在自动驾驶技术飞速发展的今天,语言模型凭借海量文本预训练知识,本应成为驾驶场景分析的“利器”——毕竟交通规则、驾驶行为逻辑都早已沉淀在文本中。但现实却是,现有数据集要么聚焦“近距离空间交互”(比如车辆碰撞、保持车距),要么规模太小,完全无法支撑非邻近性、基于交通规则/人类意图的交互推理,这也让自动驾驶的安全决策始终存在短板。近期,一篇发表于ICML 2025的论文《WOMD-Reasoning: A Large-Scale Dataset for Interaction Reasoning in Driving》给出了破局思路:构建目前最大的多模态驾驶问答数据集WOMD-Reasoning,搭配专门设计的Motion-LLaVA模型,让语言模型真正“读懂”驾驶场景中的复杂交互!
我整理了“驾驶场景+交互推理”方向10篇相关论文(包括本章1篇论文),帮助大家了解学习“驾驶场景+交互推理”方向,选题,挖创新点。
论文信息
题目:WOMD-Reasoning: A Large-Scale Dataset for Interaction Reasoning in Driving
面向驾驶交互推理的大规模数据集WOMD-Reasoning
作者:Yiheng Li, Cunxin Fan, Chongjian Ge, Seth Z. Zhao, Chenran Li, Chenfeng Xu, Huaxiu Yao, Masayoshi Tomizuka, Bolei Zhou, Chen Tang, Mingyu Ding, Wei Zhan
源码:https://github.com/yhli123/WOMD-Reasoning
一、核心痛点:现有数据集的两大致命短板
此前的驾驶语言数据集,始终绕不开两个问题:
- 交互覆盖太窄:几乎只关注“空间邻近性交互”(比如BDD-X聚焦空间阻挡、DriveLM仅解释“保持安全距离”),完全忽略了交通规则(如红绿灯、停车标志)、人类意图(如超车、让行)引发的非邻近交互——而这恰恰是自动驾驶安全决策的核心。
