英伟达的自动驾驶VLA: Alpamayo 1.5
- 2026-03-24 17:13:18
2025年英伟达GTC大会上,吴新宙讲解了英伟达的L3级自动驾驶系统NDAS(即NVIDIA DRIVE AV Solution),代号Alpamayo。2026年英伟达GTC大会上,英伟达则宣布了Alpamayo 1.5版VLA,有5亿和100亿参数两个版本。
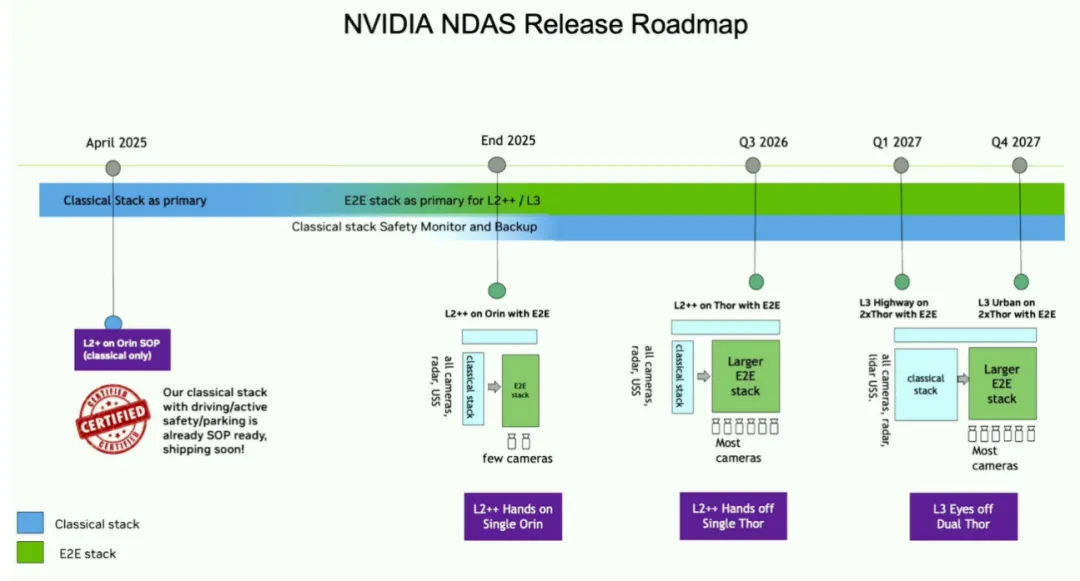
图片来源:吴新宙GTC2025大会
第一版NDAS于2025年4月推出,2027年1季度将推出双Thor高速公路版L3,2027年底推出双Thor城郊Urban版L3。从上图也能看出即便配备了双Thor,英伟达依然推荐的是经典传统算法加端到端算法,即快慢双系统,快系统是经典传统算法,慢系统自然就是端到端算法,英伟达认为端到端至少要做到10Hz才算合格。
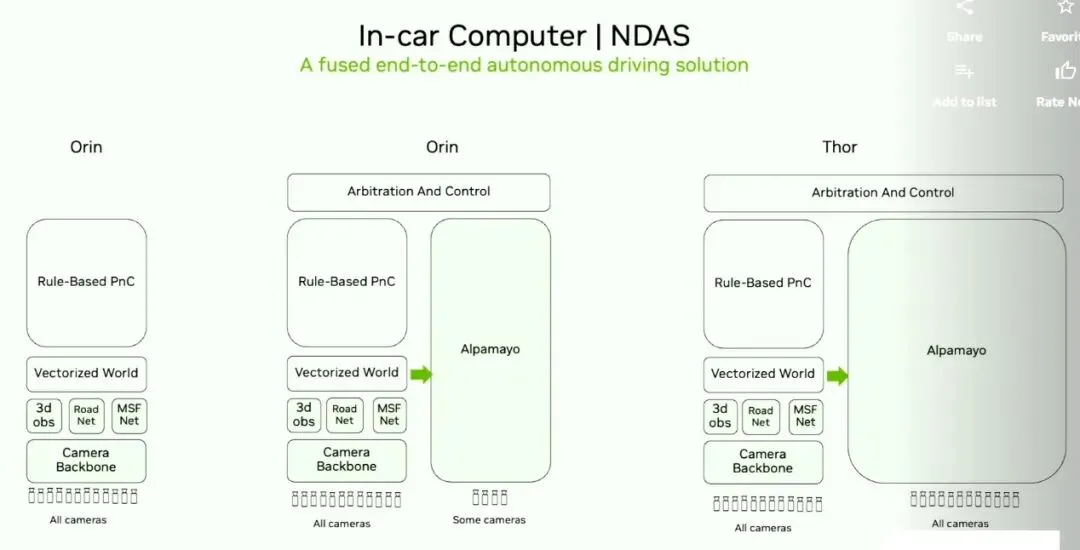
图片来源:吴新宙GTC2025大会
英伟达也对经典传统算法做了解释,即BEV提取图像特征,3D重建,矢量化全局表示,基于规则的规划和控制。
实际Alpamayo 是一个系统,包括物理AI数据集,VLA大模型和AlpaSim专为评估端到端模型设计的开源端到端仿真框架。数据集有1700小时,覆盖欧美25个国家2500个以上的城市,20秒的视频片段有306152个,激光雷达(1个,128线,360度旋转)片段则有298326个,毫米波雷达(10个)片段有160761个,整个数据集有133TB。
