自动驾驶 | CREStE: 基于反事实表征与互联网先验的可扩展无地图导航
- 2026-05-13 07:56:29
自动驾驶 | CREStE: 基于反事实表征与互联网先验的可扩展无地图导航
0. 摘要
机器人导航一直是自主系统领域的核心挑战之一。传统方法依赖于预先构建的地图或昂贵的激光雷达传感器,而视觉导航方法虽然成本较低,但在泛化能力上存在明显不足。本文介绍的CREStE(Counterfactual REpresentation and Scalable mapless navigation with intErnet priors) 提出了一种全新的范式:通过利用互联网规模的视觉先验知识,结合反事实表征学习,实现了无需地图、仅依赖RGB相机的高效机器人导航。该工作已被RSS 2025接收,并已发布到Github,代表了机器人导航领域向大规模、可扩展方向发展的重要一步。
论文地址:https://arxiv.org/html/2503.03921v2GitHub地址:https://github.com/ut-amrl/creste_public
核心亮点:
• 仅需3小时的专家演示数据即可训练 • 在笔记本GPU上实现20Hz实时推理 • 已完成2公里的真实世界部署验证
1. 研究背景与问题定义
1.1 视觉导航的核心挑战
视觉导航(Visual Navigation)是指机器人仅通过视觉传感器(如RGB相机)感知环境并完成导航任务。与基于激光雷达的方法相比,视觉导航具有成本低、信息丰富等优势,但同时面临以下核心挑战:
感知泛化问题:机器人在训练环境中学习的视觉特征往往难以迁移到新环境。不同场景的光照条件、纹理特征、物体类别可能存在显著差异,导致导航策略失效。
奖励设计困难:传统强化学习方法需要精心设计奖励函数来指导机器人学习导航策略。然而,在没有地图信息的情况下,如何设计有效的奖励信号一直是一个棘手的问题。稀疏奖励(仅在到达目标时给予奖励)导致学习效率低下,而密集奖励的设计又需要大量的人工工程。
数据规模限制:机器人导航的训练数据通常来自仿真环境或有限的真实世界采集,数据规模和多样性远远无法与计算机视觉领域的互联网数据相比。
CREStE的核心洞察在于:互联网上存在海量的导航相关视觉数据(如第一人称视角视频、室内外场景图像等),这些数据蕴含了丰富的环境理解和导航先验知识。如何有效利用这些先验知识,是突破视觉导航瓶颈的关键。
2. CREStE方法概述
2.1 核心思想
CREStE的核心思想可以概括为"利用互联网先验,通过反事实推理实现可扩展的无地图导航"。具体而言,该方法包含两个关键创新:
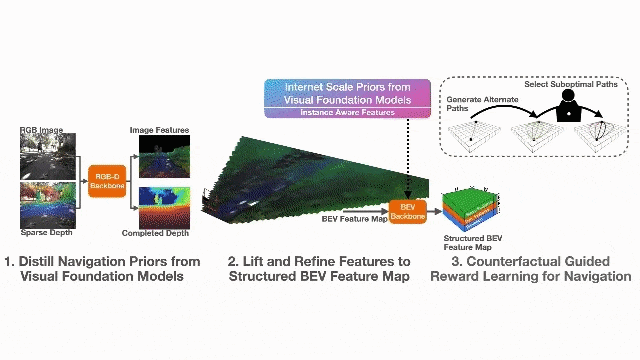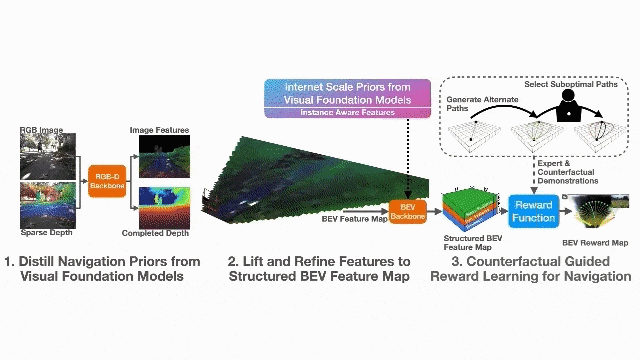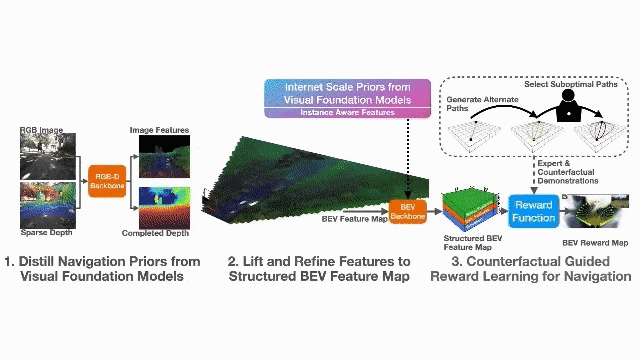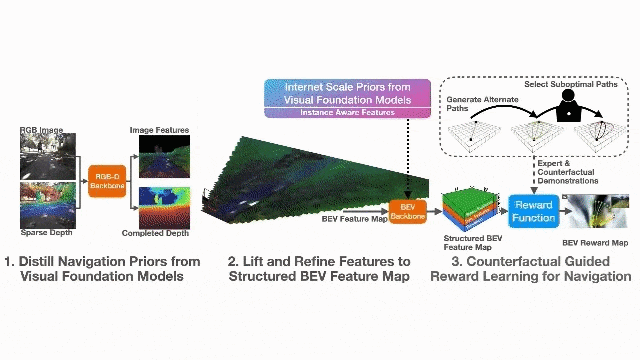
视觉基础模型蒸馏的表征学习(Representation Learning Through Model Distillation):利用在大规模互联网数据上预训练的视觉基础模型(VFM,如DINOv2和SAM2)作为教师模型,通过知识蒸馏将其先验知识迁移到轻量级的图像到BEV地图骨干网络中。具体而言,使用DINOv2的图像特征进行语义蒸馏,使用SAM2的实例标签进行BEV特征的实例一致性约束,从而学习到开放集的语义、几何和实例感知表征。
反事实对齐的奖励学习(Counterfactually Aligned Rewards):提出反事实逆强化学习(Counterfactual IRL)框架,利用反事实轨迹和专家演示共同学习奖励函数。反事实是指保持其他变量不变、仅改变从起点到终点的路径的轨迹。与传统偏好学习不同,该方法明确最小化表现出不良行为(如偏离人行横道、驶离路缘坡道等)路径的奖励,使操作员能够通过提供离线反事实反馈来纠正机器人行为。
2.2 系统架构
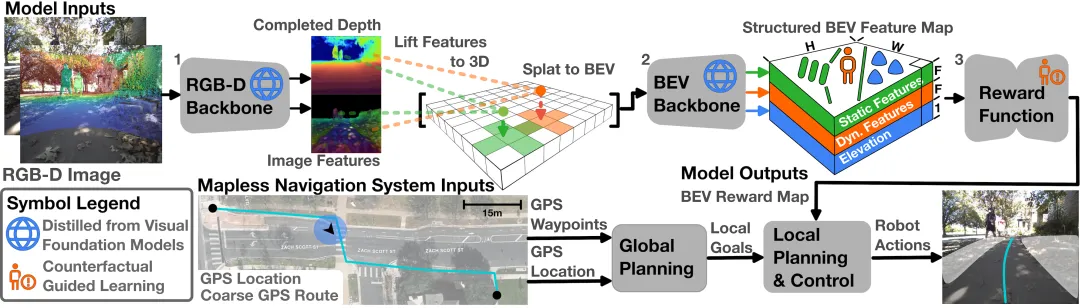
系统的工作流程如下:首先,RGB相机和稀疏深度图通过感知编码器Θ生成完成的深度图和结构化BEV特征图;然后,奖励函数rφ对BEV特征图进行评估,输出BEV奖励图;最后,使用值迭代网络(VIN)求解最优策略,结合GPS目标进行局部路径规划和控制。
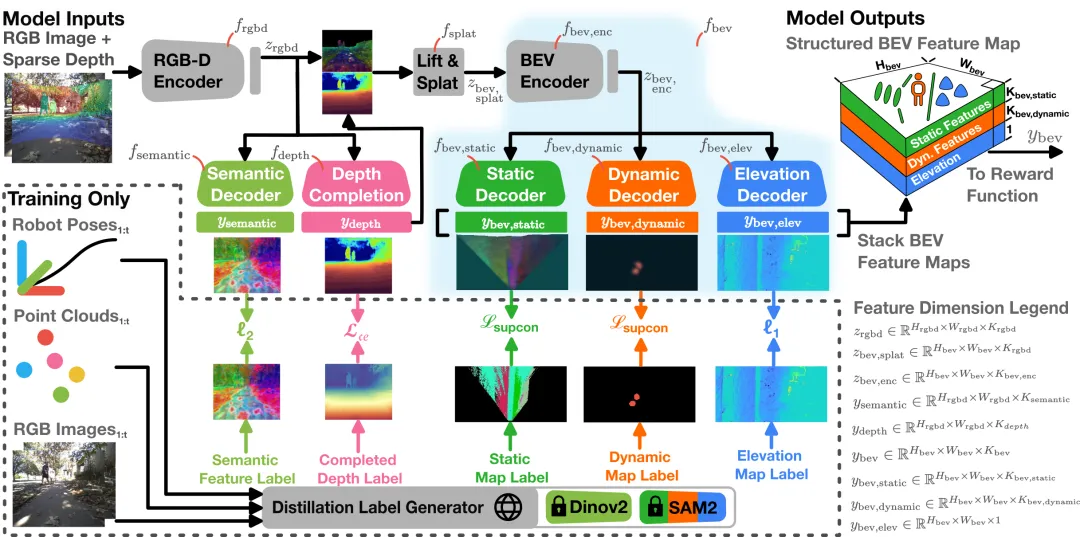
2.3 代码实现架构详解
基于开源代码分析,CREStE的实际实现采用了三阶段训练流程:
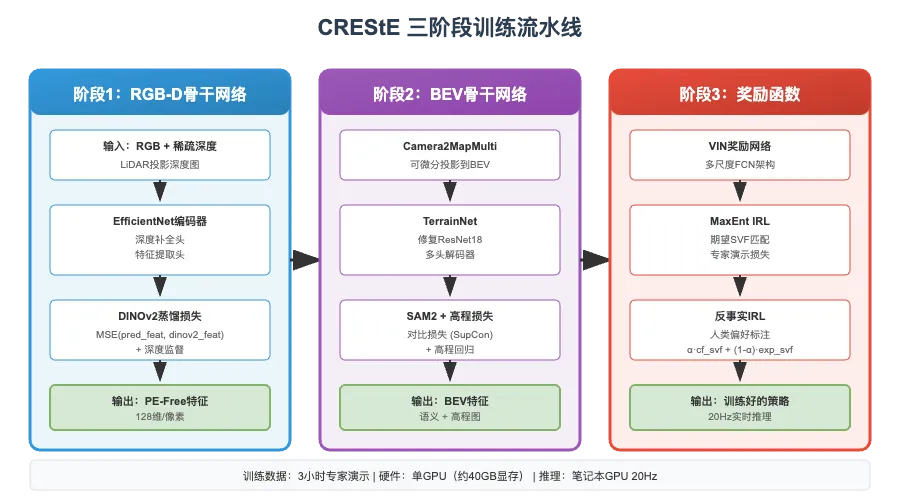
