最近和业内朋友聊自动驾驶,大家的话题三句离不开“端到端”、大模型或者特斯拉的FSD入华。在中国的语境下,自动驾驶似乎已经变成了一场关于算力、数据量和落地速度的纯粹互联网战役。
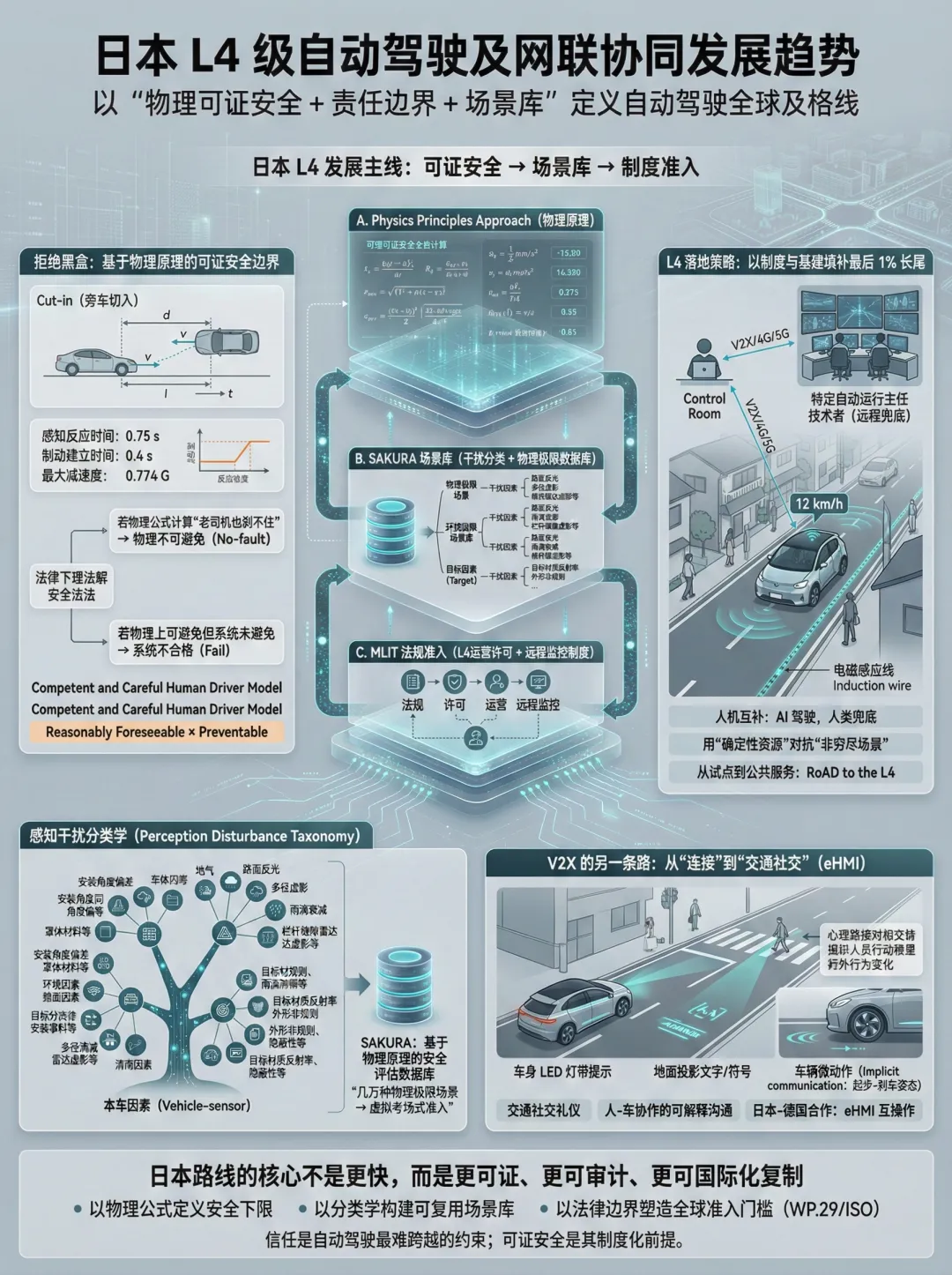
但在我们忙着“卷”开城数量、卷谁的算法更拟人的时候,我了解到了一些日本对自动驾驶发展方面的技术和政策资料,从这些文件,在我看来,日本正在做一件看起来很慢,但实际上极具杀伤力的事情:他们在试图用物理公式和法律边界,定义全球自动驾驶的“及格线”。
后面,我仔细翻阅了日本国土交通省(MLIT)和日本汽车工业协会(JAMA)一些自动驾驶方面的报道或者相关报告。日本的技术路线跟我们还是有一定却别的。如果说中国是“基建狂魔”式的技术扎堆迭代,日本则更像是一个有着严重强迫症的“逻辑构建者”。
一、 拒绝“黑盒”:用物理公式算出的安全边界
现在国内主流的自动驾驶开发逻辑是“数据驱动”——跑几千万公里,通过Corner Case(长尾场景)来训练模型。但在JAMA的工程师看来,这种逻辑有一个致命的逻辑漏洞:现实世界的场景是无限的,靠跑里程永远无法穷尽。
