如何重塑自动驾驶3D感知?骁龙提出MambaFusion解决方案,90%计算量砍掉,精度反升4.4%!
- 2026-02-20 21:11:38

你是否曾为多传感器融合的“算力黑洞”而头疼?相机与激光雷达的数据,一个语义丰富但深度模糊,一个几何精确但稀疏昂贵。强行融合,模型复杂度呈二次方爆炸;简单加权,又无法应对现实世界的校准漂移和遮挡。为什么99%的融合方案都在这对矛盾中挣扎?
今天,我们将深入解读一篇开创性工作。它通过引入线性复杂度的状态空间模型、可靠性感知的动态融合门以及基于物理的扩散推理,不仅将计算量从二次方降至线性,更在权威基准上刷新了SOTA。读完本文,你将彻底掌握这套高效、自适应且稳健的3D感知新范式。
❓ 核心痛点:传统BEV融合的四大“死穴”
在自动驾驶的感知世界里,鸟瞰图(BEV)融合框架已成为主流。它将不同传感器的特征投影到统一的几何平面上,看似解决了“对齐”问题。然而,深入其里,四个长期存在的顽疾严重制约了其性能与落地:
1. 低效的上下文建模:基于Transformer的编码器虽然能捕捉全局依赖,但其注意力机制的计算复杂度与序列长度呈二次方关系。对于需要处理长距离、多帧时间信息的3D场景,这无异于算力“无底洞”。 2. 空间不变的“盲”融合:大多数系统采用固定或全局共享的权重来融合相机和激光雷达特征。这完全忽略了传感器的可靠性是随空间位置动态变化的——近处的激光雷达点密集可靠,远处的则稀疏;相机在纹理丰富区域置信度高,在遮挡或弱纹理区域则不确定性激增。 3. 缺乏物理推理的“幻觉”检测:现有检测器往往只根据特征激活的强度来预测目标框和置信度,缺乏对几何合理性的考量。这可能导致物体重叠、悬浮在空中等违反物理规律的“幻觉”检测。 4. 时间上的“闪烁”:由于缺乏跨帧的特征约束,检测结果在不同帧之间容易出现波动和不一致,即“闪烁”现象,给下游的预测和规划模块带来极大困扰。