阶段一:RGB-D Backbone训练
• 使用EfficientNet作为编码器骨干 • 通过DINOv2知识蒸馏学习位置无关特征(PE-Free Features) • 同时训练深度补全头
阶段二:BEV Backbone训练
• TerrainNet模块进行BEV语义分割 • 结合SAM2实例标签和高程图监督 • 可微分的Camera2MapMulti投影层
阶段三:奖励函数训练
• MaxEnt IRL配合反事实标注 • VIN模块进行值迭代求解策略
3. 感知编码器:互联网先验的力量
3.1 为什么选择预训练视觉编码器
传统的机器人视觉系统通常从头训练视觉编码器,或者使用在ImageNet等数据集上预训练的模型。然而,这些方法存在明显的局限性:
• 从头训练需要大量的机器人导航数据,数据采集成本高昂 • ImageNet预训练模型主要针对物体分类任务,可能缺乏对空间结构和导航相关特征的建模
CREStE选择使用DINOv2作为感知编码器。DINOv2是一种基于自监督学习的视觉模型,在互联网规模的图像数据上进行训练,学习到了丰富的视觉语义特征。研究表明,DINOv2的特征在多种视觉任务上表现出色,包括语义分割、深度估计等与导航密切相关的任务。
3.2 特征提取过程
CREStE使用自定义的ViTExtractor类加载DINOv2模型,通过torch.hub获取预训练权重:
# creste/utils/feature_extractor.pyclass ViTExtractor(nn.Module): """ViT特征提取器,支持DINO v1/v2""" def __init__(self, model_type: str = "dinov2_vitb14", stride: int = 7): super().__init__() self.model_type = model_type # 通过torch.hub加载DINOv2模型 self.model = self.create_model(model_type) self.model = self.patch_vit_resolution(self.model, stride=stride) self.model.eval() # 图像预处理参数 self.mean = (0.485, 0.456, 0.406) self.std = (0.229, 0.224, 0.225) @staticmethod def create_model(model_type: str) -> nn.Module: if "dinov2" in model_type: # 加载DINOv2(支持register版本) model = torch.hub.load("facebookresearch/dinov2", model_type) elif "dino" in model_type: model = torch.hub.load("facebookresearch/dino:main", model_type) return model def extract_descriptors(self, batch, layer, facet="key", include_cls=False): """ 提取ViT描述符 Args: batch: [B, C, H, W] 归一化的RGB图像 layer: 提取特征的层索引(dinov2使用第11层) facet: 'key'|'query'|'value'|'token' Returns: descriptors: [B, 1, num_patches, dim] 特征描述符 """ self._extract_features(batch, layer, facet) x = torch.concat(self._feats) if not include_cls: x = x[:, :, 1:, :] # 移除CLS token desc = x.permute(0, 2, 3, 1).flatten(start_dim=-2, end_dim=-1).unsqueeze(dim=1) return descdef extract_vit_features(extractor, img_path, input_shape): """提取ViT特征的辅助函数""" # 预处理 prep = transforms.Compose([ transforms.ToTensor(), transforms.Resize(input_shape), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) img = Image.open(img_path).convert("RGB") img_th = prep(img).unsqueeze(0).cuda() # 提取第11层的key特征 with torch.no_grad(): descriptors = extractor.extract_descriptors(img_th, [11], "key", include_cls=False) return descriptors # [B, 1, H*W, F]使用torch.hub.load加载官方DINOv2权重,支持自定义stride调整特征图分辨率(dinov2使用stride=7),通过提取key特征(第11层)作为视觉描述符,并且特征经PCA降维到128维用于后续处理
这种设计的优势在于:DINOv2在大规模数据上学习到的特征具有很强的泛化能力,能够在不同的场景、光照条件下保持稳定的表征。这为后续的奖励模型提供了可靠的输入基础。
3.3 为什么冻结编码器
CREStE的一个重要设计选择是冻结预训练编码器的参数,而不是在导航任务上进行微调。这一选择基于以下考虑:
保持泛化能力:微调可能导致模型过拟合到特定的训练环境,损害其在新环境中的泛化能力。冻结编码器确保了特征提取的一致性。
计算效率:冻结编码器减少了需要训练的参数数量,加快了训练速度,也降低了内存需求。
模块化设计:冻结编码器使得BEV骨干网络和奖励模型可以独立优化,简化了系统的训练流程。
3.4 DistillationBackbone代码实现
CREStE的实际实现使用DistillationBackbone类作为感知编码器,关键代码结构如下:
# creste/models/distillation.pyclass DistillationBackbone(nn.Module): def __init__(self, model_cfg: DictConfig): super().__init__() # 深度补全骨干网络(EfficientNet) self.depthcomp = DepthCompletion(self.model_cfg) # 可选的可学习位置编码 if self.pe_map_cfg is not None: self.learnable_pe_map = nn.Parameter( 0.05 * torch.randn(1, fdn_embed_dim//2, H, W), requires_grad=True, ) self.pe_head = nn.Sequential( nn.Conv2d(fdn_embed_dim//2, fdn_embed_dim, kernel_size=1), nn.BatchNorm2d(fdn_embed_dim), ) # DINOv2特征预测头 self.dino_head = MultiLayerConv(distillation_cfg.feature_head) def forward(self, x): # 1. 深度补全 outputs = self.depthcomp(rgbd) # 2. PE-Free DINOv2特征预测 dino_feats = self.dino_head(outputs['depth_preds_feats']) # 3. 可选:添加位置编码 if self.pe_map_cfg: dino_pe = self.pe_head(self.learnable_pe_map) dino_pe_feats = dino_feats + dino_pe return outputs4. BEV投影与TerrainNet
4.1 可微分BEV投影
CREStE采用可微分的双线性插值投影(Bilinear Splatting)将相机视角特征投影到鸟瞰图(BEV)坐标系。这是实现端到端训练的关键创新。
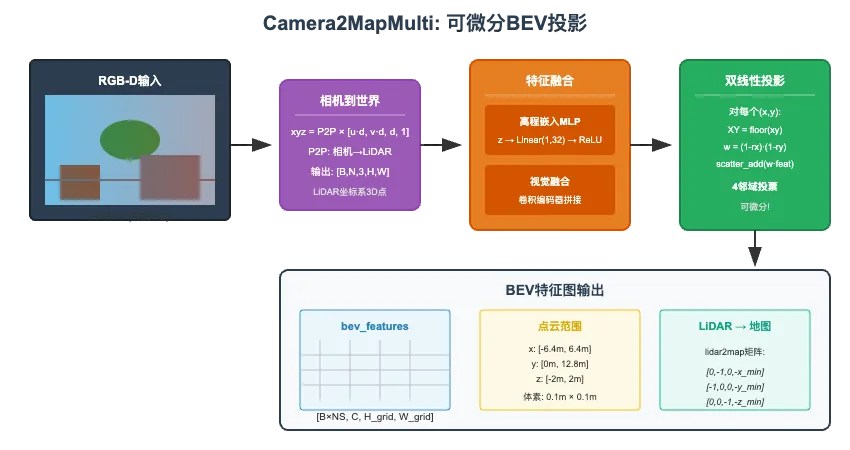
4.2 Camera2MapMulti模块
该模块实现了从相机坐标到BEV地图的可微分投影:
# creste/models/blocks/splat_projection.pyclass Camera2MapMulti(nn.Module): def __init__(self, model_cfg, mode="bilinear", scatter_mode="mean"): super().__init__() # 点云范围配置 self.point_cloud_range = torch.tensor([ -6.4, 0.0, -2.0, # x_min, y_min, z_min 6.4, 12.8, 2.0 # x_max, y_max, z_max ]) self.voxel_size = torch.tensor([0.1, 0.1, 4.0]) # LiDAR到地图坐标变换 self.lidar2map = torch.tensor([ [0, -1, 0, -x_min], [-1, 0, 0, -y_min], [0, 0, -1, -z_min], [0, 0, 0, 1] ]) # 高程嵌入MLP self.z_proj = nn.Sequential( nn.Linear(1, z_embed_dim*2), nn.ReLU(), nn.Linear(z_embed_dim*2, z_embed_dim), nn.ReLU() ) # 视觉特征融合 self.vision_fusion = ConvEncoder(model_cfg.vision_fusion) def forward(self, x): depth, feats, p2p = x[:3] # 1. 相机到世界坐标投影 xyz = self.cam2world((depth, p2p)) # 2. 高程特征嵌入 z_feats = self.z_proj(xyz[:, :, 2]) feats = torch.cat([feats, z_feats], dim=2) # 3. 特征降维融合 feats = self.vision_fusion(feats) # 4. 双线性插值投影到BEV网格 xy = self._points_to_voxels(xyz) splat_feats, splat_densities = self.splat_soft((xy, feats, grid_size)) return {'bev_features': splat_feats, 'bev_densities': splat_densities}4.3 双线性Splatting的数学原理
对于每个3D点,投影到BEV网格后,使用双线性插值权重分配特征到4个相邻网格:
其中是相邻网格坐标。这种方式保证了梯度可以反向传播,实现端到端训练。
def splat_soft(self, x): points_2d, points_features, grid_size = x XY = points_2d.floor().long() # 左上角网格索引 rXY = points_2d - XY # 余数作为权重 for xdiff in (0, 1): for ydiff in (0, 1): # 双线性权重 w = wX * wY # 累加到对应网格 volume_features.scatter_add_(2, idx_valid, w * points_features) # 归一化 volume_features = volume_features / volume_densities.clamp(min_weight)4.4 TerrainNet BEV骨干网络
TerrainNet负责处理BEV特征并输出语义分割和高程估计:
# creste/models/terrainnet.pyclass TerrainNet(nn.Module): def __init__(self, model_cfg): super().__init__() # RGB-D编码器 self.depthcomp = DistillationBackbone(model_cfg) # BEV投影 self.cam2map = Camera2MapMulti(camproj_cfg) # 可选:时序聚合(ConvGRU) if self.use_temporal: self.temporal_layer = MergeUnit(**temporal_cfg) # 多头解码器:语义 + 高程 self.bevclassifier = InpaintingResNet18MultiHead(**bev_cfg) def forward(self, x): rgbd, p2p = x[:2] # 1. RGB-D特征提取 outputs = self.depthcomp(rgbd) # 2. BEV投影 outputs.update(self.cam2map([depth, feats, p2p])) # 3. 时序聚合(可选) if self.use_temporal: outputs['merged_bev_features'] = self.temporal_layer( outputs['bev_features'], t=NS, bos=bos ) # 4. 多头解码:SAM2语义 + 高程 outputs.update(self.bevclassifier(outputs)) return outputs5. 反事实逆强化学习与奖励学习
5.1 反事实IRL的核心思想
