后浪·青科 | 空间智能如何让自动驾驶和机器人看懂这个世界?
本期主讲人:金鑫 宁波东方理工大学助理教授、博士生导师
通过空间智能技术,让机器(自动驾驶系统、机器人等)不仅能够感知和理解三维世界,还能基于这种理解做出合理的决策与行动。
《空间智能技术在自驾及机器人等具身智能产业中的探索及应用》
分享内容主要来自宁波东方理工大学(EIT)的EIT-CV实验室,项目研究合作团队包括上海交通大学、清华大学、复旦大学、香港大学、字节跳动、旷视科技、理想汽车、银河通用、逐际动力机器人等。
空间智能
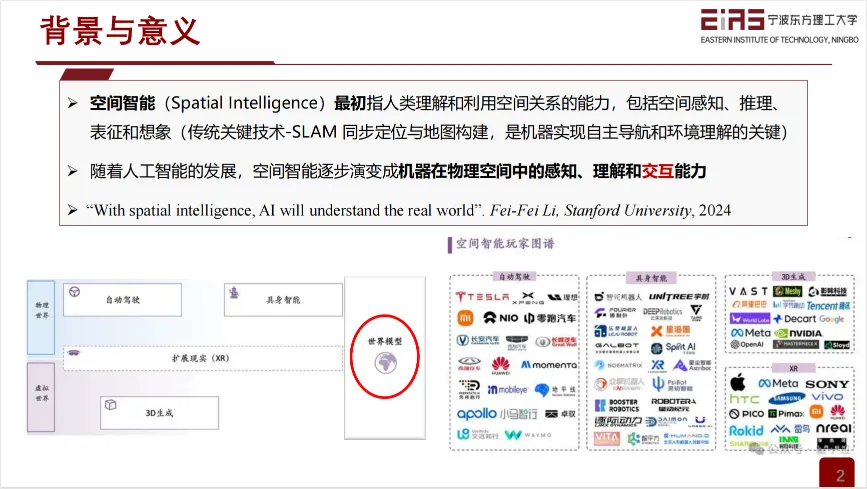
空间智能(Spatial Intelligence)最初指人类理解和利用空间关系的能力,包括空间感知、推理、表征和想象(传统关键技术-SLAM 同步定位与地图构建,是机器实现自主导航和环境理解的关键)。
