小目标
三、方法全貌:Cas-OVD整体架构解析
Cas-OVD的核心架构整合了MR-RPN和级联对齐机制,整体流程清晰且针对性强:
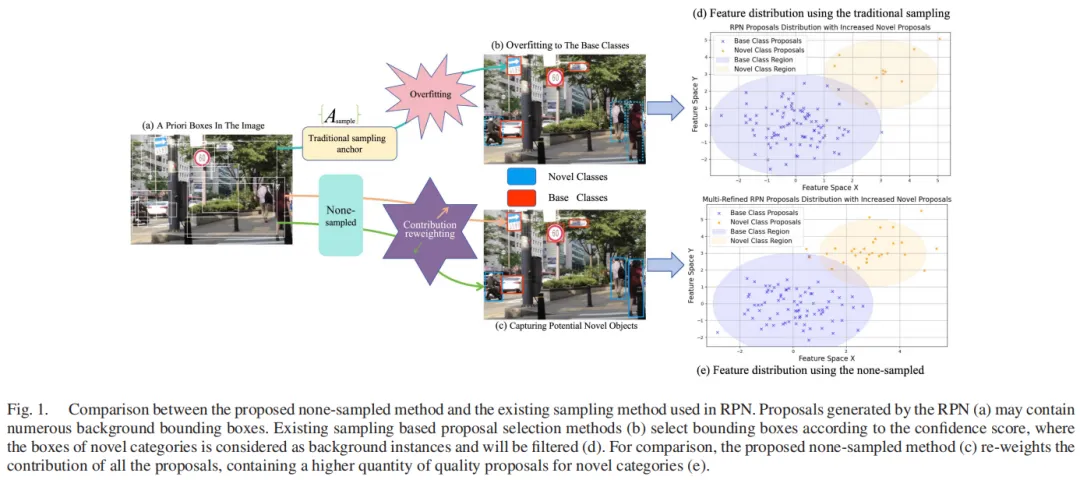 Fig.1:Cas-OVD框架与传统RPN方法的对比,(c)为多精炼RPN,(e)为Cas-OVD检测效果,可有效捕捉新类别小目标
Fig.1:Cas-OVD框架与传统RPN方法的对比,(c)为多精炼RPN,(e)为Cas-OVD检测效果,可有效捕捉新类别小目标
- 特征提取:输入图像经ResNet50提取初始视觉特征;
- MR-RPN生成提议:非采样锚点策略生成全覆盖的候选区域,特征转换模块动态适配小目标特征,输出高质量小目标提议;
- 文本特征构建:将数据集类别转换为包含上下文的自然语言描述(如“移动中的汽车在路上”),经文本编码器生成文本特征;
- 级联对齐检测:多阶段迭代精炼视觉-文本特征匹配,逐步提高IoU阈值,优化边界框回归和分类,最终输出精准的小目标检测结果。
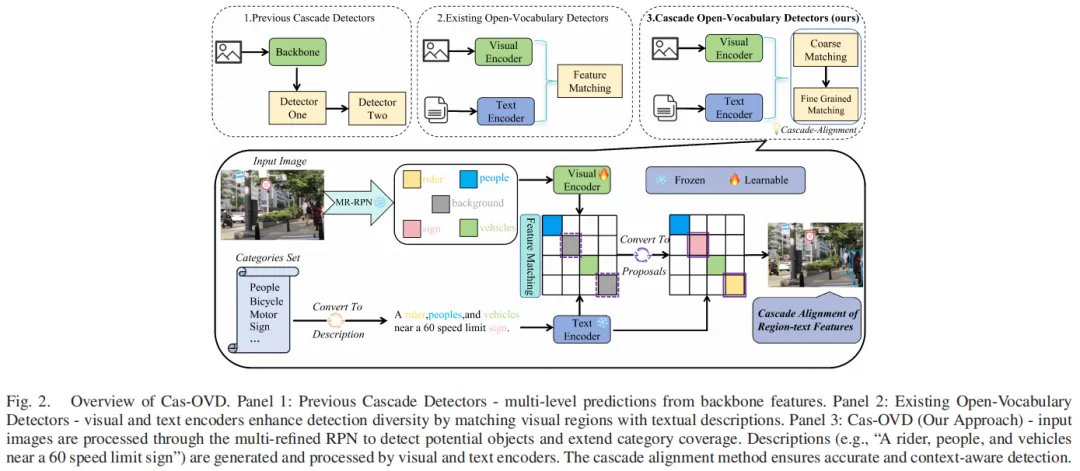 Fig.2:Cas-OVD整体架构图,集成MR-RPN和级联对齐机制,实现小目标图文特征逐步精炼
Fig.2:Cas-OVD整体架构图,集成MR-RPN和级联对齐机制,实现小目标图文特征逐步精炼
四、实验验证:性能全面超越现有方法
1. 数据集与评估指标
研究团队在融合后的BDD100K&SODA-D、KITTI&VisDrone,以及OV_COCO数据集上开展实验,采用(整体平均精度)、(小目标平均精度)、(小目标平均召回率)等核心指标评估。
2. 核心结果
- 在BDD100K&SODA-D数据集上,Cas-OVD的达17.95%,达14.6%,分别比RegionCLIP高出3.5%和3.0%;