CREStE的奖励学习基于反事实逆强化学习(Counterfactual IRL),这是一种主动学习框架。其核心思想是:反事实轨迹保持所有其他变量不变,仅改变从起点到终点的路径。与传统的偏好学习方法不同,反事实IRL明确最小化沿不良路径的奖励(如偏离人行横道、驶离路缘等),同时最大化专家轨迹的奖励。
这种方法的优势在于:
• 样本高效:反事实是比偏好更具体的反馈形式 • 可离线标注:操作员可以离线提供反事实反馈,无需额外的环境交互 • 持续改进:支持数据飞轮,通过额外部署持续改进奖励函数

5.2 反事实IRL数学推导
反事实IRL的目标函数基于Bradley-Terry偏好模型推导。定义状态-动作访问分布为在策略下到达状态并执行动作的折扣概率。
专家的奖励函数应满足排序,即专家的访问分布获得的回报大于等于其他策略。这一性质可扩展到任意次优访问分布的凸组合:
其中为次优(反事实)访问分布。最终的反事实IRL优化目标为:
当时,退化为标准的学徒学习目标;当时,变为纯偏好学习。
5.3 MaxEntIRL实现详解
CREStE采用最大熵逆强化学习(MaxEnt IRL)结合反事实标注进行奖励学习:
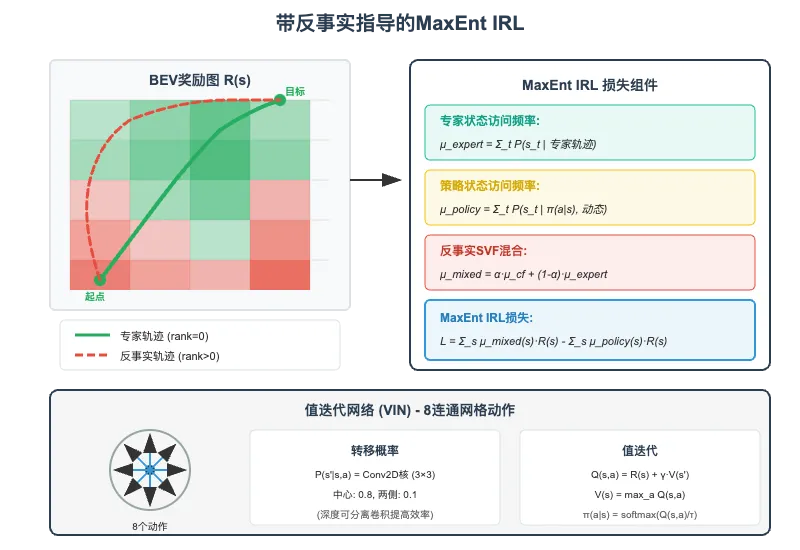
# creste/models/lfd.pyclass MaxEntIRL(nn.Module): def __init__(self, model_cfg): super().__init__() # BEV骨干网络(冻结) self.backbone = TerrainNet(backbone_cfg) # 值迭代网络(VIN) self.traversability_head = VIN(**traversability_head_cfg) # 8连通动作空间 self.dynamics = torch.tensor([ [-1, -1], [-1, 0], [-1, 1], [0, -1], [0, 1], [1, -1], [1, 0], [1, 1] ]) # 转移概率卷积核(深度可分离卷积) self.transition_probs = torch.zeros(8, 1, 3, 3) # center: 0.8, sides: 0.1 def expected_state_visitation_frequency(self, policy, expert): """ 计算期望状态访问频率(Expected SVF) 使用深度可分离卷积高效实现状态传播 """ for t in range(1, self.action_horizon): # 将终止状态SVF设为0(重要!) if self.zero_terminal_state: mu[torch.arange(0, B), t-1, S1] = 0.0 # 深度可分离卷积传播 prev_mu = mu[:, t-1].view(B, 1, H, W) policy_mu = policy_2d * prev_mu new_mu = F.conv2d( policy_mu, self.transition_probs, stride=1, padding=1, groups=A ) # [B, A, H, W] mu[:, t] = new_mu.sum(dim=1) return mu.sum(dim=1) # [B, H, W]5.4 反事实SVF混合
反事实IRL的核心在于混合专家轨迹和反事实轨迹的状态访问频率:
# creste/utils/loss_utils.py - MaxEntIRLLossdef loss(self, tensor_dict): # 1. 计算专家状态访问频率 xy, svf_expert = self.compute_expert_visitation(gt, self.map_ds, self.map_sz) # 2. 