多模态数据正成为很多企业关注的热点,但如何挖掘其价值,许多企业仍在探索中。在自动驾驶领域,图像、点云、信号等多源数据已成为业务核心,其数据体系建设积累了丰富经验。本文结合该领域实践,探讨多模态数据建设的关键思路,希望能为相关决策者提供参考。
一、业务场景:海量多模态数据下的高频交互需求
该企业每日新增数据量达数百TB,总数据量累积至百PB级。原始数据经过切分与清洗,形成海量的数据资产(Clip),每个Clip包含连续帧序列及丰富的元数据。目前Clip数量已超数亿,对应训练帧规模达百亿以上。算法工程师在日常研发中,需要频繁执行以下任务:
- 数据资产检索:根据城市、天气、车型、传感器类型等条件,快速定位目标数据;
- 训练数据集构建:基于标签组合(如“夜间+行人”)筛选帧数据,生成新的训练集或仿真测试集;
- 标签分布分析:统计各类标签(行人、车辆、交通灯等)在数据集中的占比,评估数据质量与分布缺口;
- 复杂场景挖掘:寻找长尾案例或模型误判的困难样本,用于针对性训练。
这些任务对平台的实时性与并发能力要求苛刻:需支持百万帧/秒的可见性,并在较高查询并发下保持秒级响应。
二、多模数据搜索的四种典型模式
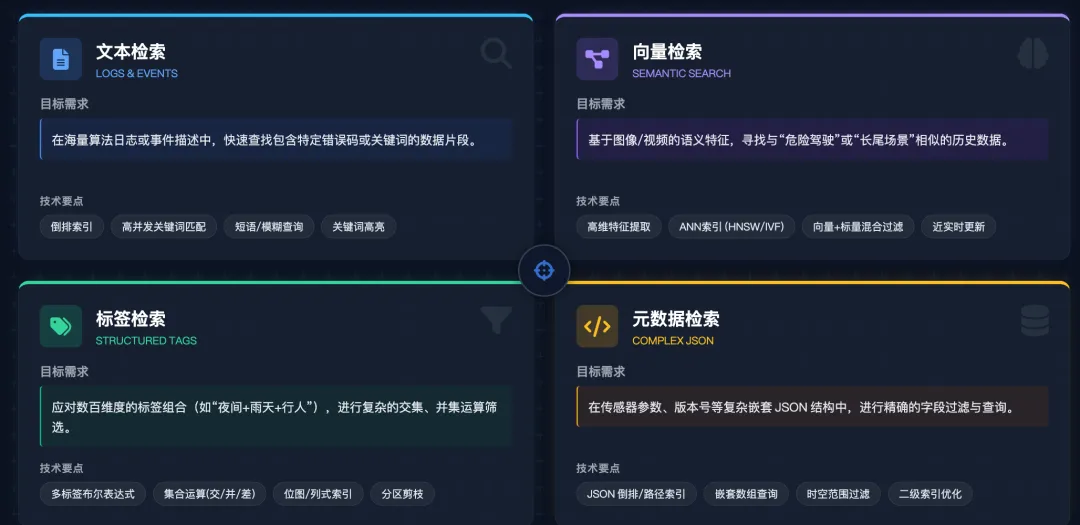
自动驾驶数据体系的显著特点是数据类型极度丰富:图像、点云、视频、标签、日志以及各类结构化或半结构化元数据,共同构成复杂的数据生态。从应用视角看,几乎所有的数据利用都离不开“搜索”——在海量数据中找到符合条件的数据片段。这些搜索需求可归纳为四种类型:
- 文本检索:解决“找到包含某些关键词的数据”的问题,例如在日志中查找错误码,或在事件描述中定位特定关键词。这类检索依赖倒排索引,强调高效的关键词匹配能力。
- 向量检索:随着视觉语言模型和深度学习特征提取技术的发展,图像、视频等非结构化数据常被转换为高维向量,用以表达语义信息。通过向量检索,可在历史数据中寻找语义相似的场景,如与某个危险驾驶场景相似的历史数据,或模型误判的相似案例。这类检索注重语义相似性,而非精确匹配。
- 标签检索:训练数据中每一帧往往带有大量标签,如“包含行人”“夜间场景”“雨天”等。算法工程师常需通过标签组合(如“复杂路口+红绿灯”)构建数据集。由于标签维度可达数百甚至上千,系统需支持高效的多标签集合运算(交集、并集、差集)。
