编者语:后台回复“入群”,加入「智驾最前沿」微信交流群
在自动驾驶中,如何让车辆“看见”并“理解”周遭环境始终是核心难题。早期的感知方案大多依赖于目标检测,也就是给摄像头捕捉到的画面里的汽车、行人或自行车画上一个个方框。这种方式虽然直观,但在面对现实世界中千奇百怪的物体时,就会显得力不从心。为了解决这一问题,占据感知网络(Occupancy Network,简称OCC)技术逐渐成为行业主流。
为什么传统的画框方式不够用了
在过去很长一段时间里,自动驾驶系统主要识别的是预先定义好的物体。研发人员会告诉人工智能,长成什么样的叫车,什么样的叫人。只要系统在画面中找到了符合特征的物体,就会用一个三维的长方体框把它们标出来。这种基于目标的识别方式在标准化的城市道路上表现不错,可一旦遇到“意料之外”的状况,问题就接踵而至。
图片源自:网络
举个例子,路上突然掉落了一个形状奇特的纸箱,或者出现了一棵倒下的树,甚至一辆货车翻倒。由于这些物体的形状并不在系统预设的类别里,感知网络很可能无法给它们画上框,从而认为前方是平坦的道路。这种识别逻辑的缺失会导致非常严重的安全事故。占据感知网络的出现,本质上是将感知思路从寻找特定物体转变为判断空间是否被占用。它不再关心前方到底是车还是树,而是会确认那块空间是不是实心的。
空间是如何被数字化切分的
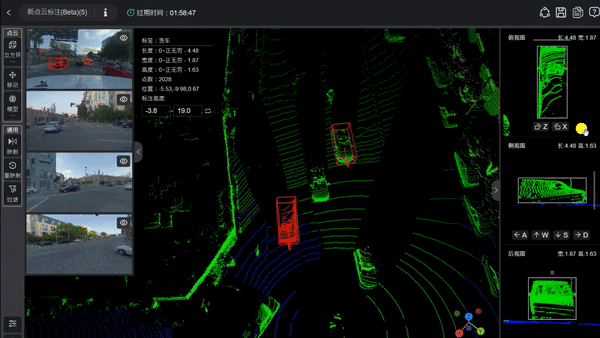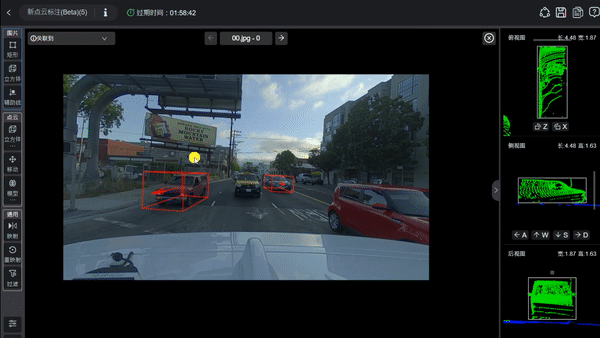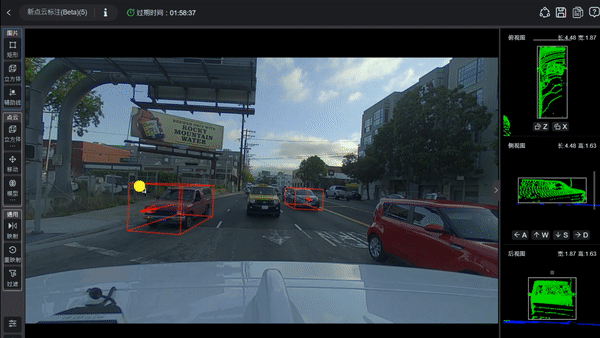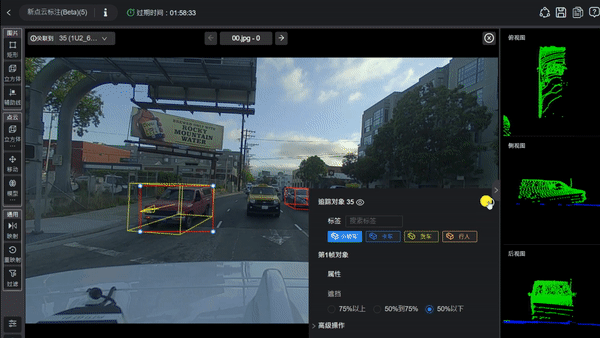
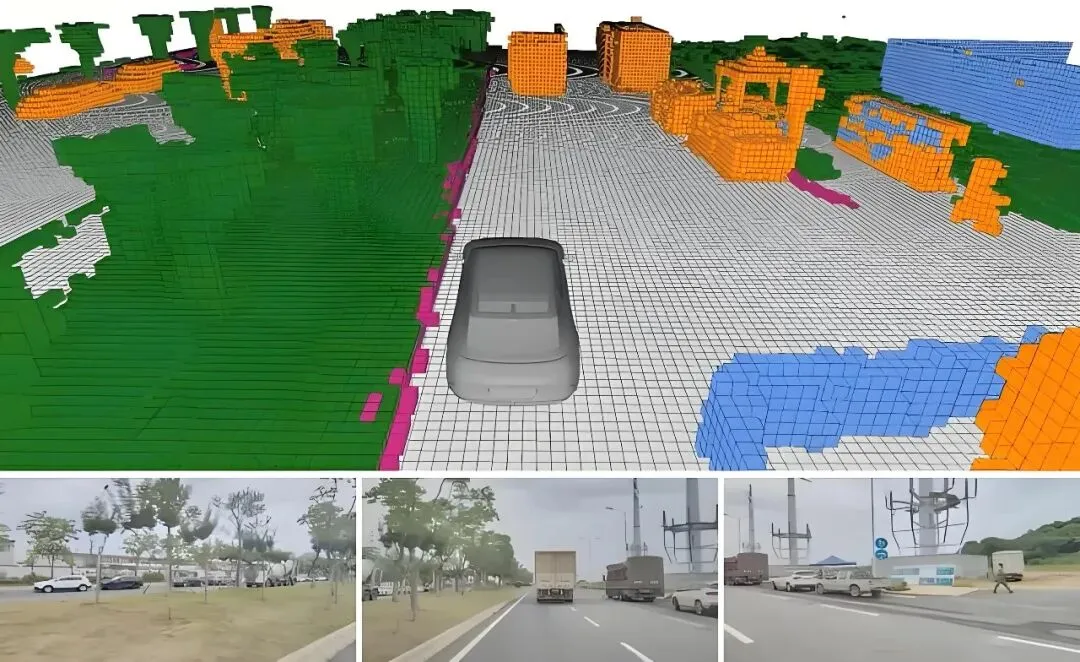
要理解占据感知网络的工作原理,可以先想象把车辆周围的三维空间切成无数个微小的正方体。这些小方块在技术上被称为“体素”。如果把传统的照片比作二维的像素点阵,那么体素就是三维版的像素。占据感知网络的核心任务,就是判断每一个微小的体素方块里到底是有物体存在,还是空无一物的透明空气。
图片源自:网络
在实际运作中,车辆搭载的多个摄像头会从不同角度拍摄周围的画面。占据感知网络会将这些来自不同位置的二维图像信息提取出来,通过数学转化,映射到预先设定好的三维网格空间里。这个过程就像是在进行连线游戏,系统需要根据图像中像素的特征,推算出它们在三维世界中对应的是哪一个格点。
