
🚗 自动驾驶论文看花眼?龙哥带你直击核心!今天这篇Drive-JEPA,巧妙融合了视频预测和模拟器蒸馏,让AI司机不仅会“看路”,更学会了“预判”和“多选”。想每天2分钟刷完AI领域最新论文、资讯、代码和招聘?「龙哥读论文」知识星球让你快人一步,一站式拿捏前沿干货!👇扫码加入,和龙哥一起探索AI驾驶的未来~
龙哥推荐理由:
这篇论文解决了端到端自动驾驶的两个核心痛点:如何从视频中学习有效的规划表征,以及如何突破单一人驾轨迹的监督瓶颈。它没有使用昂贵的像素级重建,而是通过高效的V-JEPA预训练让模型学会“预测未来”的潜在特征。更妙的是,它向模拟器“偷师”,蒸馏出多样化的安全驾驶方案来指导模型,最终在多个权威基准上刷新了纪录。方法设计清晰,实验结果扎实,对推动自动驾驶的“大脑”进化很有启发性。
原论文信息如下:
论文标题:
Drive-JEPA: Video JEPA Meets Multimodal Trajectory Distillation for End-to-End Driving
发表日期:
2026年01月
发表单位:
未明确列出(作者来自多个机构)
原文链接:
https://arxiv.org/pdf/2601.22032v1.pdf
开源代码链接:
https://github.com/linhanwang/Drive-JEPA
朋友们,想象一下这个场景:你的自动驾驶汽车正平稳行驶,前方路口突然窜出一只小狗。一个优秀的AI司机应该怎么做?是紧急刹车,还是稳妥地绕开,或者根据路况微调方向?更厉害的是,它能不能提前几秒就“感觉”到可能有状况,预先准备好多种应对方案?这背后,是端到端自动驾驶面临的两大核心难题:1. 如何从海量视频中真正学会“预测”未来场景的动态? 2. 如何突破单一人类驾驶轨迹的局限,让AI学会像老司机一样,拥有多种安全且合理的驾驶选择?今天龙哥要聊的这篇论文——Drive-JEPA,就交出了一份漂亮的答卷。它没有堆砌更复杂的模型,而是用两个巧妙的思路,让自动驾驶的“大脑”变得更聪明、更稳健。不仅在多个权威测试中刷榜,一些设计理念也让人眼前一亮。🤔Drive-JEPA:如何让自动驾驶汽车“想”得更远更稳?
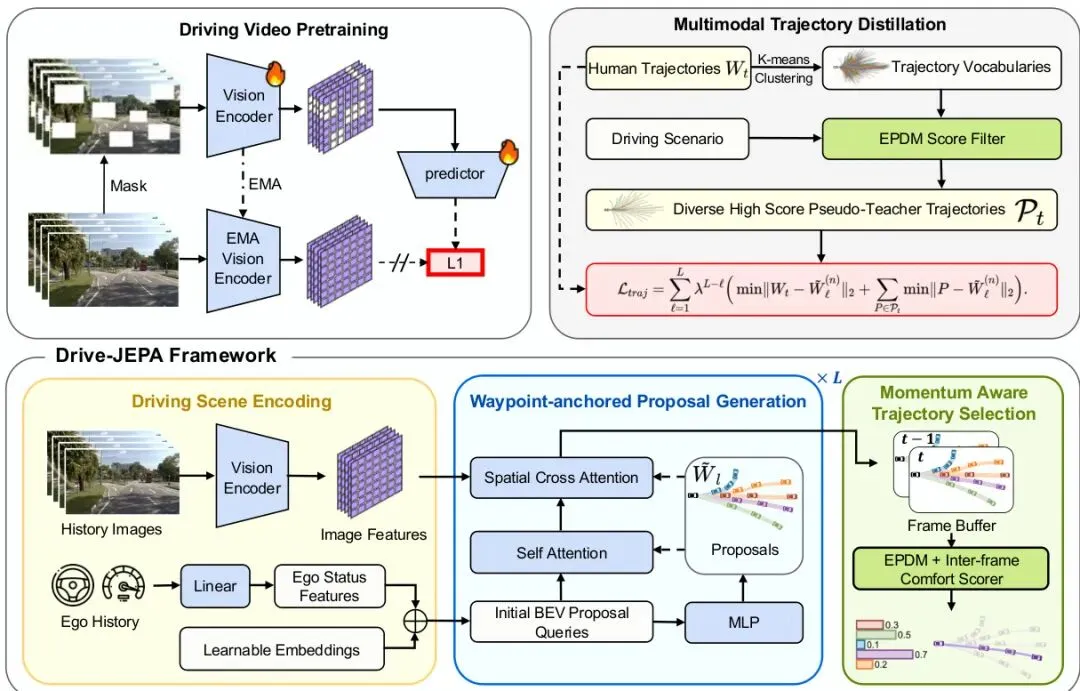
