理想MindVLA-o1让自动驾驶更像人?
- 2026-03-23 09:19:53
编者语:后台回复“入群”,加入「智驾最前沿」微信交流群
最近理想汽车发布的MindVLA-o1引起了不少人的讨论,智驾最前沿也基于此和大家聊了聊理想和小鹏VLA的区别(相关阅读:小鹏和理想均押注 VLA,两者技术各有啥特色?)
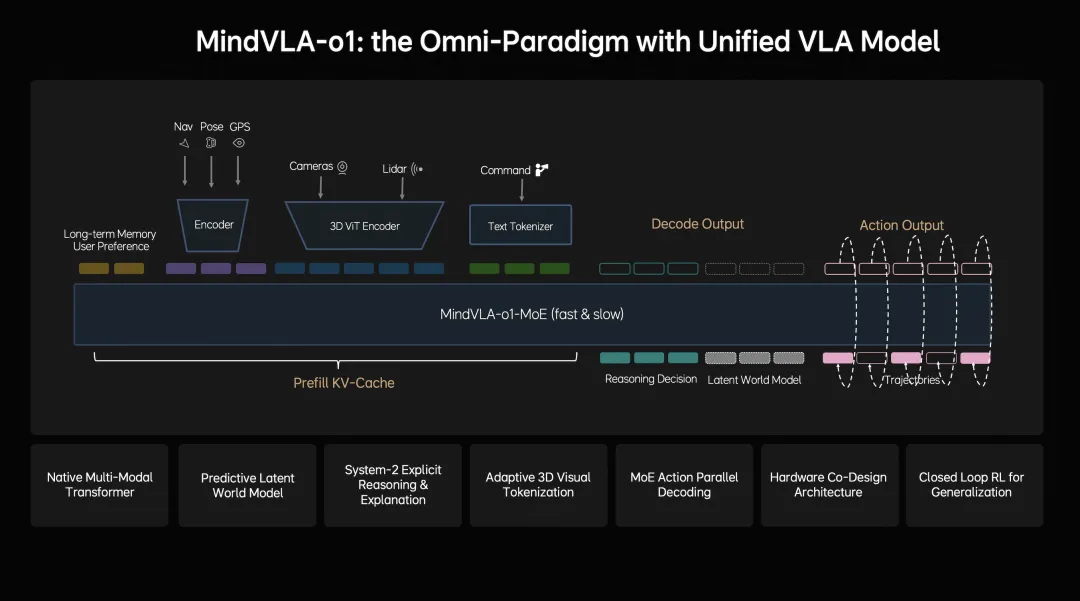
今天就详细和大家聊聊理想的MindVLA-o1到底实现了什么功能。其实从理想汽车的介绍中,MindVLA-o1的核心逻辑非常明确,即它不再把自动驾驶看作一个由感知、预测、规划组成的拼图游戏,而是试图通过一个统一的视觉-语言-动作模型,直接去模拟人类司机的驾驶逻辑。
图片源自:理想汽车
这种改变意味着车子不再是单纯地执行指令,而是在理解物理世界的基础上进行思考。
传统自动驾驶系统各功能其实是分开的,感知负责看见,规划负责决策,控制负责执行。这样做的好处是结构清楚,坏处也很明显,就是各个模块之间容易割裂,在遇到复杂场景时,信息传递不够顺,系统也很难形成统一理解。
MindVLA-o1做的就是尽量把这些能力放到一个模型里,让它不只是“看见了什么”,还要“明白这意味着什么”,并进一步判断“接下来该怎么做”。
从“看见路”到“理解路”
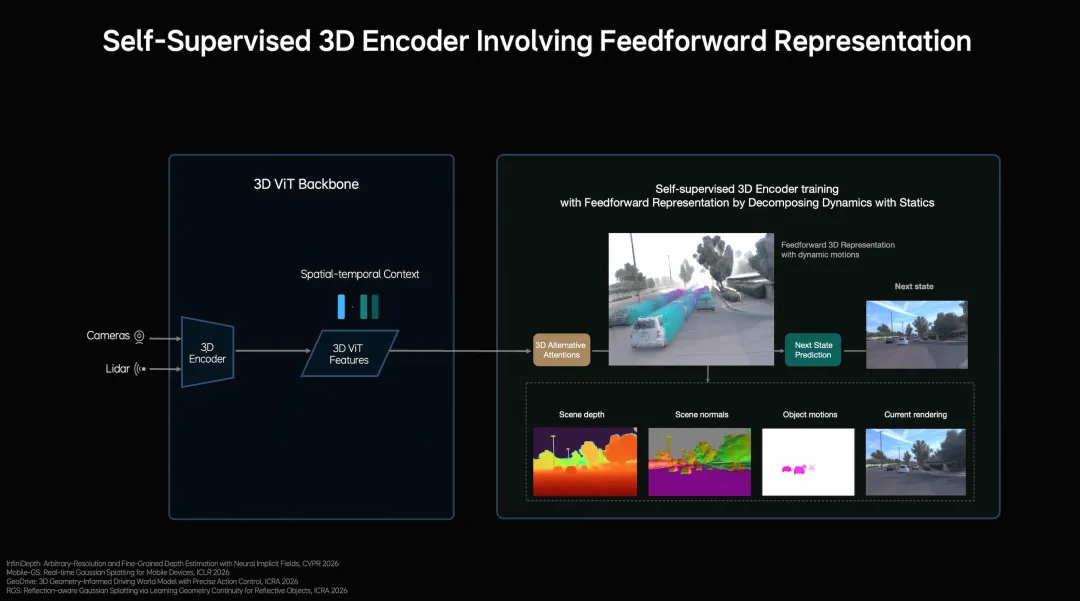
MindVLA-o1在感知层面不是单纯把图像识别做得更细,而是把三维空间理解补起来。理想采用以视觉为核心的3D ViT Encoder,同时把激光雷达点云当作三维几何提示,帮助模型更好地理解真实空间结构。这个做法的价值在于它让模型不只是识别前方有车、有行人、有障碍物,还能更稳定地把这些目标放到具体的三维关系里去理解。
图片源自:理想汽车
这一步其实很关键,因为自动驾驶真正难的地方,从来不只是“有没有看到”,而是“有没有看懂”。同一个目标,在不同距离、不同遮挡、不同道路结构下,系统对它的判断会完全不同。把语义信息和三维空间信息合到一起,模型对场景的把握才会更完整。
理想还引入了前馈式3DGS表示,把静态环境和动态物体分开建模,再通过下一帧预测作为自监督信号,让模型同时学到深度、语义和运动变化。这样做的结果,是模型对环境的理解不再停留在单帧图像,而是带上了时间维度。
智驾最前沿以为,这部分其实是让自动驾驶从二维识别往三维场景理解迈了一大步。它解决了自动驾驶一个很现实的问题,即车在路上面对的从来不是静态图片,而是连续变化的空间。
