编者语:后台回复“入群”,加入「智驾最前沿」微信交流群
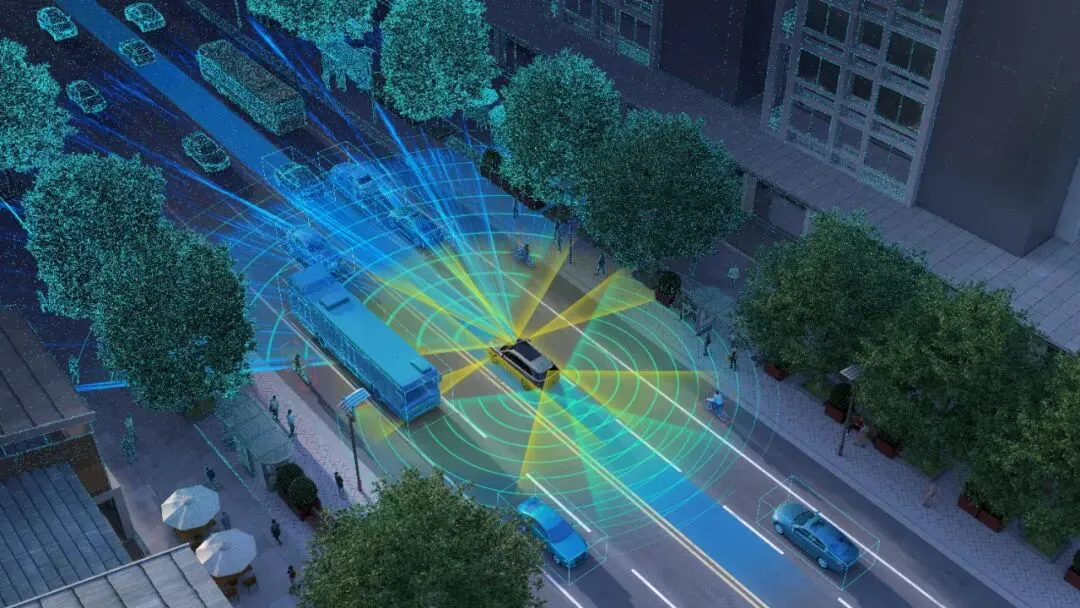
在自动驾驶技术飞速发展的今天,如何让车辆像人类一样感知周围环境,一直是非常重要的话题。无论是摄像头、激光雷达还是毫米波雷达,都存在各自的物理局限性,因此多传感器融合技术成为非常重要的技术方向。
简单来说,融合的目的就是将不同传感器捕捉到的碎片化信息拼凑成一张完整且准确的周围世界地图。而在实现这一目标的过程中,行业内逐渐分化出了两种主要的路径,即前融合与后融合。
传感器融合有何区别?
自动驾驶系统其实配备了多种感官。摄像头擅长识别颜色和纹理,能看清交通标志和红绿灯,但在强光或黑暗中表现不稳定;激光雷达能提供精准的三维空间坐标,却无法分辨颜色;毫米波雷达则对运动物体的速度极为敏感,且不受天气影响,但分辨率较低。
图片源自:网络
多传感器融合的本质,就是把这些优缺点互补的数据结合起来。
多传感器融合的关键在于融合发生的时机。如果把这个过程比作做菜,后融合就像是每个厨师各自做了一道成品菜,最后摆在一起凑成一桌席;而前融合则是在下锅之前,就把所有的食材根据配方切好、拌匀,直接烹饪成一道复合口味的大菜。
这两种不同的处理方式,直接决定了系统对环境理解的深度和广度。
殊途同归的后融合方案
后融合在行业内也被称为目标级融合,是自动驾驶早期最为普遍的做法。在这种模式下,每一个传感器都是一个独立的决策单元。
摄像头会独立识别出前方的行人,激光雷达会独立探测到一个障碍物,毫米波雷达也会测算出物体的速度。每个传感器都先输出自己认定的探测结果,通常表现为一个带有坐标和类别标签的检测框。
当这些独立的检测结果被汇总到主处理器后,系统会根据一套逻辑来判断它们是不是同一个物体。如果摄像头和激光雷达在同一个位置都发现了一个物体,系统就会提高对这个目标的信任度。
图片源自:网络
这种做法的好处显而易见,由于每个传感器各司其职,系统逻辑非常清晰,即便其中一个传感器坏了,也不影响其他传感器的正常工作,整个架构的容错性和可扩展性都很强。
后融合也存在一个致命的弱点,那就是严重的信息丢失。在每个传感器独立处理的过程中,为了降低计算量,就会过滤掉一些“看起来不重要”的原始数据。
这意味着,如果一个物体在单一传感器的视野里特征不够明显,它可能在第一阶段就被过滤掉了,等到最后汇总时,主处理器根本没有机会看到这些被丢弃的关键细节,从而导致漏检或误判。
牵一发而动全身的前融合
与后融合不同,前融合或者说数据级/特征级融合走的是一条完全不同的路。它要求系统在感知阶段的最开始,就将各个传感器获取的原始数据或者提取出来的特征向量直接整合在一起。
此时,系统不再是看一个个独立的检测框,而是面对一个包含了色彩、深度、速度等多个维度的复合数据空间。
在前融合的架构中,系统能够保留最原始、最丰富的信息。由于没有预先过滤,那些在单一传感器中显得模糊的信号,可能在结合了其他传感器的数据后变得清晰起来。
图片源自:网络
如在光线极其微弱的情况下,摄像头看到的可能只是模糊的阴影,但在叠加了激光雷达的点云信息后,系统就能迅速确认那是一个行人的轮廓。这种深度整合极大地提升了系统在极限场景下的感知上限。
不过,前融合的实现难度也成倍增加。由于它对传感器的空间和时间对齐要求极高。如果摄像头的一帧图像和激光雷达的一帧点云在时间上差了几毫秒,或者在空间坐标上差了几厘米,强行融合就会导致识别出的物体出现重影或错位。
此外,前融合需要处理海量的原始数据,这对车辆车载芯片的算力和传输带宽提出了巨大的挑战。
哪种方案更胜一筹?
既然传感器可以前融合,也可以后融合,那哪种方案更具优势?
其实在讨论哪个技术更具优势时,并不能简单地一概而论。在很长一段时间里,后融合凭借着架构简单、对算力要求低以及易于调试的优势,占据了自动驾驶落地的主流地位。它在传感器性能和算力有限的阶段,提供了最可靠的保障。
但随着人工智能模型和高性能芯片的迭代,行业的天平正在向着前融合偏移。目前备受关注的鸟瞰图(BEV)感知和占用网络等技术,本质上都是前融合思想的延伸。
图片源自:网络
这些技术通过将摄像头、雷达的数据统一转换到一个标准的三维空间坐标系中进行处理,不仅解决了单一传感器看不清的问题,还让车辆学会了如何像人脑一样,在脑海中实时构建一个连贯的动态环境。
总的来说,后融合依然是目前许多量产车型实现辅助驾驶的基础,因为它稳定且低成本。但如果我们的目标是实现更高级别的自动驾驶,前融合所带来的感知精度和鲁棒性则是不可或缺的。未来或许在不同感知层级上进行多重融合,既保留前融合的敏锐,又兼顾后融合的稳健,从而让自动驾驶系统在各种复杂工况下都能做出正确的决策。
-- END --





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
