
🐉 龙哥读论文知识星球来了!公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
在自动驾驶中,识别出没见过的障碍物是关乎安全的核心挑战。本文巧妙地利用“物体家族树”的概念,在双曲空间中学习语义层级,让模型能通过“它是动物,不是汽车”这种抽象推理来识别未知物体,思路新颖且效果拔群,是开放世界感知方向的一篇高质量工作。
原论文信息如下:论文标题: Hyp2Former: Hierarchy-Aware Hyperbolic Embeddings for Open-Set Panoptic Segmentation
发表日期:
2026年5月
发表单位: 弗莱堡大学计算机科学系、博世研究院
原文链接: https://arxiv.org/pdf/2605.02580v1.pdf
1. 🚗 开放世界感知的痛点:如何识别“没见过”的目标?
想象一下,你正坐在自动驾驶汽车里,系统突然遇到一个刚从卡车上掉落的行李箱。这个行李箱在训练数据里从来没见过——AI之前只知道"汽车"、"行人"、"自行车"。它应该怎么做?是当背景忽略?还是识别成"未知物体"然后紧急刹车?
这个问题就是开放集全景分割(Open-Set Panoptic Segmentation,OPS)要解决的核心难题。传统的神全分割(Panoptic Segmentation,PS)模型像坐井观天,只认识训练时见过的类别,遇到新东西就一脸懵。而OPS要求模型不仅能分割出已知的"thing类"(例如狗、汽车)和"stuff类"(天空、道路),还要把没见过的有效物体也分割成独立的"未知"实例。
现有的OPS方法问题可不少。它们往往把已知类别当成一堆互不相干的标签(就像把"猫"、"狗"、"桌子"当成三个独立的东西),完全忽略了它们之间的语义关系——比如"猫"和"狗"都属于"动物",而"桌子"属于"家具"。
更麻烦的是,很多方法依赖像素级的异常检测——先找出"异常区域",然后再聚类成实例。这就像硬要把拼图碎片先分类再拼起来,处理不好就支离破碎。分布偏移(distributional shift)发生的时候,系统常常把一大片OOD(out-of-distribution,分布外)的路面也当成未知物体,结果假阳性满天飞。
那怎么办呢?弗莱堡大学和博世研究院的研究者们想到了一个反直觉的点子:不直接训练模型去识别"未知",而是让模型学会"物体的家族树"。一旦模型理解了"狗→动物→物体"这样的层次关系,那遇到没见过的新物种,比如"老虎",虽然它不知道老虎的具体名字,但能推理出"这玩意儿更靠近动物而非汽车"——于是就可以放心地把它标记为未知物体。这个思路,有点天才啊。图1: 提出的Hyp2Former整体架构。多尺度特征从骨干网络提取,经像素解码器和Transformer解码器处理。可学习的查询嵌入被送入分类头F_cls和掩码头F_mask,同时被投影到双曲空间中,显式的语义层级指导层级代理锚点损失L_hyp,构建出结构化嵌入空间。2. 🛠️ 核心创新:在双曲空间学习“物体家族树”
为了让模型学会"物体家族树",先得解决一个关键问题:在哪种空间里表示"家族树"最自然?
