
辞旧迎新,知识续航!「龙哥读论文」陪你跨年,知识星球会员优惠券限时限量放送!🐉 「龙哥读论文」知识星球:让你看论文像刷视频一样简单!公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇论文瞄准了自动驾驶场景理解中的一个核心痛点:如何兼顾“已知”与“未知”。它没有选择单一的预测路线,而是巧妙地融合了“车辆语义预测”和“通用动态占据预测”,通过一个精心设计的“流引导”损失函数将它们统一起来。这种思路非常务实,既利用了深度学习对特定对象(如车辆)的强大识别能力,又保留了传统占据栅格方法对任何动态物体(包括未识别或遮挡物体)的泛化感知优势,相当于给自动驾驶系统上了“双保险”。对于追求系统鲁棒性和安全性的研究者和工程师来说,这篇论文提供了一个极具启发性的框架。
原论文信息如下:
论文标题:
Integrating Specialized and Generic Agent Motion Prediction with Dynamic Occupancy Grid Maps
发表日期:
2026年02月
发表单位:
未明确标注,作者来自法国相关研究机构
原文链接:
https://arxiv.org/pdf/2602.07938v1.pdf
龙哥有言在先:自动驾驶的“眼神儿”好不好,关键看它能不能猜到下一秒会发生啥。是只认识车,还是连乱窜的猫猫狗狗、被遮挡的行人都能防住?今天这篇论文,就给你看一套“双管齐下”的绝活儿。
想象一下,你开车在路上,前方有一辆出租车正打着右转向灯。你心里大概能猜到它可能要靠边停车。这时候,你的注意力可能还会分散到路边一个被公交车遮挡了一半、若隐若现的行人身上,虽然他还没完全进入你的视野,但你的大脑已经拉响了警报。
这就是人类驾驶的“预测”能力:既理解特定对象(比如那辆出租车)的明确意图,也对环境中任何潜在的、未明确识别的动态(比如那个行人)保持警惕。
然而,让AI学会这种“双线思考”却是个大难题。过去的自动驾驶预测模型基本是两条路:
路线A:专用代理预测 (Agent-Specific Prediction)。这类模型就像“认脸专家”,利用摄像头图像识别出具体的车辆、行人、自行车等,然后追踪它们的轨迹,预测它们未来的行为。优势是能理解具体对象的意图(比如变道、转弯),缺点是“脸盲”——如果传感器没看清、没识别出来,或者遇到了训练集里没有的新奇物体(比如一只大鹅🐶),它就彻底抓瞎了。
路线B:通用动态占据预测 (Agent-Agnostic Dynamic Occupancy Prediction)。这类模型不关心“它是谁”,只关心“那里有没有东西在动”。它通常使用激光雷达点云生成鸟瞰图下的动态占据栅格地图 (DOGM,Dynamic Occupancy Grid Map),把环境划分成一个个小格子,每个格子都有一个概率值表示它被静态/动态物体占据的可能性。这个方法泛化能力强,任何动的“像素”都能感知到,但它是个“细节控”,很难理解整体行为(比如那是个“正在右转的车”而不是“一堆正在向右平移的格子”)。
那有没有可能把A和B的优点结合起来,让自动驾驶系统既有“认脸”的智慧,又有“感知任何风吹草动”的警觉呢?
融合之道:如何让自动驾驶系统既认识“车”又感知“动”?