从“判断当下”到“推演下一秒”
如果说空间理解解决的是“眼前看得清”,那多模态思考解决的就是“接下来怎么想”。理想在MindVLA-o1里引入了预测式隐世界模型,让模型能够在隐空间里模拟未来的场景变化。
它不是简单地做一个下一帧预测,而是把世界模型、多模态推理和驾驶行为联合起来训练,让模型在做决策之前,先在内部把未来的可能性推演一遍。
这一点很像人类驾驶员的真实思考方式。人类驾驶员并不会只看当前这一秒的画面,而是会顺着路况、车速、交通参与者的动作,提前判断接下来可能发生什么。
MindVLA-o1想做的,就是把这种能力放进模型里。它通过海量视频预训练隐世界词元,再持续强化世界模型推演能力,最后把这些能力和驾驶动作对齐。这样一来,模型在面对复杂场景时,不只是做当下反应,还能提前形成对未来几秒的判断。

图片源自:网络
这也是智驾最前沿认为MindVLA-o1最有价值的地方之一。很多大模型讲“会思考”,但在自动驾驶里,真正有用的思考不是抽象推理,而是对未来场景变化的预判。
车速、距离、轨迹、相对位置,这些东西都要求模型对时间有稳定理解。只有把这种能力做进了系统里,才让“想得更深”不只是口号。
从“输出动作”到“稳定开车”
自动驾驶最后要实现的一定要落到动作上,而动作生成往往最容易暴露系统短板。理想在这里做的是统一行为生成。
MindVLA-o1使用VLA-MoE架构,并加入Action Expert,从3D场景特征、导航目标和驾驶指令中提取信息,再结合前面的多模态思考,直接生成高精度驾驶轨迹。
它不是把几个模块拼起来再凑一个结果,而是尽量让“理解”和“动作”之间少一些中间损耗。

图片源自:网络
在这个方面理想还有两个很重要的设计。一个是并行解码,也就是一次性生成所有轨迹点,提升实时性。另一个是离散扩散,用多轮迭代的方式去优化轨迹,让轨迹更连续、更稳定,也更符合车辆动力学约束。
这个部分听起来不像感知和推理那么“高大上”,但它恰恰决定了车开起来稳不稳。模型能不能在复杂场景下给出平顺、可执行、可控的动作,最终还是看这一层。
智驾最前沿觉得,MindVLA-o1在动作生成上的意义不在于“更会开车”,而在于它开始像一个真正的驾驶系统,而不是一个只会给答案的模型。
自动驾驶最怕的其实不是看不见,而是看见了却做出不稳定、不连贯的动作。统一行为生成解决的,正是这个问题。

MindVLA-o1是一套会进化的系统?
