解密自动驾驶的“语义鸿沟”与安全困局 | 视觉语言模型,能让自动驾驶更安全吗?
- 2026-02-19 05:29:04

当你的自动驾驶汽车在浓雾中行驶,前方突然出现一只横穿马路的鹿,它该如何“理解”这个从未见过的危险?传统方法可能束手无策,但一项新研究揭示:让AI学会用“人类的语言”思考,或许能成为安全驾驶的关键。
想象一下,你正坐在一辆自动驾驶汽车里。前方道路施工,一个临时路牌歪斜地立在路边。传统自动驾驶系统可能只把它识别为一个“物体”,但人类驾驶员会立刻理解:“这里有危险,需要减速并小心通过。” 这种对场景的语义理解,而非简单的物体识别,恰恰是当前自动驾驶系统最薄弱的环节。
99%的自动驾驶研究都聚焦于如何更精准地检测车辆、行人、交通标志。但当面对从未标注过的危险(如路面油渍、掉落货物、闯入的动物),或是需要解读人类意图和模糊上下文时(如“让那个行人先过”),系统往往表现不佳。这些“边缘案例”虽然罕见,却主导了真实世界中的安全事故。
今天,一项来自加州大学默塞德分校与圣地亚哥分校联合实验室的重磅研究,为我们打开了新思路。他们不是让AI“看”得更清楚,而是尝试让它“理解”得更像人类——通过视觉语言模型(VLM),将摄像头画面与“危险”、“施工”、“礼让”等自然语言概念对齐。
但研究结果却出人意料:简单粗暴地把VLM的“理解”塞给规划器,轨迹精度反而下降了。真正的安全增益,来自一个更精巧的设计……
读完本文,你将彻底搞懂:
1. 如何用一句“人话” Prompt ,实现零标注的开放世界危险检测? 2. 为什么给规划器“喂”更丰富的语义信息,反而会“帮倒忙”? 3. “乘客说句话”这种简单交互,如何能抑制致命的规划失败?
❓ 核心痛点:自动驾驶的“语义鸿沟”与安全困局
自动驾驶的安全挑战,早已不是“能不能看清”的问题。高精激光雷达和摄像头阵列,足以构建厘米级精度的三维世界。真正的瓶颈在于:系统能否像人类一样,理解眼前场景的“含义”与“风险”。
传统自动驾驶栈遵循“感知-预测-规划”的流水线:
• 感知层:像背单词一样,识别预定义的物体列表(车、人、标志)。 • 预测层:基于物理规律和轨迹历史,猜测这些物体会怎么动。 • 规划层:在规则和成本函数的约束下,计算出一条最优路径。
这套系统在高速巡航、跟车等结构化场景中表现出色。但它建立在两个脆弱的假设上:
1. 封闭世界假设:所有重要事物都已被预先定义和标注。 2. 几何优先假设:安全决策可以仅凭位置、速度、距离等几何信息做出。
现实世界却充满了开放性和语义模糊性:
• 一只鹿突然从树林窜出(未标注的“动物”类别)。 • 前方车辆双闪,但并未完全静止(是故障?还是临时停车?)。 • 乘客说:“就在那个穿红衣服的人旁边停一下。”(需要将语言指令与视觉实体关联并执行)。
在这些场景下,系统缺乏将视觉信号与高级语义概念(如“危险”、“意图”、“礼让”)连接起来的桥梁。它可能检测到了“物体”,却无法判断其风险等级;它可能规划了一条“最优”轨迹,却违背了人类的社会共识或乘客的明确意图。
这就是当前自动驾驶面临的“语义鸿沟”:机器看到了像素,却读不懂故事。而视觉语言模型,正是为弥合这道鸿沟而生。
但问题来了:把VLM这种强大的“语义理解器”接入自动驾驶系统,就像给汽车装上一个博学但话痨的副驾驶。它说的都对,但怎么确保它说的话,能真正、安全地指导车辆行动,而不是带来干扰甚至危险?