- 在OV_COCO数据集上,为32.71%,为17.26%,较RegionCLIP提升6.6%和6.1%;
- MR-RPN的(新类别提议召回率)显著高于Cascade-RPN、GA-RPN等传统方法,证明其对新类别小目标的覆盖能力更强。
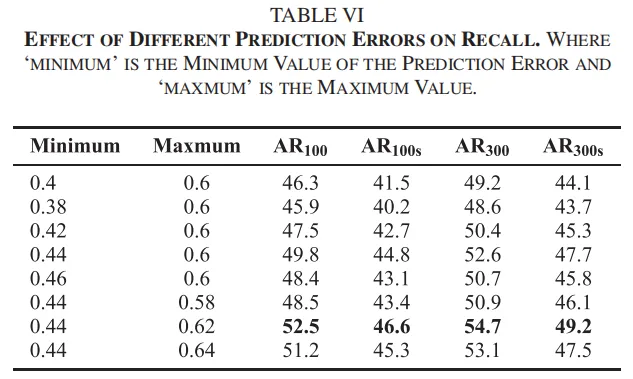 Fig.7:不同RPN模型检测效果对比,(e)为MR-RPN,可精准检测更多小目标
Fig.7:不同RPN模型检测效果对比,(e)为MR-RPN,可精准检测更多小目标
3. 消融研究:关键参数的最优选择
- 预测误差范围:聚焦[0.44, 0.62]的中等难度样本,能最大化小目标召回率,达46.6;
- 损失权重:分类损失权重、回归损失权重时,模型定位小目标的能力最优;
- 模块有效性:MR-RPN+级联对齐的组合,较单一MR-RPN进一步提升小目标检测精度。
五、挑战与展望
尽管Cas-OVD表现优异,但在低能见度场景(夜间、雾天)仍存在挑战——小目标特征区分度低,易出现边界框不准确、漏检等问题。未来可从两方面优化:
- 增强恶劣环境下的特征提取技术,提升小目标特征的鲁棒性;
- 融合更大规模的图文预训练数据,进一步强化文本-视觉对齐效果。
总结
Cas-OVD通过“多精炼RPN+级联对齐”的创新组合,精准解决了开放词汇场景下小目标检测的漏检、图文对齐不精准等核心问题,不仅在多个数据集上验证了有效性,也为自动驾驶视觉感知的落地提供了新的技术思路。这一研究再次证明,针对小目标的精细化特征处理和图文对齐优化,是突破开放词汇检测性能瓶颈的关键方向。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
