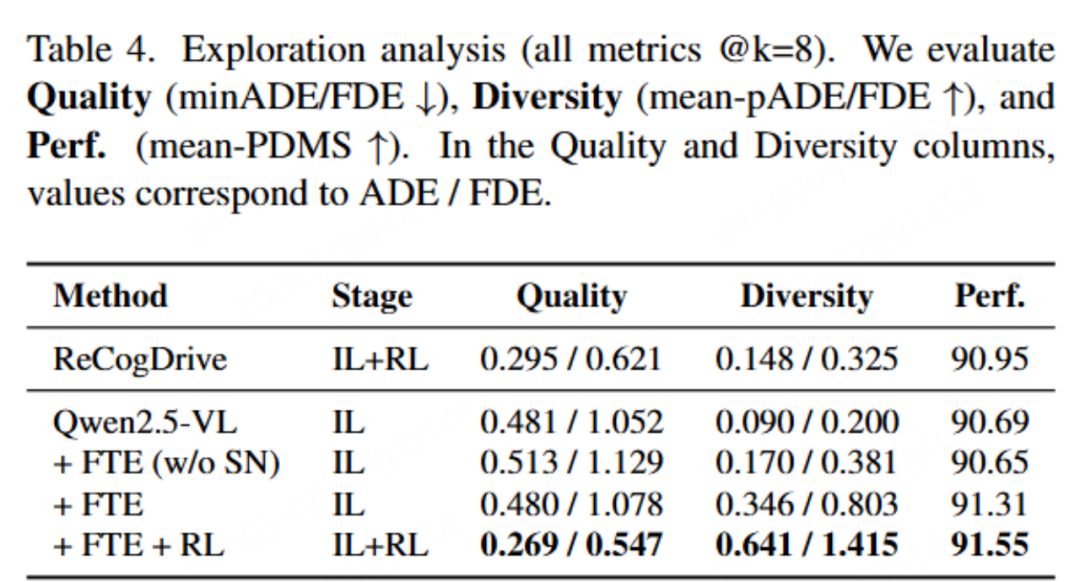
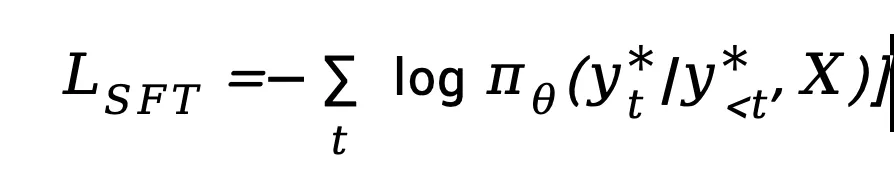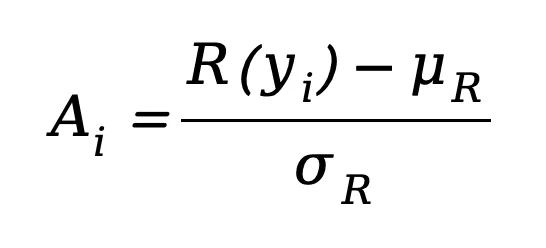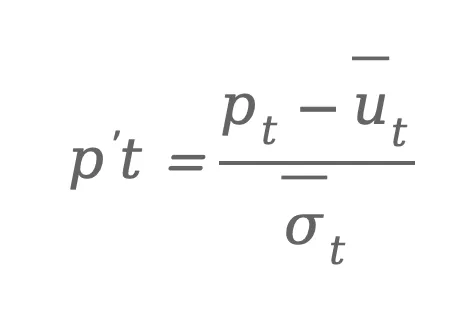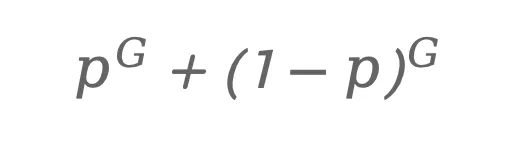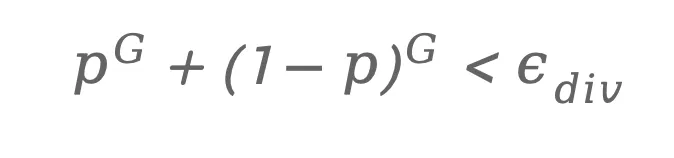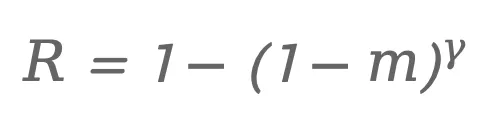自动驾驶VLA的一个隐藏问题
过去一年,自动驾驶研究正在快速转向一种新的技术范式:Vision-Language-Action(VLA)模型。在这一框架下,自动驾驶被重新建模为一个统一的生成问题——模型接收多模态环境信息(摄像头图像、车辆状态、导航指令等),然后直接生成未来的驾驶轨迹。从 DriveGPT、EMMA,到 AutoVLA、Orion、ReCogDrive,一系列工作都在探索如何利用多模态大模型承担自动驾驶中的决策与规划任务。