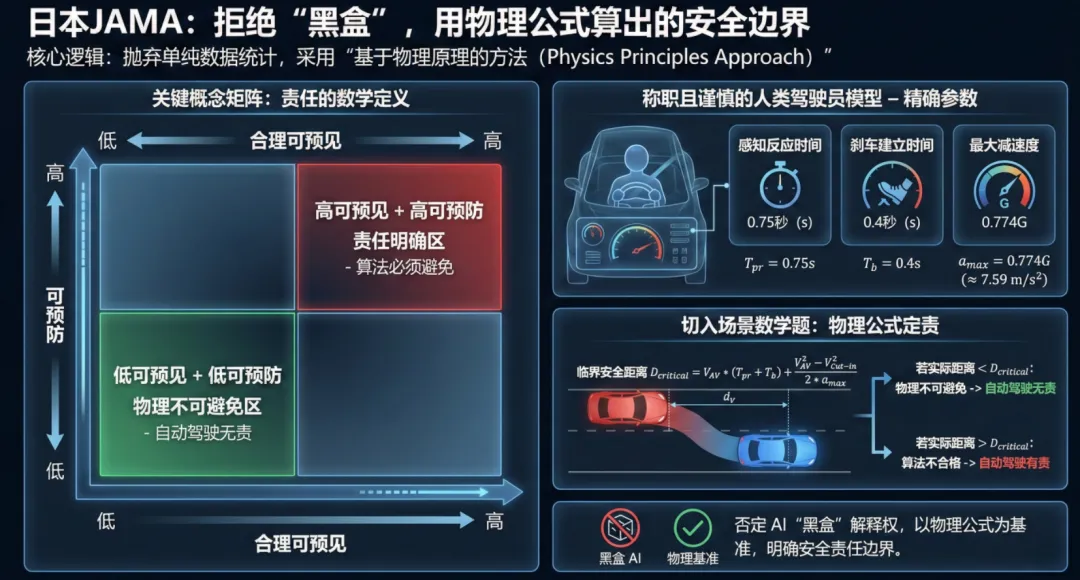
所以,在日本的《自动驾驶安全评估框架 2.0》中,日本抛弃了单纯的数据统计,提出了一种“基于物理原理的方法(Physics Principles Approach)”。
这套方法的核心逻辑极其硬核:把自动驾驶的“责任”用数学公式算出来。 他们引入了一个关键的概念矩阵:“合理可预见(Reasonably Foreseeable)”与“可预防(Preventable)”。
为了定义什么叫“可预防”,JAMA没有用模糊的AI判断,而是直接建立了一个“称职且谨慎的人类驾驶员模型”(Competent and Careful Human Driver Model)。
这里我们要注意,这不仅仅是一个概念,他们给出了精确的参数:
为什么要定这些数?日本人把切入(Cut-in)场景做成了数学题:如果旁车切入时,留给后车的距离和时间,让一个反应时间0.75秒、能踩出0.774G刹车的人类老司机都撞了,那就是“物理上不可避免”,自动驾驶撞了也无责。反之,如果物理公式算出能刹住,而你的系统没刹住,那就是算法不合格。
