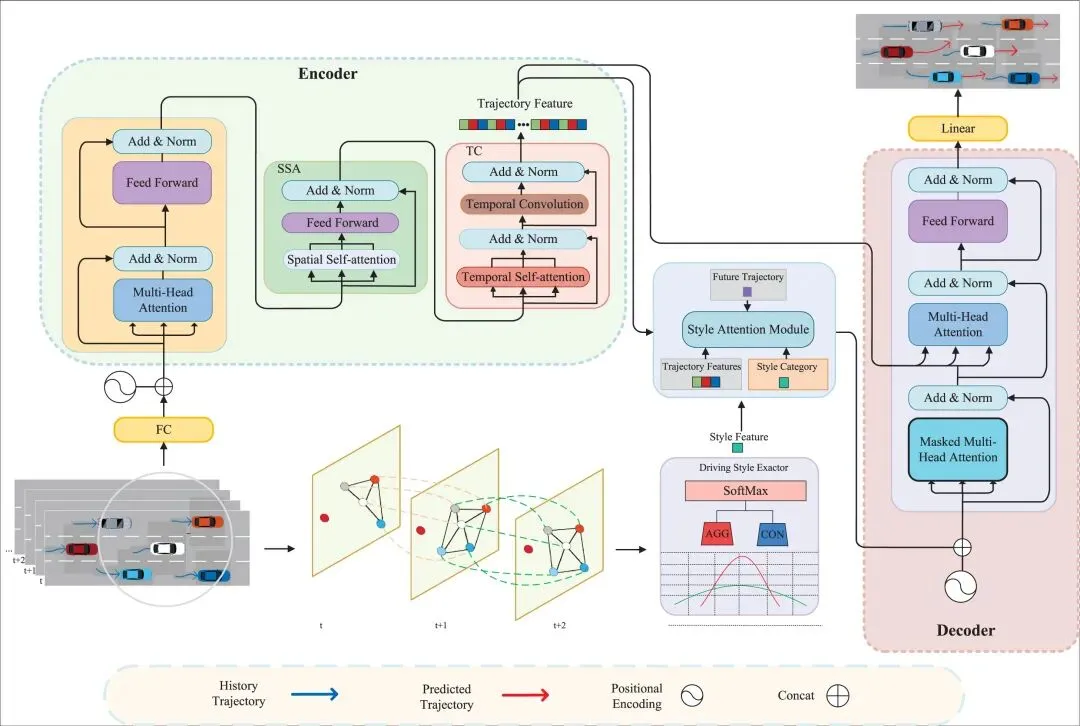
本文提出的 DS-STT 方法整体结构如图1所示,围绕驾驶风格建模与时空特征融合展开,以实现复杂交通场景下的个性化轨迹预测。模型以多车辆历史轨迹为输入,通过统一的符号体系进行建模与表示,并明确了编码器、解码器以及驾驶风格特征提取模块之间的数据流关系。其中,编码器用于提取车辆间的时空相关性,解码器用于生成未来轨迹,而驾驶风格特征提取器则从交通图结构中学习驾驶行为表征,并为后续预测提供风格先验信息。
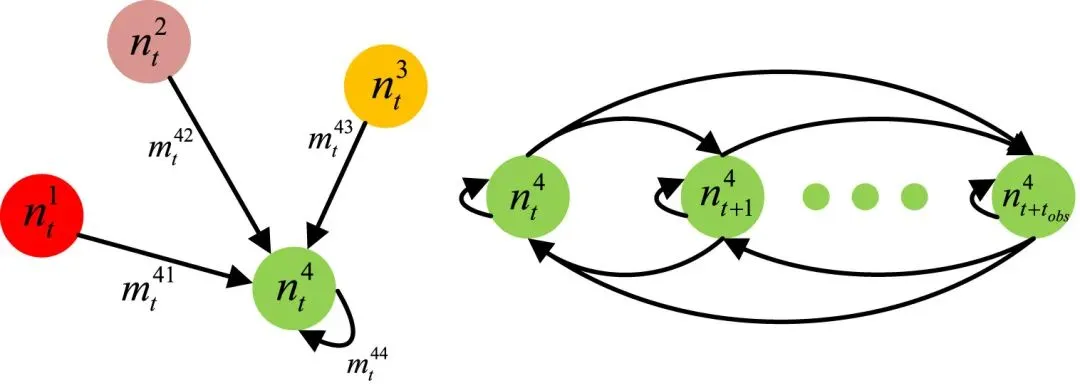
在方法设计上,首先对车辆轨迹预测问题进行形式化建模,将其视为多变量时间序列预测任务,输入为历史时刻的车辆状态信息(包括位置、速度等),输出为目标车辆的未来轨迹序列。在驾驶风格建模方面,本文构建了时空交通图(STTG)来刻画多车辆之间的空间交互与时间依赖关系(见图2相关结构),其中空间边描述同一时刻车辆之间的交互关系,时间边描述同一车辆在相邻时间步之间的动态演化。基于该图结构,引入加权邻接机制以反映车辆之间交互强度,并结合图论中的度中心性与接近中心性来刻画车辆的局部交互程度与空间位置特征:度中心性用于衡量车辆与邻域车辆的连接数量,从而反映其交互活跃程度与潜在激进性;接近中心性则通过平均距离的倒数衡量车辆在交通流中的相对位置,能够反映其靠近或远离交通拥堵中心的趋势。