当自动驾驶SoC算力过剩时,数据搬运工的效率在哪里?
- 2026-03-12 12:44:22

近五年,自动驾驶技术的发展与SoC算力的指数级增长密不可分。从几十TOPS到如今已经上千,甚至迈向2000 TOPS的门槛。然而,一个根本性的问题随之浮现:系统的性能是否等同于其核心计算单元的峰值算力?
答案显然是否定的。一个完整的自动驾驶任务流程,是从传感器数据采集开始,经由数据传输、预处理、AI推理,最终输出决策指令的复杂闭环。
在这个链条中,负责将海量数据从系统各处高效、低延迟地送达计算核心的“数据搬运工”——即数据移动引擎及其依赖的通信总线,其效率正成为木桶的最短板。
峰值TOPS仅反映理论计算能力,并不能代表实际应用中的处理能力,存在局限性。在2000 TOPS时代,系统瓶颈已从“算不动”转向了“运不快”,片间通信带宽不足正成为限制下一代自动驾驶平台性能的“阿喀琉斯之踵”。
我们先对输入数据量与系统传输能力进行量化对比。
传感器数据的爆炸式增长
高级别自动驾驶系统通常配备一套庞大且高精度的传感器组合,其产生的数据量是惊人的:
摄像头:作为数据量最大的传感器,系统通常搭载8颗甚至更多的高清摄像头。一颗800万像素(4K)摄像头以30fps的帧率工作时,其原始数据流速率可达3-4 Gbit/s。若采用多路8K视频流,数据量将更为恐怖。一个典型的视觉方案,仅摄像头部分就能轻易产生超过30 Gbit/s的原始数据。
激光雷达:高线束(如128线)激光雷达每秒可产生数百万个点云数据,数据速率通常在20-100 Mbit/s之间,但下一代高分辨率成像雷达的数据量正朝Gbps级别迈进。
毫米波雷达与其他传感器:尽管单个雷达的数据量较小(通常在15 Mbit/s以下),但多雷达融合以及未来4D成像雷达的应用,也将显著增加总数据带宽需求。
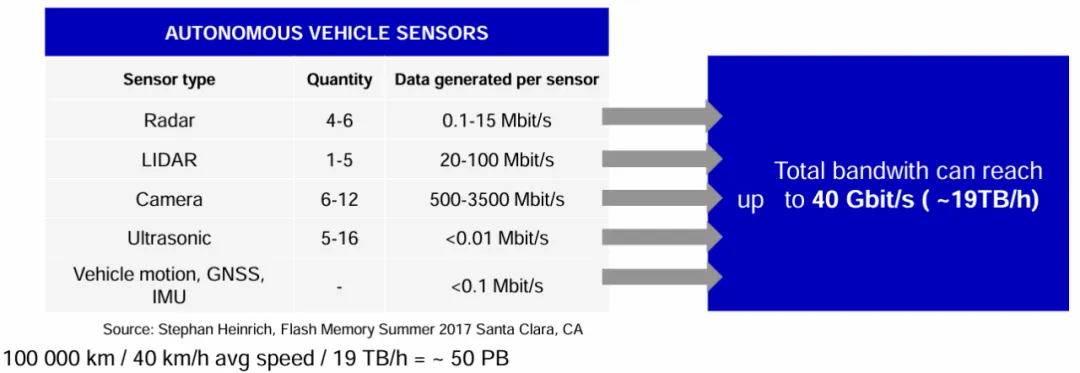
图源:dSPACE
综合来看,一个典型的L4级自动驾驶平台,其所有传感器并发产生的原始数据带宽峰值需求,可以轻松突破100 Gbit/s,甚至在未来会达到每小时TB级别的数据规模。这些数据必须以极低的延迟从传感器接口传输到中央计算单元的SoC中进行处理。
片间通信的“高速公路”有多宽?