简单来说,Drive-JEPA做了一件很酷的事:它把视频预测学习和多轨迹知识蒸馏这两个招式,融进了一个端到端自动驾驶框架里。它的名字已经剧透了核心:Drive代表自动驾驶,JEPA则是它的第一个绝招——Joint-Embedding Predictive Architecture(联合嵌入预测架构)。这是一种自监督学习方法,不是让模型去费力地“画”出未来视频的每个像素(那太费算力了),而是让它学会预测未来画面的“本质特征”。这就好比不是预测下一帧照片的每个色彩点,而是预测“接下来画面里物体会怎么移动、场景会如何变化”这种高级信息。图2:Drive-JEPA的整体架构概览。核心分为三步:驾驶视频预训练学习一个强大的视觉编码器;路径点锚定方案生成模块在线产生多种轨迹方案;最后通过动量感知的轨迹选择模块,挑出最安全、最舒适的一条。框架的运作流程就像一位经验丰富的指挥官:首先,视觉编码器(ViT)像眼睛一样观察前方路况(单目摄像头就够了)。接着,规划器会一口气生成几十条可能的未来行驶轨迹(比如32条),这些轨迹方案覆盖了加速、减速、绕行等多种可能性。最后,一个打分器会评估每条方案的安全性、合规性和舒适度,并综合考量前后决策的连贯性,选出最优解来执行。核心突破一:用视频预训练教会模型“预测未来”
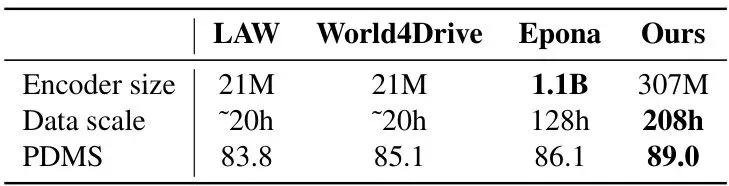
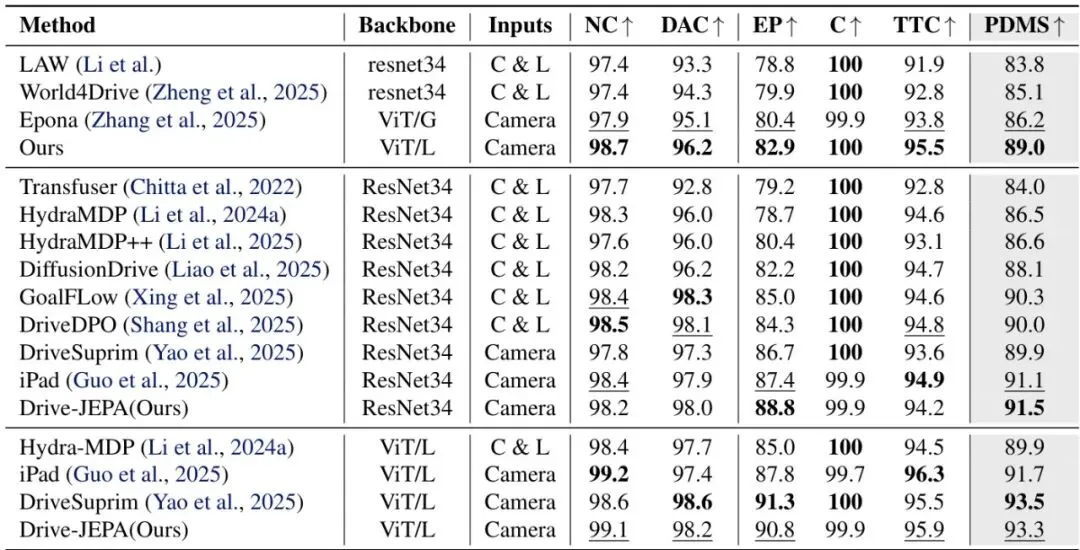
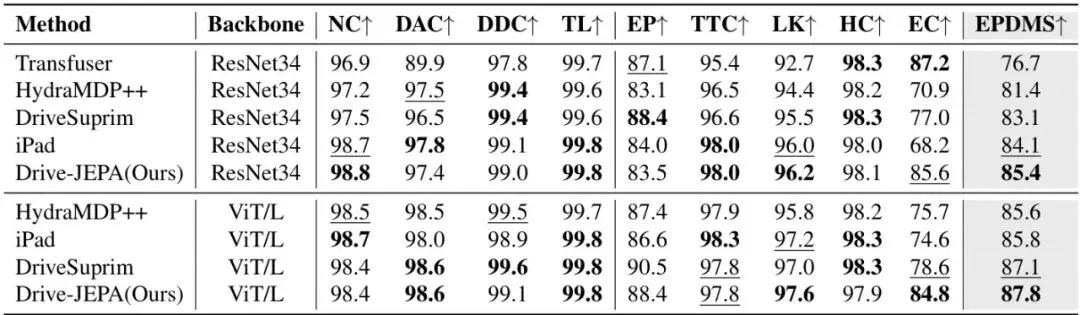
想让AI开车开得好,先得让它“看”得懂。以前的思路要么是让模型重建整个视频(计算量大,还容易纠结于无关的视觉细节),要么是预测下一帧的抽象特征,但效果提升有限。Drive-JEPA请来了V-JEPA(Video JEPA)这位“教练”。它的训练方式很聪明:给模型看一段驾驶视频,但随机遮挡(Mask)掉其中一部分时空片段,然后让它根据看到的部分,去预测被遮挡部分的特征。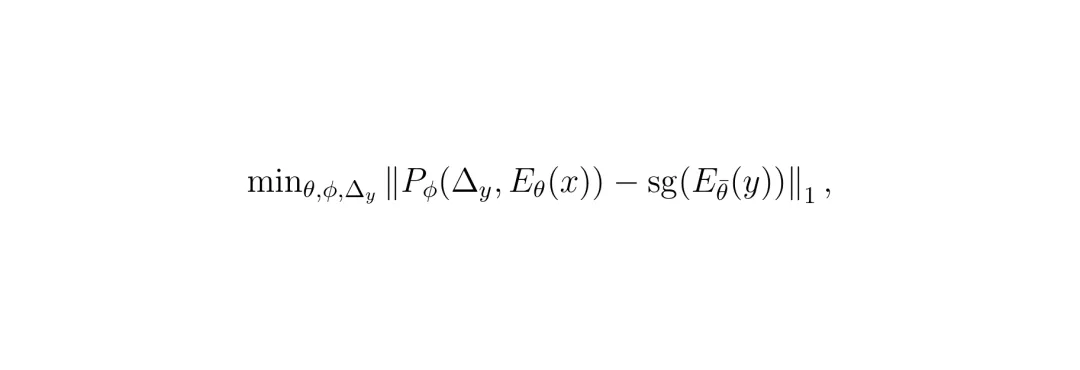 这就是V-JEPA的核心目标函数。简单说,就是让预测器Pφ根据编码器Eθ看到的画面(x),去预测目标编码器Eθ̄看到的画面(y)的特征。sg(·)代表“停止梯度”,θ̄是θ的滑动平均,这种设计能有效防止训练崩溃,学到的特征更稳定。