我们重点来看VLA大模型。英伟达2026年1月发布了论文Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail。
Alpamayo-R1架构
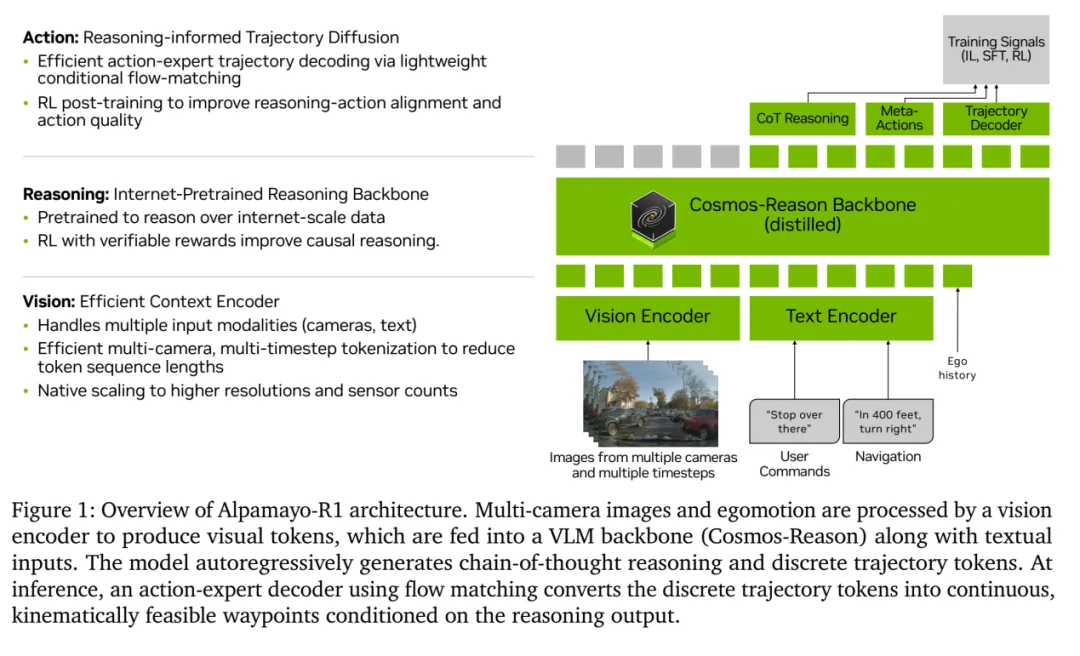
图片来源:英伟达
VLA分三个部分,第一部分是感知与自身状态输入,将物理世界的原始信号(视频、车身状态)压缩成 VLM 能“理解”的 Token。
视觉编码 (Vision Encoding),Backbone: 外挂了 SigLIP (Sigmoid Loss for Language Image Pre-training)。相比于早期的 CLIP,SigLIP 在多图处理上的边缘对齐能力更强,参数量大约是4亿。
状态编码 (Ego-Status Encoding),将车辆自身的速度、加速度、方向盘转角等数值,通过 MLP 映射到与 VLM相同的 Embedding(三角函数运算) 维度,作为 State Tokens 拼接到输入序列中。
文本编码(Text Encoder),包含用户指令(User Commands)与高层导航指令(Navigation)。虽然看起来很像是一个感知模块,但实际上不是,这是 VLM的Backbone的一部分。
Cosmos-Reason1概览
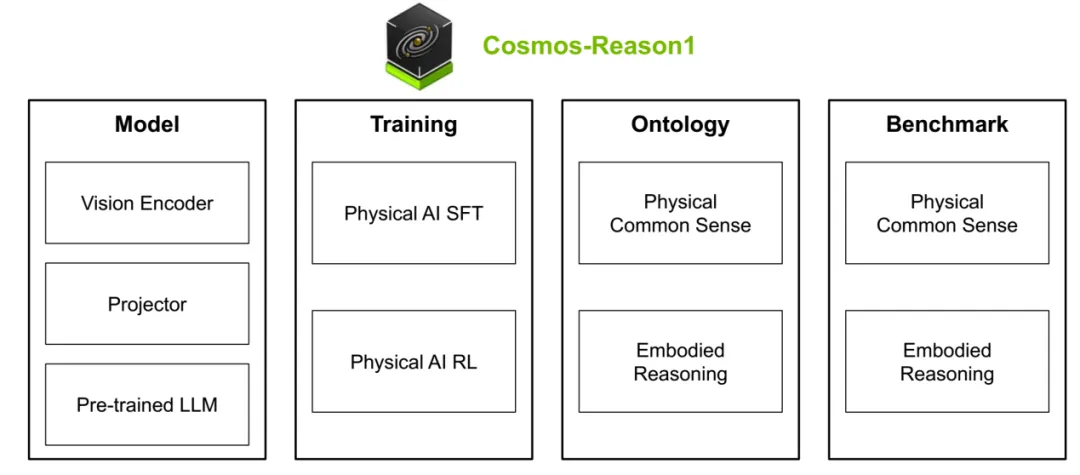
图片来源:英伟达
第二部分是推理层,即名为Cosmos-Reason的VLM,这个VLM有70亿和560亿参数两个版本,其中70亿版本采用InternViT-676M-V2.5视觉编码器,阿里千问Qwen2.5-VL-7B为预训练模型,560亿参数版本采用InternViT-300M-V2.5视觉编码器,Nemotron-H作为LLM骨干。