原文题目:ARTEMIS: Autoregressive End-to-End Trajectory Planning with Mixture of Experts for Autonomous Driving作者:冯仁炬,郗宁,褚端峰,邓泽健,王安政,陆丽萍,王金湘,黄岩军来源:Feng R, Xi N, Chu D, et al. Artemis: Autoregressive end-to-end trajectory planning with mixture of experts for autonomous driving[J]. IEEE Robotics and Automation Letters, 2025, 11(1): 226-233.01
摘要
本文提出了一种端到端自动驾驶框架ARTEMIS,该框架创新性地将自回归轨迹规划与混合专家模型(Mixture-of-Experts,MoE)架构相结合。传统的模块化方法容易产生误差传播,而现有的端到端模型通常采用静态的单次推理范式,难以充分捕捉环境的动态变化。ARTEMIS采用了一种全新的方法,通过顺序生成轨迹路点,不仅保留了关键的时间依赖性,还能根据具体场景动态地将特征查询路由到特定的专家网络中。这种方法有效缓解了引导信息模糊时经常遇到的轨迹质量下降问题,并克服了单一网络架构在处理多样化驾驶场景时的表征局限性。此外,我们采用了一种轻量级的批次重分配策略,显著提升了MoE模型的训练速度。在NAVSIM数据集上的大量实验表明,ARTEMIS展现出了卓越的性能,以ResNet-34为主干网络实现了86.9的PDMS和83.1的EPDMS,在多项核心指标上达到了SOTA(State-of-the-Art)性能。02
研究背景及意义
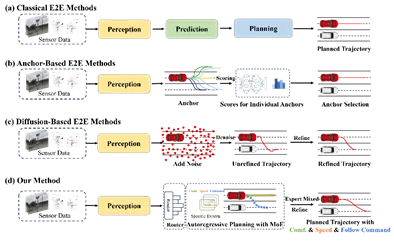
图1四种端到端架构自动驾驶技术近年来经历了蓬勃的发展。传统的模块化方法将自动驾驶任务划分为感知、预测和规划等独立模块,但模块间的累积误差和复杂依赖往往会成为系统性能的瓶颈。端到端模型通过将传感器数据直接映射为规划轨迹克服了这些问题,但它们静态的、单次生成的推理范式往往无法捕捉环境的动态演变。相较之下,自回归方法通过顺序生成轨迹,保留了时间连贯性,使得模型能够基于先前规划的片段进行自适应决策。然而,目前面临的挑战是:单网络的端到端模型依然难以充分适应复杂多变的驾驶场景。在自动驾驶中,车辆在相同环境条件下可能有多种合理的未来动作选择,驾驶行为本身具有内在的多模态与不确定性。为了应对这种复杂性,我们将混合专家(MoE)架构引入端到端轨迹规划中。MoE使得不同的专家模块能够专注于特定的驾驶场景或行为模式,从而无需依赖强先验约束即可学习真实的驾驶特征分布,有效避免了由于引导信息偏差导致的轨迹质量退化。03
整体框架
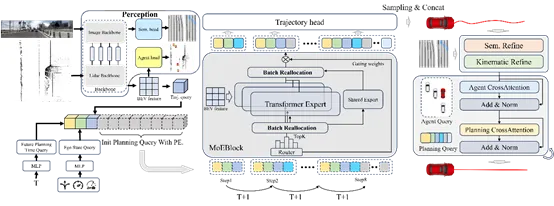
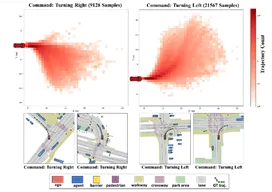
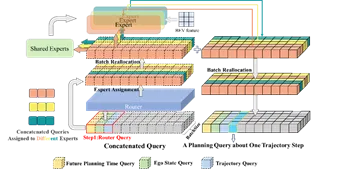