这就好比在驾校里,教练把后视镜或部分车窗暂时遮住,让学员仅凭前方和侧方的有限信息,推断车身周围和后方的情况。长期这样训练,模型就学会了从动态序列中提取对未来规划最有用的时空特征,而不是死记硬背画面细节。论文作者们攒了一个长达208小时的大规模驾驶视频数据集,在这个数据集上对ViT编码器进行了V-JEPA预训练。效果有多明显呢?在完全不依赖任何感知标注(如3D框、车道线)的“纯规划”设定下,仅仅把这个预训练好的编码器,搭配一个轻量的Transformer解码器,就能取得惊人的效果。表1:与之前感知无关规划器的对比。可以看到,Drive-JEPA(Ours)在使用更少输入(仅前视相机)和可比的模型大小下,PDMS分数大幅领先。这充分说明了V-JEPA预训练学到的表征对于规划任务的有效性。
这就是V-JEPA的核心目标函数。简单说,就是让预测器Pφ根据编码器Eθ看到的画面(x),去预测目标编码器Eθ̄看到的画面(y)的特征。sg(·)代表“停止梯度”,θ̄是θ的滑动平均,这种设计能有效防止训练崩溃,学到的特征更稳定。这就好比在驾校里,教练把后视镜或部分车窗暂时遮住,让学员仅凭前方和侧方的有限信息,推断车身周围和后方的情况。长期这样训练,模型就学会了从动态序列中提取对未来规划最有用的时空特征,而不是死记硬背画面细节。论文作者们攒了一个长达208小时的大规模驾驶视频数据集,在这个数据集上对ViT编码器进行了V-JEPA预训练。效果有多明显呢?在完全不依赖任何感知标注(如3D框、车道线)的“纯规划”设定下,仅仅把这个预训练好的编码器,搭配一个轻量的Transformer解码器,就能取得惊人的效果。表1:与之前感知无关规划器的对比。可以看到,Drive-JEPA(Ours)在使用更少输入(仅前视相机)和可比的模型大小下,PDMS分数大幅领先。这充分说明了V-JEPA预训练学到的表征对于规划任务的有效性。核心突破二:向模拟器“偷师”,生成多模态驾驶方案
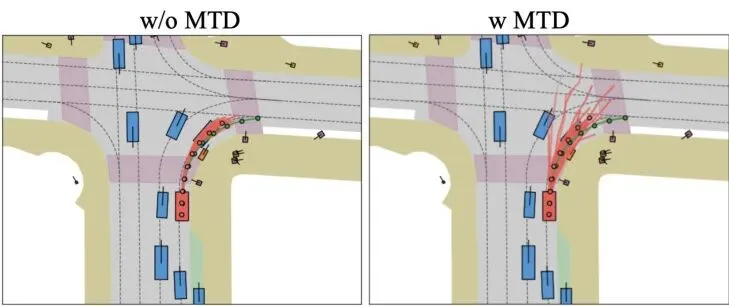
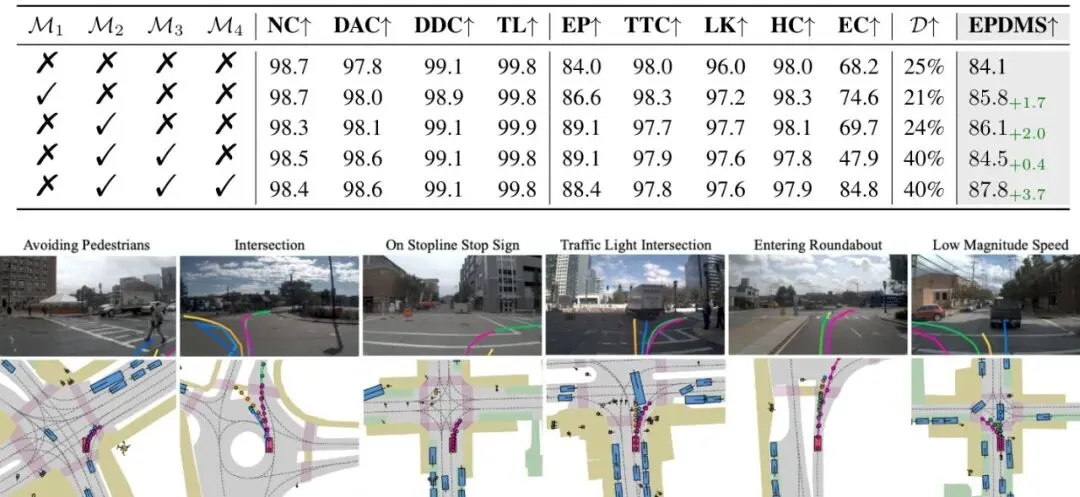