我们平时熟悉的欧氏空间(Euclidean space)是"平坦"的,适合表示平面关系。但层级树结构有一个特点:越往深处走,节点数量呈指数级增长。例如,"物体"下面有"动物"、"交通工具"……"动物"下面又有"狗"、"猫"、"鸟"……欧氏空间的体积是多项式增长的,兜不住这种指数增长的树,会产生严重扭曲。
这时候就要请出双曲空间(Hyperbolic Space)了。双曲空间是负曲率的,就像马鞍面或喇叭花的形状,它的体积是指数级增长的。这跟树层级结构的指数增长完美契合。打个比方:在欧氏空间里画一棵树,越往深层枝干越挤;但在双曲空间里,越往外围越宽阔,自然就能把树画得清清楚楚。这就是为什么用双曲空间表示层级结构比欧氏空间更"舒适"。
基于这个洞察,本文提出Hyp2Former——一个把双曲空间层级表示学习用到开放集全景分割上的框架。论文使用了双曲空间的洛伦兹模型(Lorentz model)。在这个模型中,每个点用一个n+1维向量表示,分为"空间部分"和"时间部分"。洛伦兹内积为:
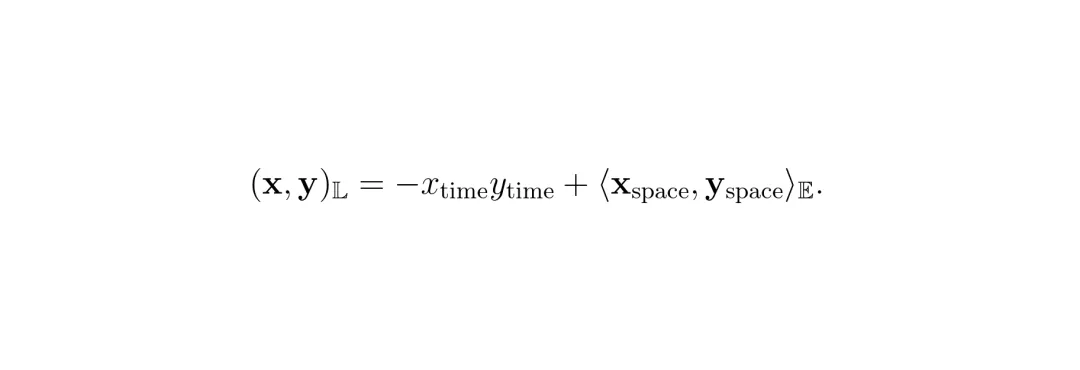 其中x和y是点,下标time是时间分量,space是空间分量,⟨·,·⟩_E是欧氏内积。定义在曲率为-c(c>0)的洛伦兹模型上的点集合为:
其中x和y是点,下标time是时间分量,space是空间分量,⟨·,·⟩_E是欧氏内积。定义在曲率为-c(c>0)的洛伦兹模型上的点集合为: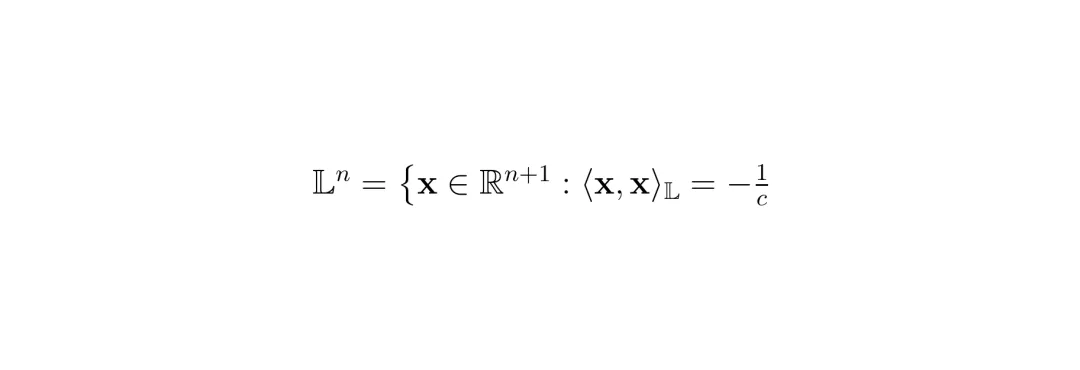
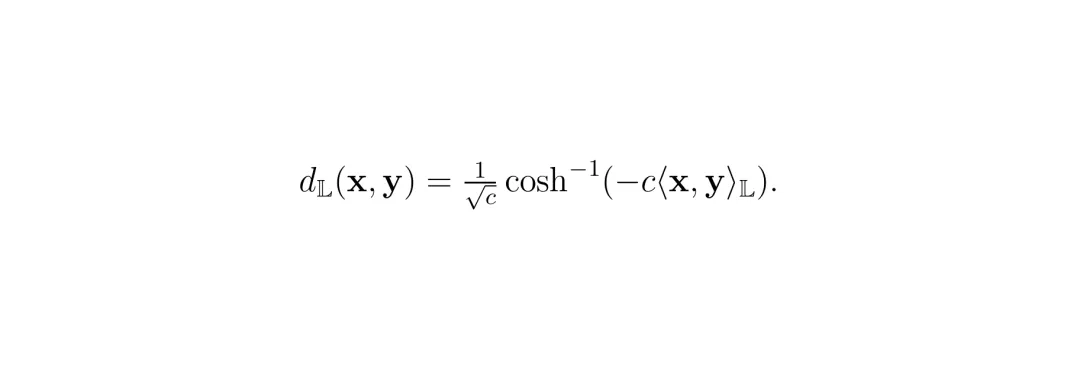 要把欧氏空间里的查询嵌入向量v搬到双曲流形上,需要用到指数映射(exponential map):