ARTEMIS的总体框架主要由三个核心组件构成:感知模块、带有MoE的自回归规划模块,以及轨迹优化模块。图2 ARTEMIS整体框架图感知模块采用了Transfuser的架构设计,负责从原始传感器数据中提取特征。该模块使用独立的主干网络分别处理图像和激光雷达点云数据,随后通过Transformer在不同阶段进行多模态特征融合,最终构建出统一的鸟瞰图(BEV)特征表示。有别于传统的单次生成,该模块逐步构建轨迹路点,这需要模型融合历史规划信息,并根据当前场景特征动态分配计算资源。图3控制指令与实际表现不符的部分场景解决指令偏差与因果混淆:在真实数据集中(如navtrain),我们观察到驾驶指令分布存在严重的不平衡,且部分训练样本的控制指令与专家实际轨迹存在矛盾。如果单纯依赖驾驶指令来选择专家网络,会导致部分专家训练不足。因此,ARTEMIS仅将当前的自车状态(如控制命令、二维速度和加速度)编码进入特征空间,以防模型产生“因果混淆”。位置与时间嵌入机制:规划序列在首次自回归步骤中加入了位置嵌入,以引入序列的空间位置信息,同时每个规划时间步都会加入时间嵌入。数据驱动的隐式路由:我们摒弃了基于人类显式规则(如左转、直行标签)的硬性路由方案。因为规则往往难以覆盖所有的长尾场景,导致在未定义的边界情况下专家分配呈现“妥协性”。ARTEMIS采用数据驱动的隐式路由,允许路由器网络直接从高维场景特征中学习最优的特征空间微观划分,大幅提升了模型的鲁棒性。批次重分配:针对MoE 模型计算效率问题,我们提出了一种高效的批次重组策略。在计算出每个专家的激活分数并选取Top-k 后,系统会根据专家索引对批次样本进行排序和数据重组,将激活相同专家的序列块整合在一起进行矩阵运算,运算完成后再通过逆向重组恢复原始批次顺序。这在处理大规模数据时极大降低了算力开销。图4批次重分配操作由于真实的驾驶场景极为复杂且常伴有与规划无关的噪声,我们引入了轨迹优化模块,以确保最终生成的轨迹满足运动学约束、避开障碍物并保持平滑。该过程分为“语义运动学优化”和“交叉注意力优化”两个级联阶段,进一步增强了轨迹特征与智能体特征及场景上下文的深度交互。04
实验与分析
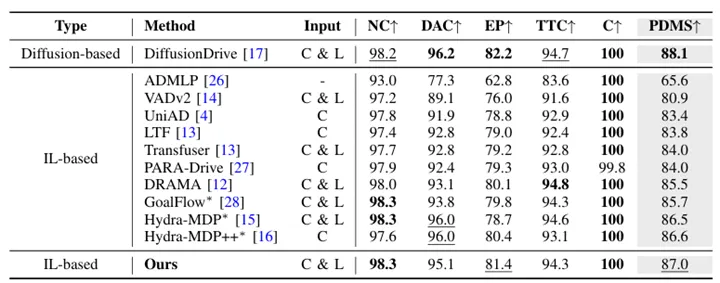
为全面评估ARTEMIS的性能,我们在NAVSIM数据集上进行了大量实验。NAVSIM引入了预测驾驶模型得分(PDMS),该指标与闭环评估具有高度相关性。在Navtest基准测试中,使用相同的ResNet-34主干网络,ARTEMIS在标准评估下获得了86.9的PDMS得分,在无碰撞(NC)、舒适度(C)和自车进度(EP)等核心指标上展现出显著优势,证明了其强大的轨迹规划能力与环境适应性。此外,在包含了车道保持(LK)、交通信号合规(TLC)等扩展指标的EPDMS测试中,ARTEMIS更是以83.1的高分大幅超越了包括Transfuser、VADv2和Hydra-MDP++在内的所有对比基线,确立了领先性能。表1在Navtest基准测试中的测试结果(原始指标)
表2 Navtest基准测试中的测试结果(拓展指标)
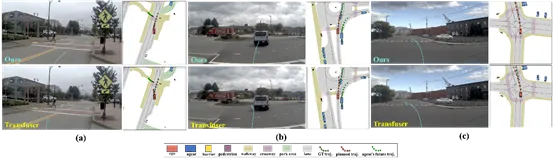
通过可视化模型在实际复杂场景中的表现,我们可以清晰地观察到MoE中不同专家的策略分化。例如:十字路口场景:面对前方路口,专家网络会自发分化为“左转”与“直行”两类探索行为,最终路由网络结合上下文,精准选取了直行专家的方案作为最终规划。环岛场景:在复杂的环岛路况下,尽管多数专家给出了错误的“向右前方行驶”预测,但其中一个特定的专家网络成功捕获了环岛的几何特征并规划了正确的绕行轨迹。系统内在的路由机制准确地赋予了该正确专家最高的权重,完美化解了难题。这些结果充分证明了ARTEMIS内在路由机制的合理性,以及应对多样化驾驶意图和长尾路况时的强悍鲁棒性。图5 ARTEMIS与Transfuser基线的定性对比