这篇来自法国研究机构的论文《Integrating Specialized and Generic Agent Motion Prediction with Dynamic Occupancy Grid Maps》就给出了一套漂亮的解决方案。它的核心思想非常直观:“两手都要抓,两手都要硬”,但关键在于用一个聪明的“粘合剂”把这两手预测统一起来。
这个“粘合剂”就是场景流 (Scene Flow)。简单来说,场景流就是每个像素点(在鸟瞰图里是每个栅格)的运动矢量,告诉你它下一秒会移动到哪去。论文作者认为,无论是具体的车辆,还是未知的动态物体,它们的运动都应该遵循一致的物理规律,而这个规律就体现在“流”里。
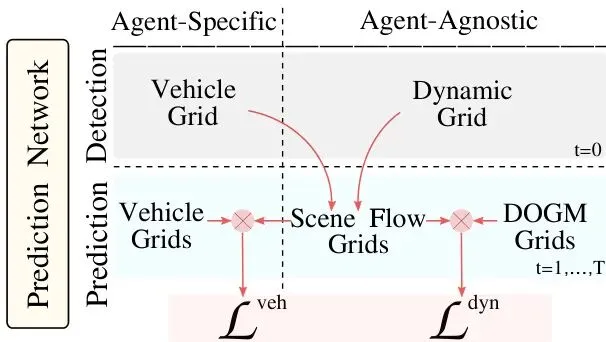
图1:本方法生成检测和预测网格,用于专用和通用行为。场景流网格在桥接这两类预测中起着核心作用。
如上图所示,整个框架的输入融合了两种信息:来自激光雷达的DOGM(包含占据状态和速度)和来自摄像头的车辆语义分割图。输出则是一个“三头六臂”的预测系统,同时给出:1. 当前时刻的检测:当前帧的车辆位置图 和 通用动态占据图。2. 未来序列的预测:未来几秒钟每一帧的车辆预测图 和 场景流图。3. 未来序列的DOGM预测:未来几秒钟每一帧的通用占据状态图(未知、静态、动态)。
所有这些东西不是孤立的,它们被一个精心设计的“流引导”损失函数捆绑在一起训练,确保预测的车辆运动、预测的动态占据点运动,以及预测的“流”本身,在物理逻辑上是一致的。
这就好比,你不仅预测了“那辆出租车会向右移动3米”,还预测了“它覆盖的那些格子会整体向右平移”,并且这两件事必须匹配。同时,对于那些没有被识别为车辆的“动态格子”,模型也必须为它们预测出一个合理的“流”。这样一来,即使是没被认出来的行人,模型也能根据周围格子的运动趋势,“猜”出他可能怎么动。
核心揭秘:多任务预测框架与流引导损失函数