要把欧氏空间里的查询嵌入向量v搬到双曲流形上,需要用到指数映射(exponential map):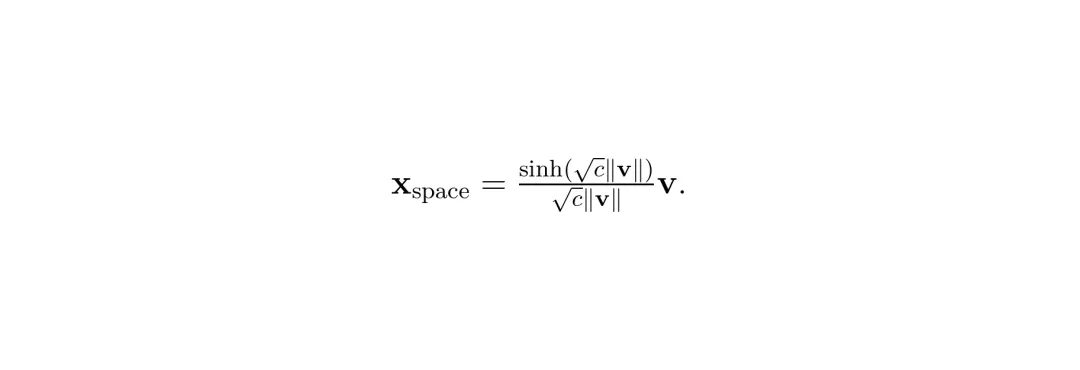 再把时间分量算出来,就得到了洛伦兹模型上的点。看起来有点数学,但通俗地说:双曲空间给了我们一个"天然适合画家族树"的画板。
Hyp2Former基于Mask2Former改造,保持了分类和掩码分支在欧氏空间中的标准损失,保证已知类别的精度不下降。同时在并行分支中,将查询嵌入投影到双曲空间,并引入一个层级代理锚点损失(Hierarchical Proxy-Anchor Loss)。
具体来说,对于每个已知类别,在双曲空间里定义一个可学习的锚点(proxy)。同时,按预设的语义层级(例如COCO的4级层级),将高层概念(如"动物")的锚点作为其子类别(如"狗"、"猫")的祖先锚点动态计算出来(通过双曲均值)。损失函数包含两项:
再把时间分量算出来,就得到了洛伦兹模型上的点。看起来有点数学,但通俗地说:双曲空间给了我们一个"天然适合画家族树"的画板。
Hyp2Former基于Mask2Former改造,保持了分类和掩码分支在欧氏空间中的标准损失,保证已知类别的精度不下降。同时在并行分支中,将查询嵌入投影到双曲空间,并引入一个层级代理锚点损失(Hierarchical Proxy-Anchor Loss)。
具体来说,对于每个已知类别,在双曲空间里定义一个可学习的锚点(proxy)。同时,按预设的语义层级(例如COCO的4级层级),将高层概念(如"动物")的锚点作为其子类别(如"狗"、"猫")的祖先锚点动态计算出来(通过双曲均值)。损失函数包含两项:
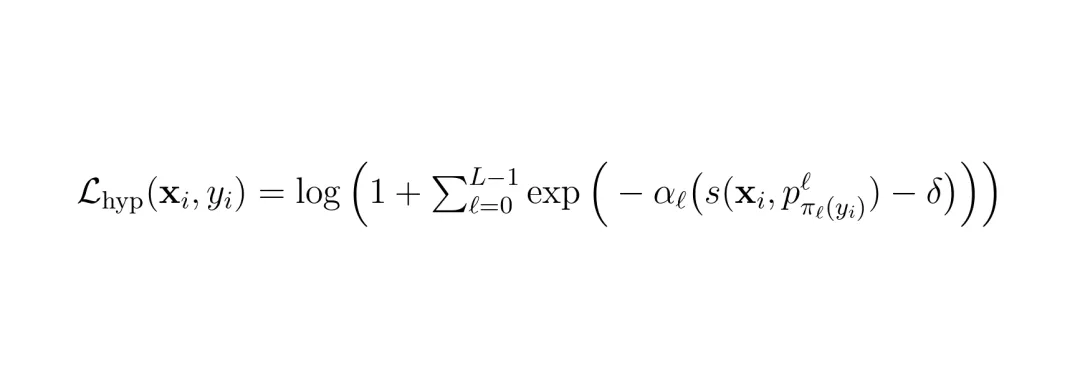
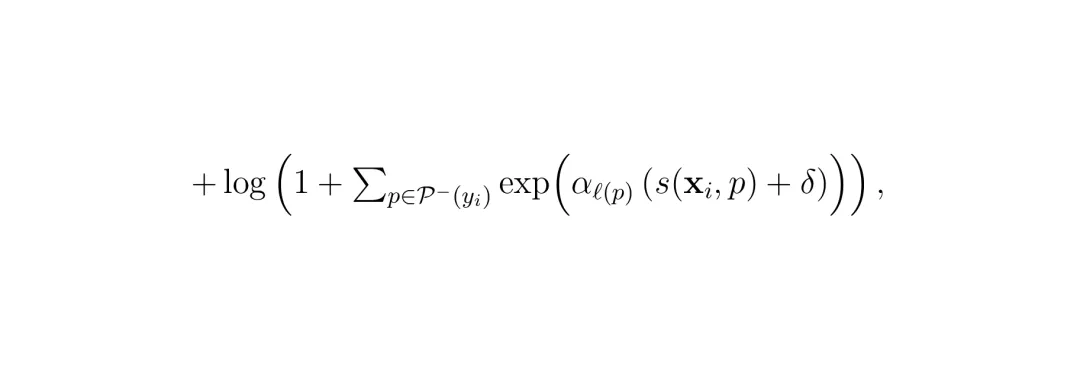 第一项拉近嵌入与正样本锚点(包括类别本身的锚点及其所有祖先锚点)的距离,第二项推开与所有负样本锚点的距离。α是层级相关的缩放因子(叶子层α大,祖先层α小),δ是间隔。最终总损失为:
第一项拉近嵌入与正样本锚点(包括类别本身的锚点及其所有祖先锚点)的距离,第二项推开与所有负样本锚点的距离。α是层级相关的缩放因子(叶子层α大,祖先层α小),δ是间隔。最终总损失为: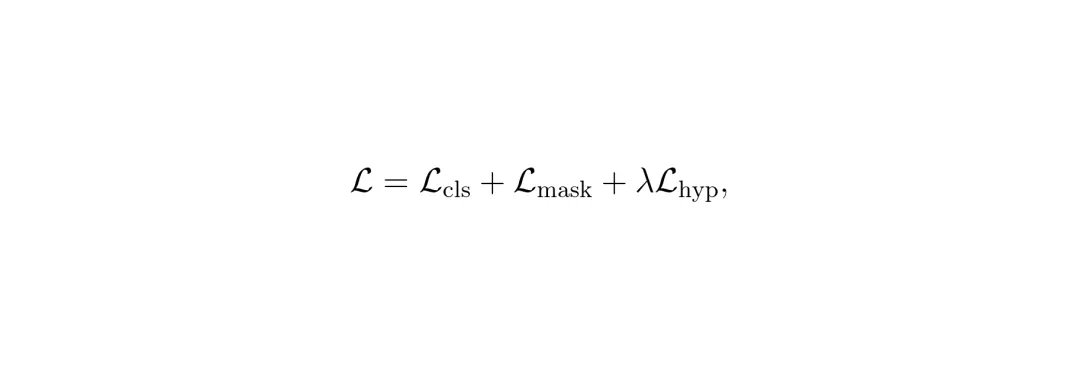 λ是平衡权重。这样,学习到的嵌入空间就结构化了:同类实例靠近叶子锚点,相似类别的实例靠近共同的祖先锚点,完全不同类别的实例相距很远。
推理时,Hyp2Former不再只保留高置信度的已知类别查询。它对所有查询先做一次物体一致性检查:如果该查询在双曲空间中最近的锚点属于"物体子树"(thing子树),就认为是物体候选。再计算一个层级分数S_hier和发散分数S_div,最终物体性分数为:
λ是平衡权重。这样,学习到的嵌入空间就结构化了:同类实例靠近叶子锚点,相似类别的实例靠近共同的祖先锚点,完全不同类别的实例相距很远。
推理时,Hyp2Former不再只保留高置信度的已知类别查询。它对所有查询先做一次物体一致性检查:如果该查询在双曲空间中最近的锚点属于"物体子树"(thing子树),就认为是物体候选。再计算一个层级分数S_hier和发散分数S_div,最终物体性分数为: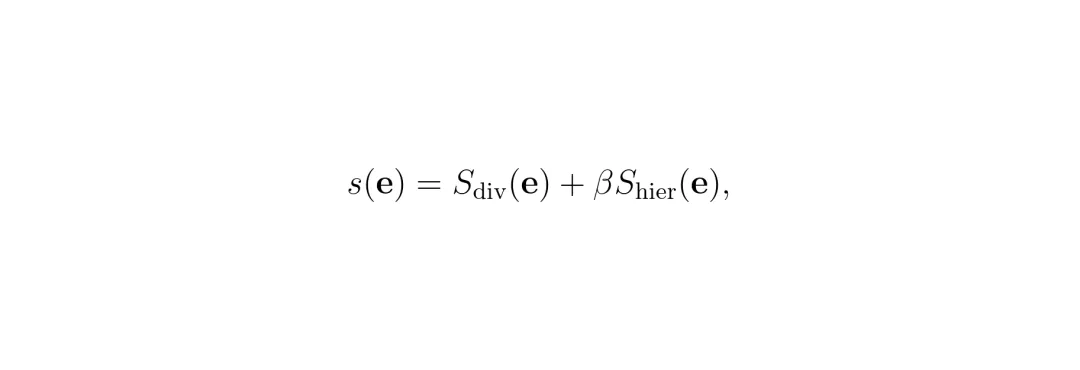 排名靠前的候选被选为未知实例,参与最终的掩码竞争。这种方式让未知物体直接从嵌入空间的层级结构中"自然生长"出来,不需要额外数据或聚类后处理。
排名靠前的候选被选为未知实例,参与最终的掩码竞争。这种方式让未知物体直接从嵌入空间的层级结构中"自然生长"出来,不需要额外数据或聚类后处理。3. 📊 效果揭秘:检测未知更准,已知也不掉队