然而,如果仔细观察当前主流VLA系统的技术路线,会发现一个非常普遍的设计模式:以多模态大模型(MLLM)作为语义理解与推理底座,在其之上往往外挂一个专门的轨迹规划模块,例如 Diffusion Planner 或其他生成式规划器。这种结构能够在一定程度上弥补语言模型在连续控制上的不足,但同时也增加了系统复杂度,并在一定程度上限制了模型能力随规模扩展的潜力。
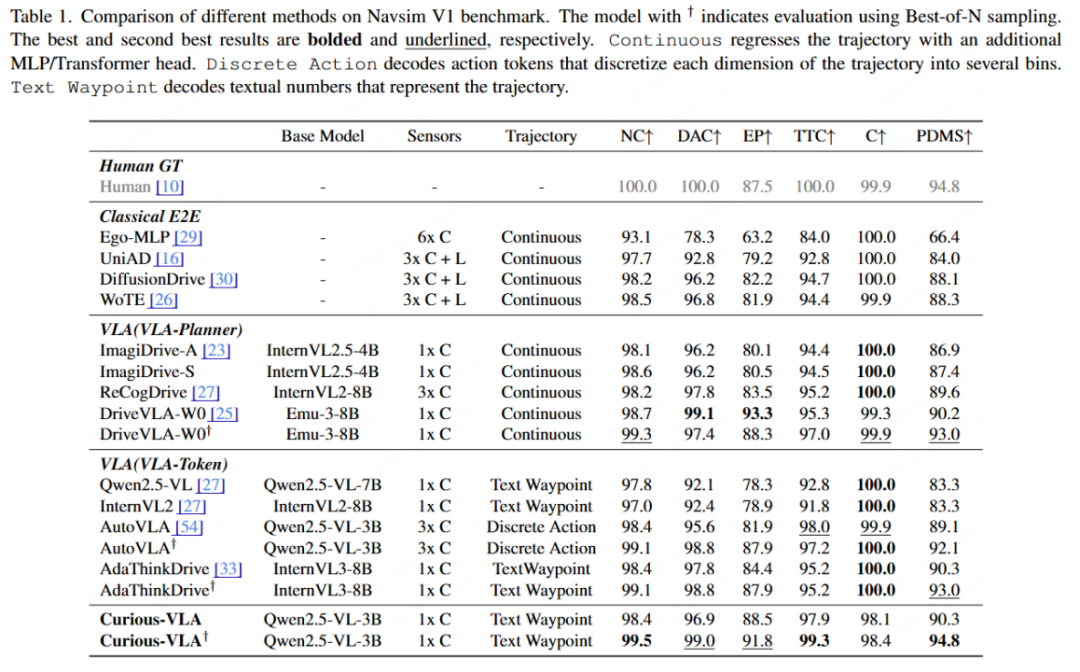
相比之下,Curious-VLA选择了一条更加激进的技术路径:完全依赖MLLM的自回归生成能力来完成轨迹规划,而不引入额外的Action Token设计,也不依赖Diffusion Planner等复杂规划模块。令人惊讶的是,在这种更加简洁的模型结构下,该方法依然能够在Navsim基准上取得VLA自动驾驶的SOTA性能。
按理说,在这种“纯MLLM自回归规划”的VLA模型中,强化学习应该能够进一步提升模型的策略质量,并帮助模型探索更加优越的驾驶行为。然而在许多相关工作中,强化学习带来的提升却非常有限。有些模型在加入RL之后只获得了极小的性能改进,甚至性能出现了下降。
这就引出了一个关键问题:为什么在自回归VLA模型中,强化学习几乎没有发挥作用?