通过对这些时序中心性特征进行建模,并结合多时间步的图结构信息,模型学习驾驶行为与图特征之间的映射关系,进而输出对应的驾驶风格类别(如激进型与保守型),并以 one-hot 向量形式进行编码,为后续模块提供风格条件输入。
在轨迹编码阶段,首先通过全连接层对原始运动状态进行高维嵌入,并结合位置编码以保留轨迹的序列顺序信息。在此基础上,编码器由空间自注意力(SSA)子层与时间卷积(TC)子层构成:SSA 子层通过多头自注意力机制建模不同车辆之间的空间交互关系,实现对邻车影响的全局建模;TC 子层则进一步通过时间自注意力与时间卷积相结合的方式,捕捉车辆轨迹在时间维度上的动态依赖关系,并扩展感受野以增强对长时序信息的建模能力。通过层级化的时空特征提取,编码器能够获得兼具空间交互与时间演化信息的表示。
在轨迹解码阶段,本文设计了风格注意力模块(SAM),用于融合驾驶风格、车辆交互特征以及历史运动状态信息。该模块通过前馈神经网络生成注意力权重,并在解码过程中保持相对稳定,以表征驾驶员在观测窗口内的行为倾向,从而在时间维度上保持一致的行为影响。融合后的特征作为解码器输入,解码器由多头自注意力、带掩码的时间注意力以及前馈网络组成,其中掩码机制保证预测仅依赖于已知历史信息,从而实现自回归式生成。最终,通过线性映射与归一化操作输出未来轨迹序列。