为了帮你快速把握全局脉络,我们先看这张核心架构思维导图——它清晰地展示了研究如何从三个不同层面(危险筛查、规划增强、指令约束)系统性探索VLM与自动驾驶的融合。
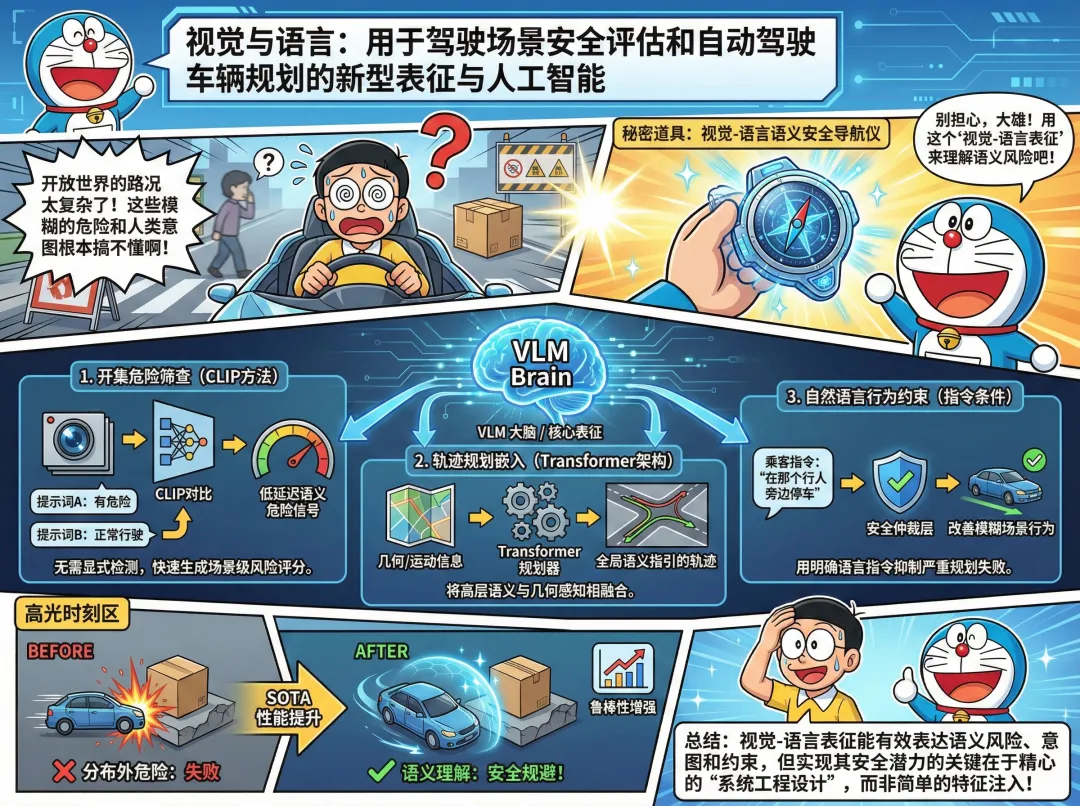
接下来,我们逐层拆解这张图中的每个关键模块,看看研究者们是如何“驯服”VLM,让它真正为安全驾驶服务的。
🚀 原理拆解:三大系统,三种融合哲学
💡 系统一:轻量级危险筛查——让VLM当“哨兵”
第一个思路最直接:既然VLM能理解图片和文字,那就让它直接看图说话,判断“有没有危险”。
研究者们采用了经典的CLIP模型。它的原理很简单:将图像和文本分别编码为向量,然后计算它们的相似度。相似度越高,说明图像内容越符合文本描述。
核心设计:
1. 定义“危险”与“安全”:研究者为7类常见危险(动物、行人、低能见度、施工等)分别设计了正负 Prompt 对。 • 正 Prompt : “前方道路施工”• 负 Prompt : “没有异常情况的道路”2. 计算危险置信度:对于每一帧图像,分别计算其与正、负 Prompt 的相似度得分,然后取差值。 • 差值 = 相似度( 图像,“危险描述”) - 相似度(图像,“安全描述”)• 这个差值就是危险置信度信号,值越大,当前帧越可能包含对应危险。 3. 阈值判断与融合:为每类危险设置一个阈值,超过即报警。如何综合多类报警?研究测试了三种策略: • 类别独立:任何一类报警就算危险。 • 类别+通用:增加一个通用的 “道路危险”Prompt ,任何类别或通用 Prompt 报警都算。• 双重验证:必须同时满足通用 “道路危险”报警且至少一个具体类别报警。这是为了降低误报。
这就好比,你在监控室看道路摄像头。以前需要训练一个专门的“鹿检测器”、“雾检测器”。现在,你只需要问CLIP:“这画面像不像‘有动物横穿马路’?”和“这画面像不像‘正常道路’?”它给出的信心分数差,就是你的风险指标。
💡 实战思考:这个方法最大的优势是“零标注”和“开集检测”。你不需要为“骆驼上高速”这种罕见情况收集数据,只需要用语言描述它。但它的精度足够担任安全“哨兵”吗?