在论文《Devil is in Narrow Policy: Unleashing Exploration in Driving VLA Models》中,作者给出了一个非常关键的解释——问题不在强化学习本身,而在于策略已经在模仿学习阶段“塌缩”了。换句话说,当RL开始训练时,模型其实已经只会一种驾驶方式。
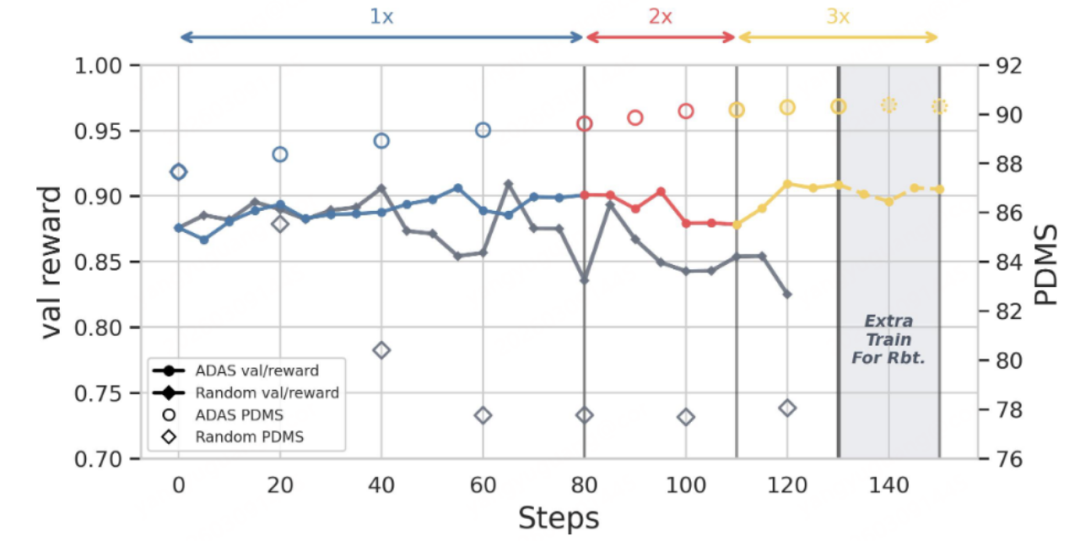
VLA应用本文提出强化学习方法ADAS(ADAS val/reward)与直接应用GRPO(Random val/reward)强化学习的效果对比图(来源:论文 补充材料Figure 6)
一个被忽视的问题:Narrow Policy
在分析自动驾驶VLA训练流程时,作者提出了一个此前几乎没有被系统讨论的问题:Narrow Policy(策略过窄)。简单来说,Narrow Policy指的是模型在决策时只会生成非常单一的一类驾驶轨迹,缺乏必要的策略多样性。
为了验证这一现象,论文对现有两类代表性VLA模型进行了实验分析,包括基于轨迹token生成的Qwen2.5-VL,以及带外部规划器的ReCogDrive。研究者对同一个驾驶场景多次采样模型输出轨迹,并统计这些轨迹之间的差异。结果发现,无论是哪一类方法,生成的轨迹都高度相似,几乎集中在同一个模式上。即使旨在生成Multimodal轨迹端到端模型DiffusionDrive,其最高置信度的“选中轨迹”也出现多样性堪忧
Narrow Policy问题示意图(来源:论文 Figure 1(b))
这意味着,即使在一个存在多种合理驾驶策略的场景中,模型仍然倾向于给出几乎相同的决策。论文将这种现象称为探索塌缩(exploration collapse)。更直观地说,当模型面对一个路口时,人类驾驶员可能会存在多种合理策略,比如略微提前减速、稍微晚一点刹车、或者选择不同的通过轨迹。但在当前VLA模型(以及部分端到端模型)中,多次推理得到的轨迹往往几乎重合。
这种现象在论文的可视化Figure 1结果中非常明显:基线模型生成的多条轨迹几乎重叠,而作者方法生成的轨迹则呈现出明显的多样性。为了系统分析这一问题,论文提出了一组Behavioral Diagnostics 指标来量化策略探索能力:
第一是Diversity,用于衡量模型生成轨迹之间的差异程度;
第二是Quality,表示采样轨迹中与真实轨迹最接近的一条;
第三是Performance,即整体驾驶性能指标(例如Navsim 的 PDMS)。
理想情况下,一个优秀的自动驾驶模型应该同时具备三个特征:既能够生成多样化的候选轨迹,又能够在这些轨迹中找到高质量的驾驶策略,最终实现整体驾驶性能的提升。但现实情况是,大多数现有VLA模型在 Diversity 指标上都非常低,说明策略空间已经严重收缩。