模型的眼睛变尖了,下一步是让它的“决策脑”变得更灵活。一个现实难题是:我们训练AI用的数据,每段路通常只有一条人类司机实际开的轨迹。但真正开车时,同一场景下往往有多种合法、安全且合理的开法(比如稍微靠左或靠右一点)。只学一条,模型容易变得僵化,遇到突发状况可能反应不过来。图3:鸟瞰视角下的轨迹方案对比。左侧没有多模态轨迹蒸馏,所有方案挤在一起(模式坍塌);右侧使用了蒸馏,方案呈现出健康的多模态分布,覆盖了更多可能性。Drive-JEPA的解决办法是:向规则模拟器“偷师”!它准备了一个包含8192条标准轨迹的“题库”(通过聚类真实轨迹得到)。对于训练数据中的每一个场景,它都用模拟器去快速“跑一遍”题库里的所有轨迹,根据安全、合规、舒适等指标(如EPDMS分数)打分,然后筛选出得分最高的一批“伪教师”轨迹。在训练规划器生成多条候选轨迹时,损失函数就不再只盯着那一条人类轨迹了,而是同时让生成的轨迹去靠近这些高质量的“伪教师”轨迹。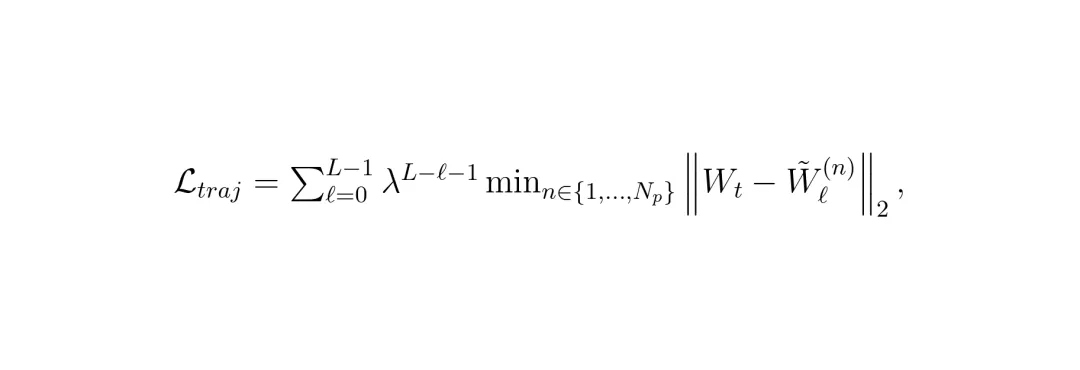 原始的轨迹损失,只让生成的方案(W̃ℓ(n))去逼近唯一的人类轨迹(Wt)。
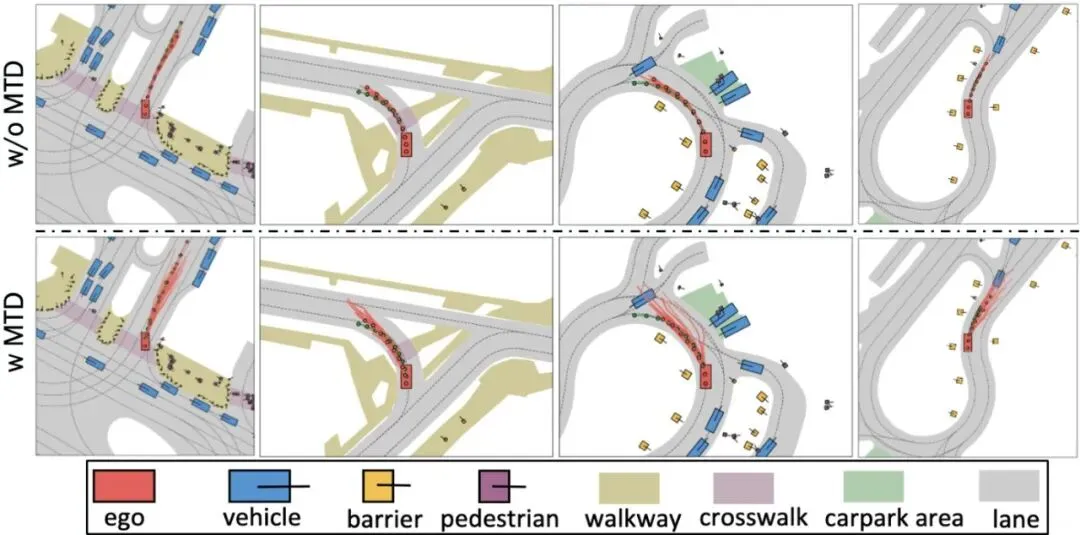
原始的轨迹损失,只让生成的方案(W̃ℓ(n))去逼近唯一的人类轨迹(Wt)。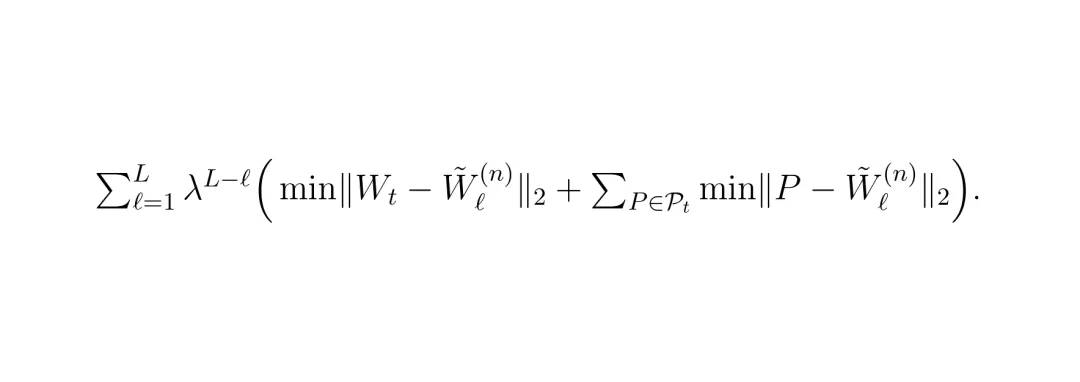 加入多模态轨迹蒸馏后,损失函数变为同时逼近人类轨迹和多个高质量的伪教师轨迹(P ∈ Pt)。λ是衰减因子,让模型在迭代后期更精细地调整。这个“多模态轨迹蒸馏”(Multimodal Trajectory Distillation, MTD)的妙处在于:它利用离线模拟低成本地获得了大量“如果…会怎样”的优质答案,从而让AI在学习时,见识了更丰富的驾驶可能性,决策时自然就更从容、更多元。图6:另一个视角的轨迹方案对比,再次验证了MTD对于防止模式坍塌、促进多模态分布的关键作用。
加入多模态轨迹蒸馏后,损失函数变为同时逼近人类轨迹和多个高质量的伪教师轨迹(P ∈ Pt)。λ是衰减因子,让模型在迭代后期更精细地调整。这个“多模态轨迹蒸馏”(Multimodal Trajectory Distillation, MTD)的妙处在于:它利用离线模拟低成本地获得了大量“如果…会怎样”的优质答案,从而让AI在学习时,见识了更丰富的驾驶可能性,决策时自然就更从容、更多元。图6:另一个视角的轨迹方案对比,再次验证了MTD对于防止模式坍塌、促进多模态分布的关键作用。核心突破三:引入“动量”思维,让驾驶决策更平滑舒适