面对这些痛点,一个理想的解决方案必须同时做到:高效、自适应、符合物理、时间稳定。这听起来像是一个“不可能三角”,但MambaFusion通过一套精巧的架构设计,给出了令人惊艳的答卷。
该方法通过线性复杂度的状态空间模型(SSM)替代二次方注意力的核心思想,结合可靠性感知的动态融合门与结构条件扩散推理,构建了一个从特征编码、融合到结果优化的完整高效感知闭环。为了帮你快速把握全局脉络,我们先看这张核心架构思维导图——
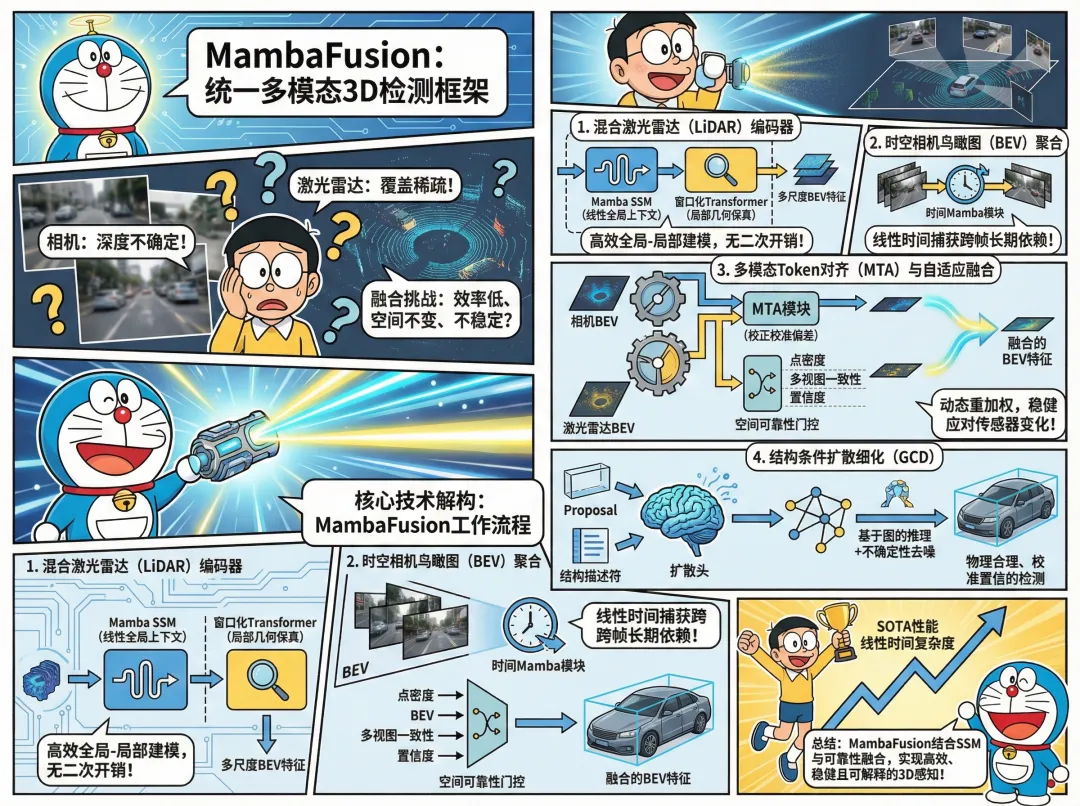
接下来,我们逐层拆解这张图中的每个关键模块,看看它是如何精准命中上述四大痛点的。
🚀 原理拆解:硬核但易懂的架构革新
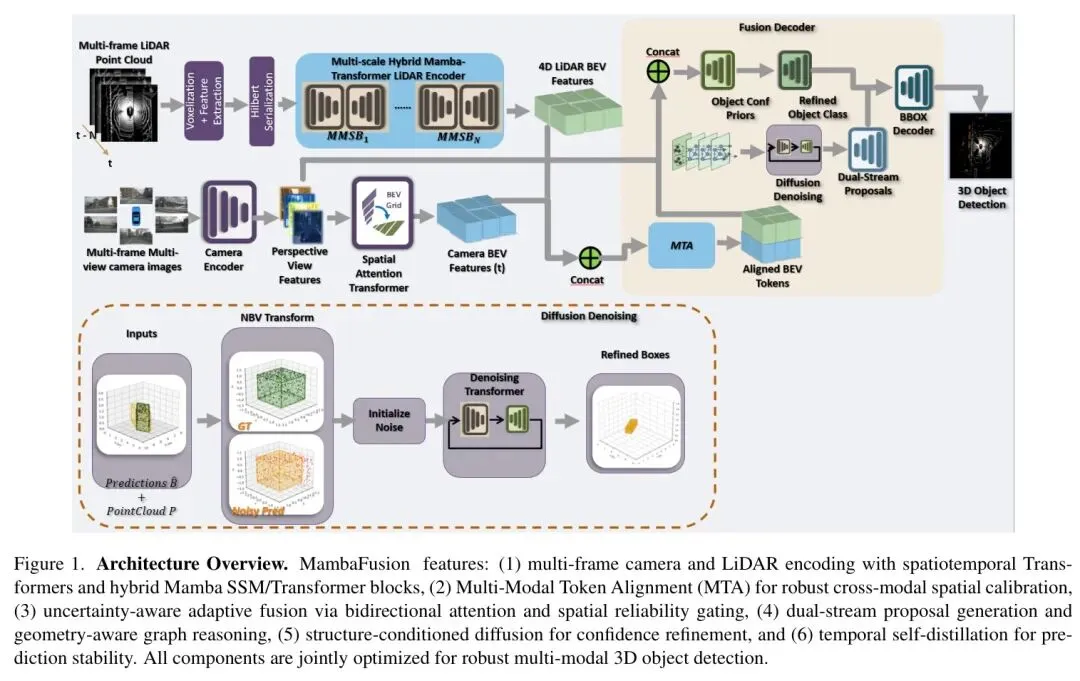
MambaFusion是一个端到端的统一框架,其核心创新可归结为三大支柱:混合线性编码器、自适应可靠性融合与结构条件扩散细化。我们逐一深入。
💡 混合线性时间编码器
传统方法在Sparse卷积(效率高但感受野有限)和全局注意力(效果好但计算爆炸)之间艰难取舍。MambaFusion的编码器设计堪称“鱼与熊掌兼得”的典范。
激光雷达流:原始点云被体素化后,沿着希尔伯特空间填充曲线序列化,以最大程度保持空间邻接性。随后,序列进入一个交替堆叠的模块:
• Mamba状态空间模型(SSM)块:负责全局上下文传播。其核心优势在于,对于长度为 的序列,SSM能以 的线性复杂度建模长距离依赖,彻底摆脱了Transformer 的算力枷锁。 • 窗口化Transformer块:负责局部空间推理。在划分的局部窗口内进行自注意力,以 的成本( 为窗口大小)捕捉精细的几何结构细节。
这种“SSM抓全局,窗口注意力抠细节”的交替设计,在多个空间尺度上进行,最终生成多尺度BEV特征 ,完美平衡了效率与精度。