MindVLA-o1不只是一个静态模型,它背后还有一整套闭环强化学习和软硬件协同设计。理想把传统逐步优化式重建,升级成前馈式场景重建,让系统能更快生成大规模、高保真的驾驶场景,再结合世界模拟器持续训练和优化。
这个思路的核心,不是靠一次训练定终局,而是让模型在仿真和真实世界之间不断循环,持续修正自己。
与此同时,理想还把模型设计和硬件约束放到一起考虑。通过Roofline模型分析计算能力和内存带宽限制,再评估近2000种架构配置,最终找出精度和推理延迟之间的平衡点。
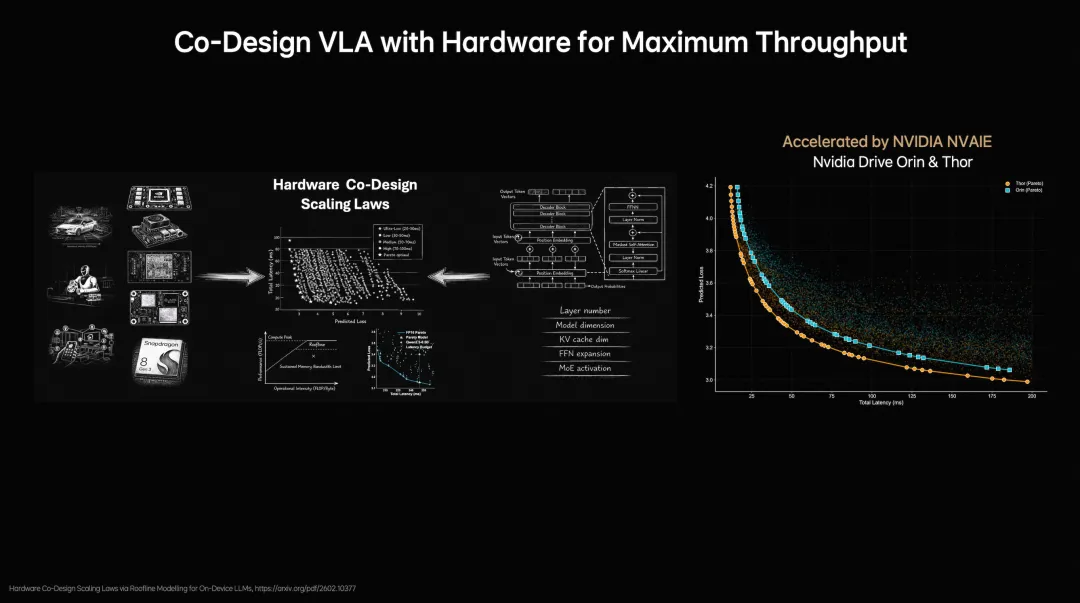
图片源自:理想汽车
这个动作很重要。因为自动驾驶不是实验室里的模型比赛,模型再强,放不上车、跑不动、调不快,都没有意义。MindVLA-o1能被认真讨论,不只是因为它提出了新结构,更因为它把“怎么上车”这件事摆到了同等重要的位置。
从这个角度看,MindVLA-o1真正实现的,不是单点突破,而是一整套面向物理世界智能的能力拼接起来了。
看得更远,是三维空间理解;想得更深,是多模态思考;行得更稳,是统一行为生成;进化更快,是闭环强化学习;部署更高效,是软硬件协同。这五件事合在一起,才构成了它的完整价值。
结语
如果只把MindVLA-o1看成一套自动驾驶新模型,理解会太窄。理想真正想表达的,是自动驾驶正在从“功能系统”走向“物理世界智能系统”。它现在当然还主要服务于车,但它的结构已经不再局限于车。视觉、语言、行动统一之后,模型就有了扩展到机器人等物理系统的可能。
-- END --

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- MindDriver:为自动驾驶引入渐进式多模态推理
- 谁说燃油车难超车?这几款自主轿车,把卡罗拉甩在身后!
- 特斯拉4s店,轿车裸价3.5万起步,3.5~
- 大型轿车市场,国产汽车正在崛起,但还不足以形成类似中小型汽车市场的替代
- 炸了!1月轿车销量前十仅1台新能源,油车全面反攻,比亚迪竟没影!
- 2025轿车销冠榜:中国品牌压过BBA?
- 阿维塔旗舰SUV前瞻:09或将登场,双动力+华为智驾,技术实力全解析
- 这台中大型SUV真香!只售15.19W,车长5002mm仅4.7L油耗,还带6座
- 35-40万硬派SUV闭眼冲!提坦克500 Hi4-Z跑3万公里,落地价+真实用车全曝光
- 贵阳市云岩区,招聘自动驾驶标注工程师等岗位,大专起报!