方案多了是好事,但也可能带来新问题:相邻两帧之间,选出的最优轨迹如果差异太大,会导致车辆“摇摆不定”,乘坐体验极差。Drive-JEPA在最后的选择环节,加入了一个“动量感知”的机制。简单说,就是给打分过程加了一个“记忆项”:在选择当前帧的最佳轨迹时,不仅要看它本身的安全性分数(S),还要考虑它与上一帧已执行轨迹(Ŵt-1)的连贯性,计算一个舒适度分数(Sc)。 最终的得分由原安全分数(占7/8)和舒适度分数(占1/8)加权得到。这个权重参考了评测标准。这就好比一位老司机,在决定下一刻怎么开时,会自然而然地让动作承接上一个动作,而不是每次都从零开始做一个突兀的新决定。这个小小的设计,显著提升了乘坐的平滑感和舒适度。
最终的得分由原安全分数(占7/8)和舒适度分数(占1/8)加权得到。这个权重参考了评测标准。这就好比一位老司机,在决定下一刻怎么开时,会自然而然地让动作承接上一个动作,而不是每次都从零开始做一个突兀的新决定。这个小小的设计,显著提升了乘坐的平滑感和舒适度。实验结果:多项基准测试刷新纪录
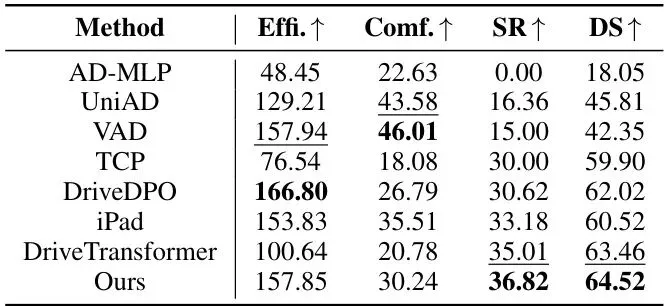
光说原理不够,是骡子是马得拉出来溜溜。Drive-JEPA在三个主流的自动驾驶基准测试上接受了检验。这是目前最受关注的开环规划评测基准。它不直接控制车辆,而是用模拟器来评估输出轨迹的质量。v2比v1的评估维度更细,加入了更多交通规则和舒适度指标。表2:在NAVSIM v1上的量化对比。Drive-JEPA在多种骨干网络(ResNet34, ViT/L)下都取得了领先或极具竞争力的成绩,尤其是在纯相机输入的设定下表现突出。表3:在更严苛的NAVSIM v2上的结果。Drive-JEPA(Ours)在最终的综合指标EPDMS上,无论是ResNet34还是ViT/L骨干,均取得了最佳成绩(87.8),创造了新的State-of-the-Art(SOTA)。特别值得注意的是,其在扩展舒适度(EC)这一项上优势明显,这直接体现了动量感知选择机制的有效性。这是一个在CARLA模拟器中进行的闭环评测基准,要求模型实时控制车辆完成复杂、交互性强的城市驾驶任务,更接近真实应用场景。表4:在Bench2Drive上的对比。