这种“死磕”参数的做法,直接否定了AI的“黑盒”解释权。它告诉所有厂商:别跟我吹你的算法有多智能,先过一遍物理公式。
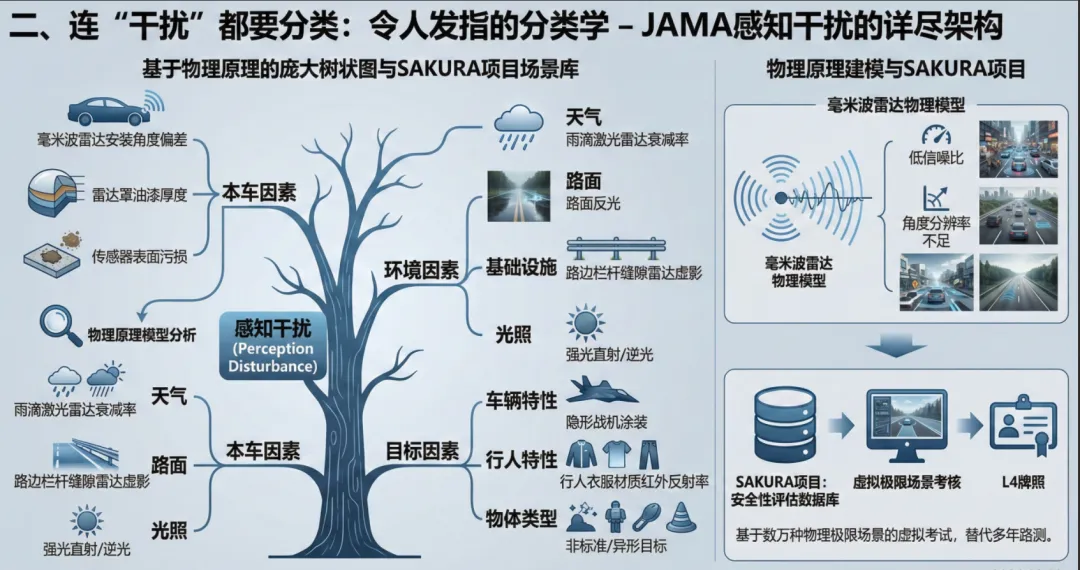
二、 连“干扰”都要分类:令人发指的分类学
JAMA文件的另一个震撼之处,在于他们对“感知干扰”的分类(Perception Disturbance)。
在国内,我们通常笼统地说“传感器受天气影响”。但在日本的架构里,这被拆解成了一个庞大的树状图(参考JAMA框架文件第34-45页)。他们把干扰源分为了三大类:
- 本车因素(Vehicle-sensor): 比如毫米波雷达的安装角度偏差、罩子的油漆厚度。
- 环境因素(Environment): 不仅仅是下雨,他们细化到了路面反光(Ghost objects from multipath reflection)、雨滴对激光雷达光束的衰减率、甚至是路边栏杆缝隙产生的雷达虚影。
- 目标因素(Target): 前车是不是隐形战机涂装?行人的衣服材质对红外线的反射率是多少?