此外,模型训练通过最小化预测轨迹与真实轨迹之间的误差来进行优化。相较于基于图神经网络的方法(依赖逐步消息传递),DS-STT 利用注意力机制实现全局交互建模与并行计算,在保证表达能力的同时提升了计算效率,使其在中等规模交通场景(如 HighD 与 ApolloScape 数据集)中具备良好的实时性与可扩展性。整体而言,该方法通过将驾驶风格建模与时空建模相结合,在统一框架下实现了对交通参与者异质行为的显式刻画,从而提升轨迹预测的精度与个性化能力。
本研究围绕所提出的DS-STT模型,在HighD与ApolloScape两个大规模真实数据集上开展了系统且全面的实验验证,涵盖数据集设置、评价指标、对比实验、消融分析以及定性可视化分析。实验在统一的输入条件与数据划分(训练/验证/测试为7:1:2)下进行,所有模型均不依赖高精地图、路径意图或语义标注,以确保公平性与可复现性。在数据构建方面,HighD数据集包含约11万车辆的高速公路轨迹数据(选取双向六车道场景,并将25 Hz降采样至5 Hz),而ApolloScape数据集包含约10万条城市交通轨迹,融合了摄像头与LiDAR等多源信息。针对数据集中缺乏显式驾驶风格标签的问题,本文采用基于时变交通图与中心性特征的标注方法,并结合人工注释,将驾驶行为划分为激进与保守两类,同时仅利用历史轨迹信息进行推断,以避免标签泄漏并保证标注的可靠性。
