自动驾驶仿真新范式:可组合设计破解泛化难题
强化学习智能体在单一场景训练后换个路口就失败,根本原因不是算法不行,而是仿真器给不出足够多样的训练场景——MetaDrive用可组合设计让一个仿真平台生成无限种驾驶场景,实验证明场景多样性提升直接带来泛化能力跃升。
论文原文: MetaDrive: Composing Diverse Driving Scenarios for Generalizable Reinforcement Learning 作者: Quanyi Li, Zhenghao Peng, Lan Feng, Qihang Zhang, Zhenghai Xue, Bolei Zhou 链接: https://arxiv.org/abs/2109.12674[1]
问题到底难在哪里
想象你在某个固定的模拟城镇里训练了一个自动驾驶智能体,它学会了完美通过每个路口、避开每辆车。但当你把它放到另一个城镇时,它立刻翻车——这就是强化学习面临的泛化性危机。
这个问题的技术根因在于数据分布的贫瘠。现有驾驶仿真器如CARLA、SUMMIT虽然渲染逼真,但它们的地图、交通流规则都是手工设计的固定资产。一个仿真器可能只有几十个场景,而现实世界的驾驶场景组合是指数级的:不同道路拓扑、车流密度、障碍物位置的排列组合,远超现有数据集能覆盖的范围。
核心矛盾在于:仿真器需要高效轻量才能大规模训练,但又必须提供海量多样场景才能避免过拟合。追求照片级渲染的仿真器运行缓慢,一天只能跑几千个episode;而简化仿真器又往往只有寥寥几个固定地图。研究表明,在单一场景训练的智能体,测试成功率可能不到训练场景的一半——这种程度的过拟合让强化学习难以真正落地自动驾驶。
MetaDrive的切入点是:不追求单个场景的极致逼真,而是用程序化生成和可组合架构,让仿真器能以300帧每秒的速度生成无限种不同场景。
核心洞见
MetaDrive的灵感来自游戏开发中的程序化内容生成技术。Roguelike游戏能用有限的房间模块拼出无数地牢,关键在于每个模块都是标准化接口的可复用组件。MetaDrive将这个思想迁移到驾驶仿真:把道路、车辆、障碍物全部抽象为带参数空间的可组合对象。
核心Insight: 仿真场景的多样性不应依赖手工设计新地图,而应通过将基础元素(道路块、车辆、交通规则)抽象为可配置对象,然后用管理器系统按需组合——就像用乐高积木而非雕刻整块木头。