在Qwen2.5-VL-7B基础上大规模再训练post-training,在3.7M个视觉问答 (VQA) 样本上进行了再训练 ,以培养物理常识和具身推理能力,预训练数据中包含 24.7K 个专门针对驾驶场景的精选视频 VQA 样本。这些样本不仅包含场景描述和驾驶难度标注,还包含了通过 DeepSeek-R1 蒸馏出的、用于预测下一步行动的推理轨迹 (reasoning traces)。
然后是针对自动驾驶领域,即特定领域的监督微调 (Domain-Specific SFT),跨域知识迁移:整理了涵盖多个“物理 AI”领域的补充数据集,包括自动驾驶、机器人、医疗保健、智慧城市、制造、零售和物流。这种广泛的训练旨在让模型获得通用的物理常识,从而能更好地迁移到驾驶场景中。驾驶数据增强:专门为自动驾驶增加了 100K 个新样本。这些样本包含对环境关键对象(Critical Objects)的标注以及对下一步行动的推理。在自动驾驶VLM的LingoQA测试集上得分66.2。

这里的Ours即Cosmos-Reason VLM。
70亿版本采用纯Transformer架构,560亿参数版本使用混合Mamba-MLP-Transformer架构。Transformer架构问世以来,已经彻底改变了语言建模领域,成为构建基础模型的事实标准。然而,它的自注意力机制的时间复杂度与上下文长度成二次关系。相比之下,Mamba架构引入了线性时间的序列建模方法,并采用选择性的状态空间模型,使其在处理长序列时更为高效。但Mamba的选择性状态空间可能不足以捕捉长序列中的每一个细节。为解决这一问题,在Mamba中嵌入了一部分Transformer层以进行长上下文建模,从而产生了混合的Mamba-MLP-Transformer架构。