相机流:多视图图像通过共享主干网络(如Swin-T)和特征金字塔网络(FPN)提取特征。借鉴BEVFormer,可学习的BEV查询通过可变形交叉注意力聚合多尺度图像特征,生成相机BEV特征 。
时间建模:对于多帧序列 ,作者同样摒弃了二次复杂度的时序注意力,而是再次应用Mamba模块进行线性时间聚合,高效地捕捉运动与场景连续性。
💡 实战思考:用线性复杂度的SSM替代注意力进行全局和时序建模,是本次效率提升的基石。这启示我们,在处理长序列的视觉任务中,SSM可能是一个比Transformer更具潜力的基础模型。
💡 多模态Token对齐(MTA)
现实很骨感:车辆行驶中的振动、热膨胀会导致相机和激光雷达的外参校准发生漂移(研究表明可达 )。直接融合未对齐的特征,效果必然大打折扣。
为此,作者设计了一个轻量级的MTA模块。它学习相机和激光雷达BEV Token之间的位置偏移,动态地对它们进行空间对齐:
其中 是一个轻量的交叉注意力网络。这个设计让模型对实际部署中不可避免的校准误差具备了内在的鲁棒性。
💡 可靠性感知的动态融合
对齐后的特征 和 通过双向多头注意力进行信息交互,得到 和 。真正的精华在于接下来的空间可靠性门控。
对于BEV空间中的每个单元格 ,模型会计算一个可靠性描述符 ,它综合了:
• 激光雷达点密度 • 相机深度方差 • 遮挡分数 • 多视图一致性 • 自车距离
一个小型MLP根据这些信号以及当前的特征,预测一个动态的融合权重门控 。
但这还不够“聪明”。模型还会让每种模态预测一个不确定性(方差)图。最终,采用经典的逆方差融合策略进行加权:
高不确定性区域的贡献会自动降低。此外,训练中还会随机丢弃某一模态的数据,迫使模型在部分传感器失效时也能保持鲁棒。
你在实际项目中,是如何处理传感器不确定性或失效情况的?欢迎在评论区分享你的经验!