随着人工智能的发展,空间智能逐步演变成机器在物理空间中的感知、理解和交互能力。
空间智能的应用场景
空间智能的应用场景包括自动驾驶、机器人、低空经济、智慧城市等重点领域。
空间智能的发展趋势
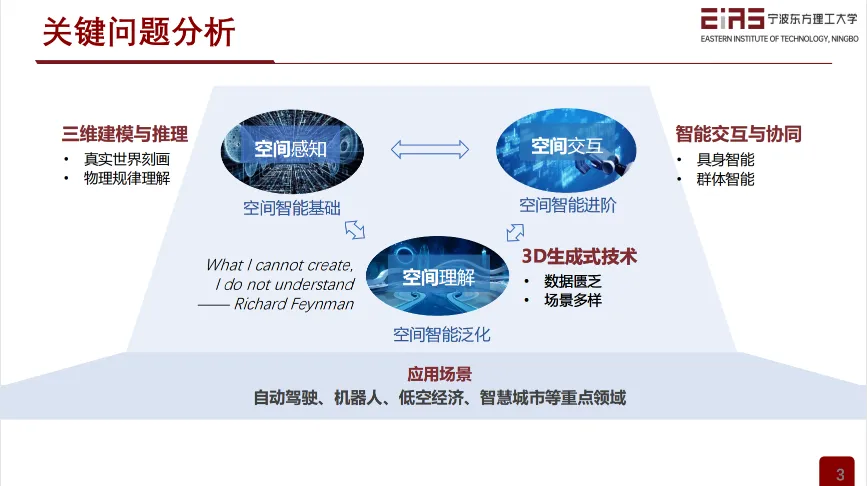
从空间构型(感知、理解、生成)到智能体训练(模仿、学习、执行)的研究路径。
自动驾驶场景的感知与生成
在自动驾驶领域,如何让车辆准确理解周围的三维环境是核心挑战之一。研究团队提出了一种名为UniScene的框架,可以统一生成自动驾驶所需的三维空间信息,包括:
• 三维语义占用(空间中每个体素是什么)
• 多视角视频
• 激光雷达点云数据
具身智能场景的空间感知与生成
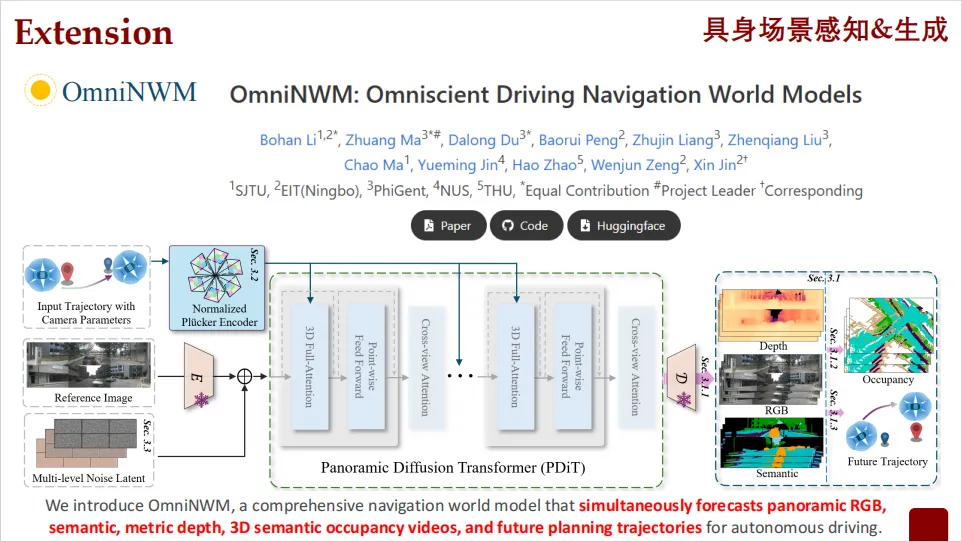
研究团队利用OmniNWM进行探索,这是一个用于自动驾驶的综合导航世界模型,能够同时预测多种信息:
• 全景RGB图像
• 语义信息
• 度量深度
• 三维语义占用
• 未来的行驶轨迹
这种多任务联合预测的能力,使得模型对环境有更全面、更深入的理解,有助于提升自动驾驶的安全性和可靠性。
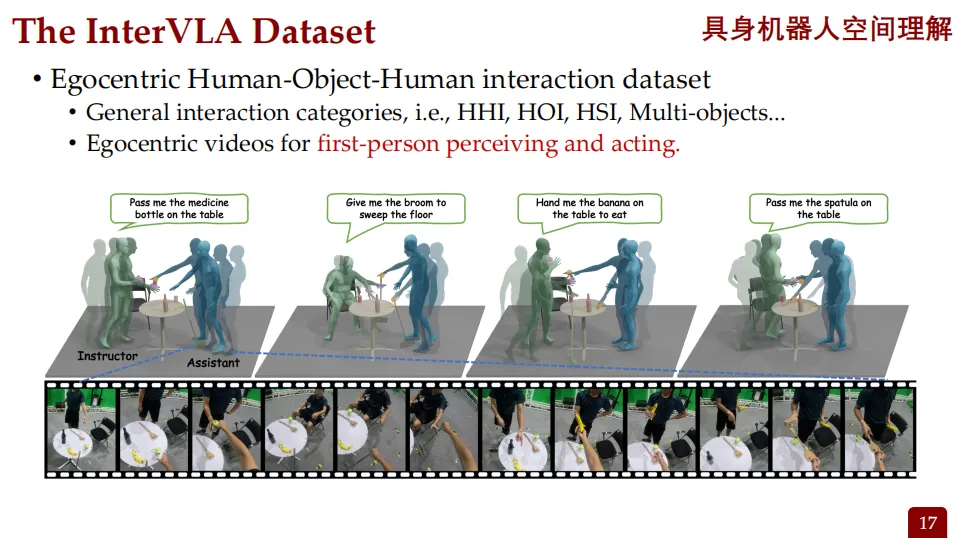
第一人称视角的数据集构建
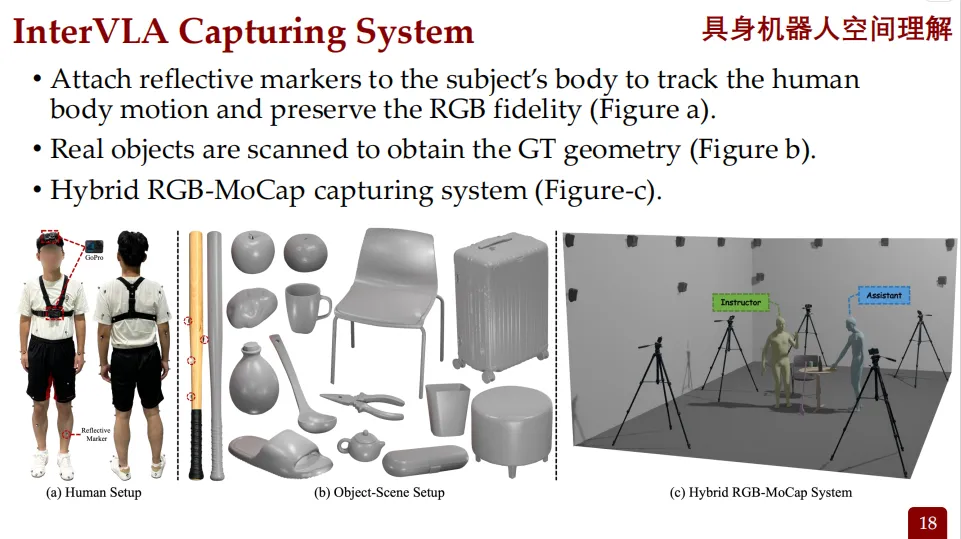
通用的智能机器人需要理解人类如何与物体、他人、场景互动,但这类数据的采集非常昂贵和复杂。因此,研究团队决定构建一个以人为中心的数字数据集InterVLA,用来训练机器人。
这些数据包括:
• 第一人称视频
• 第三人称视频
• 人体与物体的运动轨迹
• 文字说明
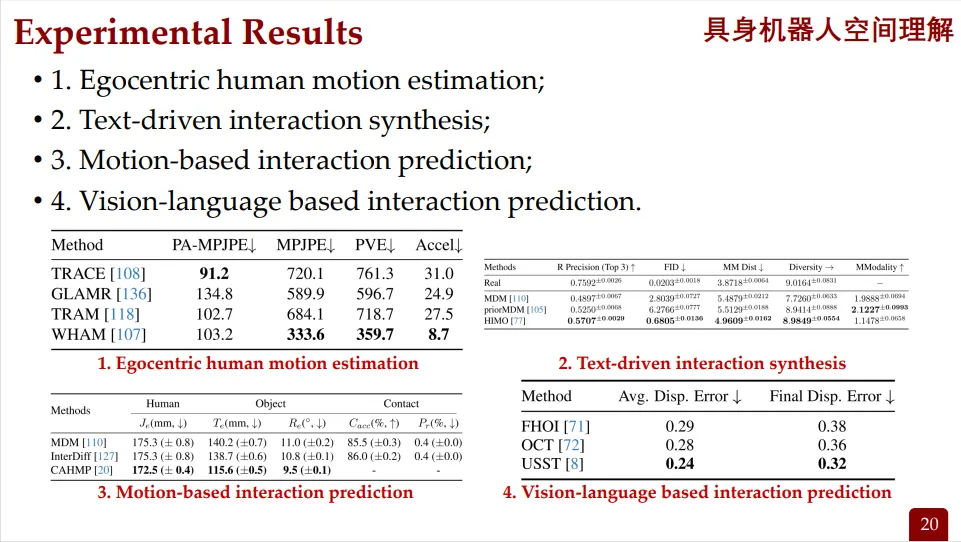
每个方向都有相应的实验数据对比,展示了不同方法的性能差异。