Cosmos-Reason VLM两个版本配置
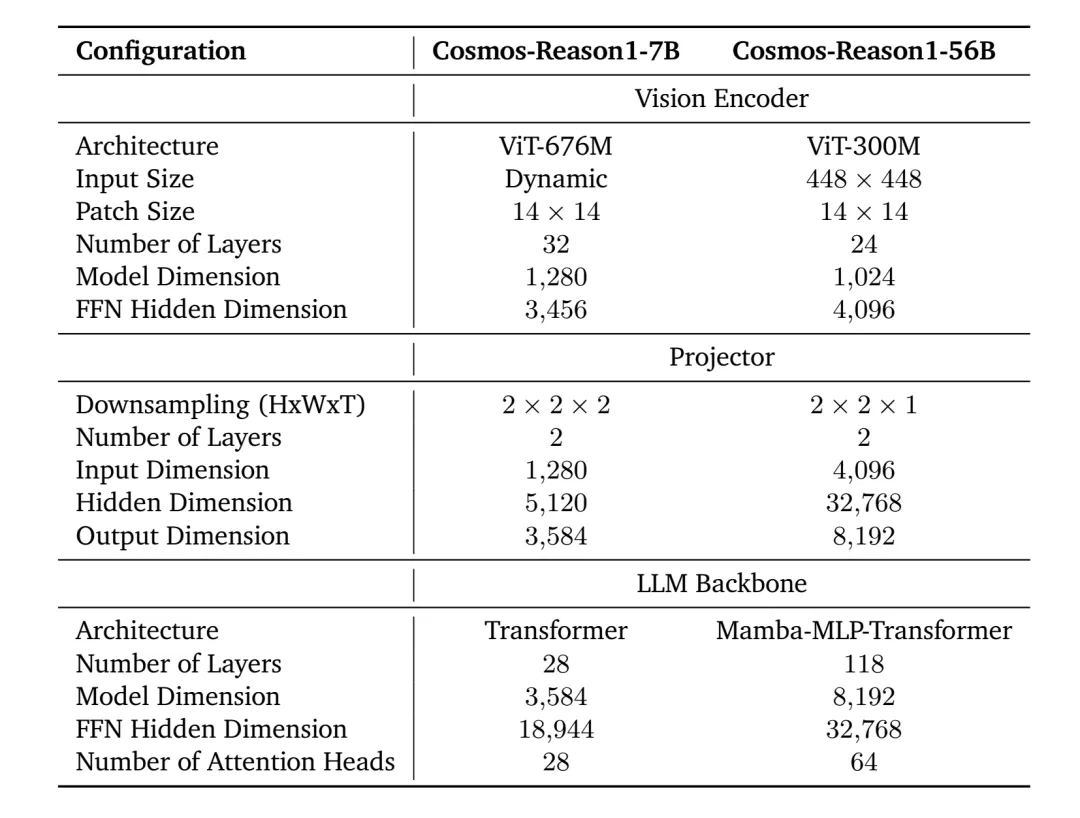
图片来源:英伟达
第三层是执行层,采用 “离散决策 + 连续修正” 的双重表征设计,解决 VLM无法输出平滑连续轨迹的问题,训练过程是离散分支 + 连续分支。
离散分支 (Discrete Action Head),作用是粗粒度规划 (Coarse-level Planning)。将连续的轨迹空间离散化为 1024 个 Cluster (类似于 VQ-VAE 的 Codebook)。VLM 像生成文本一样,自回归地预测出代表轨迹形状的 Token 序列。目的是让 Transformer 能够利用其擅长的概率预测能力,决定“大概怎么走”(比如:左转、急刹、缓行)流匹配动作专家 (Flow Matching Action Expert),作用: 细粒度精修 (Fine-grained Refinement)。机制: Flow Matching (流匹配)。这就好比是一个轻量级的 Diffusion Model,但速度更快。Input: 它接收两个输入:从标准高斯分布采样的噪声x0x_0x0,Conditioning: 来自 VLM 输出的离散 Action Token 的 Embedding(即 VLM 的“意图”)。Process: 它通过求解常微分方程(ODE),将噪声“流”向目标轨迹分布。Output: 输出符合 单车动力学 (Unicycle Dynamics) 的连续轨迹点 (x,y,h)(x, y, h)(x,y,h) (位置 + 航向角)。