💡 系统二:规划器增强——给大脑“喂补药”却中毒了?
第二个思路更深入:如果VLM能理解场景语义,那把它的理解(嵌入向量)直接作为额外信息输入给轨迹规划器,是不是能让规划更安全、更智能?
研究者基于Waymo数据集,在一个先进的视觉轨迹规划模型(MTR-VP)上做实验。他们在规划器的输入中,除了原有的图像、历史轨迹、驾驶意图外,额外拼接了从CLIP或DINOv2提取的全局场景嵌入向量。
理想很丰满:规划器获得了“这个场景很复杂”、“这里可能有行人”等高层次语义信息,应该能做出更周全的决策。
但结果却令人大跌眼镜!
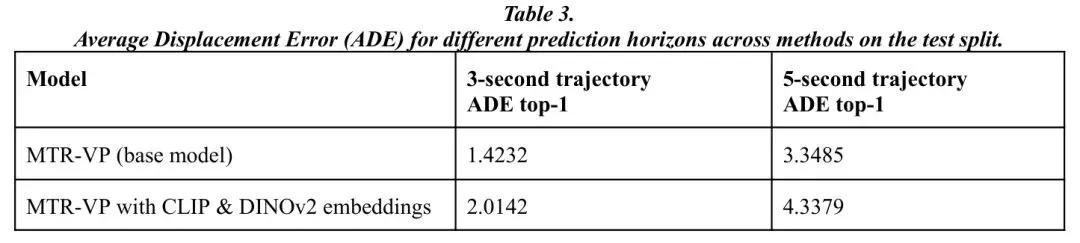
如表所示,加入VLM嵌入的模型,其3秒和5秒轨迹预测误差(ADE)均高于 Baseline 。这意味着,额外的语义信息非但没有帮助,反而干扰了规划器的决策。
为什么?论文给出了关键洞见:表征-任务错配。轨迹规划是一个对空间几何关系极度敏感的任务。它需要知道“车在哪里”、“人距离多远”、“哪条车道可用”。而CLIP产生的全局语义嵌入,虽然包含了“施工”、“拥堵”等概念,却丢失了精确的空间结构和位置信息。
这就像你问路时,路人告诉你:“那个地方很热闹,有很多好吃的。”(全局语义),但你真正需要的是:“向前走200米,第二个路口右转。”(几何指令)。前者信息虽对,但无法直接用于导航。
这个反直觉的发现至关重要:不是信息越多越好,而是信息必须与任务对齐。 简单粗暴的特征拼接,在安全关键系统中可能适得其反。
💡 系统三:指令约束——让乘客成为“安全副驾”
前两个系统是从机器视角出发,试图让AI自主理解。第三个系统则换了个思路:让人用最自然的方式(语言)来提供关键约束,让AI去执行。
研究者利用doScenes数据集,其中包含了事后标注的、乘客可能发出的自然语言指令(如:“在公交车站后面停车”)。他们将指令作为条件,注入到一个开源的规划框架(OpenEMMA)中。
运作模式:
1. 系统收到指令:“在人行横道前,停在道路右侧的路缘处。” 2. 规划器同时处理视觉场景和这条指令。 3. 指令作为一个软约束,影响规划器的成本函数或决策过程,使其生成的轨迹倾向于满足指令要求。
效果如何?

研究发现,语言指令的加入,最显著的效果是抑制了那些罕见但严重的规划失败。在某些场景下,仅依赖视觉的 Baseline 会产生穿越人行道、驶入不可行驶区域等灾难性轨迹,导致误差(ADE)极大。而一句明确的乘客指令,像是一个“安全护栏”,及时纠正了这些行为。
关键在于,语言在这里不是提供全局语义,而是提供明确的、与视觉元素绑定的行为约束。 它回答了“在哪里”、“对什么”、“做什么”的问题,这与规划任务所需的几何和动作信息是直接对齐的。
🤔 你在实际项目中,是否也曾遇到过“模型学到了错误关联”或“特征干扰”的情况?欢迎在评论区分享你的经历和解决方案!