Drive-JEPA取得了最高的驾驶分数(DS),并且在效率(Effi.)和成功率(SR)上表现也很出色。相比同为方案中心化(proposal-centric)方法的iPad,DS提升了4分,这验证了多模态轨迹蒸馏在复杂闭环交互中的价值。图4:不同模型在各种驾驶场景下(前视视角和鸟瞰视角)的轨迹定性对比。可以看到,Drive-JEPA生成的轨迹(绿色)更接近人类轨迹(红色),并且在复杂路口和变道场景下表现得更加合理、果断。实验结果充分说明,Drive-JEPA这套组合拳确实有效,不仅在精度上领先,在驾驶的多样性、安全性和舒适性上也取得了很好的平衡。未来展望与启发
Drive-JEPA给我们展示了两个清晰的思路,对未来的研究和应用很有启发:
1. 自监督预训练的价值凸显:在自动驾驶这种对时序动态理解要求极高的任务上,像V-JEPA这类专注于学习预测性、动态表征的自监督方法,比单纯在ImageNet上分类图片的预训练模型,能带来更直接的性能增益。未来,针对驾驶场景定制化、更大规模的视频预训练可能会成为标配。
2. “模拟器蒸馏”的范式潜力:如何突破有限、有噪声的真实数据瓶颈?Drive-JEPA提供了一个优雅的答案:利用高性能但可能耗时的模拟器(或规则系统),离线生成大量高质量的“教学范例”,再通过蒸馏的方式注入到高效的端到端模型中。这种“离线模拟,在线蒸馏”的思路,可以推广到许多需要学习多样化、安全策略的决策任务中。
当然,论文本身也提到,方法目前主要是在仿真和特定数据集上验证。要真正上车,还需要在极端天气、传感器故障、长尾场景等方面进行更严苛的测试和工程优化。龙迷三问
这篇论文解决的核心问题是什么?本文主要解决了端到端自动驾驶中的两个关键瓶颈:一是如何从大规模无标签驾驶视频中,高效地学习对规划任务有价值的时空动态表征;二是在训练数据每帧只有一条人类轨迹的监督下,如何让模型学会生成并选择多样化的、安全合理的驾驶行为,避免决策模式单一和僵化。
文中的BEV和ViT分别代表什么?BEV是Bird‘s-Eye View的缩写,即鸟瞰视角。在自动驾驶中,通常将多个相机的图像特征转换到一个统一的、自上而下的二维平面坐标系中,便于进行目标检测、车道线理解和轨迹规划。ViT是Vision Transformer的缩写,是一种基于Transformer架构的视觉模型,已广泛应用于图像和视频理解任务,本文用它作为视觉编码器的主干网络。