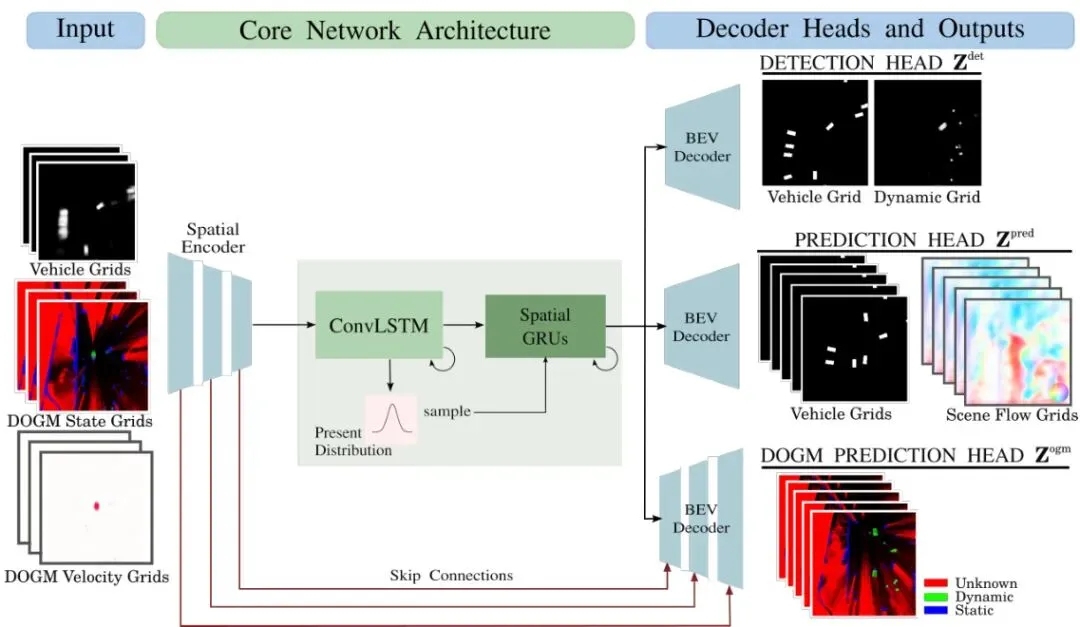
光说思想还不够,我们得看看这“三头六臂”是怎么长出来的。下面这张图清晰地展示了整个框架的流水线。
图2:提出的预测框架:输入序列包含车辆栅格、DOGM占据状态栅格和速度栅格。网络预测当前时刻的检测、未来车辆和流序列、以及未来占据状态序列。
模型吃进去的是过去1秒(3帧)的鸟瞰图序列。每帧图有6个通道,像千层饼一样叠在一起:
公式解读:这个公式定义了每一时刻的输入X_t。它将3个占据状态(未知、静态、动态),2个速度分量(v_x, v_y)和1个车辆语义分割图(S)拼接成一个6通道的张量。
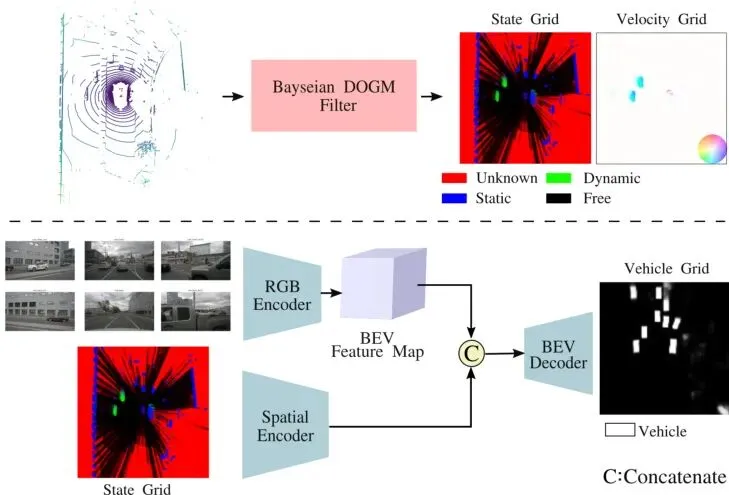
图3:场景表示:DOGM状态和速度栅格由LiDAR数据生成。为融合语义信息,从相机图像编码的BEV特征与占据状态栅格融合,以预测车辆分割栅格。
这6通道的时空序列被送入一个由卷积长短时记忆网络(ConvLSTM)构成的“理解中枢”。ConvLSTM擅长处理像视频这样的时空数据,它能记住前面几帧发生了什么,并抽取出场景变化的规律。
由于未来有多种可能性(出租车可能靠边,也可能突然直行),论文采用了条件变分自编码器的思想。简单说,模型会学习一个关于未来可能性的“概率云”。在训练时,它知道真实未来,会调整“概率云”去贴合真实情况。在预测时,它就从“概率云”里采样一个最可能的情况出来。这增加了预测的多样性,避免了总预测出“中庸”的结果。
经过“理解中枢”处理后的特征,被送到三个不同的“解码头”,分别生成前面提到的三组输出。模型最终的输出可以概括为:
公式解读:这个公式定义了模型的完整输出Ŷ,它由三部分组成:当前帧的检测结果、未来T帧的车辆与流预测序列、以及未来T帧的DOGM占据状态序列。
如果三个头各练各的,那还是“三个和尚没水喝”。本文最大的创新点在于设计了一套互相监督、环环相扣的损失函数,核心就是利用“场景流”。
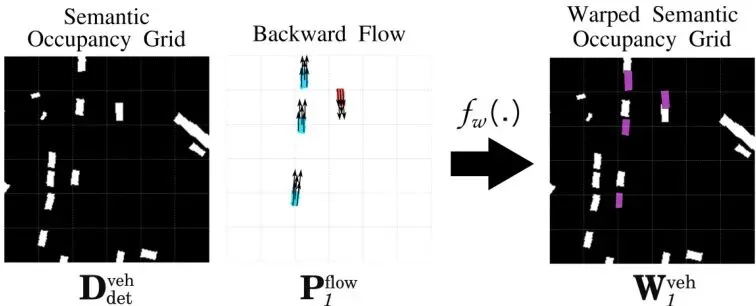