Narrow Policy分析(来源:论文 Figure 1(a))
而这一问题的根源,其实来自训练流程中的第一阶段——模仿学习(Imitation Learning)。
为什么模仿学习会导致策略塌缩
如果进一步追溯Narrow Policy 的来源,问题其实出现在训练流程的第一阶段——模仿学习(Imitation Learning, IL)。作者从两个方面展开了分析:
1.模仿学习的监督信号过强:在当前主流VLA方法中,模型通常通过监督微调(SFT)学习人类驾驶数据。训练目标非常简单:给定环境输入,让模型预测与数据集中 真实驾驶轨迹(Ground Truth trajectory)一致的轨迹token。从优化角度来看,这一过程本质上是在最小化Cross-Entropy loss:
也就是说,模型在训练过程中会被持续鼓励去生成唯一正确的轨迹。问题在于,自动驾驶并不是一个只有单一正确答案的任务。在大多数真实驾驶场景中,往往存在多种同样安全、合理的驾驶策略。例如在一个路口减速时,稍微早一点刹车或晚一点刹车,都可能是完全合理的行为。但在模仿学习框架下,训练数据只提供了一条轨迹,其它策略都会被当作“错误答案”。这就导致模型逐渐学到一种极端行为:对数据中的那条轨迹产生高度自信,而忽略所有其它可能策略。论文将这种现象称为optimization objective mismatch——优化目标与真实驾驶策略空间之间存在明显不匹配。
2.轨迹表示的时间尺度不均衡问题:除了监督目标本身,作者还指出了另一个容易被忽略的问题:轨迹时间尺度的不均衡(horizon scale mismatch)。在自动驾驶任务中,模型通常预测未来几秒的多个waypoints。由于预测采用自车坐标系,越远的时间步,其位置分布的方差就越大。例如论文中指出,4秒后的轨迹位置变化可能比0.5秒后的变化大几个数量级。结果是,在训练过程中,远距离轨迹的误差会主导整体loss,而近距离轨迹(真正决定转向与控制精度的部分)反而贡献较小。 这进一步削弱了模型对驾驶行为细节的学习能力,也减少了策略的多样性。当这样的策略进入强化学习阶段时,问题就会进一步放大。强化学习通常通过采样多条轨迹来估计策略梯度。如果模型已经只会生成一种几乎相同的轨迹,那么这些样本的奖励也会非常接近。此时奖励方差会趋近于零,GRPO优势函数也会随之消失:
这就是为什么很多自动驾驶VLA工作在加入强化学习后几乎没有明显提升——因为模型在进入RL阶段之前,其策略空间其实已经被模仿学习严重压缩。换句话说,强化学习并没有真正的“探索空间”。