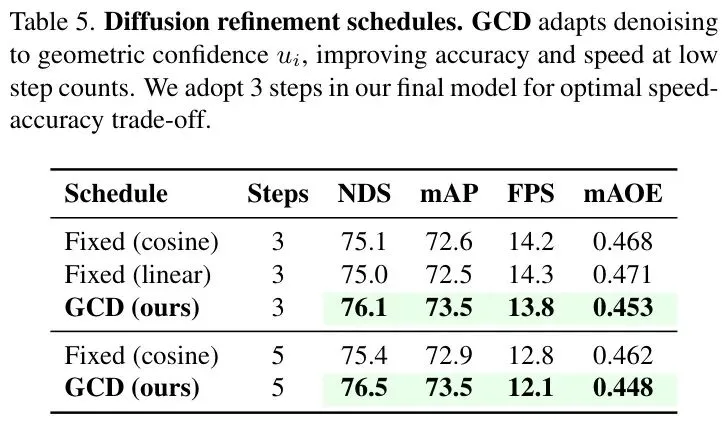
💡 结构条件扩散细化(GCD)
从融合特征中生成初始检测提案后,MambaFusion并未止步。它引入了一个基于扩散模型的细化头,专门优化提案的置信度,并确保其符合物理规律。
空间图推理:首先,在提案之间构建一个空间图,连接一定距离内的邻近目标。每个节点用结构描述符(如类别-尺寸一致性、离地高度、激光雷达点支持数等)增强。通过图神经网络的消息传递,模型能感知物体间的空间关系,抑制“物体重叠”、“悬浮”等不合理配置。
不确定性引导的扩散:扩散过程的核心创新在于,噪声的添加强度与提案的初始不确定性相关。置信度低的提案(例如,激光雷达点少、离地高度异常、局部相机特征模糊)会被添加更多噪声,在去噪过程中需要更多的“修正”:
这里 是估计的置信度, 是与置信度负相关的噪声水平。去噪网络 在训练时学习从噪声数据中恢复干净提案,同时以结构描述符和局部特征为条件。
在推理时,仅需3步去噪迭代,就能获得物理合理、置信度校准的最终检测结果,在精度和速度间取得完美平衡。
💡 时间自蒸馏(TSD)
为了进一步稳定跨帧预测,作者引入了时间自蒸馏。模型利用当前帧的BEV嵌入和Mamba状态,预测下一帧的嵌入,并与下一帧的真实嵌入(梯度截断)计算一致性损失 。这使特征能够平滑地随时间演化,有效减少了检测结果的“闪烁”。