与庞大的数据输入形成鲜明对比的是,当前主流SoC之间或SoC与外围设备间的通信带宽,虽在不断进步,但仍显捉襟见肘。
PCI Express (PCIe):这是目前最主流的高速片间互联技术。PCIe 5.0 x16的理论双向带宽约为64 GB/s,而更先进的PCIe 6.0 x16则翻倍至约128 GB/s。
虽然数字看起来很高,但这是SoC与加速器(如另一颗SoC或专用芯片)之间理想状态下的峰值带宽,且通常需要占用大量芯片引脚和复杂的PCB布线。在实际车载环境中,受限于成本、功耗和空间,可能无法部署全速率的x16通道。
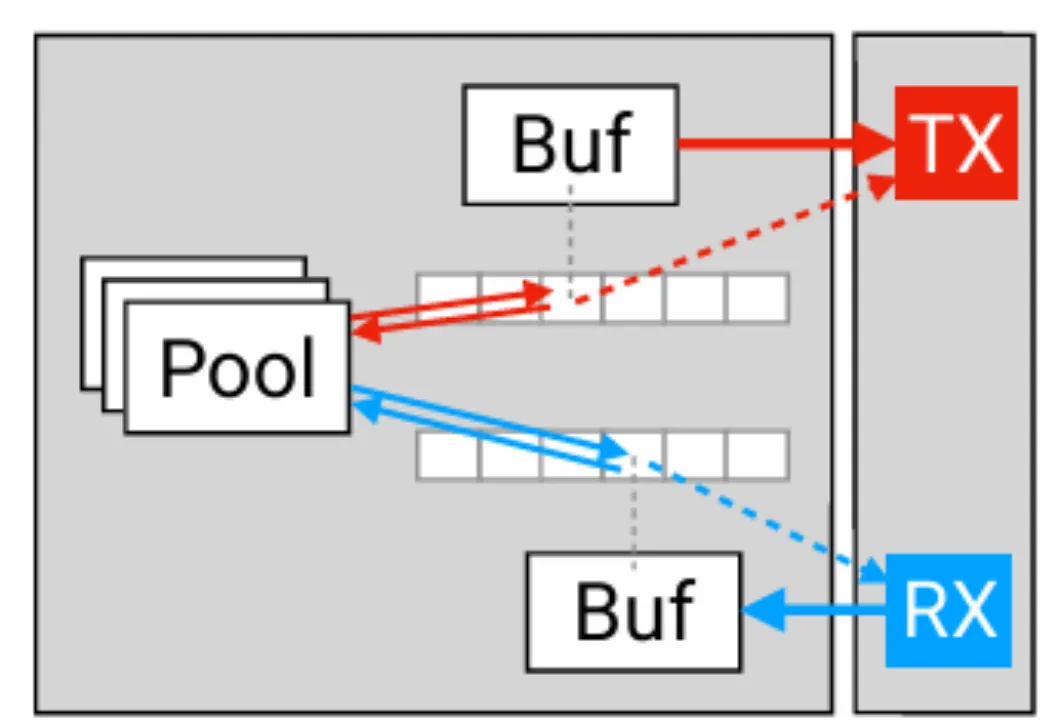
上图展示了PCIe NIC的基本架构
Compute Express Link (CXL):基于PCIe物理层构建的CXL,增加了内存一致性协议,对于多SoC协同计算和内存扩展至关重要。CXL 2.0/3.0的带宽与PCIe 5.0/6.0相当它更多解决的是内存访问和一致性问题,但物理带宽的上限依然受制于PCIe物理层。
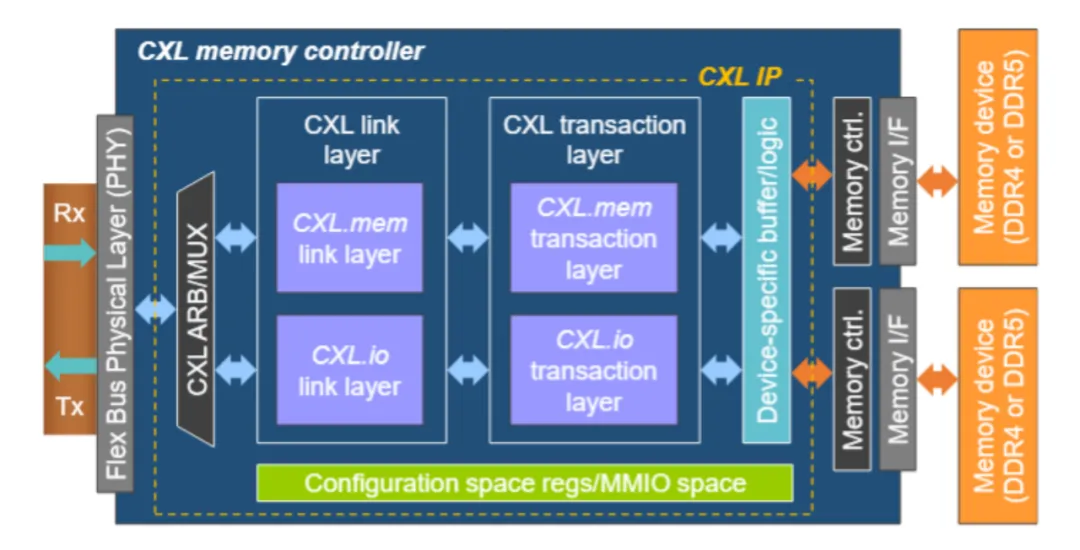
上图展示了CXL的基本架构
车载以太网:虽然车载以太网速率已发展到10 Gbit/s甚至更高,但它主要用于不同域控制器之间的通信,其协议开销和延迟特性,决定了它不适合作为中央计算单元内部SoC或Chiplet之间的高强度、低延迟数据交换总线。
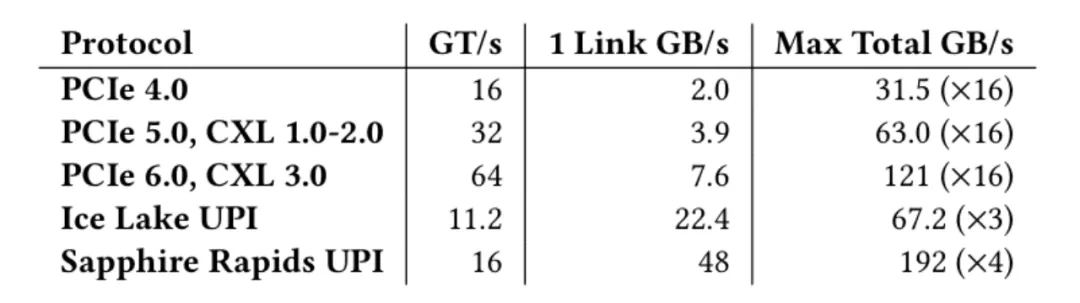
上图展示了PCIe、CXL和Intel UPI的带宽能力
算力饱和,带宽告急
将传感器数据流(峰值>12.5 GB/s)与片间通信带宽(如PCIe 5.0 x8,单向约16 GB/s)进行对比,看似尚有余量。但问题在于:
多路并发与共享带宽:带宽并非专用于传感器数据输入。SoC之间需要频繁交换中间处理结果、同步状态,AI加速器需要从内存抓取模型权重和数据,这些都会抢占宝贵的总线带宽。