当这些信息汇总到三维网格后,神经网络会通过深度学习模型对每个格子的状态进行预测。它会给每个格子分配一个概率值,用来描述这个地方被占据的可能性。如果概率值很高,系统就会认为这里存在障碍物。这种处理方式不需要提前学习每一种障碍物的长相,只要某个空间反射回来的视觉特征显示那里有东西,它就会被标记为“占据”状态,从而提醒车辆避让。
摄像头画面如何变成三维模型
由于目前主流的占据感知方案大多基于视觉相机,如何从扁平的图片中还原出准确的深度信息就变得至关重要。系统会利用特征提取网络,把摄像头拍到的每一帧画面转化为高维的特征数据。这些数据不仅包含了颜色和纹理,还隐含了物体之间的空间关系。随后,系统会利用特殊的变换模块,将这些分布在不同视角下的特征融合在一起,形成一个以车辆为中心的统一空间视角。
图片源自:网络
在这个统一的特征空间里,网络会进一步细化对空间的理解。除了判断格子是否被占据,有些的占据感知网络还能识别出格子的属性。例如,它能分辨出这一团被占据的空间是属于静止的马路牙子,还是属于正在移动的车辆。
这种语义上的细分,能帮助自动驾驶系统做出更合理的决策。比如面对路边的绿化带,车辆可以选择贴近行驶,而面对同样高度的石墩子,则必须保持更远的安全距离。
这种感知方式的另一个优势在于它对物体遮挡的鲁棒性。在复杂的交通流中,前方的车辆经常会遮住更远处的路面。占据感知网络具备一定的空间推理能力,它能根据已有的视觉线索,对被遮挡区域的占据情况做出合理的估算。这种脑补能力让自动驾驶车辆在处理十字路口或拥挤路段时,表现得更像一个经验丰富的人类驾驶员。
面对异形物体时有什么优势
占据感知网络最大的杀手锏在于它解决通用障碍物问题的能力。在真实的道路上,会出现垃圾桶、施工围栏、甚至是被风刮起的塑料袋,它们的形态千变万化。传统的识别算法很难穷尽所有的可能性,而占据感知网络通过体素化的方式,将物理世界完整地建模了出来。无论障碍物长得多么奇怪,只要它占据了空间,就会在三维网格中显现出来。
图片源自:网络
这种从底层逻辑上的改变,极大地提升了自动驾驶的安全性上限。它不再依赖于见过才认识,而是基于存在即感知的逻辑。当车辆行驶在路面上时,占据感知网络就像在实时构建一个数字孪生的三维世界,将所有的物理实体都以概率的形式填充在格子里。这种对环境的精细刻画,不仅为避障提供了依据,也为后续的路径规划提供了更加可靠的底图。
最后的话
占据感知网络让自动驾驶系统从单纯的图像识别进化到了空间感知。它通过对三维空间的体素化重构,打破了传统检测框架的束缚,使得车辆能够更从容地应对复杂多变的交通环境。随着算力的提升和算法的优化,这种技术正在让自动驾驶变得更加安全和智能。
-- END --