- 规模太小:数据量不足以支撑多模态微调,无法覆盖场景描述、运动预测、轨迹规划等全栈任务。
针对这些问题,WOMD-Reasoning的出现,直接填补了这两大空白。
二、WOMD-Reasoning:300万问答对的驾驶交互“知识库”
1. 数据集核心创新:不止“大”,更在“准”和“全”
WOMD-Reasoning基于Waymo开放运动数据集(WOMD)构建,核心亮点直击行业痛点:
- 规模天花板:包含300万个真实世界驾驶场景问答对,是现有同类数据集的6-113倍;其中仅“交互特定问答对”就有40.9万个,专门聚焦交通规则/人类意图交互。
- 覆盖维度全:问答分为“事实性内容”和“推理性内容”两大板块:
- 事实性内容:地图环境(交叉口、停车标志、车道数)、自车/周边智能体运动状态(速度、加速度、位置);
- 推理性内容:智能体交互分析(谁该让行、为何交互)、自车意图预测(基于交互的轨迹规划)。
- 自动化生成+高准确率:作者设计了“规则转换+ChatGPT-4提示”的自动化流程——先通过规则程序将运动数据转成语言描述,再用GPT-4生成交互推理问答,整体准确率约90%,大幅降低人工标注成本(仅GPT-4调用成本约12750美元)。
2. 数据集里的“典型交互案例”:读懂非邻近交互的价值
很多关键交互并非“近距离触发”,而是由交通规则主导,这正是WOMD-Reasoning的核心价值所在:
- 交通规则交互示例(图1):
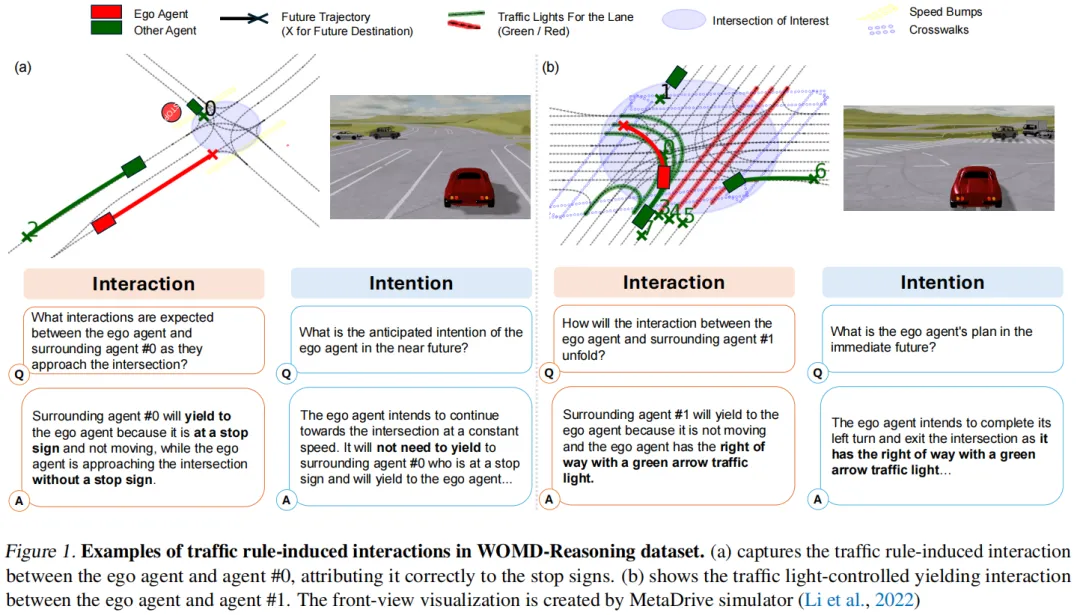 左图中,智能体#0虽距离自车较远,但受停车标志约束必须让行;右图中,智能体#1需让行给拥有左转绿灯优先通行权的自车——这类交互在传统数据集中完全被忽视,却是自动驾驶安全的关键。
左图中,智能体#0虽距离自车较远,但受停车标志约束必须让行;右图中,智能体#1需让行给拥有左转绿灯优先通行权的自车——这类交互在传统数据集中完全被忽视,却是自动驾驶安全的关键。 - 人类意图交互示例(图3):