在建模层面,本文构建了基于距离倒数加权的无向时空交互图(引入距离阈值μ),并通过空间自注意力与时间卷积机制联合建模车辆间交互关系与时序依赖,同时引入驾驶风格相关的中心性特征(如度中心性与接近中心性)来刻画车辆行为的动态变化,从而在上下文感知框架下实现对驾驶风格的有效表征。该设计在不依赖显式结构信息的情况下,仍能稳定捕捉复杂交通环境中的关键交互关系。
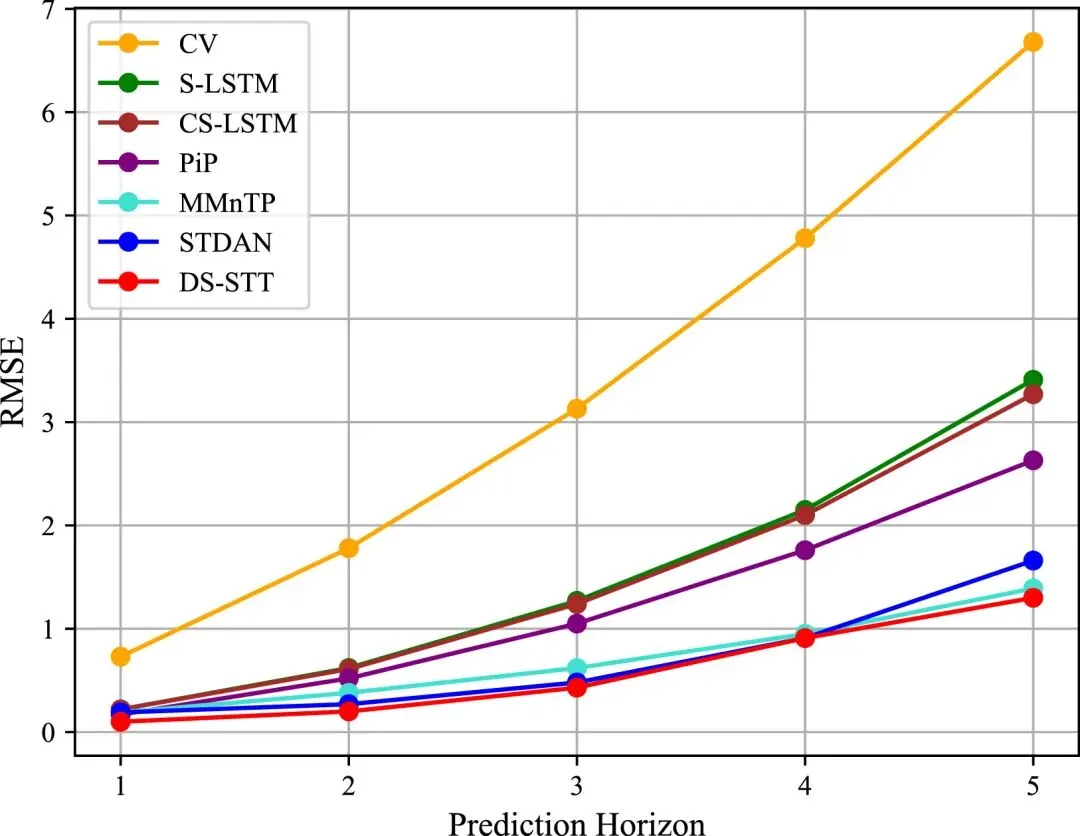
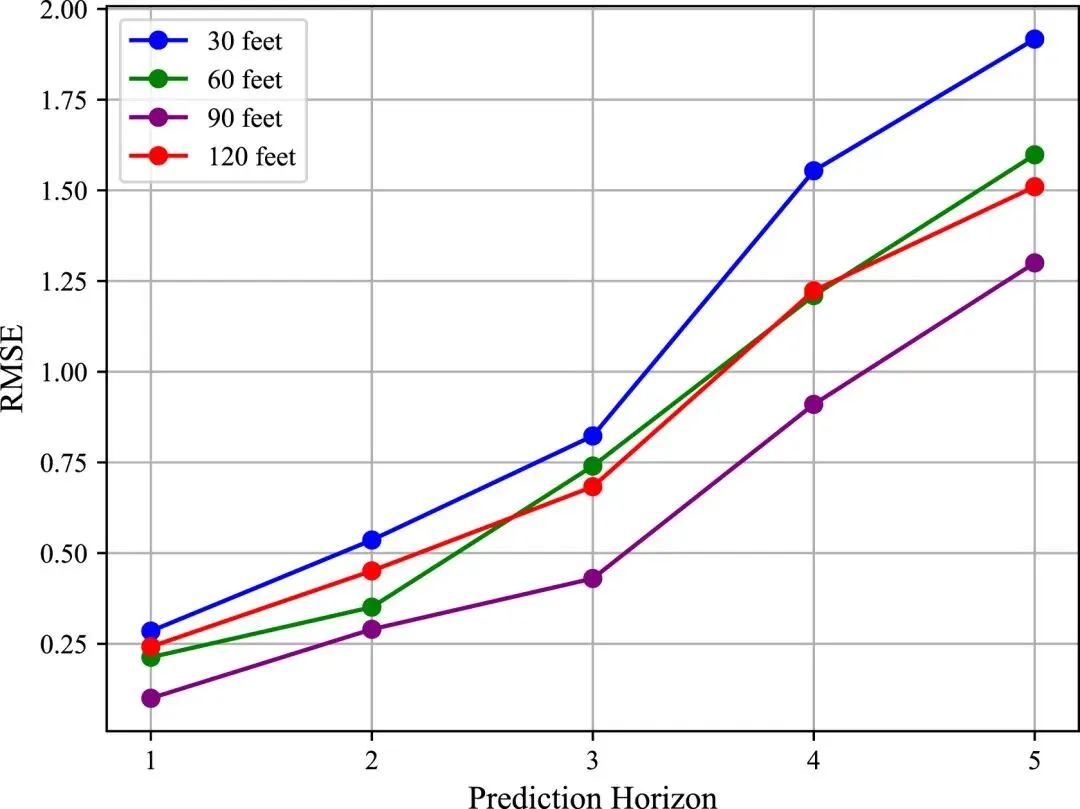
在定量实验方面,DS-STT在HighD与ApolloScape两个数据集上均显著优于包括CV、S-LSTM、CS-LSTM、PiP、MMnTP、STDAN、GRIP++以及SOUT在内的多种基线方法。在HighD数据集上,DS-STT在不同预测时域中均表现出最低的预测误差,相较传统恒速模型CV最高可降低81.58%的RMSE,同时相较STDAN等深度学习方法亦有约13.67%的性能提升。随着预测时间延长,各模型误差整体呈上升趋势,但DS-STT增长最为平缓,体现出更强的长时预测稳定性与误差抑制能力。相关趋势在图3中得到直观展示:DS-STT的RMSE从1秒时的0.10 m缓慢增长至5秒时的1.30 m,而传统CV模型则从0.73 m急剧上升至6.68 m,表明其在长时预测中存在显著的误差累积问题。