这个洞见解决了前面的核心矛盾:通过牺牲单帧渲染质量换取组合空间的爆炸性增长。一个包含10种道路块的系统,拼成5段道路就有10万种组合;加上车流密度、障碍物位置的随机化,场景数量实际上无穷。同时,因为每个基础组件都经过高度优化,组合出的新场景不会拖慢仿真速度。
方法拆解
Object:万物皆可配置对象
Why: 传统仿真器的问题是底层引擎和Python接口耦合,开发者想改个车辆参数都要深入物理引擎。要实现快速组合,必须先把所有元素标准化。
What: Object是物理模型和渲染模型的统一代理,对外只暴露高层API。
How: 每个Object类定义了参数空间边界,实例化时可指定或随机采样参数。比如车辆对象有轮胎摩擦系数、悬挂刚度、车身颜色等几十个参数。调用vehicle.set_state()一行代码就能改变位置速度,而不必接触Bullet物理引擎的底层实现。关键设计是参数会自动同步到物理模型和渲染模型两个后端,保证仿真一致性。
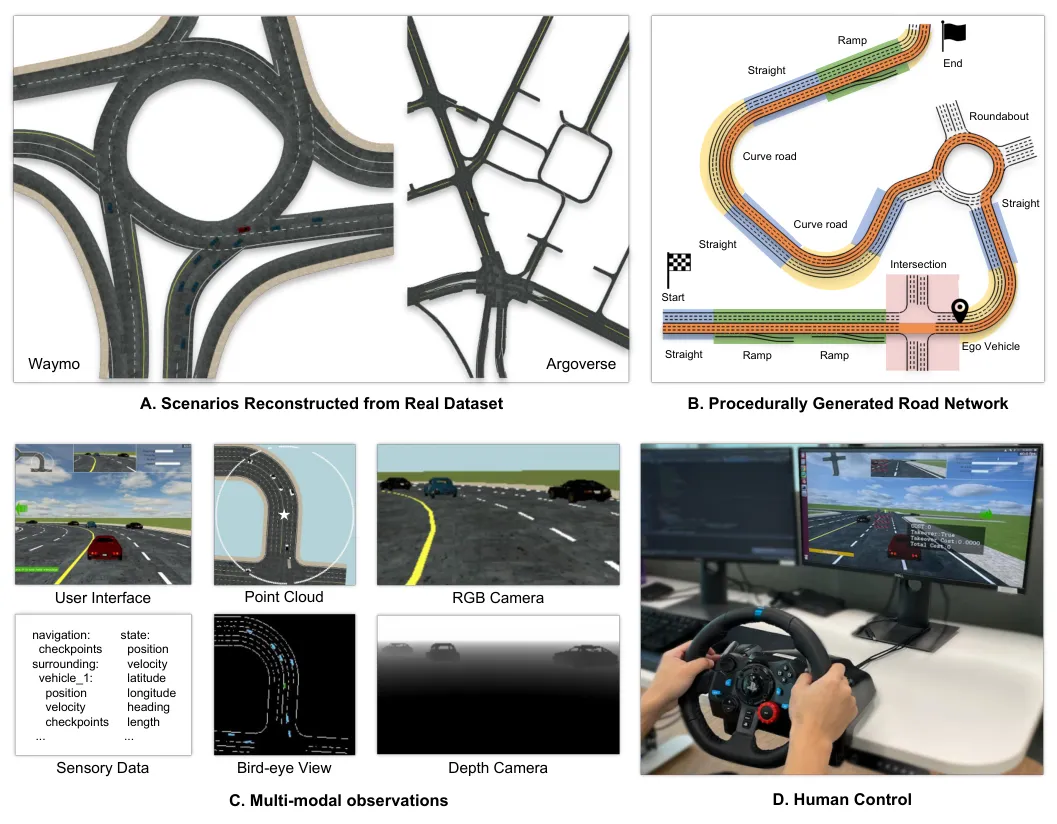 图1:MetaDrive支持两种场景生成方式——左侧展示从真实数据集(Waymo/Argoverse)导入地图和交通流,右侧展示程序化生成的道路网络。无论哪种来源,都能通过统一的Object接口操控
图1:MetaDrive支持两种场景生成方式——左侧展示从真实数据集(Waymo/Argoverse)导入地图和交通流,右侧展示程序化生成的道路网络。无论哪种来源,都能通过统一的Object接口操控
Manager:场景的乐高说明书
Why: 有了标准化组件还不够,需要定义"谁在什么时候创建哪些对象,用什么策略控制"。这就是Manager系统要解决的编排问题。
What: Manager是对象生命周期和策略分配的控制中心,每类Manager负责一类场景元素。
How: MetaDrive定义了四个基础Manager:Map Manager随机选择或生成地图、Traffic Manager管理交通车流、Object Manager散布障碍物、Agent Manager管理受RL策略控制的目标车辆。每个Manager在初始化阶段spawn对象并分配策略,运行时监控对象状态决定回收或创建新对象。比如Traffic Manager的Respawn模式会在交通车到达终点后将其重新放置到随机起点,维持恒定车流密度。