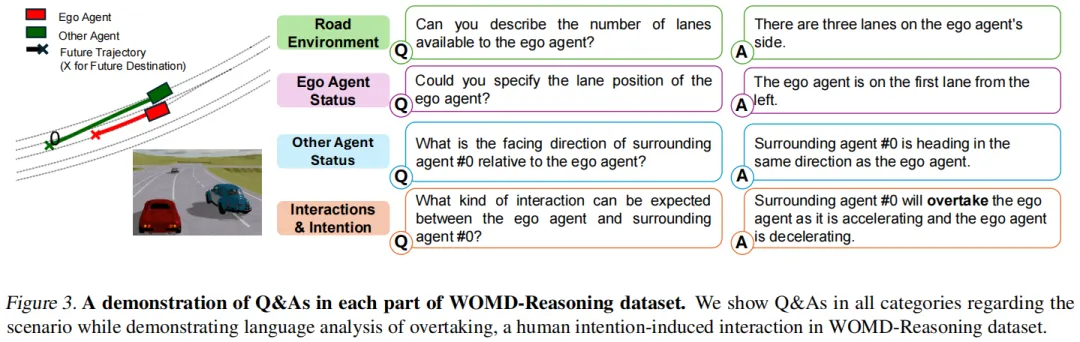 以“超车”为例,数据集能精准捕捉驾驶员的意图逻辑,为模型理解人类驾驶行为提供了细粒度标注。
以“超车”为例,数据集能精准捕捉驾驶员的意图逻辑,为模型理解人类驾驶行为提供了细粒度标注。
3. 视觉扩展:补上“图像/视频”维度
原始WOMD缺少相机数据,作者通过ScenarioNet和MetaDrive模拟器,为每个场景生成了鸟瞰图、自车视角视频(90帧、10Hz,含10帧历史+80帧未来轨迹),让数据集能支撑视觉-语言多模态任务。
三、Motion-LLaVA:让模型“吃透”驾驶交互的核心方法
为验证数据集价值,作者基于LLaVA打造了Motion-LLaVA多模态模型,专门适配驾驶场景的运动数据输入,核心设计如下:
1. 方法总体架构(图4):
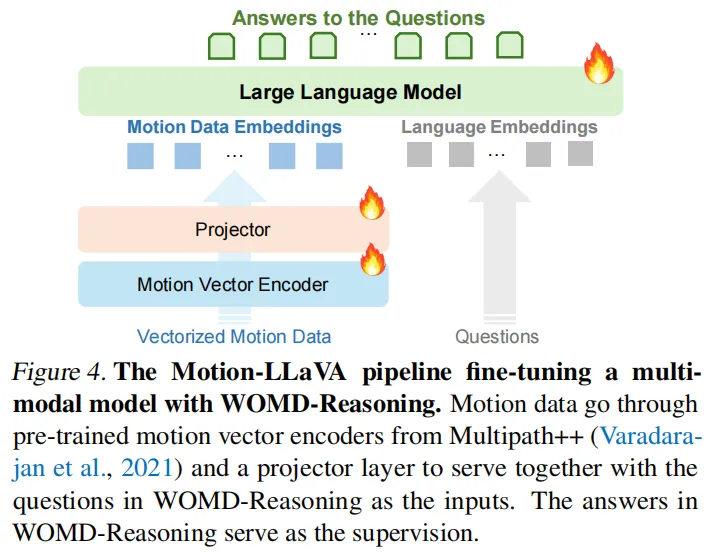 Motion-LLaVA总体架构
Motion-LLaVA总体架构- 输入层:替换LLaVA的视觉编码器,改用MultiPath++运动预测模型的编码器处理运动数据;
- 训练策略:解冻所有组件,混合驾驶无关问题避免“灾难性遗忘”;
- 推理策略:采用“思维链”——先回答事实性问题(地图、运动状态),再汇总结果作为上下文,回答交互/意图推理问题,大幅减少模型“幻觉”。
2. 训练成本:
在2块NVIDIA A6000 GPU上,训练1个epoch仅需1天,兼顾效率与效果。
四、效果验证:从交互预测到轨迹规划,全维度突破
1. 交互预测:精准捕捉交通规则交互(图5)
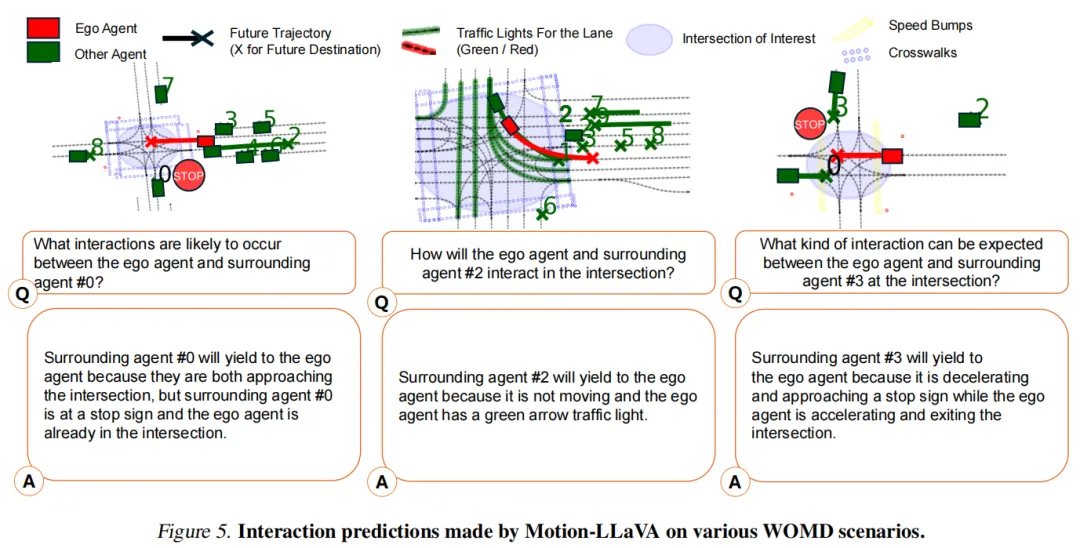 Motion-LLaVA能准确预测未见过的真实场景中,由交通灯、停车标志等规则引发的交互,比如“自车在绿灯时直行,右侧车辆需让行”,彻底摆脱了传统模型“只看距离不看规则”的局限。
Motion-LLaVA能准确预测未见过的真实场景中,由交通灯、停车标志等规则引发的交互,比如“自车在绿灯时直行,右侧车辆需让行”,彻底摆脱了传统模型“只看距离不看规则”的局限。