- 元数据检索:采集数据常附带车辆配置、软件版本、传感器标定、故障记录等元数据,多以JSON等半结构化形式存储,还包含复杂嵌套结构。工程师需要在其中进行精确过滤,如查找某车型在特定时段内出现某种故障的采集数据。这要求平台具备高效的JSON解析与复杂条件过滤能力。
可见,自动驾驶数据平台不仅需支持多种搜索模式,还必须在海量规模下保证查询效率,这对底层数据架构提出了严苛挑战。
三、复杂的多模数据处理架构
为解决多模数据管理难题,企业在原始多模数据之上构建了三种独立的数据处理链路:
- 大数据仓库链路:将结构化标签通过ETL加工后存入Hive/Iceberg,用于标签分析、统计报表和数据集构建。该链路以批处理为主,延迟较高,难以满足实时交互需求。
- 图文检索链路:对视频帧提取向量特征,存入向量数据库(如Zilliz),支持向量+标量的混合检索,用于相似场景挖掘。但向量库与数仓分离,跨系统查询需搬运数据,效率低下。
- 元数据检索链路:将车辆状态、事件等元数据存入Elasticsearch,利用其JSON检索能力。但ES在海量数据下的复杂聚合性能有限,且无法与标签库统一关联分析。
三条链路之上虽有查询服务进行统一封装,但数据查询往往需要跨系统联动。例如工程师需先通过元数据系统筛选数据资产,再到数仓中分析标签分布,最后到向量数据库查找相似场景。这种多系统串联的流程不仅复杂,而且延迟较高。同时,多系统导致数据同步和运维成本高昂,数据结构变化时多个系统需同步调整。随着数据规模攀升至数百亿级,传统系统在查询性能和扩展性方面也面临压力。
四、统一多模数据搜索与分析的构建思路
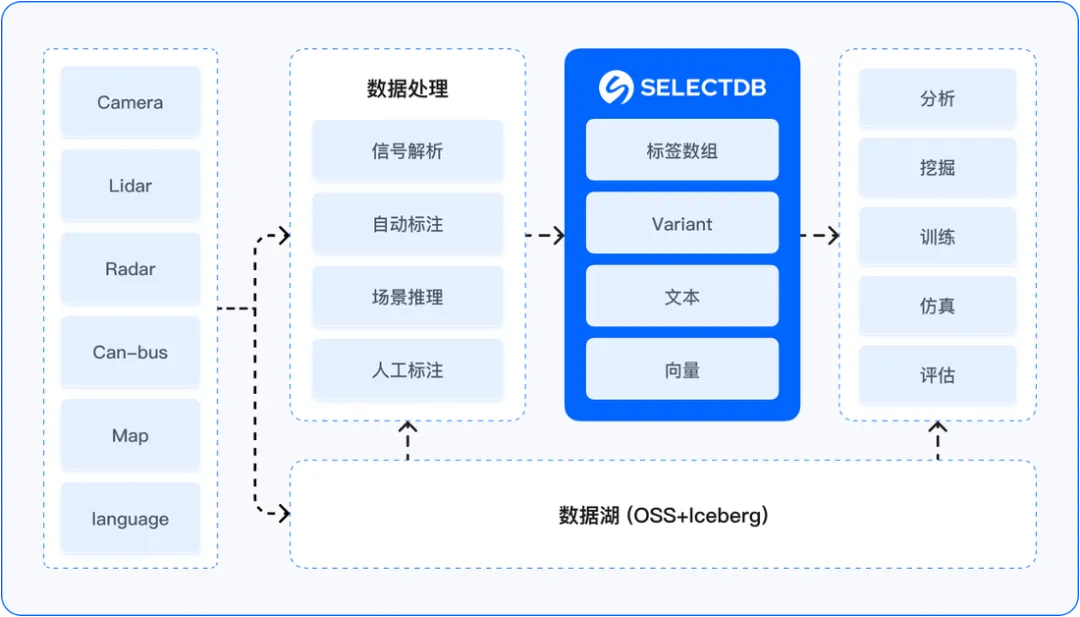
面对上述挑战,企业开始探索统一的多模数据架构。在早期阶段,该企业已经引入了Apache Doris来解决标签搜索与分析问题。Doris在标签场景下表现优异——其向量化执行引擎和MPP架构能够高效支撑百亿级标签的实时聚合与筛选,这一能力在互联网用户画像、人群圈选等场景中已得到广泛验证。企业将Doris用于训练帧的标签组合查询后,显著提升了数据集的构建效率。
随着Apache Doris及其商业版SelectDB逐步扩展了能力边界——开始支持全文检索(倒排索引)、向量索引以及半结构化数据(如JSON)的高效处理。企业顺势往SelectDB作为统一多模搜索和分析引擎的架构演进,尝试将原本分散在数仓、向量库、ES中的数据整合。以下是该架构的核心设计思路:
1. 冷热数据分层