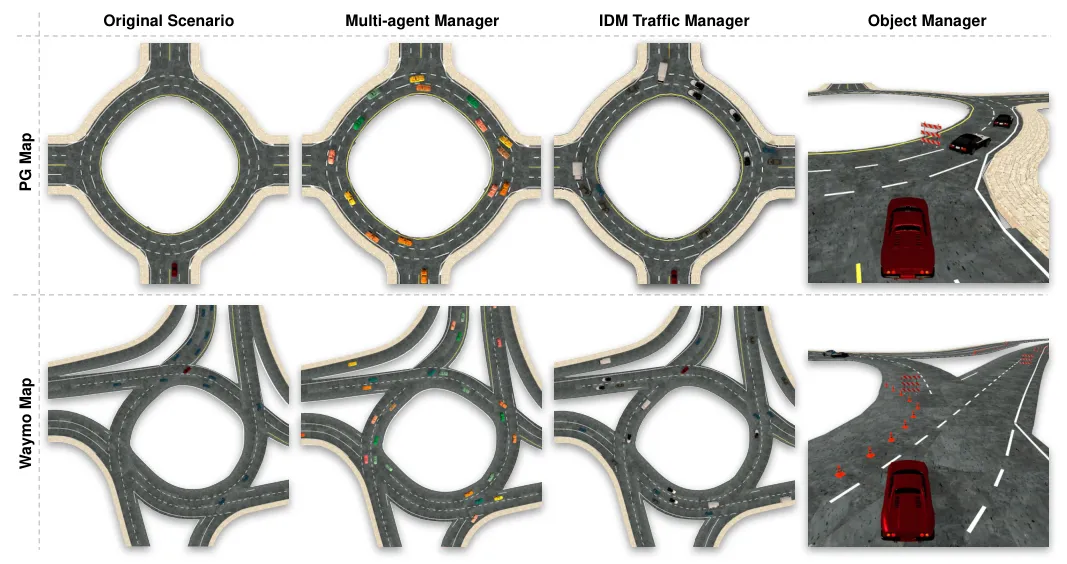 图2:通过替换和组合不同Manager生成新场景——第一列是原始场景(PG生成地图和Waymo真实地图),第二列替换为Multi-agent Manager生成多智能体导航任务,第三列加入IDM Traffic Manager添加响应式交通流,第四列加入Object Manager构成安全关键场景。四种Manager的排列组合产生丰富场景类型
图2:通过替换和组合不同Manager生成新场景——第一列是原始场景(PG生成地图和Waymo真实地图),第二列替换为Multi-agent Manager生成多智能体导航任务,第三列加入IDM Traffic Manager添加响应式交通流,第四列加入Object Manager构成安全关键场景。四种Manager的排列组合产生丰富场景类型
程序化生成:道路的自动拼接算法
Why: 手工设计地图无法扩展,需要算法自动生成合法且多样的道路网络。
What: 基于道路块(Block)的增量生成算法,每个Block是直道、弯道、环岛等预定义结构。
How: 用图结构表示Block,节点是关键点,边是车道,额外包含Socket(连接点)信息。算法核心是Block Incremental Generation:随机选一种Block类型,找到新Block和已有网络的Socket,旋转新Block使两个Socket方向互补,检查碰撞,无冲突则合并到网络中。若当前尝试失败则回溯换另一个Block,最多尝试T次。通过控制Block序列和每个Block的参数(车道数、宽度),可生成从简单直道到复杂立交桥的任意拓扑。
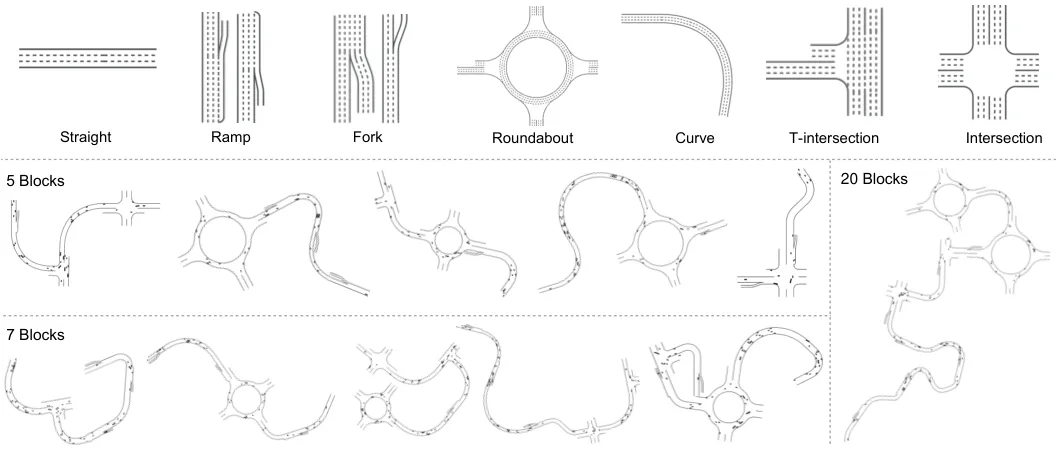 图3:第一行展示基础道路块类型(直道、弯道、环岛等),后续行展示用不同数量的Block组合生成的地图。Block数量越多,地图拓扑越复杂,训练场景多样性越高
图3:第一行展示基础道路块类型(直道、弯道、环岛等),后续行展示用不同数量的Block组合生成的地图。Block数量越多,地图拓扑越复杂,训练场景多样性越高
真实数据导入:虚实结合的泛化验证
Why: 纯合成数据可能有分布偏差,需要真实场景验证泛化能力。
What: 从Waymo和Argoverse数据集导入真实道路和交通轨迹。
How: Map Manager解析数据集中的道路几何信息重建地图,Replay Traffic Manager有两种模式:Log-replay模式严格重放记录的轨迹不响应环境,IDM模式用真实数据初始化车辆位置但后续用IDM策略控制使其能响应目标车辆。这种设计支持在真实地图上测试PG训练的策略,或混合真实与合成数据训练。