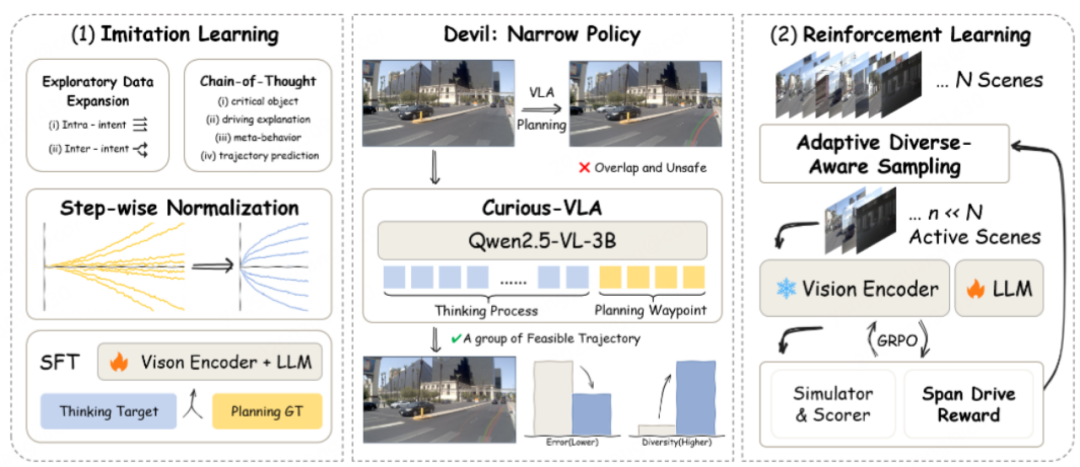
Curious-VLA:让自动驾驶模型重新学会探索
既然问题出在策略探索能力不足,那么解决思路其实就非常明确:在训练过程中重新引入探索能力。基于这一思路,论文提出了一个新的训练框架Curious-VLA。与现有方法不同,这一框架并没有改变VLA模型的结构,而是从训练流程入手,系统性地提升策略多样性。
整个方法可以概括为一句话:在模仿学习阶段增加轨迹多样性,在强化学习阶段鼓励策略探索。具体来说,Curious-VLA包含两个关键部分。
CuriousVLA整体框架图(来源:论文 Figure 2)
·第一部分是Feasible Trajectory Expansion(FTE),用于改造模仿学习阶段的数据分布。传统模仿学习只使用一条真实驾驶轨迹作为监督信号,而FTE的核心思想是:将真实轨迹视为众多合理驾驶行为中的一种,并主动生成更多“可行轨迹”。通过这种方式,模型在训练时能够看到多种合理驾驶策略,从而避免策略过度集中。
·第二部分是Diversity-Aware Reinforcement Learning,用于提升强化学习阶段的探索能力。论文通过新的采样策略和奖励设计,使强化学习更关注具有多样性的策略样本,从而持续推动模型探索新的驾驶行为。
这两个部分分别对应训练流程中的两个阶段:在模仿学习阶段,重点解决数据层面的策略单一问题;在强化学习阶段,重点解决策略更新中的探索不足问题。这种设计背后的逻辑其实非常简单。如果模仿学习阶段就已经把策略压缩到一个非常窄的分布,那么强化学习几乎不可能再重新扩展策略空间。因此,Curious-VLA首先通过数据扩展让模型看到更多合理轨迹,然后再通过强化学习逐步优化这些策略。
在接下来的两节中,我们分别来看这两个关键模块是如何实现的。
Feasible Trajectory Expansion (FTE)
为了从根本上缓解Narrow Policy 问题,论文首先从训练数据入手,提出了 Feasible Trajectory Expansion(FTE)。
其核心思想非常直接:不要只学习一条真实驾驶轨迹,而是学习一组合理的驾驶轨迹。
在传统模仿学习中,每个训练样本只包含一条人类驾驶轨迹,这会使模型逐渐收敛到一个极其狭窄的策略分布。而在真实驾驶环境中,同一个场景往往存在多种合理的驾驶行为,例如不同的减速时机、略微不同的转向路径等。