看效果好不好,最直接的方法就是上数据。作者在三个数据集上做了全面评估:包含城市街景的Cityscapes、包含真实道路障碍物的Lost&Found、以及包含大规模通用场景的MS COCO。
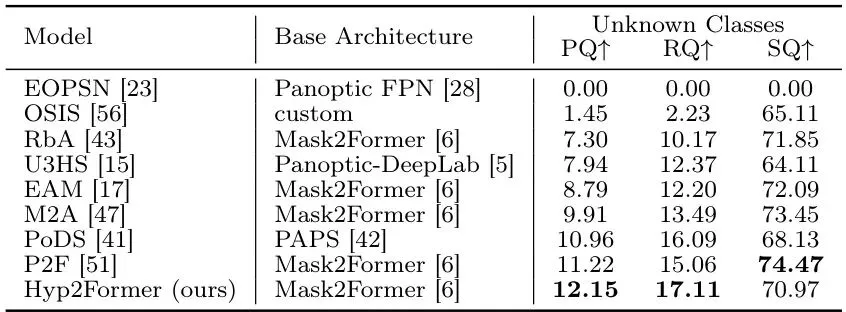
首先看未知物体的检测能力。模型在Cityscapes上训练,直接在Lost&Found上测试——真实世界的分布外物体(例如路上放的假人、箱子等)。结果一目了然:表1: 跨数据集评估未知实例全景分割。所有模型在Cityscapes上训练,在Lost&Found上测试。Hyp2Former取得最高性能。
Hyp2Former在未知类别上的PQ(全景质量)达到12.15%,超过之前最好的P2F(11.22%),提升主要来自于RQ(识别质量)的大幅提高——意味着对未知物体的定位和识别更准了。注意EOPSN直接0分,因为它根本没训练过如何检测未知物体。
但光能检测未知还不够,如果因为检测未知而把已知类搞得一团糟,那就得不偿失了。所以评估了在开放世界设定下(同时检测已知和未知)已知类别的表现:表2: Cityscapes上开放世界设定下已知类别性能。Hyp2Former退化最小。
在开放世界设定下,Hyp2Former的已知类别PQ高达53.91%,远超U3HS(41.21%)和P2F(45.25%)。而且从封闭世界到开放世界的PQ下降幅度(ΔPQ)只有5.29%,比其他方法小得多。P2F虽然在封闭世界下PQ很高(59.40%),但一开放就狂掉14.15个点——这是"为了未知牺牲已知"的典型表现。Hyp2Former做到了"两全其美"。
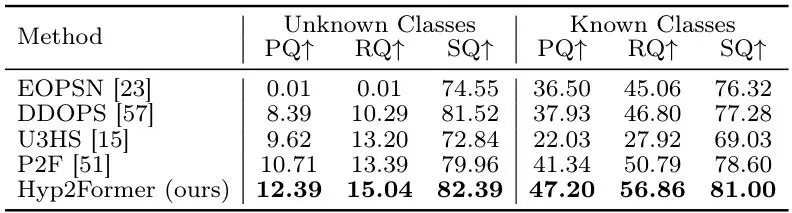
表3: MS COCO上未知和已知类别表现。Hyp2Former在两项上都达到最佳。