进一步从逐时域误差变化来看,DS-STT在不同预测步长下始终保持更低且更平滑的误差增长曲线。
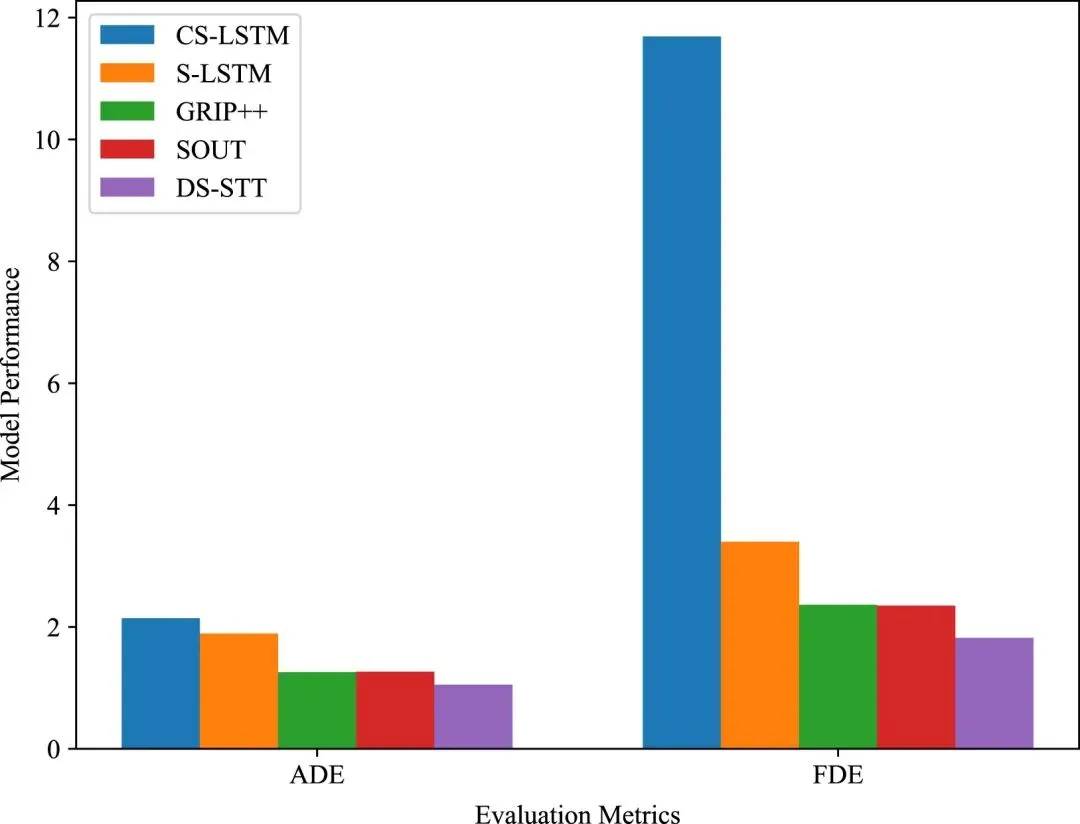
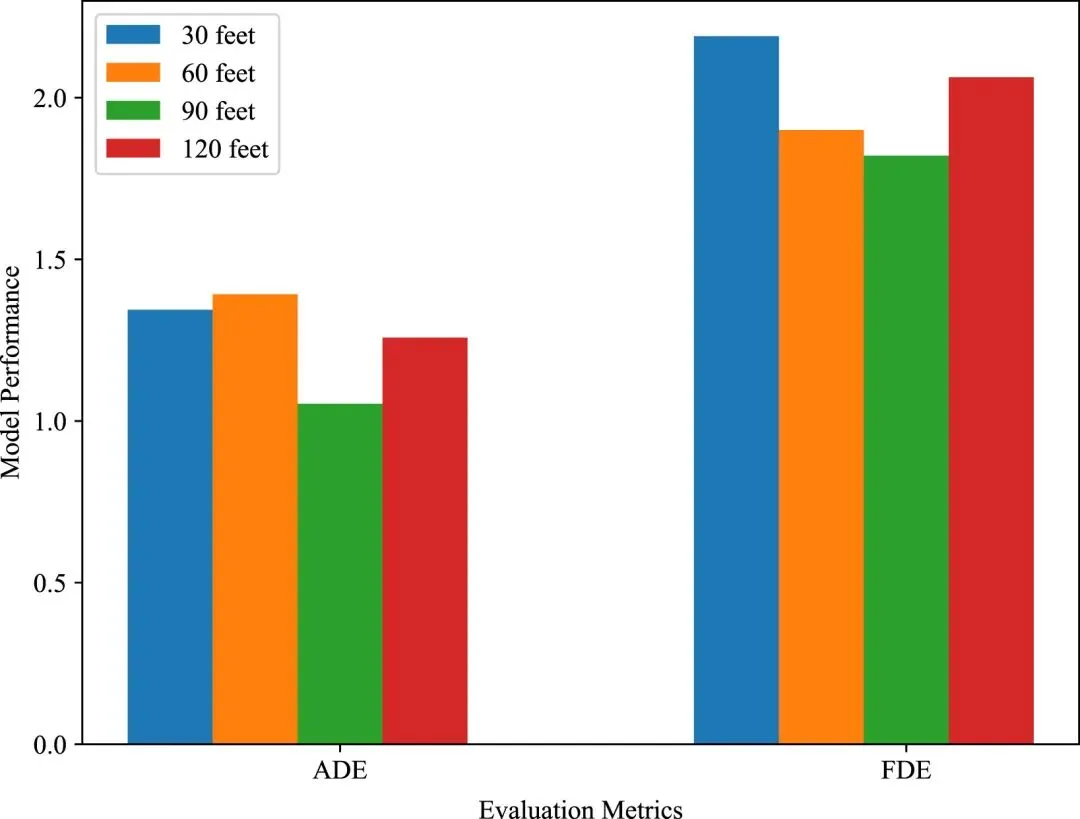
在ApolloScape数据集上,DS-STT在ADE与FDE指标上均取得最优性能,相较SOUT分别提升16.89%与22.51%,并在FDE上降低约0.5 m,显示出更优的终点预测能力与潜在安全性。同时,相较于同样基于图结构建模的GRIP++,DS-STT也实现了约16.29%的性能提升。这一结果表明,在更复杂的城市交通场景中,通过融合车辆交互信息、运动状态与驾驶风格特征,DS-STT能够更准确地建模多主体行为并实现稳健预测。相关定量对比结果可见于图4。
消融实验进一步验证了各模块的有效性。具体而言,分别移除空间自注意力模块(SSA)、时间卷积模块(TC)以及风格注意力模块(SAM)后,模型性能均出现明显下降。其中,去除SSA会削弱对车辆间空间交互关系的建模能力;去除TC会降低对时间依赖的建模能力;而去除SAM则使模型无法根据不同驾驶风格自适应调整注意力分配,从而忽略个体行为差异。