如果有反事实标注,进行SVF混合 if self.cf_key is not None and self.alpha is not None: for cf_dict in cf_dict_list: invalid_traj = cf_dict['trajectories'][cf_dict['rank'] > 0] _, cf_svf = self.compute_expert_visitation(invalid_traj, ...) # 关键:alpha混合 # alpha=0.5 表示专家和反事实各占一半权重 exp_svf = self.alpha * cf_svf + (1 - self.alpha) * exp_svf # 3. MaxEnt IRL损失 svf_rewards = (svf_policy * reward_preds).sum(dim=(1, 2)) exp_svf_rewards = (exp_svf * reward_preds).sum(dim=(1, 2)) visitation_loss = mean_exp_svf_rewards - mean_svf_rewards # 4. 梯度正则化(SMODICE风格) reward_grad = torch.autograd.grad(reward_preds.sum(), state_features, ...) reward_penalty = ((reward_grad.norm(2, dim=1) - 1)**2).mean() return self.maxent_weight * visitation_loss + self.reward_weight * reward_penalty5.5 主动奖励学习框架
CREStE采用三阶段的主动奖励学习框架:
阶段一:预热(Warmstart):仅使用专家演示训练基础奖励函数,此时将设为0。
阶段二:合成反事实生成:使用阶段一学习的奖励函数进行策略rollout,通过Hausdorff距离选择与专家演示偏差较大的样本。对于这些样本,生成与专家共享起点/终点的候选轨迹,由人工标注员选择违反其偏好的轨迹作为反事实。
阶段三:反事实奖励对齐:使用反事实标注和原始专家演示重新训练奖励函数,此时非零以平衡两者的相对重要性。重复阶段二和三直到学习的策略与专家行为收敛。
# creste/utils/loss_utils.py - 反事实轨迹生成的关键逻辑@staticmethoddef compute_expert_visitation(gt, map_ds, map_sz): """ 计算专家状态访问频率 Inputs: gt - [B, T, 3, 3] 专家SE(2)位姿在BEV中的表示 Outputs: interpolated_points - [B, T, 2] 所有访问坐标(xy) visit_counts - [B, H, W] 访问计数(归一化到0-1) """ if gt.ndim == 3: B, T, _ = gt.shape xy = gt else: B, T, _, _ = gt.shape xy = gt[:, :, :2, 2] # 将专家位姿预处理为访问索引 xy = xy / map_ds # 按地图下采样因子归一化 H, W = map_sz # 初始化访问计数 visit_counts = torch.zeros(B, H, W, dtype=torch.float32, device=gt.device) # 计算连续点之间的线段 start_points = xy[:, :-1] # [B, T-1, 2] end_points = xy[:, 1:] # [B, T-1, 2] # 计算插值步数 distances = torch.norm(end_points - start_points, dim=-1) # [B, T-1] max_steps = torch.ceil(distances).long().max().item() # 沿线段插值点 t_factors = torch.linspace(0, 1, max_steps, device=gt.device).view(1, 1, -1, 1) interpolated_points = ( start_points.unsqueeze(2) + t_factors * (end_points - start_points).unsqueeze(2) ) # [B, T-1, max_steps, 2] interpolated_points = interpolated_points.view(B, -1, 2) # 累加访问计数 x_coords = interpolated_points[:, :, 0].clamp(0, H - 1).long() y_coords = interpolated_points[:, :, 1].clamp(0, W - 1).long() linear_indices = x_coords * W + y_coords flat_visit_counts = visit_counts.view(B, -1) flat_visit_counts.scatter_add_( 1, linear_indices, torch.ones_like(linear_indices, dtype=torch.float32) ) # 移除多次访问的位置 flat_visit_counts[flat_visit_counts > 1] = 1 visit_counts = flat_visit_counts.view(B, H, W) return interpolated_points, visit_counts6. 值迭代网络(VIN)
6.1 VIN模块实现
CREStE使用值迭代网络进行策略求解,这是一种可微分的规划模块:
# creste/models/blocks/vin.pyclass VIN(nn.Module): def __init__(self, reward_cfg, qvalue_cfg): super().__init__() self.discount = qvalue_cfg.get('discount', 0.95) # 奖励网络(MultiScaleFCN) self.r = MultiScaleFCN(reward_cfg) # 8连通动作转移核 self.w = torch.zeros(8, 1, 3, 3) # 每个动作对应不同的3x3卷积核 # center: 0.8, left: 0.1, right: 0.1 def value_iteration_manual(self, r, goal, threshold=0.001, discount=0.95): """ 手动实现值迭代算法 """ v = torch.zeros_like(r) delta = torch.inf while delta > threshold: old_v = v.clone() # Q值 = R + γ * V'(通过卷积实现状态转移) q = F.conv2d(r + old_v * discount, self.w, stride=1, padding=1) new_v = q.max(dim=1, keepdim=True)[0] delta = (new_v - old_v).abs().max().item() v = new_v # 策略 = softmax(Q) q = F.conv2d(r + v * discount, self.w, stride=1, padding=1) policy = F.softmax(q - q.max(dim=1, keepdim=True)[0], dim=1) return v, policy, q def forward(self, feat_map, S, solve_mdp=False): # 1. 从BEV特征预测奖励图 r = self.r(feat_map) # [B, 1, H, W] if solve_mdp: # 2. 值迭代求解 v, policy, q = self.value_iteration_manual(r, S[:, -1]) return {'policy': policy, 'q_estimate': q, 'traversability_preds': r} return {'traversability_preds': r}6.2 8连通网格动作空间
VIN使用8连通网格作为离散动作空间,每个动作对应一个方向:
转移概率使用3x3卷积核建模,中心概率0.8,两侧概率各0.1,表示执行动作时的不确定性。
7. 部署与实时推理
7.1 模型编译与TorchScript
CREStE支持将训练好的模型编译为TorchScript格式,用于C++实时部署:
# 下载数据字典wget <https://web.corral.tacc.utexas.edu/texasrobotics/web_CREStE/public_datasets/data_dict_creste_19_4830.pkl> \\ -O ./scripts/runtime/data_dict.pkl# 编译模型export CKPT_PATH=model_ckpts/TraversabilityLearning/.../Adam-epoch=05.ckptpython scripts/runtime/compile.py \\ 'model=traversability/inference/terrainnet_maxentirl_msfcn_sam2dynsemelev' \\ 'model.weights_path=$CKPT_PATH'# 输出:scripts/runtime/creste_rgbd_trace.pt7.2 C++实时推理库
官方提供了独立的C++推理库 creste_realtime:
• ROS1集成:直接订阅相机和LiDAR话题 • 无Python依赖:纯C++实现,部署简单 • 20Hz推理:在笔记本GPU上实现实时运行
git clone <https://github.com/ut-amrl/creste_realtime># 按照README配置编译7.3 数据准备
# 1. 生成深度图python scripts/preprocessing/build_dense_depth.py \\ --cfg_file ./configs/dataset/creste.yaml \\ --out_dir ./data/creste --scans 0 --proc LAIDW# 2. 提取DINOv2特征python scripts/preprocessing/create_pe_dataset.py \\ --input_dir data/creste --output_dir data/creste \\ --model_type dinov2 --img_shape 512,612 --feat_dim 128# 3. 生成SAM2实例标签./scripts/preprocessing/create_sam_creste.sh 4 8 0 static./scripts/preprocessing/create_sam_creste.sh 4 8 0 dynamic# 4. 生成BEV高程图python scripts/preprocessing/build_feature_map.py \\ --cfg configs/dataset/distillation/creste_pefree_dinov2.yaml \\ --out_dir data/creste/sam2_map --feat_type geometric --tasks elevation7.4 三阶段训练
# Stage 1: RGB-D Backbonepython creste/train_pefree.py \\ 'dataset=distillation/creste_pefree_dinov2' \\ 'model=distillation/effnet_ds2_dinov2_128' \\ 'model.batch_size=16'# Stage 2: BEV Backboneexport VISION_BACKBONE_WEIGHTS_PATH=model_ckpts/Dinov2Distillation/.../Adam-epoch=49.ckptpython creste/train_ssc.py \\ 'model.batch_size=16' '+model.freeze_backbone_epochs=5' \\ model.vision_backbone.weights_path=$VISION_BACKBONE_WEIGHTS_PATH# Stage 3: Reward Functionexport BEV_BACKBONE_WEIGHTS_PATH=model_ckpts/TerrainNetSAM/.../Adam-epoch=42.ckpt./scripts/traversability/train_creste.sh \\ --weights_path $BEV_BACKBONE_WEIGHTS_PATH \\ --alpha 0.5 --reward_weight 1.0 --horizon 508. 结论
CREStE代表了机器人视觉导航领域的一次重要突破。通过充分利用视觉基础模型(VFM)蒸馏学习开放集BEV表征,结合反事实逆强化学习(Counterfactual IRL)进行奖励对齐,该方法实现了仅需3小时专家演示的可扩展无地图导航,并在多种城市、越野和住宅环境中展现出优越的泛化能力,相比现有方法减少了70%的人工干预。
更多ROS、具身智能相关内容,请关注古月居
👉 关注我们,发现更多有深度的自动驾驶/具身智能/GitHub 内容!
🚀 往期内容回顾 👀
🔥 具身智能 | 机器学习分类全面指南:从迁移学习到联邦学习🔥 十分钟实用教程 | 不用服务器也能玩OpenClaw?——基于Ollama的边缘AI协作实战🔥 十分钟实用教程 | Uni-NaVid使用和仿真环境搭建