PDMS和EPDMS这两个指标是什么意思?它们是NAVSIM评测基准的核心指标。PDMS是Predictive Driver Model Score(预测性驾驶员模型分数),综合了无过错碰撞、可行驶区域合规、自我进度、舒适度和碰撞时间等多个子项。EPDMS是Extended PDMS,在PDMS基础上进一步加入了驾驶方向合规、交通灯合规、车道保持等更细致的交通规则评估,以及更长时域的舒适度评估,因此更全面、更严格。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
将V-JEPA这一前沿的视频自监督表征学习方法,与多模态轨迹蒸馏巧妙地结合到端到端驾驶框架中,思路清晰且有新意。“动量感知选择”也是一个提升体验的实用设计。整体创新性属于优秀水准。实验合理度:★★★★☆
在NAVSIM v1/v2和Bench2Drive三个主流且有挑战性的基准上进行了充分测试,并设置了感知无关的对比实验,结果具有说服力。消融实验也清晰展示了各模块的贡献。学术研究价值:★★★★☆
为自动驾驶的规划表征学习和多模态决策提供了新的、有效的技术路径。尤其是“模拟器蒸馏”的思路,对缓解数据瓶颈有很高的启发价值,值得相关领域研究者关注和借鉴。稳定性:★★★☆☆
在论文限定的仿真和数据集环境下表现稳定。但作为端到端系统,其稳定性严重依赖于视觉编码器的鲁棒性(如恶劣天气、强光)和模拟器生成的“伪教师”轨迹的质量。真实世界的复杂性是更大的考验。适应性以及泛化能力:★★★☆☆
框架设计具有一定通用性。然而,其性能与预训练数据、轨迹词汇表以及规则模拟器的领域紧密相关。要泛化到全新的城市、交通规则或驾驶文化,可能需要重新进行数据收集和模拟器适配。硬件需求及成本:★★★☆☆
推理阶段相对高效,主要计算量在视觉编码器(ViT)和方案生成迭代上。但训练成本不低,包括大规模视频预训练和离线模拟器打分。ViT-Large模型在实际车载芯片上的部署也需要优化。复现难度:★★★★☆
论文描述清晰,代码已开源。主要难点在于复现需要收集或构建同等规模和质量的多源驾驶视频数据集,以及实现高效的离线轨迹模拟评分管道。对计算资源也有一定要求。产品化成熟度:★★☆☆☆