三者协同作用共同构成了DS-STT性能提升的关键来源。不同配置下的对比结果如Table 5与Table 6所示。此外,距离阈值μ的敏感性分析表明,该参数对模型性能具有重要影响:当μ设置为30 ft时,模型因遗漏关键邻近车辆而表现较差;当μ扩大至120 ft时,引入过多无关车辆,增加计算负担并干扰建模效果;最终选择90 ft作为在性能与效率之间的折中方案。相关实验趋势如图5和图6所示.
在定性分析方面,通过轨迹可视化结果(图7)可以观察到,DS-STT预测结果与真实轨迹具有高度一致性,并能够有效区分不同驾驶风格。在图中,激进驾驶车辆(红色)表现出高速行驶、频繁变道及超车等行为特征,而保守驾驶车辆(白色)则呈现出稳定车道保持、较低速度以及更短轨迹长度等特点。相比STDAN等强基线方法,DS-STT生成的轨迹更贴近真实分布,说明模型不仅能够准确进行轨迹预测,还能够学习并刻画不同驾驶风格下的行为模式。
综上,DS-STT通过融合空间—时间建模与驾驶风格建模,在多数据集与多场景条件下均展现出优异的预测精度、良好的长时稳定性以及较强的泛化能力,有效缓解了轨迹预测中的误差累积问题,并验证了显式引入驾驶风格信息对于提升自动驾驶轨迹预测性能与行为理解能力的重要价值。












 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