传统的 Diffusion 生成步骤太多(50-100步),推理太慢。Flow Matching 使用 Straight Vector Fields (直线向量场),可以在极少的步数内(甚至 1 步)生成高质量轨迹,完美契合车载端的实时性要求。
Alpamayo-R1训练管线
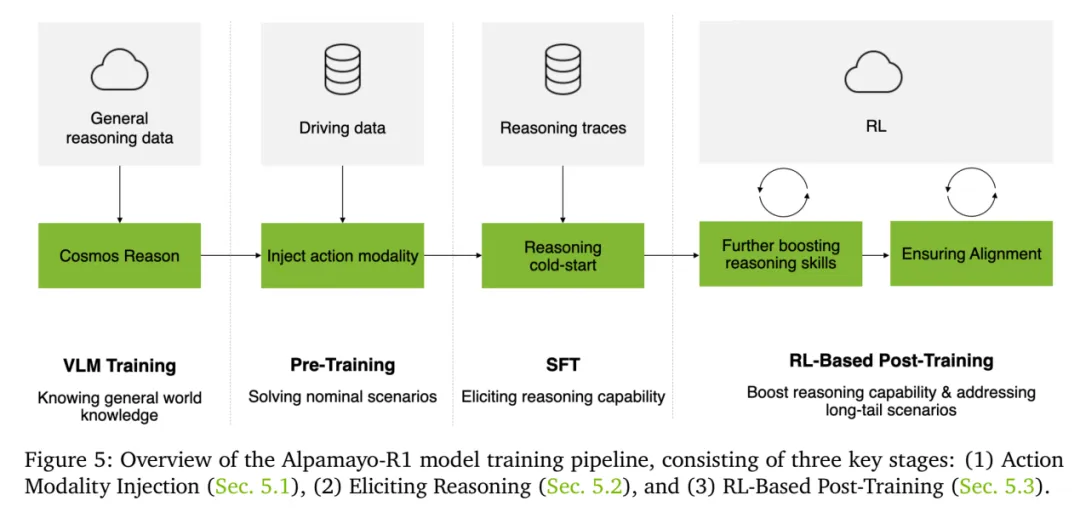
图片来源:英伟达
Alpamayo-R1训练管线,第一部分是动作模态注入。在训练过程中,通过离散token 将动作模态注入到 VLM 中,并使用交叉熵损失函数,基于定义的训练 token 序列来训练 VLM。根据基于控制的表示,每条轨迹由 64 个路径点组成,每个路径点有两个量化值(加速度 𝑎_𝑖 和曲率 𝜅_𝑖),因此每条轨迹共有 128 个离散 tokens。这些 tokens 使用一组专门用于动作表示的特殊 tokens 进行编码。
第二部分是SFT,主要是为了引发推理能力,为此英伟达构建了一个名为Chain of Causation (CoC)数据集,并开发了一种人工和电脑自动化的混合标注,其中人工标注占10%,自动化标注占90%。
第三部分是强化学习,主要是应对长尾场景,也为了增加泛化能力。
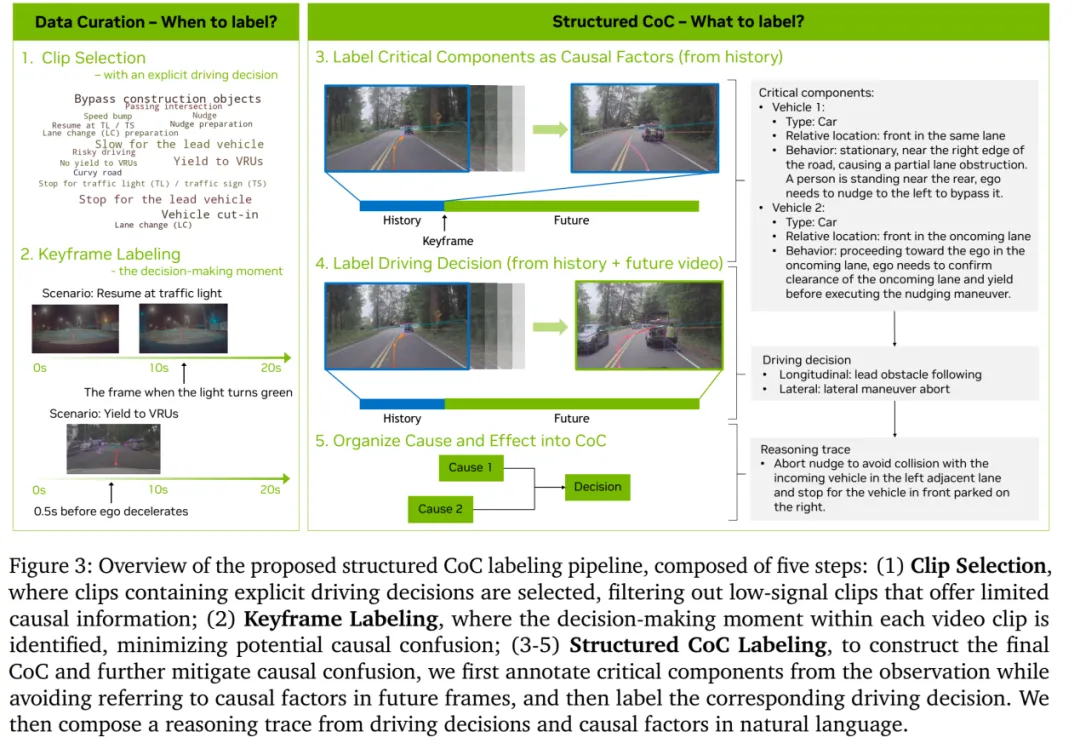
图片来源:英伟达