目前仍处于前沿研究阶段。虽然基准测试成绩优异,但距离上车应用还有很长的路要走。需要经过海量实车数据闭环迭代、极端场景安全验证、系统冗余设计、与规控模块深度集成等工程化步骤。可能的问题:论文方法的核心依赖之一是高保真的规则模拟器来生成“伪教师”轨迹。模拟器与真实世界的差距(Sim2Real Gap)会直接影响到蒸馏知识的质量。在高度动态、交互复杂的场景中,模拟器的行为模型是否足够真实,是一个潜在的风险点。
[1] Linhan Wang, Zichong Yang, Chen Bai, et al. Drive-JEPA: Video JEPA Meets Multimodal Trajectory Distillation for End-to-End Driving. arXiv preprint arXiv:2601.22032, 2026. (本论文)[2] Assran, M., Bardes, A., et al. V-JEPA 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985, 2025.[3] Dauner, D., Hallgarten, M., et al. Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking. Advances in Neural Information Processing Systems, 37, 2024.[4] Jia, X., Yang, Z., et al. Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving. In NeurIPS 2024 Datasets and Benchmarks Track, 2024.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

想和更多自动驾驶、机器人领域的小伙伴一起探讨Drive-JEPA这样的前沿技术吗?欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+清华+龙哥),根据格式备注,可更快被通过且邀请进群。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