📊 实验验证:数据说话,全面领先
理论再优美,也需要实验的铁证。MambaFusion在nuScenes和Argoverse2两大权威自动驾驶数据集上进行了全面验证。
🏆 SOTA性能对比
在nuScenes 验证集上,MambaFusion取得了NDS: 77.9 和 mAP: 74.9 的惊人成绩,在使用Swin-T主干网络的方法中树立了新的标杆。
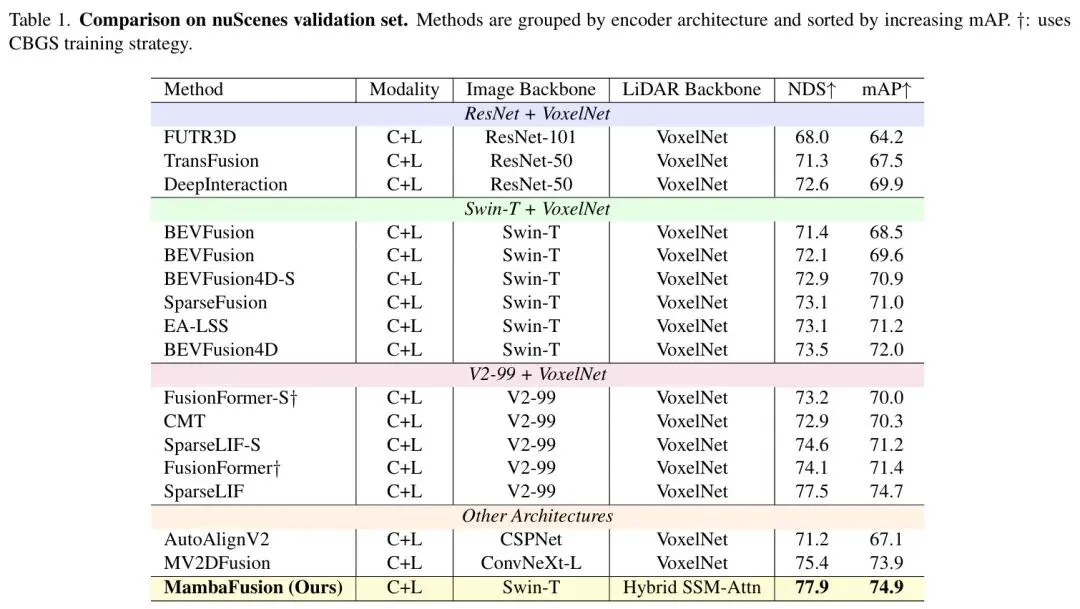
与强大的基线BEVFusion4D(NDS: 73.5, mAP: 72.0)相比,MambaFusion在NDS上提升了**+4.4**,在mAP上提升了**+2.9**,优势非常显著。
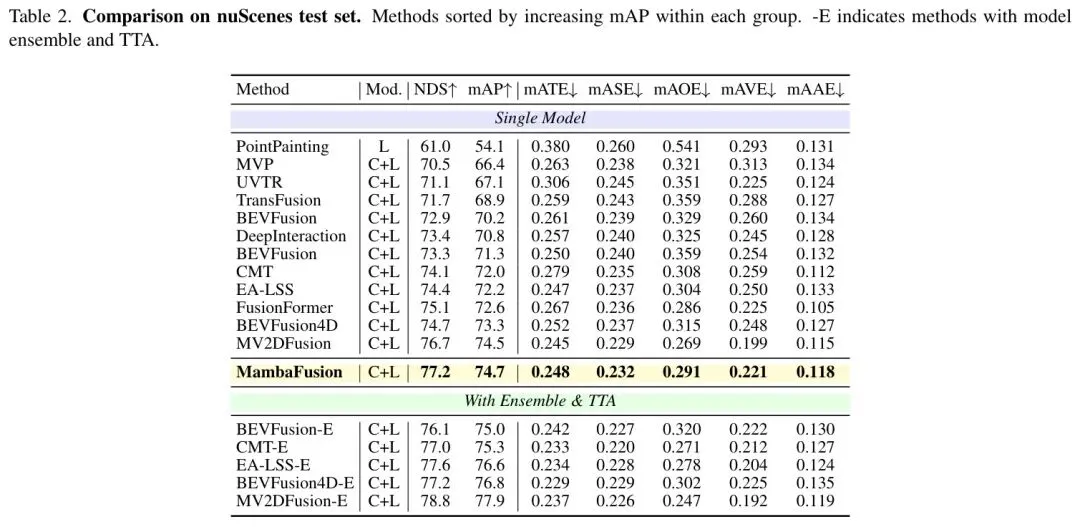
在nuScenes 测试集上,MambaFusion继续发力,取得了NDS: 77.2和mAP: 74.7,甚至超过了使用更大主干网络(ConvNeXt-L)的MV2DFusion,证明了其卓越的泛化能力。
🔬 深度消融实验
作者进行了详尽的消融研究,揭示了每个组件的价值。
编码器选择:如表4所示,作者提出的“Mamba + 窗口注意力”混合设计,在精度(NDS: 73.2)和效率(推理时间69ms)上取得了最佳权衡,显著优于纯Mamba或纯Transformer。