数据集的构建和标注流程有5步,首先是挑选出高价值片段clip,并非所有路段都值得标注。系统只挑选包含显式驾驶决策的片段(如绕行施工、减速让行、红绿灯起步)才做标注。平直空旷道路的数据会被过滤放弃,因为含金量太低。然后是挑选关键帧,对于“绿灯起步”,关键帧是灯变绿的瞬间;对于“让行VRU(弱势交通参与者)”,关键帧是减速动作发生前的 0.5秒。让模型学习在“动作发生前”进行预判,而不是事后诸葛亮。
再后是提取关键要素Label Critical Components,只人工标注导致当前决策的物体,忽略无关背景。人工标注分两步走。第一步只能看历史视频标组件(0~2s,防止利用未来信息),第二步看完整视频标决策(0~8s)。再后是将复杂的驾驶行为拆解为结构化的纵向 + 横向 meta(原子)决策并标注。将视频、轨迹和meta动作喂给GPT-5,90%的片段让GPT-5做自动标注。最后构建因果链。
CoC的GPT-5做的自动标注
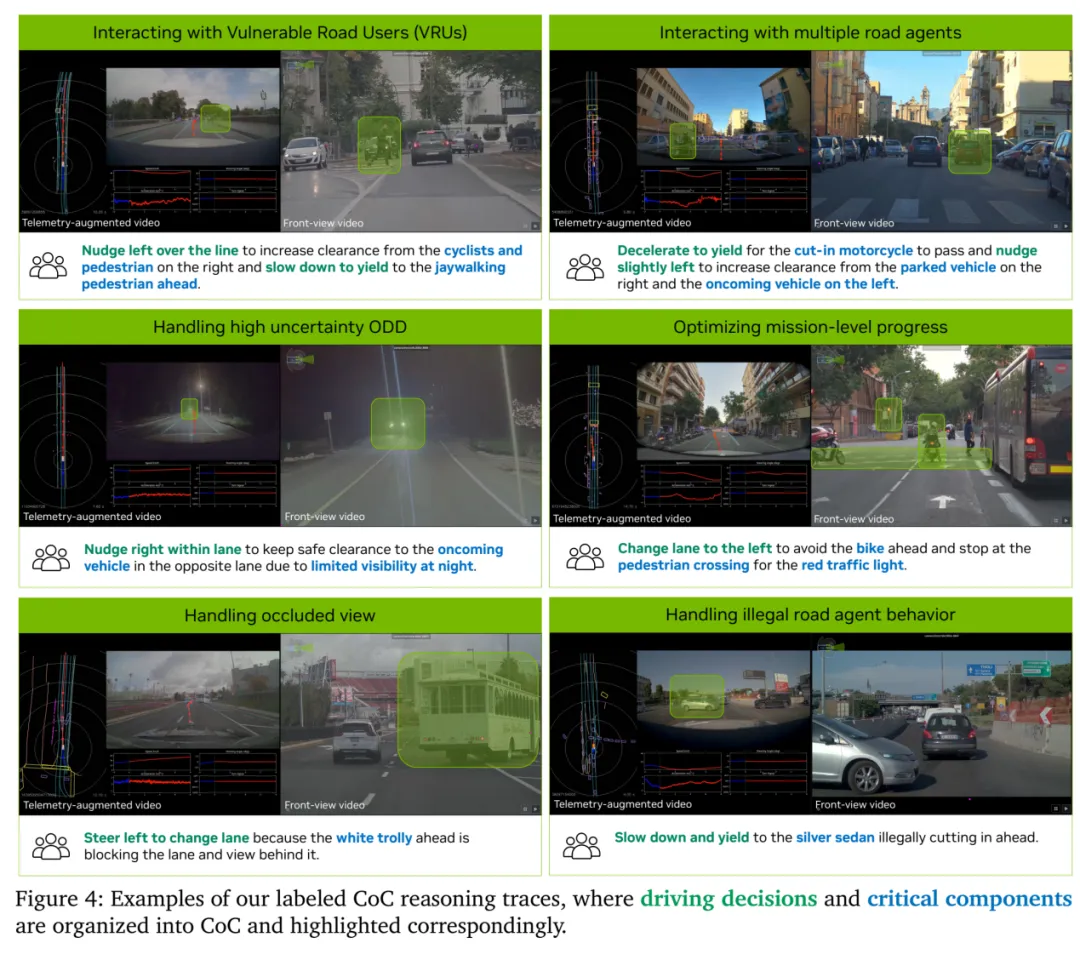
图片来源:英伟达

来源:英伟达
英伟达在实车和仿真平台AlpaSim做了测试,由于很少有人使用英伟达仿真平台AlpaSim,所以没有办法横向对比。上表就是测试数据,开环测试意义不大,关键是闭环测试,我们也能看出100亿参数版本比5亿参数版本的性能还是要高很多,基本上是一倍的差距。

来源:英伟达
英伟达基于RTX6000 Pro Blackwell计算平台部署了Alpamayo-R1,英伟达未点明VLA参数,应该是100亿参数版本,因为5亿参数版本耗时应该比这个低很多。视觉编码耗时都是3.43毫秒,预填充耗时16.54毫秒,推理解码耗时70毫秒,流匹配轨迹解码耗时8.75毫秒,总计99毫秒,英伟达认为这个耗时可算实时性能。不过上面的表有一点令人疑惑,Alpamayo-R1没有使用自回归轨迹解码,而是扩散,应该与扩散做对比。