高频访问的近期数据可存储在具备高性能查询能力的在线存储中,通过时间分区和设备分桶优化并发查询;历史数据则下沉至成本更低的数据湖(如Iceberg)进行长期保存。利用联邦查询能力,用户可在同一接口下透明访问冷热数据,实现无感分层管理。
2. 元数据检索的优化
对于JSON格式的元数据,现代数据平台可提供专门的数据类型(Variant)来直接存储JSON,并结合倒排索引实现高效检索。复杂的嵌套字段可在SQL中直接展开,支持任意条件的过滤。这种设计使得数十亿级元数据的检索仍能保持较高效率。
3. 标签数据的集合运算加速
针对帧级标签,可采用Bitmap数据结构进行建模:每个标签对应一个帧ID的位图,标签组合查询转化为Bitmap的集合运算(交、并、补)。这种方案即使在百亿级规模下,也能实现秒级的复杂场景统计。同时,支持主键模型的实时写入,可使新标签数据在秒级内可见,每天可处理数百亿条标签更新。
4. 向量检索的整合
平台可内置向量索引能力,将图文特征向量与标量数据统一存储,实现向量与标签/元数据的混合检索。这避免了数据在不同系统间搬移,简化了相似场景挖掘的流程,也为未来多模态联合查询打下基础。
5. 统一查询引擎
通过支持SQL接口同时访问标签、元数据、向量等不同类型数据,平台可让用户在一个查询中完成复杂的数据探索,无需切换系统。统一的索引和存储管理也大幅降低了开发和运维成本。
五、统一多模数据搜索与分析架构带来的收益
经过上述改造,企业在多模态数据管理方面获得了显著提升:
- 查询性能大幅跃升:从分钟级响应降至秒级,算法工程师可实时探索不同标签组合下的数据规模,交互式分析成为可能。
- 数据准备效率提升:数据集选样从离线批处理转变为实时交互,训练数据准备周期明显缩短。
- 系统可扩展性增强:统一平台能够稳定支撑近7天千亿级数据的检索,并应对近千QPS的并发负载。
- 架构简化与成本降低:统一数据引擎同时支持标量、JSON、向量检索,减少了多系统维护的复杂度,数据同步和开发成本随之下降。
六、总结
自动驾驶领域的多模态数据建设,核心在于构建一个能够同时处理文本、向量、标签、元数据等多种数据类型,并支持高效检索与分析的统一平台。从分散式架构走向融合,不仅提升了查询性能与开发效率,也为未来更智能的数据驱动研发奠定了基础。这一思路对于其他面临多模态数据挑战的行业(如智慧城市、工业质检、内容推荐等)同样具有借鉴意义。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