因此,论文将真实轨迹视为众多可行驾驶策略中的一个样本,并通过数据生成的方式扩展策略空间。具体来说,作者首先从Navsim 训练集约10万条数据中筛选出约 1.2万段具有挑战性的驾驶片段,例如多车道场景、复杂路口以及遮挡环境等。随后利用基于 diffusion 的规划模型生成多个候选轨迹,并通过 PDMS 安全评分进行过滤,确保这些轨迹在安全和交通规则上是可行的。最终,训练数据被扩展为 约14.2万条多样化轨迹样本。
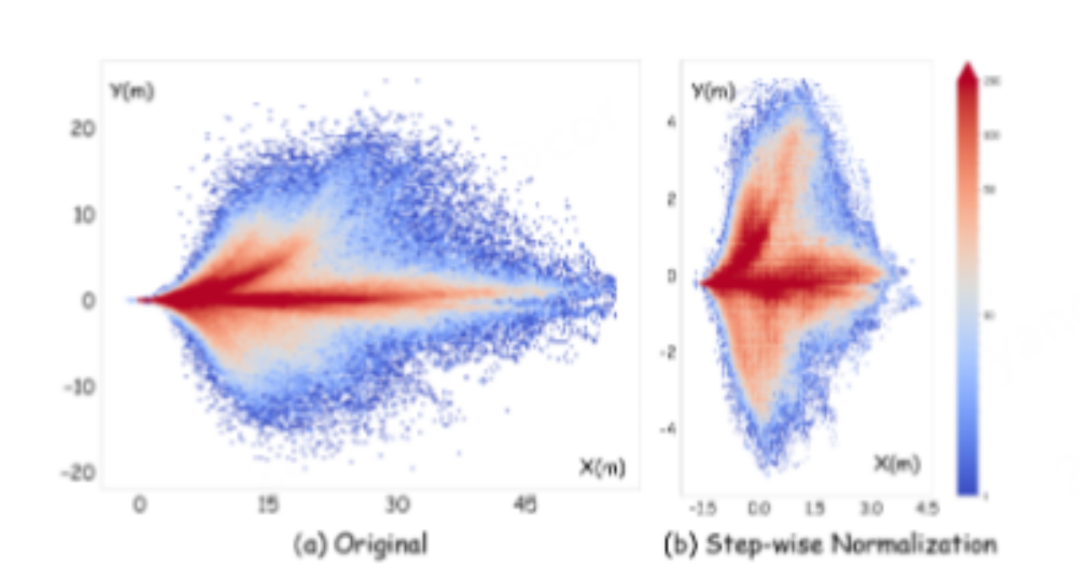
不过,当训练数据中包含大量不同轨迹时,又会出现一个新的问题:不同时间步的轨迹尺度差异非常大。远距离预测点的坐标变化远大于近距离预测点,导致训练时的梯度主要来自远端轨迹。为了解决这一问题,论文提出了Step-wise Normalization(SN)。该方法对每个时间步的轨迹坐标分别进行标准化处理,使不同时间步的误差处于相似的数值尺度,从而避免远端轨迹主导训练过程。具体来说,作者首先统计了NAVISM数据集中的每一条轨迹在1-T每一个时间步上动作的平均值和方差,接下来对训练VLA所使用的每一条轨迹的每一个时间步的动作执行如下标准化操作,如果第t步的轨迹动作为, 那么标准化后则表示为:
Step-wise Normliaztion效果图:统计Navtrain数据集的轨迹分布变化(来源:论文 Figure 3)
但即便如此,如果强化学习阶段仍然只关注少数策略样本,探索能力依然会受到限制。因此,论文在强化学习阶段又进一步提出了一套新的探索机制。
Adaptive Diversity-Aware Sampling(ADAS)
即便在模仿学习阶段引入了更多轨迹数据,如果强化学习阶段仍然使用传统训练方式,策略探索能力依然可能很快再次塌缩。
为了解决这一问题,论文在强化学习阶段提出了一套Diversity-Aware Reinforcement Learning机制,其中包含两个关键设计:Adaptive Diversity-Aware Sampling(ADAS)和Spanning Driving Reward(SDR)。
首先来看ADAS(Adaptive Diversity-Aware Sampling)。在传统强化学习训练中,训练数据通常是随机采样的。但在自动驾驶任务中,不同场景的探索潜力其实差异很大。有些场景无论如何采样,模型生成的轨迹几乎完全相同;而在另一些复杂场景中,策略空间则更加丰富。如果大量训练步骤都发生在那些“没有探索空间”的场景上,那么策略更新就会非常低效。
为此,论文提出了一种基于奖励分布的场景筛选机制。在每一轮训练开始前,模型会对每个场景进行多次离线采样,并统计这些轨迹的奖励分布。如果某个场景中所有轨迹的奖励都非常接近,说明该场景几乎没有策略多样性,此时该样本就会被暂时移出训练集合。从数学角度来看,ADAS 的核心目标是保证每个训练场景能够产生足够的奖励分布方差,从而避免强化学习中的advantage collapse。