关键操作:基于流的“翘曲”。如图4所示,模型预测的“流”是一种“向后流”,意思是指向上一帧位置的向量。有了这个流和当前时刻检测到的车辆(或动态)格子,我就可以通过一个“翘曲”操作,把当前格子“搬”到它下一帧应该在的位置,从而生成一个预测的未来格子图。
图4:流引导的占据预测:翘曲操作基于运动矢量(指向其在向后流栅格中的原始位置),将初始检测栅格中的占据单元(紫色所示)进行传播。图中展示了递归过程的第一步。
精妙之处:这个“翘曲”出来的未来格子图,要和模型“直接预测”出来的未来车辆图/动态占据图进行比较,计算损失(ℒ𝒲)。这就强迫模型预测的“流”必须是准确的,否则“翘曲”结果就对不上。同时,“流”本身的预测也有损失(ℒF)。此外,每个解码头都有自己的监督损失,比如车辆预测用交叉熵损失ℒP,DOGM预测用均方误差损失ℒOGM。
公式解读:这是模型训练的核心目标,寻找一组网络参数θ*,使得预测值Ŷ和真实值Y之间的复合损失函数ℒ最小。
通过这种方式,场景流就成了连接专用预测(车辆)和通用预测(动态占据)的桥梁和“监督员”。模型被迫学习一个全局一致的运动场,这个运动场既要能解释被明确识别车辆的运动,也要能合理地推断那些未被识别物体的运动趋势。
实验验证:在真实复杂场景中表现如何?
理论很美好,实战见真章。论文在自动驾驶领域两个著名的真实数据集上进行了测试:nuScenes和Woven Planet (WP)。这两个数据集都包含城市复杂交通场景,有丰富的车辆、行人、自行车等动态元素。
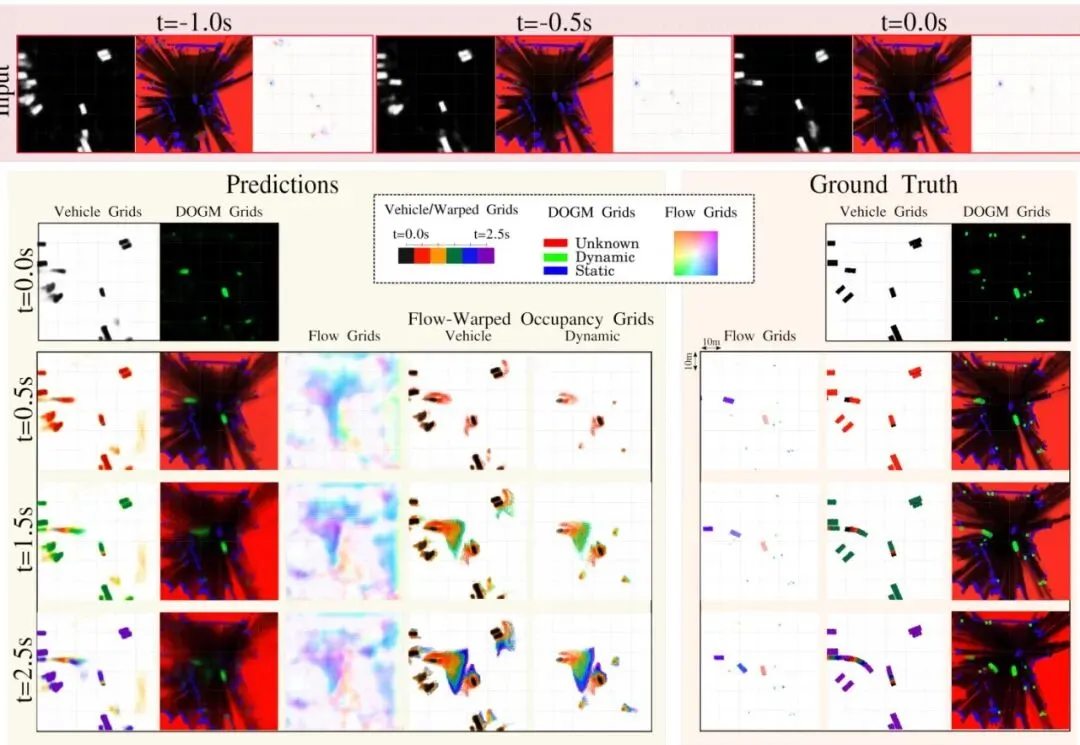
首先,我们来看一个定性展示的例子,直观感受下模型预测的效果。
图5:在Nuscenes数据集上一个驾驶场景的预测示例。场景包含两辆动态车辆、多个行人和位于栅格中心的自我车辆。左边五列是预测结果,右边三列是对应的真实值栅格。