📊 实验验证:数据说话,细节定成败
🏆 危险筛查: Prompt 就是生产力
在危险筛查任务中,研究者们在COOOL数据集上进行了详尽的评估。结果清晰地展示了** Prompt 工程**的极端重要性。
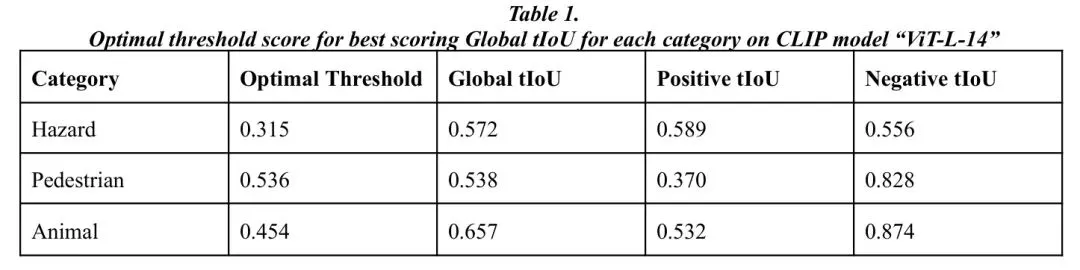
核心发现:
1. 性能差异巨大:“低能见度”类别表现最佳(全局时间IoU 0.765),而“道路杂物”和“紧急场景”表现较差(0.451和0.318)。这是因为CLIP在训练时见过大量雾、雪等天气图片,但对“小物体”和“动态闪烁”理解不足。 2. 融合策略是关键:采用“双重验证”策略(需通用危险+具体危险同时报警)后,系统在非危险视频片段中的误报率大幅降低,从其他策略的约66%降至30%,可靠性显著提升。 3. ** Prompt 措辞是玄学**:对于“施工区域”,使用“前方道路施工”与“没有异常情况的道路”作为 Prompt 对,性能(0.564)远超使用“施工区域”与“没有危险的畅通车道”(0.305)。一词之差,性能暴跌45.7%。
结论:VLM筛查是一个有效的第一道防线,尤其适合检测引起全局场景变化的危险(如大雾)。但它无法替代精细的物体检测器,且其性能高度依赖于精心设计的 Prompt 。
🔬 规划增强:负面结果的正面价值
系统二的实验数据几乎全是“负面”的,但其价值毫不逊色。
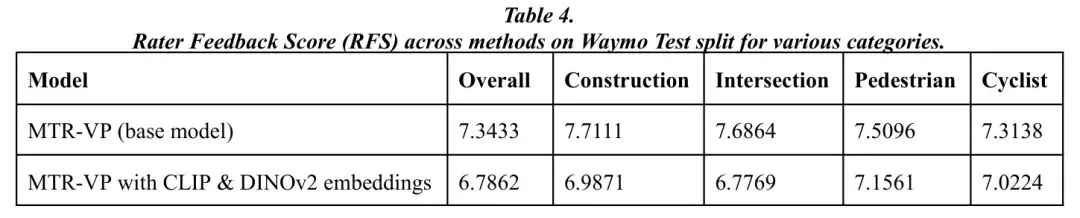

除了轨迹误差(ADE)增加,在“施工区域”、“行人交互”等关键安全场景中,人类专家对VLM增强模型生成的轨迹评分也更低。这双重证据表明,全局的、非空间锚定的语义信息,会损害规划器生成符合人类驾驶习惯的、安全轨迹的能力。
这个“失败”的实验为整个领域敲响了警钟:通往更智能的规划,不是简单地堆叠更强大的感知模型特征。
🔬 指令约束:抑制灾难,而非提升平均
系统三的结果最有启发性。如果只看整体平均误差,指令带来的提升似乎有限。但拆解数据后,故事完全不同。
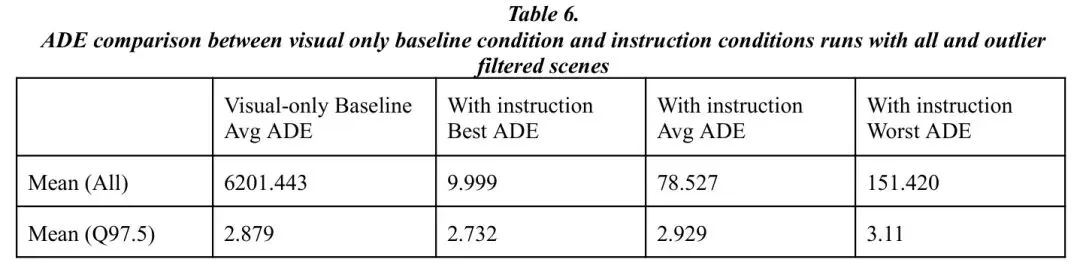
1. 整体平均误差(All)大幅下降:这主要是由于指令抑制了那些导致巨大误差的灾难性规划失败。几个极端错误场景被纠正,直接拉低了整体均值。 2. 过滤异常值后(Q97.5)仍有稳定提升:在排除极端值后,表现最佳的指令仍能带来5.1% 的误差降低。这说明指令在“正常”场景下也能微调行为,使其更符合预期。 3. 指令质量至关重要:研究进一步发现,中等长度(9-12词)、提及具体动态物体(如“移动的车辆”)的指令效果最好。模糊的指令(如“在这儿停”)则收效甚微。
结论:自然语言作为行为约束,其核心价值在于提高系统的鲁棒性下限,防止最坏情况发生。这对于安全而言,可能比平均性能的微小提升意义更大。
⚖️ 客观评价:潜力与挑战并存
这项研究为我们勾勒了一幅清晰的图景:VLM在自动驾驶安全中大有可为,但必须用对地方、用对方法。
✅ 显著优势:
• 开集风险感知:为零样本、长尾危险检测提供了全新范式。 • 人机自然交互:使乘客能用最直观的方式影响车辆短期行为。 • 语义推理能力:为理解复杂场景上下文奠定了基础。
⚠️ 核心局限与挑战:
1. 时空感知缺失:现有VLM(如CLIP)是静态的,无法理解“闪烁”、“横穿”等动态时间概念,也难以精确定位小物体。 2. 表征-任务鸿沟:如何将高级语义结构化、空间化地传递给规划器,仍是未解难题。直接注入嵌入向量是条死胡同。 3. 指令的模糊与对抗:现实中的语言充满歧义,甚至可能存在恶意指令。系统需要强大的意图理解、冲突仲裁和安全边界机制。 4. 计算与延迟:大型VLM的推理速度可能无法满足实时规划的高频要求,需要异步架构等工程优化。
未来的方向不是放弃VLM,而是进行更精细的系统工程:例如,开发具有时空感知的驾驶专用VLM;设计中间层,将语义转化为规划器可理解的空间-动作约束;建立完善的语言指令安全验证与接管流程。
🌟 价值升华 + 行动号召
这项研究给我们上了深刻的一课:
1. 安全是系统工程,不是模型堆砌:把最强的感知模型输出直接丢给规划器,可能比不用更危险。模块间的接口设计与信息对齐,与模块自身性能同等重要。 2. 语言是强大的约束工具,而非决策主体:让语言描述“做什么”、“在哪做”,比让它回答“为什么”并生成轨迹更可靠、更安全。人机协同中,应明确各自的优势边界。 3. 评估指标需洞察本质:平均性能的提升固然好,但对极端失败案例的抑制能力,往往是安全系统更重要的价值体现。
这项研究像一位冷静的工程师,它没有鼓吹VLM的万能,而是通过扎实的实验告诉我们:这条路能走通,但必须带着镣铐跳舞——在严格的系统设计、任务对齐和安全边界的约束下,视觉语言模型才能真正成为自动驾驶安全的“守护神”,而非“干扰源”。
🤔 深度思考:你认为“乘客语音指令约束”这项技术,最可能率先在哪个场景落地?是RoboTaxi,私人乘用车,还是封闭园区的物流车?欢迎在评论区留下你的观点!
💝 支持原创:如果这篇近5000字的硬核解读帮你理清了思路,点赞+在看就是最好的支持!分享给你的技术伙伴,一起探讨AI安全的未来!
🔔 关注提醒:设为星标,第一时间获取深度技术解读!
#AI技术 #自动驾驶 #视觉语言模型 #VLM #AI安全 #论文解读
参考
VISION AND LANGUAGE: NOVEL REPRESENTATIONS AND ARTIFICIAL INTELLIGENCE FOR DRIVING SCENE SAFETY ASSESSMENT AND AUTONOMOUS VEHICLE PLANNING
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 哈弗初恋俄罗斯销量大爆发,国产SUV真牛
- 合资燃油SUV还能打?全新RAV4、2026款缤智、改款狮铂拓界,这3款刚更新的车给答案
- 双周$327开走, 中高配大七座SUV, 全景天窗+360环影+哈曼卡顿全拉满!Taos还返场?太狠了!
- 12万预算想要大沙发SUV?长安吉利零跑一起挑
- 过年了,最安全的豪华轿车,15.99万起?
- 买车不修车比啥都强!这5台SUV闭眼入,五年后你会回来感谢我
- 2026年3月,要上市的四款SUV!都是爆款!
- 彻底崩了!1月SUV销量洗牌:合资全军覆没,无缘前四!
- 1400匹插混SUV极氪8X申报曝光家用性能双兼顾?
- 3.2026必看SUV!10台新车全梳理,50岁大叔一台比一台香