延迟是隐形杀手:带宽瓶颈不仅降低吞吐量,更会急剧增加数据传输延迟。对于毫秒必争的自动驾驶决策而言,数据在传输路径上的任何拥堵和等待都可能是致命的。
多芯片架构的必然性:实现2000 TOPS级别的算力,往往需要采用多SoC级联或Chiplet(芯粒)集成方案。这意味着数据不仅要在芯片内部流动,更要在不同的物理芯片或芯粒之间穿梭,每一次跨越都依赖于前述的片间互联接口,瓶颈效应被进一步放大。
一个2000 TOPS的计算集群,可能因为数据无法及时“喂给”算力单元,导致大量的计算周期被浪费在等待I/O上。系统的实际有效算力远低于其峰值标称,数据搬运工的效率,直接决定了这2000 TOPS算力的“兑现率”。
DMA效率与系统架构的挑战
数据在系统内部的流动,主要依赖于DMA引擎。然而,这个默默无闻的“搬运工”如今正面临前所未有的压力。
DMA引擎:从幕后英雄到性能瓶颈
DMA的核心作用是在不需要CPU干预的情况下,直接在内存和外设之间,或者内存的不同区域之间高速传输数据,从而将CPU解放出来专注于计算任务。然而,DMA自身的性能并非无限。
性能黑盒:一个令人担忧的现状是,尽管芯片厂商大肆宣传其SoC的TOPS值,但对于其内部DMA引擎的关键性能指标——如在搬运真实传感器数据(如8K视频流、LiDAR点云)时的峰值吞吐量和端到端平均延迟——却少有公开的、标准化的基准测试数据。
受限于物理链路:DMA的搬运速度,最终受限于其所连接的总线物理带宽(如PCIe)和内存子系统的访问带宽。当总线拥堵时,DMA控制器也无能为力,只能排队等待。
协议开销:在复杂的SoC中,数据传输需要经过多层总线协议、仲裁和数据包的封装/解封装,这些都会带来额外的延迟和开销,降低有效数据传输率。
因此,即使SoC内部集成了高效的DMA引擎,如果连接各关键部件的“道路”(即片间互联)本身狭窄且拥堵,DMA的效率也无从谈起。
重构数据流,为搬运工“修路搭桥”
要解决数据搬运的效率困境,必须超越单纯的算力升级,从系统架构、互联技术和封装层面进行一场深刻的革命。