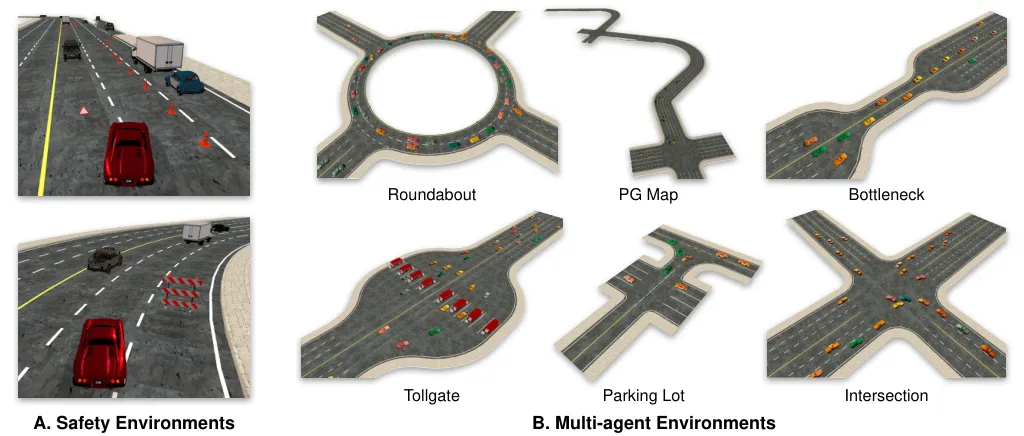 图4:左侧展示安全驾驶环境,在地图上随机散布锥桶、护栏、抛锚车辆等障碍物。右侧展示多智能体环境,包括环岛、瓶颈路段、收费站、停车场、路口等复杂交互场景,所有车辆都由学习策略控制
图4:左侧展示安全驾驶环境,在地图上随机散布锥桶、护栏、抛锚车辆等障碍物。右侧展示多智能体环境,包括环岛、瓶颈路段、收费站、停车场、路口等复杂交互场景,所有车辆都由学习策略控制
实验结果
论文在程序化生成场景上进行了泛化性实验,使用PPO和SAC两种强化学习算法。训练集场景数量从1个增加到1000个,在独立的测试集评估。
关键发现:当训练集只有1个场景时,PPO智能体在训练集成功率达到0.9,但测试集仅0.4,严重过拟合。随着训练场景增加到100个,测试成功率提升至0.75,同时碰撞率从0.15降至0.05。SAC算法表现更稳定,在100个训练场景时测试成功率达到0.82。
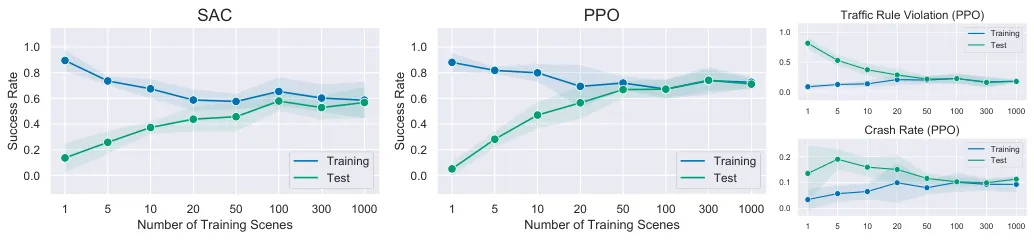 图5:左图显示SAC算法的泛化曲线,右图显示PPO算法结果。两种算法都呈现相同规律:增加训练场景数量显著提升测试成功率并降低碰撞率和违规率。SAC训练更稳定,阴影区域表示标准差
图5:左图显示SAC算法的泛化曲线,右图显示PPO算法结果。两种算法都呈现相同规律:增加训练场景数量显著提升测试成功率并降低碰撞率和违规率。SAC训练更稳定,阴影区域表示标准差
真实场景实验中,在5个Waymo真实场景训练的策略测试成功率为0.68,而用100个PG场景训练的策略在真实场景测试只有0.42,说明sim-to-real gap依然存在。但将真实数据和合成数据混合训练,真实数据占比40%时就能达到0.73的成功率,证明混合训练是提升泛化的有效策略。
多智能体实验在40个智能体的环境中训练,平台仍能保持60 FPS运行速度。安全强化学习基准测试了SAC-Lag、PPO-Lag、CPO等算法,提供了标准对比数据。
工程师能学到什么
MetaDrive的可组合设计哲学可迁移到其他仿真需求:
机器人操作仿真:把物体、机械臂、传感器抽象为Object,用Task Manager组合抓取、放置、组装等任务,一套代码支持从简单积木到复杂装配的渐进训练。
游戏AI测试:将地图元素、敌人、道具定义为可配置对象,用关卡生成器自动拼接,测试AI在未见过地图的表现。