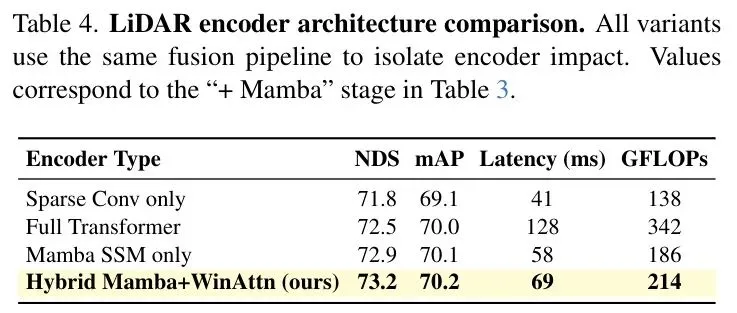
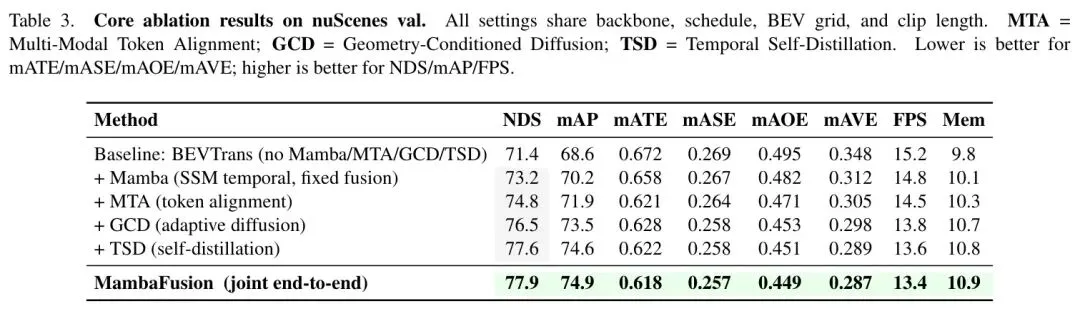
组件级贡献:如表3所示,逐步添加Mamba时间编码器、MTA对齐模块、GCD扩散细化和TSD时间蒸馏,均带来了持续的、显著的性能提升(NDS累计提升超过5分),最终汇聚成完整模型的强大性能。
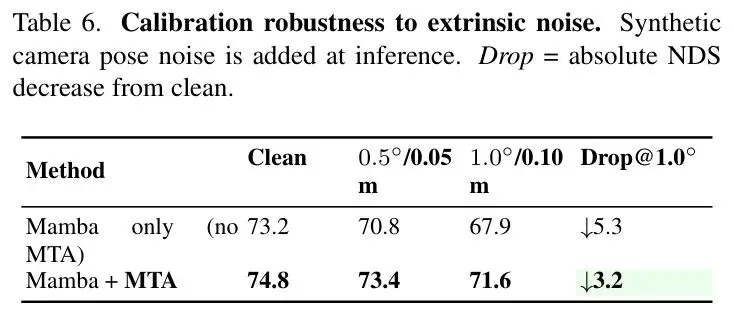
校准鲁棒性:这是MambaFusion的一大亮点。如表6所示,当人为添加相机外参扰动(模拟真实校准漂移)时,带有MTA模块的模型性能下降幅度远小于不带MTA的版本。在 的扰动下,NDS下降减少了40%,这在实际部署中价值巨大。
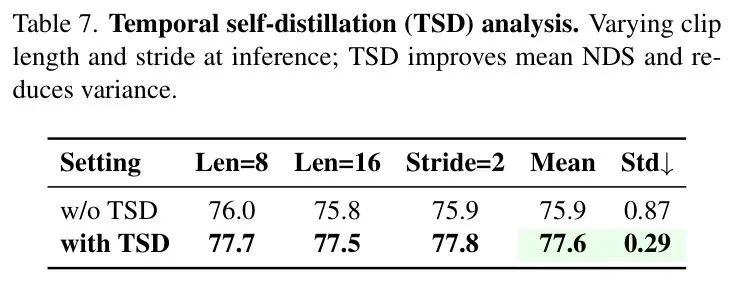
时间稳定性:如表7所示,引入时间自蒸馏(TSD)后,模型在不同剪辑长度和步长下的性能方差降低了67%,平均NDS提升了+1.8,证明了其有效促进时间一致性的能力。
扩散效率:如表5所示,基于几何条件(GCD)的自适应扩散调度,仅用3步就达到了比固定5步调度更高的精度和更快的速度(FPS提升7.8%),体现了其高效性。
看到这些硬核的数据对比,你是否对Mamba在视觉任务中的潜力有了新的认识?点赞支持,我们继续深挖!