新一代互联标准:UCIe与CXL的曙光
(1)Universal Chiplet Interconnect Express (UCIe)
UCIe是为Chiplet时代量身打造的开放标准,旨在解决封装内Die-to-Die的高效互联问题。
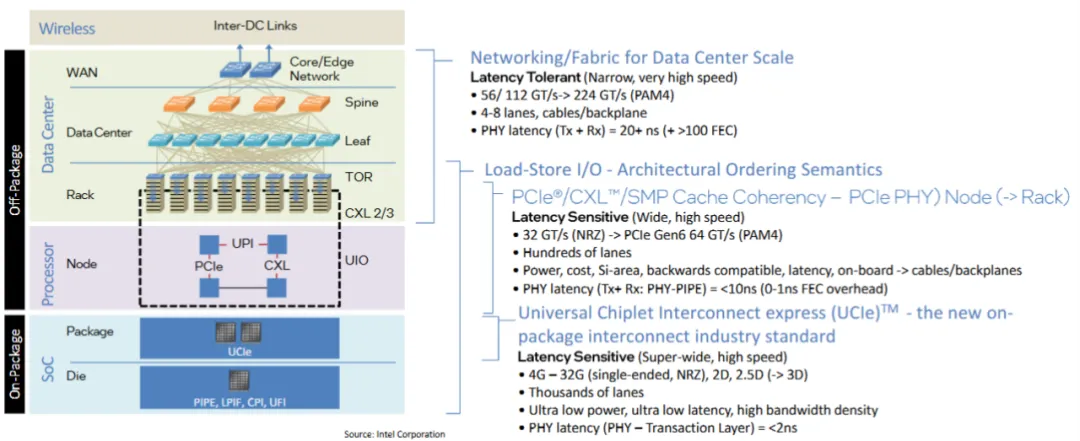
图源:英特尔
上图展示了从封装内Die-to-Die互联到数据中心网络的完整互联层级,其中UCIe作为新一代封装内互联标准,凭借超低延迟、高带宽密度的特性,为Chiplet架构提供了高效的Die-to-Die互联解决方案。
它的出现是革命性的,因为它提供了:
超高带宽密度:UCIe通过先进的封装技术,可以在极小的芯片边缘上实现极高的带宽,其带宽密度目标可达TB/s/mm²级别。这远超传统PCB上的PCIe连接。
超低延迟:由于物理距离极短,UCIe的物理层延迟可以控制在2纳秒以内相比PCIe的数十甚至上百纳秒延迟,实现了数量级的降低。
通过UCIe,可以将一颗2000 TOPS的SoC设计为多个功能最优化的Chiplet(如CPU、AI加速器、I/O),并通过超宽、超快的内部总线连接,消除传统意义上的“片间”带宽瓶颈,为数据搬运工铺设了无拥堵的“内部高速公路”。
(2)CXL的内存语义扩展
CXL通过其内存一致性协议,允许多个计算单元共享和池化内存资源。这意味着数据不再需要在不同SoC的私有内存之间进行低效的复制,计算单元可以直接访问共享内存中的数据,极大地减少了不必要的数据搬运,提升了DMA的搬运效率和系统的协同能力。
封装革命:从2D到3D,无限拉近距离
先进封装技术是实现新一代互联标准的基础。通过2.5D和3D堆叠技术,可以将计算芯片和高带宽内存等组件在垂直方向上紧密集成。
HBM的应用:将HBM直接封装在SoC旁边,通过数千条数据线路连接,可以提供高达TB/s级别的内存带宽。这解决了AI计算中对内存带宽的极度渴求,确保算力单元不会因为等待数据而“挨饿”。