图中可以看到,模型成功地预测了前方两辆车的运动轨迹(红色和蓝色),同时,在通用动态占据预测(O_dyn)一栏,它也将行人的运动趋势预测了出来(下方和右侧的动态区域)。这完美体现了“专用”与“通用”预测的结合。
除了预测已知动态,模型还能有效处理传感器盲区(“未知”状态)。图6展示了在快速行驶的自我车辆前方,模型如何合理预测未知区域的演变,这对于安全至关重要。
图6:在Nuscenes数据集上,一个快速行驶的自我车辆的未来未知状态栅格预测场景。
当然,光看例子不够,需要用数字说话。论文与多个基线方法进行了全面对比。
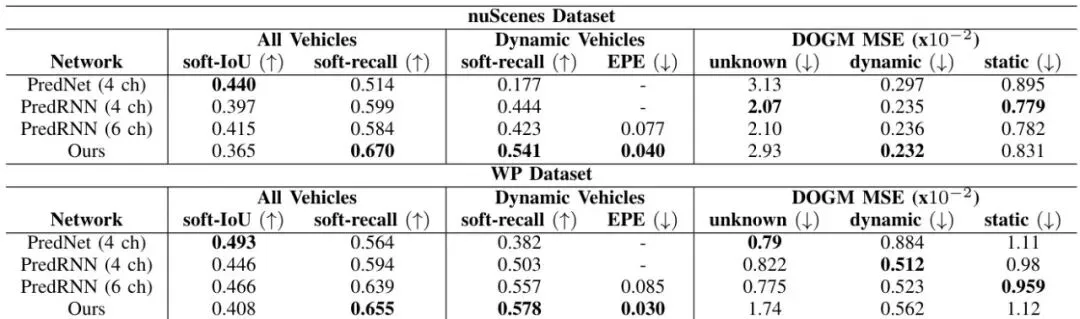
表1:在Nuscenes和Woven Planet数据集上,不同网络的性能对比。
上表评估的是动态车辆(即被明确识别和标注的车辆)的预测精度,使用了两种指标:MSDE(平均平方位移误差)和FDE(最终位移误差)。可以看到,本文提出的完整模型(最后一行)在两个数据集、多个预测时长上,都取得了最佳或接近最佳的表现。这证明了融合语义信息确实提升了专用车辆预测的准确性。
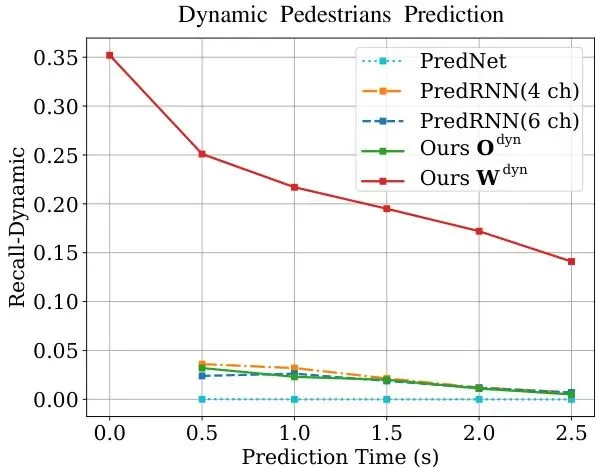
更有趣的是评估其通用预测能力,即预测那些未被识别为车辆的动态物体(主要是行人)。结果如图7所示:
图7:在nuScenes数据集上突出显示通用代理预测能力的行人动态召回率曲线。在DOGM动态通道和本方法的翘曲动态栅格上计算了不同预测网络的动态行人召回率。
图中的翘曲动态栅格 W_dyn,就是通过流“翘曲”出来的通用动态占据预测。可以看到,它的性能(蓝色实线)显著超越了其他只做DOGM预测的基线方法(橙色和绿色虚线)。这强有力地证明了:通过流引导将语义信息与占据预测耦合,能够大幅提升对非车辆动态物体的预测能力。
论文还进行了详细的消融实验,证明了每个组件(车辆语义输入、流引导损失等)都是有效的。
表3:在Nuscenes数据集上,对不同预测配置的消融研究。
优势与局限:方法带来了什么,又留下了什么?