2. 符合交通规则的规划(图6)
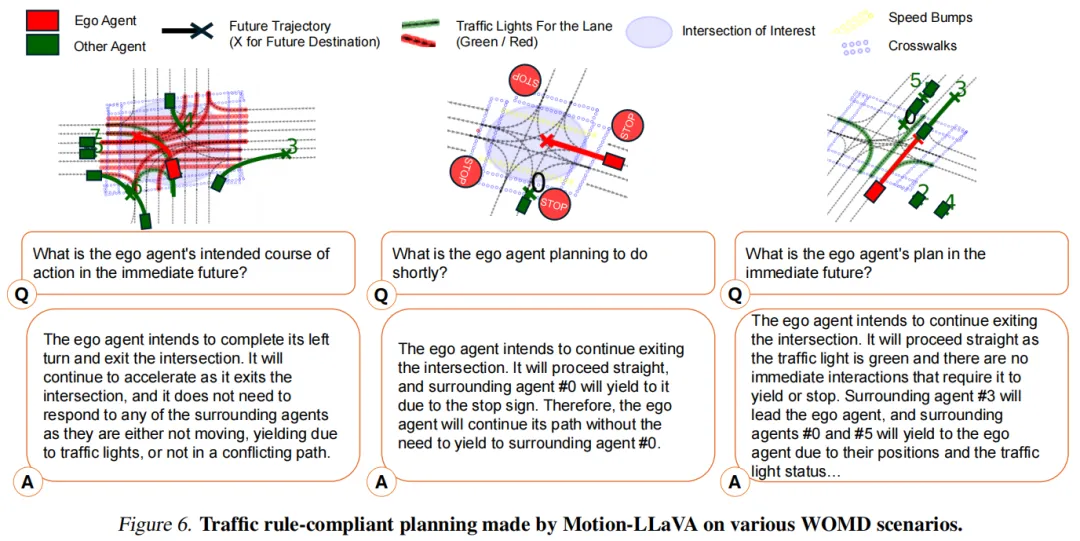 基于交互分析,模型能为自车生成符合优先通行权的轨迹规划,比如“左转时优先于对向直行车辆”,直接落地到自动驾驶的规划任务中。
基于交互分析,模型能为自车生成符合优先通行权的轨迹规划,比如“左转时优先于对向直行车辆”,直接落地到自动驾驶的规划任务中。
3. 定量评估:指标全面领先(表4)
在BLEU-4、ROUGE-L、GPT Score等语言指标上,Motion-LLaVA远超未微调的LLaVA,甚至优于“鸟瞰图输入”的微调版本——原因是运动数据编码避免了视觉转换的信息丢失。
4. 下游任务赋能:轨迹预测效果提升(表6)
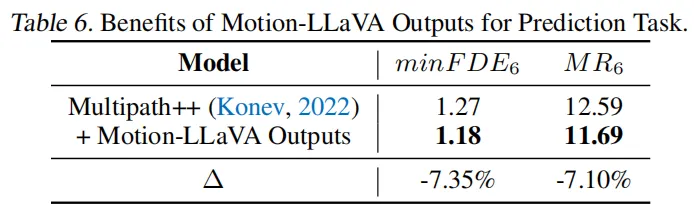 将Motion-LLaVA输出的交互语言嵌入引入Multipath++轨迹预测模型后,预测指标显著提升,同时增强了模型的可解释性。
将Motion-LLaVA输出的交互语言嵌入引入Multipath++轨迹预测模型后,预测指标显著提升,同时增强了模型的可解释性。
五、总结:重新定义驾驶语言数据集的“天花板”
WOMD-Reasoning的核心价值,不仅在于“300万问答对”的规模,更在于首次系统性覆盖了“交通规则+人类意图”引发的非邻近交互,填补了行业空白;而Motion-LLaVA则验证了这类数据集的落地价值——让语言模型真正从“文本知识”走向“驾驶场景理解”。
对于自动驾驶领域而言,这一工作不仅提供了高质量的数据集,更给出了“语言模型+驾驶交互”的完整落地思路:从数据生成、多模态微调,到交互预测、轨迹规划,全链路打通了语言模型在自动驾驶中的应用路径。未来,随着数据集的视觉扩展和模型的进一步优化,语言引导的自动驾驶决策或将成为新的研究方向!



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