⚖️ 客观评价与未来展望
MambaFusion无疑是一篇里程碑式的工作,它系统性地解决了多模态BEV融合中的效率、自适应、物理合理性和时间稳定性难题,并在权威基准上实现了显著领先。
核心优势:
1. 效率革命:线性复杂度的SSM backbone,为处理长序列、多帧的3D感知任务打开了新的大门,让实时高性能融合成为可能。 2. 智能融合:从“盲”融合到“可靠性感知”的动态加权,让模型能像人类一样,在不同场景下信任不同的传感器。 3. 物理合理:引入图推理和条件扩散,将物理先验和不确定性感知深度融入检测流程,大幅减少“幻觉”检测。 4. 稳健可靠:MTA对齐和TSD蒸馏,让模型对校准误差和时间波动具备了强大的鲁棒性,更贴近实际部署需求。
潜在局限与展望:
• SSM的潜力挖掘:本文主要用SSM替代了时序和全局上下文建模中的注意力。未来,SSM能否更深度地融入特征提取、交互等各个环节,值得探索。 • 更极致的效率:尽管已是线性复杂度,但在边缘设备上部署时,模型整体的参数量和计算量仍有优化空间。 • 泛化到更多模态:当前框架针对相机和激光雷达设计。其“可靠性感知融合”的思想,可以很自然地扩展到毫米波雷达、超声波传感器等多模态融合中。 • 端到端自动驾驶:如此强大的感知模块,如何与预测、规划模块更紧密地耦合,构建真正端到端的自动驾驶系统,是下一个前沿。
🌟 价值升华与行动号召
总结来说,MambaFusion为我们提供了三个关键启示:
• 效率新范式:在处理视觉长序列任务时,状态空间模型(SSM)是比Transformer更高效的潜在基础模型。 • 融合新哲学:多传感器融合不应是简单的特征拼接或固定加权,而应是基于不确定性和空间可靠性的动态、自适应过程。 • 感知新高度:3D感知不仅要“看得准”,还要“看得稳”、“看得合理”,将物理规律和时空一致性作为模型的深层约束是通往更高阶智能的必经之路。
🤔 深度思考:你认为MambaFusion这套“高效SSM + 动态融合 + 物理推理”的技术范式,最可能率先在哪个具体的AI应用场景(如机器人、AR/VR、工业检测)中落地并产生颠覆性影响?欢迎在评论区留下你的观点!
💝 支持原创:如果这篇近5000字的深度技术解读让你有所收获,点赞+在看就是对我最大的支持!也欢迎分享给你身边正在钻研AI技术的伙伴!
🔔 关注提醒:关注并设为星标,第一时间获取更多融合前沿模型架构、优化技巧的深度解读!
#AI技术 #深度学习 #自动驾驶 #3D感知 #多模态融合 #Mamba #论文解读 #技术干货
参考
MambaFusion: Adaptive State-Space Fusion for Multimodal 3D Object Detection
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 想买15万操控性好的SUV,看看这两款,空间舒适、耐用动力强
- 奔驰这次真急了,最便宜SUV直接上800V+600km续航,工薪层可以等等了
- 小米SUV谍照曝光!对开门设计直接对标法拉利,雷军这波要给友商上课了
- 哈弗猛龙PLUS:一台能坐7个人的SUV,重新定义新派硬核家庭,还省油
- 15万级家用SUV怎么选?哈弗大狗吉利新SUV丰田小号RAV4,谁才是真香定律
- 日产全新轿车来袭,13.99万起,与华为合作,车长4.9米,油耗6.4L
- 40万级家用SUV就看它,车长超5.1米,续航超1400km,乘坐也很舒适
- 1月中型SUV榜单出炉:途观L拿下第一,Model Y退居第二,仅6款破万你看意外吗?
- 爱在路上823——成功救援一辆亏电的轿车!沂蒙救援临港大队!
- 20万预算,选个纯电或混动SUV,怎么选?