总结一下,这篇论文提出的方法,其优势是清晰而突出的:1. 开创性的融合思路:真正在特征级、训练目标和输出层面将专用代理预测和通用占据预测统一到一个框架内,不是简单的后处理拼接。2. 巧妙的“流引导”设计:以场景流为核心监督信号,通过“翘曲”损失强制不同预测任务之间保持运动一致性,这是方法有效的关键。3. 全面提升的预测性能:实验证明,该方法既能提升对已知车辆的轨迹预测精度,又能显著增强对未知/未识别动态物体(如行人)的感知与预测能力,实现了“1+1 > 2”的效果。4. 模块化设计:骨干网络可替换,便于后续集成更强大的特征提取器。
当然,作为一项前沿研究,它也存在一些局限和值得思考的地方:
 1. 计算成本:“三头”解码和复杂的损失函数计算,无疑会增加模型的计算负担。对于需要实时运行的自动驾驶系统,这是一个需要权衡的实际问题。2. 语义类别有限:目前只融合了“车辆”这一种语义信息。虽然动态占据预测可以覆盖行人等,但若能进一步融入“行人”、“自行车”等更细粒度的语义,专用预测的能力会更强。3. 交互建模尚浅:方法主要关注单个物体的运动预测,对于车辆之间、车辆与行人之间复杂的交互行为(如博弈、礼让)的建模能力,可能不如一些基于图神经网络的社会交互模型。
1. 计算成本:“三头”解码和复杂的损失函数计算,无疑会增加模型的计算负担。对于需要实时运行的自动驾驶系统,这是一个需要权衡的实际问题。2. 语义类别有限:目前只融合了“车辆”这一种语义信息。虽然动态占据预测可以覆盖行人等,但若能进一步融入“行人”、“自行车”等更细粒度的语义,专用预测的能力会更强。3. 交互建模尚浅:方法主要关注单个物体的运动预测,对于车辆之间、车辆与行人之间复杂的交互行为(如博弈、礼让)的建模能力,可能不如一些基于图神经网络的社会交互模型。未来展望:更智能、更安全的运动预测之路
这篇论文为自动驾驶运动预测领域指明了一个非常有前景的方向。未来的工作可以沿着以下几个路径深化:轻量化与效率优化:设计更高效的网络结构和损失函数,在保持性能的同时降低计算开销,是走向产品落地的必经之路。多类别语义融合:将行人、交通锥、动物等多类别语义信息融入框架,使专用预测更加全面。深度交互理解:在现有密集预测的基础上,引入对场景中多个智能体之间深层交互关系的显式建模,预测结果将更加符合人类社会的交通规则。端到端学习:探索从原始传感器数据(激光雷达点云、相机图像)直接端到端学习预测的可能性,减少中间表示的误差累积。
归根结底,自动驾驶的安全冗余永远不嫌多。这种“专用+通用”的双轨预测思想,就像为系统装上了“火眼金睛”和“顺风耳”,既能看到明确的威胁,也能感知到模糊的风险,是朝着更高阶自动驾驶安全性迈出的扎实一步。