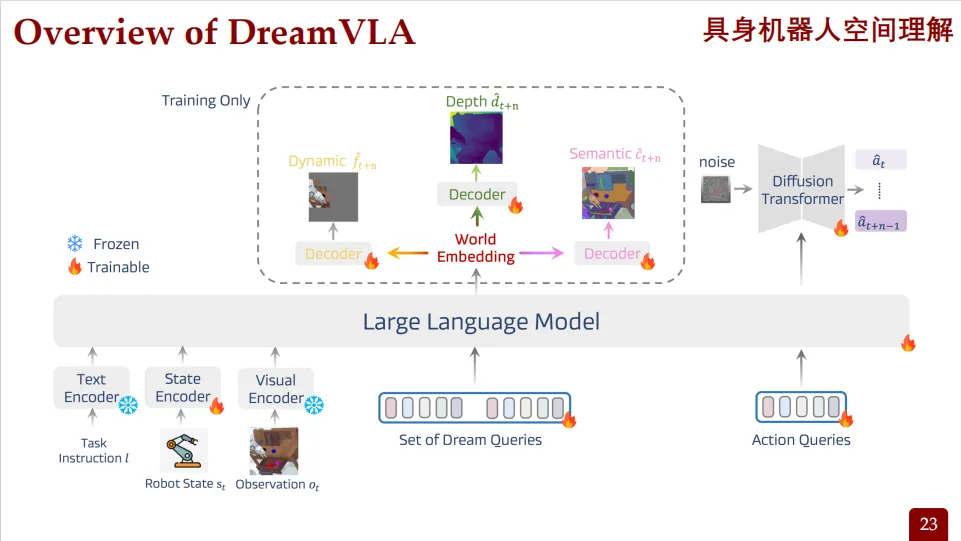
DreamVLA:视觉-语言-动作模型
传统的VLA(Vision-Language-Action)模型往往直接根据当前帧图像输出动作。而DreamVLA提出了一种更接近人类思维方式的设计:先形成多模态推理链,再执行动作。
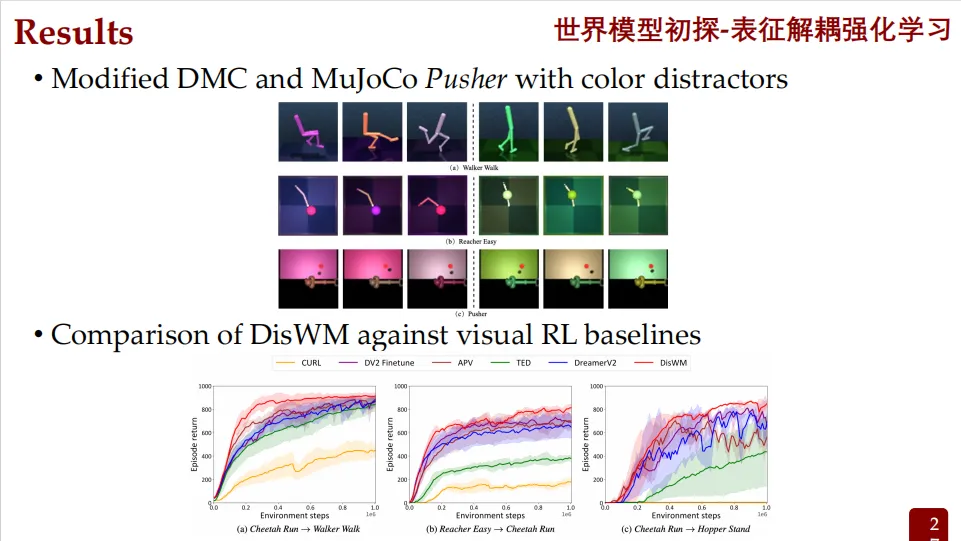
世界模型初探与表征解耦强化学习
提出一种解耦世界模型,能够从带有干扰的视频中提取出语义知识(即与任务相关的关键信息),并利用这些知识来帮助智能体更快学习新任务。
空间智能赋予机器感知、理解与交互三维世界的能力,为具身智能注入物理交互“常识”,让我们共同期待空间智能行业从“感知智能”迈向“动作智能”,实现在自驾及机器人等复杂场景的商业化应用。
责编 | 陈心琪
审校 | 邵鹏博
核发 | 邓 瑶