他们甚至为每一种干扰都建立了物理原理模型。比如针对毫米波雷达,他们分析了“低信噪比(Low S/N)”和“角度分辨率不足”在不同路况下的具体表现。
这种做法看似笨重,但它构建了一个极其严密的“场景库”。这也就是日本大力推行的SAKURA项目——一个基于物理原理和干扰分类的自动驾驶安全性评估数据库。他们的野心是,未来你的车要想拿L4牌照,不需要上路跑个几年,只要在这个虚拟数据库里,把这几万种物理极限场景考过就行。
三、 L4的真相:不是为了酷,是为了“活着”
看完了硬核的技术标准,再看看落地的政策。
MLIT发布的《实现L4级自动驾驶的措施》里,透露出的紧迫感并非来自科技竞争,而是人口危机。日本的目标很明确:到2025年,在全国50个地区实现真正的无人出行服务(RoAD to the L4项目)。
但日本的L4落地有一个极具特色的前置条件:混行空间下的远程监控。
不同于我们在空旷示范区里的测试,日本的L4预设场景就是狭窄、人车混杂的乡村或老龄化社区。因此,日本法律(2023年4月实施的新《道路交通法》)强制要求L4级服务必须设立“特定自动运行主任技术者”。
这实际上是一套“人机互补”的方案:AI负责开车,人类在远端负责监控和兜底。PPT中展示了福井县永平寺町的案例(参考MLIT ICV近况文件第7页),一辆仅以12km/h速度行驶的无人车,背后是一整套远程监控室和电磁感应线(Induction wire)作为保底。
这种看起来“很土”的技术路线,恰恰反映了日本的务实:在AI无法处理100%长尾场景之前,用人力和基建的确定性来填补最后1%的安全漏洞。
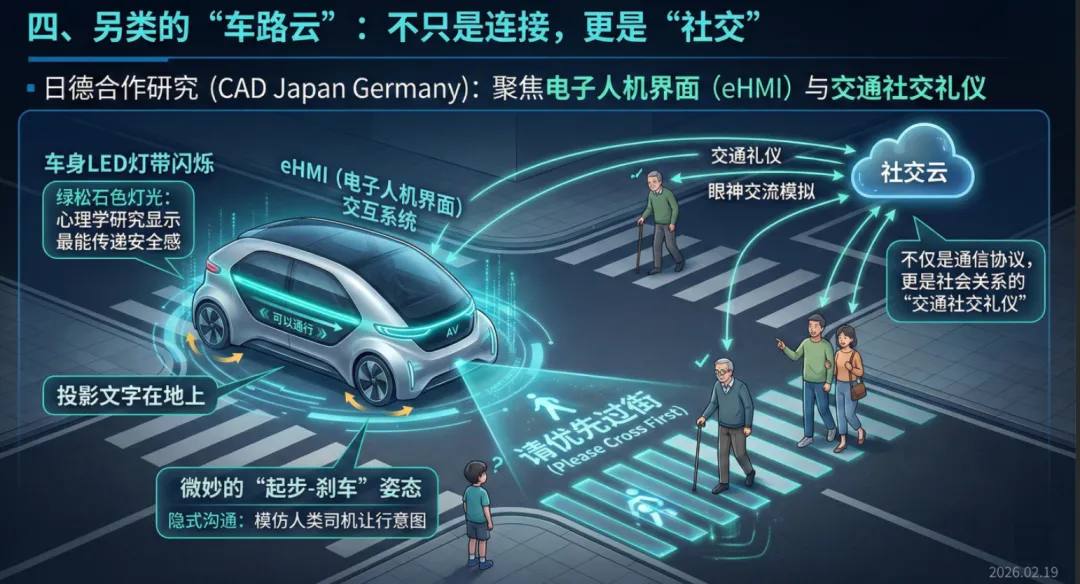
四、 另类的“车路云”:不只是连接,更是“社交”
说到“车路云一体化”,国内往往联想到的是路侧感知杆、边缘计算、红绿灯读秒。但在日本与德国合作的研究项目(CAD Japan Germany)中,我看到了一种完全不同的V2X思维——电子人机界面(eHMI)。
在他们的PPT中(参考日德合作研究文件),研究重点不是“车怎么从路端获得数据”,而是“车怎么跟人说话”。
举个很有意思的实验:当一辆自动驾驶车在没有斑马线的路口遇到行人,车该怎么做? 日本和德国的研究人员测试了各种方案:
- 车辆进行微妙的“起步-刹车”姿态(Implicit communication)?