龙迷三问
DOGM是什么?和普通占据栅格有什么区别?DOGM是Dynamic Occupancy Grid Map(动态占据栅格地图)的缩写。普通占据栅格只表示“这里有没有东西”,而DOGM更进一步,每个栅格除了有“未知、空闲、静态占据、动态占据”四种状态的概率外,还估计了该位置的速度。它由激光雷达点云通过贝叶斯滤波器生成,能更好地表示环境中的运动信息。
场景流(Scene Flow)和光流(Optical Flow)是一回事吗?非常相关,但有区别。光流通常指在2D图像平面上,像素点从一个帧到下一个帧的移动。而场景流指的是3D空间中点的运动。在本文的鸟瞰图BEV表示下,我们可以近似认为每个栅格代表一小块地面上的垂直柱体,所以这里的场景流可以理解为这些“柱体”在2D地面上的运动矢量,它比纯图像光流多了物理世界的尺度信息。
为什么论文里用的是“向后流”而不是“向前流”?这是一个非常棒的问题!向后流指每个格子的运动矢量指向“它在上一帧的位置”。这样做有一个关键好处:它天然地处理了遮挡和物体出现/消失的问题。比如一个物体从遮挡后出现,在向前流中你很难为它凭空指定一个源头,但在向后流中,新出现的格子没有“来源”,这个信息本身就很有用。此外,向后流在视频插值等任务中也被证明更稳定。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
将专用与通用预测在训练目标层面深度耦合,并以场景流为核心设计一致性损失,思路新颖且系统,不是简单的模块堆叠。实验合理度:★★★★☆
在两个主流真实数据集上进行验证,对比了多种基线,并进行了详细的消融实验,结果可信。但对计算效率、实时性等工程指标的评估稍显不足。学术研究价值:★★★★★
为提升自动驾驶预测系统的鲁棒性提供了一个极具启发性的框架范式。“双轨预测”思想具有很高的研究价值,可衍生出大量改进工作。稳定性:★★★☆☆
方法原理上能提升对未知动态和遮挡的感知,增加了系统安全冗余。但多任务复杂模型的训练稳定性和在极端 corner case 下的表现仍需更多验证。适应性以及泛化能力:★★★★☆
核心框架不依赖高清地图,且通用占据预测部分使其对训练集外的物体类别有较好的泛化能力。但在不同国家/地区的交通行为差异上泛化性未知。硬件需求及成本:★★★☆☆
三头解码、多尺度特征融合和复杂损失计算,推断时计算负载较高。需进行工程优化才可能满足车规级芯片的实时性要求。复现难度:★★★☆☆
论文方法描述清晰,但需要自己实现DOGM生成、车辆语义BEV特征提取等预处理模块,且多任务损失的调参需要一定经验。产品化成熟度:★★☆☆☆