RTX6000 Pro Blackwell有服务器版本和工作站版本,工作站版本的RT核心性能略高于服务器版本,除此外AI性能都完全一致,即FP4精度下稀疏算力达4000TOPS,基本上是Thor-X的两倍性能,是Thor-U的三倍差不多。
不过存储带宽远高于Thor-X,RTX6000 Pro Blackwell采用96GB的GDDR7,存储位宽高达512bits,存储带宽高达1597GB/s,几乎是Thor-X的六倍,加上RTX6000 Pro Blackwell是独立CPU+独立GPU结构,CPU常见的是Intel Xeon W5-2455X,这样的设计比Thor-X这种SoC效率要高出数倍,如果用Thor-X部署100亿版本的Alpamayo-R1,估计一次推理耗时至少是600-1000毫秒,如果是Thor-U的话,估计是1000-1500毫秒,如果是5亿版本,估计Thor-X还能做到100毫秒。
快慢双系统应该是最佳选择,但这样显然无法在宣传口径上取得制高点,VLA前路漫漫,还有很长的路要走。
免责说明:本文观点和数据仅供参考,和实际情况可能存在偏差。本文不构成投资建议,文中所有观点、数据仅代表笔者立场,不具有任何指导、投资和决策意见。
更多报告
| AI机器人 | ||
AI机器人 | ||
| 云端和AI | ||
| 车云 | ||
| 动力层 | ||
| 动力 | 混合动力报告 | |
| 800-1000V高压平台 | 电驱动与动力域研究 | |
热管理 | ||
其他 |
| 电子电气架构层 | ||
| E/E架构框架 | E/E架构 | 汽车电子代工 |
| 48V低压供电网络 | ||