他们发现,技术不仅仅是效率工具,更是社会关系的一部分。如果自动驾驶汽车不能像人类司机那样进行“眼神交流”,就会造成交通瘫痪或恐慌。因此,他们的“车路云”不仅是通信协议,更是一套“交通社交礼仪”。他们甚至在研究,不同颜色的外屏灯光(比如绿松石色)对路人过街意愿的心理学影响。
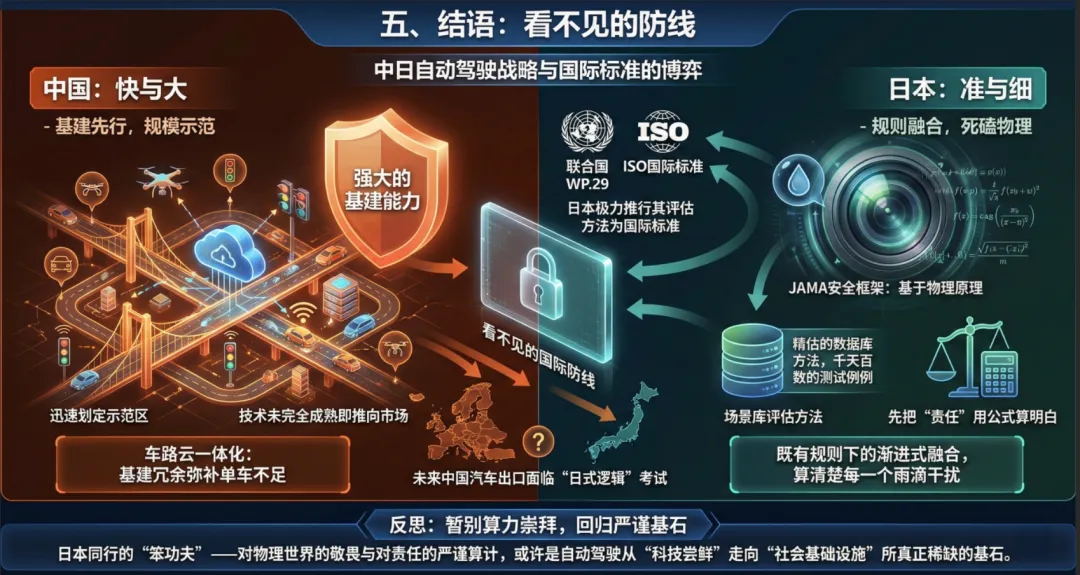
五、 结语:看不见的防线
对比中日两国,能看到两种截然不同的文明底色。
中国的优势在于“快”与“大”。我们有强大的基建能力,政府可以迅速划定示范区,企业敢于在技术尚未完全成熟时就推向市场进行迭代。我们的“车路云”是一张巨大的网,试图通过基建的冗余来弥补单车智能的不足。
而日本的优势在于“准”与“细”。他们深知自身资源有限,无法像中国一样进行大规模基建翻新,因此更强调在既有规则下的渐进式融合。
JAMA那套死磕物理公式的安全框架,虽然看起来没有“端到端大模型”那么性感,但它正在构建一条隐形的国际防线。日本目前是联合国WP.29自动驾驶工作组的主席国,他们正在极力将这套基于物理原理和场景库的评估方法推行为ISO国际标准。
这意味着,未来中国的汽车要卖到欧洲或日本,可能都得通过这套“日式逻辑”的考试。
在L4迟迟无法大规模盈利、大模型“幻觉”难以根除的今天,也许我们该暂时放下对算力的盲目崇拜,回头看看日本同行。他们那种把每一个雨滴对传感器的干扰都算清楚的“笨功夫”,那种先把“责任”用公式算明白再上路的严谨,或许正是自动驾驶从“科技尝鲜”走向“社会基础设施”所真正稀缺的基石。
毕竟,信任,才是自动驾驶最难跨越的那座山。
(注:本文核心数据及技术细节援引自 JAPIA/JAMA《自动驾驶安全评估框架 2.0》、MLIT《ICV相关的日本近况》及日德联合研究报告)



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