目前更偏向于一个研究原型。要产品化,必须在计算效率、模型轻量化、处理延迟、以及对各种恶劣天气和传感器故障的鲁棒性方面进行大量工程化改造和验证。可能的问题:损失函数中多个权重需要仔细调整,否则可能顾此失彼。对交互行为的建模较为隐式,在密集交互场景(如无保护左转)中可能不如显式交互模型。实时性是落地最大障碍。[1] R. Asghar, L. Rummelhard, W. Liu, A. Spalanzani, C. Laugier, “Integrating Specialized and Generic Agent Motion Prediction with Dynamic Occupancy Grid Maps”, arXiv preprint arXiv:2602.07938v1, 2026. (本论文)[3] C. Laugier et al., “Bayesian Occupancy Filtering for Dynamic Environments”, in Springer Tracts in Advanced Robotics, 2011. (DOGM基础框架)[27] A. Hu et al., “FIERY: Future Instance Prediction in Bird’s-Eye View from Surround Monocular Cameras”, ICCV, 2021. (条件变分预测的经典工作)[30] J. Ngiam et al., “Scene Flow Fields for Autonomous Driving”, CVPR, 2021. (场景流预测的先驱工作)*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

想让你的自动驾驶模型也拥有“双保险”视野吗?🚗👀 来和更多同行一起交流吧!欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+清华+龙哥),根据格式备注,可更快被通过且邀请进群。


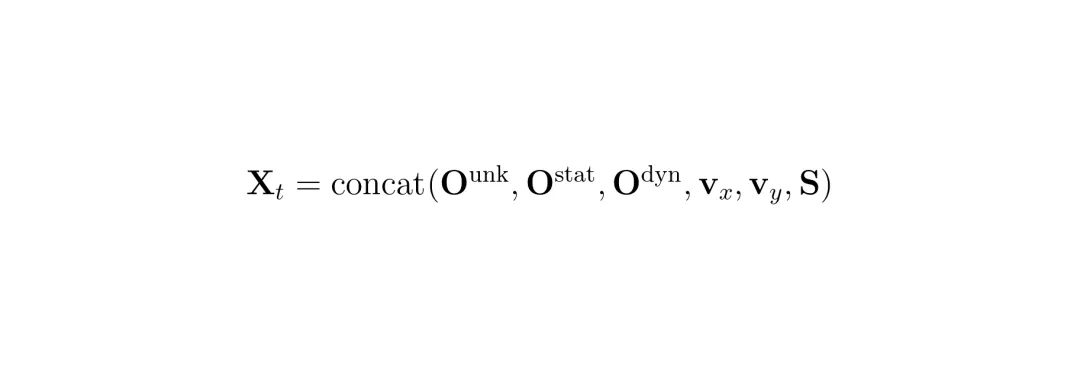
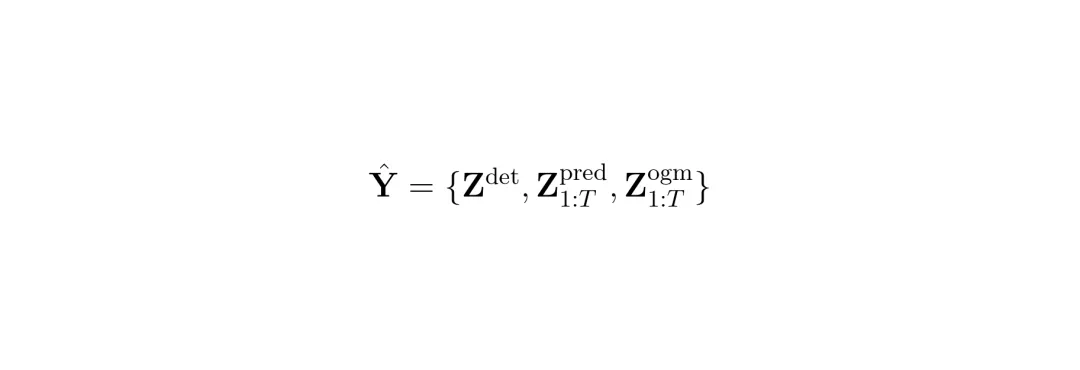
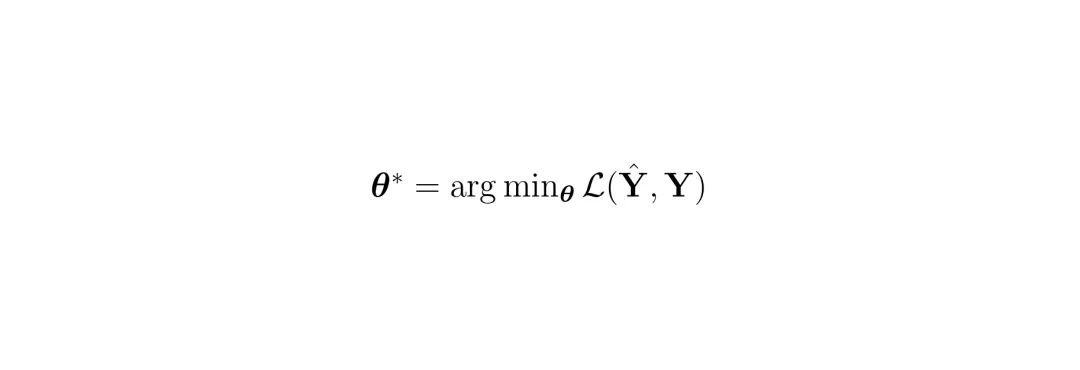




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