| 智驾域 | 自动驾驶SoC | |
| 座舱域 | 座舱域控 | |
| 车控域 | 车身(区)域控研究 | |
| 通信/网络域 | ||
| 跨域融合 | ||
| 其他芯片 | ||
| 车载存储芯片 |
| 智舱系统集成和应用层 | ||
智能座舱应用框架 | 座舱设计趋势 | |
自动驾驶算法和系统 |
| OS和支撑层 | ||
| SDV框架 | SDV:软件定义汽车 | |
信息安全/功能安全 |
| 其他宏观 | ||
| 车型平台 | 车企模块化平台 | |
| 政策、标准、准入 | 智能辅助驾驶法规和汽车出海 |
「AI与机器人月报」

「联系方式」
手机号同微信号

产业研究部丨赵先生 18702148304
推广传播部|杜先生 13910162318
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- SUV和轿车哪个开着更舒服?其实很多人都搞错了
- 大获全胜!2月大型SUV终端销量排名:国产包揽前11名,库里南第24
- 20万级合资新能源SUV:EZ-60与NX8各有章法
- 15万内入手的新能源SUV,这4款无短板!
- 预算12万闭眼冲!这台SUV越级体验拉满
- 全新奥迪Q5L焕新上市!豪华SUV的「全能王者」来了!
- 当家用SUV遇到智能化:EZ-60与NX8各有妙手
- 合资新能源家用 SUV 双选对比 马自达 EZ-60 与日产 NX8 各展所长
- 20 万级合资新能源 SUV 新对决 马自达 EZ-60 与日产 NX8 同台诠释家用新定义
- 聚焦 20 万级家用 SUV 市场 马自达 EZ-60 与日产 NX8 各凭实力圈粉