关键工程Takeaway:
参数空间而非固定资产:设计系统时为每个组件定义参数范围而非hardcode值,运行时随机采样,用同一套代码生成多样实例。实现上用配置字典 + 参数验证机制,开发成本增加不到20%但灵活性提升数量级。
Manager模式解耦组合逻辑:不要在环境类里写巨型if-else控制对象创建,而是为每类功能(地图、交通、障碍)设计独立Manager,通过注册机制组合。代码示例:engine.register_manager("traffic", IDMManager) 即可切换交通策略。
真实数据作为验证集而非训练主体:收集真实数据成本高,不如用程序化生成海量合成数据训练,用少量真实数据验证和微调。实验显示20%真实数据混合就能有效弥合sim-to-real gap。
开源资源: 代码已开源于https://github.com/metadriverse/metadrive,文档包含自定义Manager和添加新道路块的教程。关键超参数:训练至少100个不同场景才能观察到明显泛化提升,车流密度建议0.1-0.3辆/米覆盖稀疏到拥堵场景。[2]
批判与展望
最明显的局限:MetaDrive为了仿真效率牺牲了视觉真实性,这在端到端视觉策略训练上可能带来sim-to-real gap。论文用的是Lidar-like的几何观测而非摄像头RGB图像,现实中基于视觉的系统还需要额外的domain adaptation步骤。理想化假设是几何信息足够——但真实驾驶中光照、天气、遮挡等视觉因素会显著影响感知。
论文未深入讨论的问题是长尾场景的覆盖:虽然程序化生成能产生大量场景,但这些场景的分布是否覆盖真实世界的关键corner case(如复杂施工区、异常天气、行人突然冲出)仍不清楚。随机组合更像是插值而非外推,可能遗漏罕见但关键的失败模式。
最值得跟进的方向是对抗性场景生成:不是随机组合道路块,而是训练一个对抗生成器,专门产生当前策略会失败的场景,形成curriculum learning。这样能主动探索策略的弱点而不是被动希望随机采样碰到,可能用更少场景达到更好泛化。结合MetaDrive的可组合架构,对抗生成器只需学习Manager的参数分布,实现难度可控。
引用链接
[1]https://arxiv.org/abs/2109.12674
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