缩短物理距离:3D封装从根本上缩短了信号传输的物理路径,这不仅降低了延迟,还显著减少了数据传输的功耗。数据搬运的每一步都变得更“经济”、更快捷。
架构创新:从源头减少不必要的数据搬运
除了“修路”,更聪明的做法是减少“货运量”。
智能传感器与边缘预处理:改变将所有原始数据都传回中央SoC的传统模式。在传感器端或区域控制器进行预处理,例如图像的ISP处理、LiDAR点云的降噪与特征提取。这种“数据规整”可以成倍地降低需要通过主干网络传输的数据量,从源头上为数据搬运工减负。
存内计算:这是更具颠覆性的架构思想。它旨在打破传统冯·诺依曼架构中计算与存储分离的壁垒,直接在存储单元内执行部分计算任务。对于神经网络这类计算密集且数据复用率高的应用,CIM可以消除绝大部分数据在计算单元和内存之间的往返搬运,实现能效比的巨大飞跃。
光子互连的远景:对于未来需要连接多个超算模块的更复杂系统,铜线互连将达到物理极限。共封装光学技术,利用光作为传输介质,有望提供数十乃至上百Tbps的超高带宽和更低的功耗,彻底解决长距离、高带宽的互联挑战。
—end—

推荐阅读:
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 华山论剑|以一场新轿车体制的变革,定义新能源时代的丰田味道
- 2026款仰望U7豪华轿车发布,配备1006公里续航和闪充功能
- 奔驰EQE 500四驱轿车
- 本田大招“连发”,轿车SUV一起降
- 数据分享 | 2025年度国内轿车投诉分析报告
- 搭全新发光中网!首款搭四驱中级电混轿车!银河星耀7黑棚图首曝!
- 全国政协委员江浩然:建议加快高级别自动驾驶场景规模化落地
- 比亚迪发布Seal 08旗舰轿车,目标为1000公里续航和Blade Battery 2.0
- 突发!一汽奔腾轿车“飞”入滨海大道中间隔离带!
- 女性友好型豪华 SUV 更新!凯迪拉克 XT4 智驭尊贵型上市, 一口价15.99 万起诚意拉满