为了刻画该场景的策略多样性,论文将轨迹结果简化为一个Bernoulli过程:每条轨迹要么成功(高PDMS),要么失败(低PDMS)。如果成功概率为 p,则在一个大小为G的采样组中,所有结果完全一致(全部成功或全部失败)的概率为:
如果这个概率过高,就说明该场景几乎不会产生策略差异,因此探索价值很低。
因此,ADAS只会选择满足以下条件的场景进入训练集:
这一条件保证在强化学习采样时,不同轨迹之间具有足够的策略差异。与此同时,为了避免奖励估计不稳定,论文还增加了一个统计一致性约束:
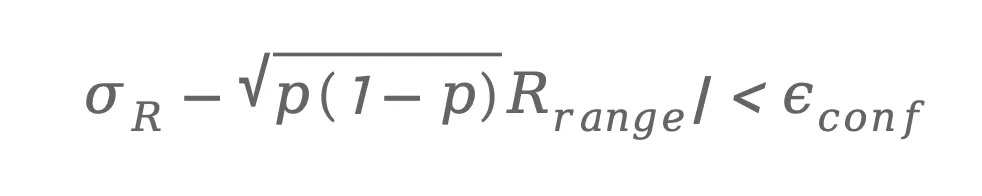
其中R(range)表示奖励范围,该约束用于确保实际奖励分布与理论Bernoulli 方差保持一致。通过这两个条件,ADAS 能够自动筛选出 具有高探索潜力的训练场景,从而维持强化学习中的奖励方差,并避免策略梯度消失问题。
那些能够产生明显奖励差异的场景会被优先用于强化学习训练。通过这种方式,训练过程会自动集中在具有更高探索价值的驾驶场景上,从而保持奖励分布的方差,并避免强化学习中的梯度消失问题。除了采样策略之外,论文还重新设计了强化学习中的奖励函数。在Navsim 基准中,自动驾驶性能通常通过 PDMS 指标计算,该指标综合考虑安全性、效率以及舒适度等多个因素。但原始奖励函数的数值差异往往比较小,这会削弱强化学习对不同策略质量的区分能力。因此论文提出Spanning Driving Reward(SDR),通过类似focal loss 的形式对奖励进行非线性变换:
这种设计会放大高质量轨迹与普通轨迹之间的差异,使奖励函数对驾驶质量更加敏感,从而增强强化学习的优化信号。通过多样性采样策略(ADAS)与跨度奖励函数(SDR)的结合,强化学习阶段能够持续保持足够的策略探索空间,并逐步优化模型的驾驶行为。
在下一节中,我们来看这些设计在实验中的实际效果。
实验结果:Curious-VLA如何释放探索能力
为了验证Curious-VLA 的有效性,论文在多个自动驾驶基准数据集上进行了系统实验,其中最主要的评估平台是 Navsim benchmark与老牌的nuScene benchmark。
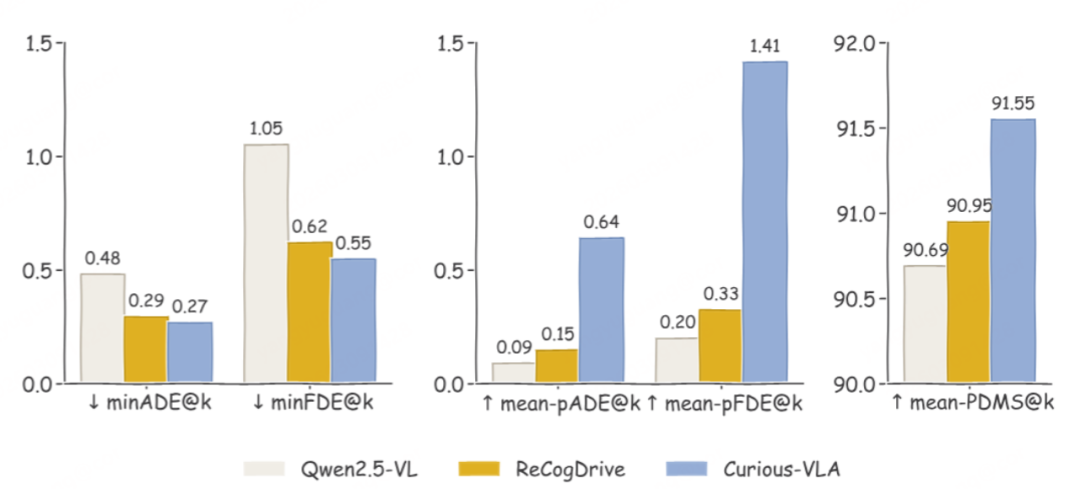
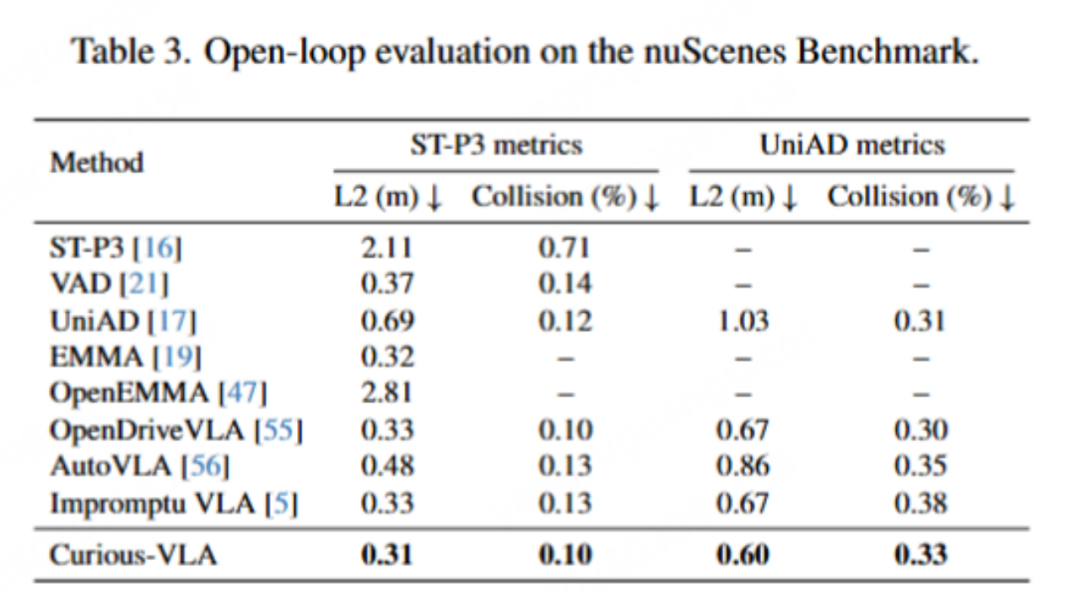