图6 ARTEMIS在不同场景的定性展示05
消融实验
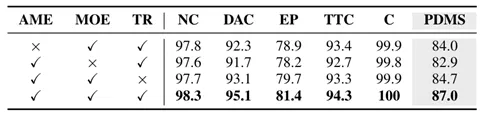
为了严谨地验证ARTEMIS中各个核心设计的有效性,我们在NAVSIM数据集上进行了多维度的消融实验,深入剖析了模型的性能边界与底层机制。我们将模型拆解,分别移除了带有MoE的自回归规划模块(AME)、混合专家模块(MOE)以及轨迹优化模块(TR)。移除自回归模块(AME):模型的PDMS分数显著下降了2.9分。这有力地证明了自回归范式在捕捉路点间时间依赖性、以及适应动态环境演变方面的核心作用。移除混合专家模块(MOE):性能出现了最剧烈的下滑,PDMS骤降4.0分。这直接凸显了MoE架构在动态适应复杂多样驾驶场景与多模态行为模式时的绝对优势。移除级联轨迹优化(TR):PDMS下降2.2分,说明该模块在平滑自回归生成的采样不稳定性、确保运动学可行性上发挥了关键作用。表3核心组件的消融
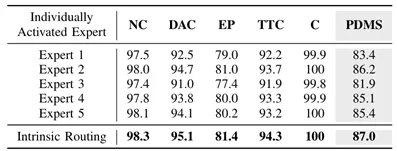
我们强制模型在推理时只激活单一的特定专家(Expert 1至5),结果显示没有任何单个专家能达到最优性能(得分在81.9到86.2之间徘徊,均低于完整模型的86.9)。这证明了路由网络进行动态专家组合的必要性,同时也表明模型在训练过程中没有发生“模式崩溃”,各个专家确实学到了差异化的策略。表4专家的激活情况的消融实验
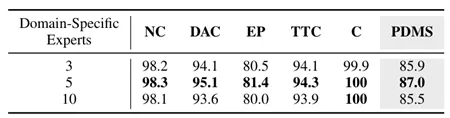
我们探索了领域专用专家的数量对性能的影响。将专家数从3个增加到5个时,模型处理复杂场景的能力增强,性能稳步提升;但当专家数量激增至10个时,性能反而下降了 1.4分。这表明在有限的训练数据下,过多的专家会导致计算资源分散和功能重叠。表5领域专用专家数量的消融实验
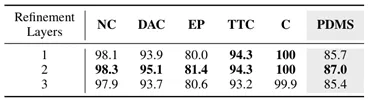
级联层数的边际效应:在轨迹优化模块中,增加交叉注意力层数初期能提升性能,但当层数超过2层时,边际效益递减甚至出现性能轻微回落(3层得分为85.4)。因此,2层级联优化在计算开销与性能之间取得了最佳平衡。表6优化层数的消融实验
06
团队介绍
AgiLab(Agent In-Motion Lab)面向智能无人系统,聚焦智能车辆、无人机、移动机器人等多形态智能体,推动认知智能与具身智能的深度融合。实验室以"数据驱动 与知识引导"为核心方法,围绕大模型推理、具身决策与多智能体协同等方向开展研究,致力于让智能体在物理世界中安全、高效、可解释地行动。
研究方向:
- 环境感知与理解
- 场景建模与空间智能
- 端到端自动驾驶
- 多智能体协同
科研项目:
近年来,主持了各类科研项目20余项,涵盖国家级项目(国家自然科学基金、国家重点研发计划)、省级自然科学基金、省市级重点研发计划等,以及多个企事业单位委托的横向项目。
科研平台:
实验室配备无人车、无人机、机械臂、硬件在环仿真平台、多GPU训练平台等实验条件,全面支撑自动驾驶、具身智能与机器人算法的研发及测试验证工作。
毕业生去向:
团队培养的毕业生广泛就职于华为、阿里、京东、百度、小鹏、零跑、滴滴、东风、长安等行业头部企业,从事核心技术研发。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