在Navsim v1 基准上,Curious-VLA 在仅使用 单前向摄像头输入的情况下取得了PDMS 90.3 的成绩,达到了当前VLA方法中的SOTA水平。相比此前使用相同基础模型的 AutoVLA(PDMS 89.1),该方法提升了 1.2 PDMS。在nuScene基准上,Curious-VLA则实现了0.33%的碰撞率,安全系数相比于业内SOTA大幅度提升13%(0.38 0.33)。
更值得注意的是,在Best-of-N 评估设置下(即从多个候选轨迹中选择最优轨迹),Curious-VLA 的 PDMS 达到了 94.8,几乎与Human Ground Truth 的 94.8持平。
这一结果说明,当模型能够生成多样化的候选策略时,它实际上已经具备了接近人类水平的驾驶决策能力。
除了整体性能指标之外,论文还重点分析了策略探索能力的变化。通过前文提出的Behavioral Diagnostics 指标可以看到,在引入 Curious-VLA 后,模型在 轨迹多样性(Diversity)和轨迹质量(Quality)两个维度上都取得了明显提升。
例如在轨迹多样性指标上,平均pairwise FDE 从原始模型的约 0.20–0.33m提升到了1.41m,说明模型确实能够生成更加分散且多样的候选轨迹。同时,在质量指标上,最佳轨迹与真实轨迹之间的误差也显著下降。
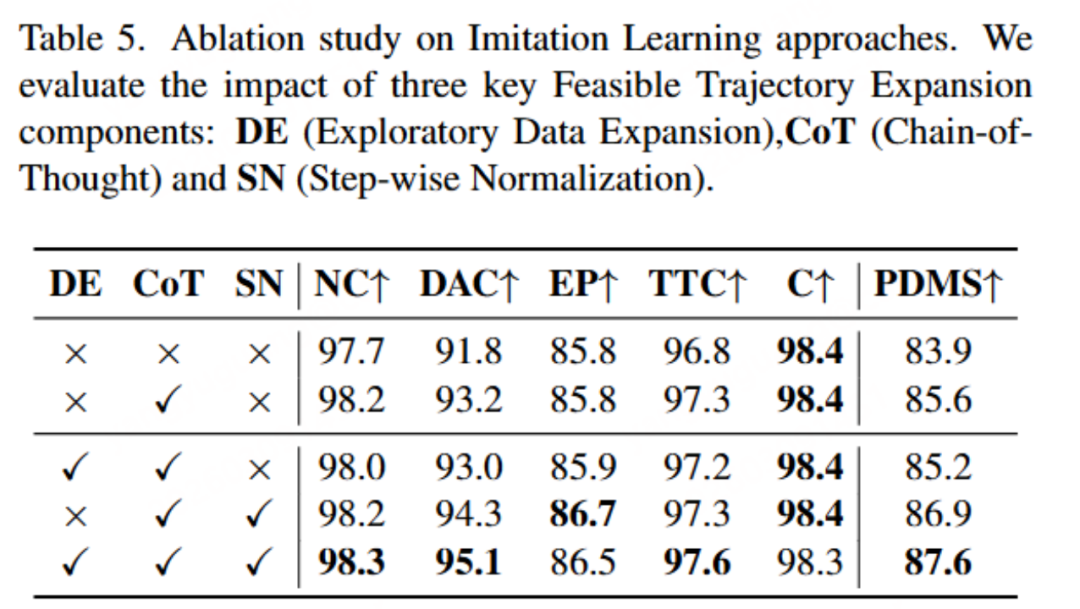
论文的消融实验进一步说明了不同模块的作用。在模仿学习阶段,仅仅增加数据扩展并不能带来明显提升;只有在加入Step-wise Normalization之后,模型才能真正有效利用这些多样化轨迹数据。而在强化学习阶段,若采用随机采样策略,训练很容易出现性能崩溃,只有ADAS 采样机制能够稳定提升模型表现。
模仿学习消融实验(来源:论文Table 5)
这些实验结果共同表明:策略探索能力确实是自动驾驶VLA性能提升的关键因素。当模型能够生成更加多样化的候选驾驶策略时,强化学习才能真正发挥作用,从而不断优化驾驶决策质量。
结语
长期以来,大多数自动驾驶VLA模型都采用多模态大模型底座外挂Diffusion Planenr模块的方式实现自动驾驶。然而,Curious-VLA则在不依赖额外Action Token、不引入Diffusion Planner等复杂规划模块的情况下,仅依赖MLLM的自回归生成能力,就能够实现VLA自动驾驶的SOTA性能。作者的独特贡献在于从SFT和RL两个方面分别消除了这条技术路径上的障碍,使得自动驾驶模型可以完全利用MLLM时代的所有红利。这对于自动驾驶模型的Scaling有莫大的意义和好处。
·论文链接:https://arxiv.org/pdf/2603.06049
·代码开源:https://github.com/Mashiroln/curious_vla.git