Hyp2Former的未知PQ达到12.39%,已知PQ达到47.20%,均领先于所有对比方法。尤其注意U3HS在COCO上已知PQ只有22.03%——为了未知牺牲了太多已知。而Hyp2Former把已知PQ拉到47.20%,比次好的P2F高出近6个点,这差距很显著。图2: 未知预测定性对比。前两列为Lost&Found结果,后两列为MS COCO结果。橙色框为标注的未知,黄色框为额外有效但未标注的未知。与P2F相比,Hyp2Former预测更加实例一致。4. 🔬 实验验证:跨数据集、跨场景,泛化能力全面碾压
前面看到的是标准数据集上的结果,但Hyp2Former的真正实力在跨域泛化上显露无遗。
作者做了一项非常"硬核"的测试:把COCO上训练的模型,零样本直接用在波士顿动力Spot机器人拍摄的室内场景上,以及车载FLIR Blackfly相机拍摄的真实城市驾驶场景上。完全不微调,看模型在完全不同的视角、传感器和场景里能不能认出未知物体。图3: 真实世界零样本泛化评估。未知物体标为红色。无需微调,Hyp2Former能可靠检测分布偏移下的未知物体。
结果让人眼前一亮:不管是在机器人视角的走廊里检测到消防栓,还是在真实街道上识别出没见过的锥桶,Hyp2Former都把它当成连贯的未知实例分割出来,同时已知类别(建筑、汽车等)也分割得很干净。
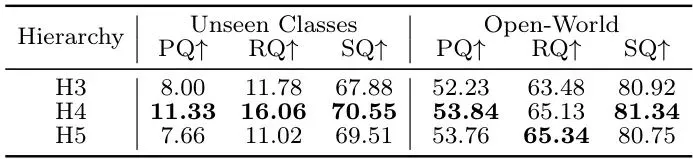
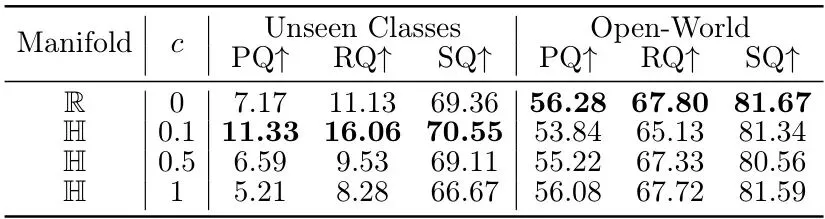
还做了大量消融实验验证各模块的有效性,这里挑几个关键的分析:表4: 主要组件消融。结合层级嵌入和未知挖掘实现了未知检测与已知性能的最佳平衡。表5: 层级结构的影响。加入祖先锚点对齐稍微牺牲已知性能但大幅提升未知检测。表6: 层级深度影响。H4(适中深度)效果最好,太浅(H3)或太深(H5)都会降低泛化性。附录表1: 双曲曲率c的影响。中等曲率(c=0.1)对未知最佳。
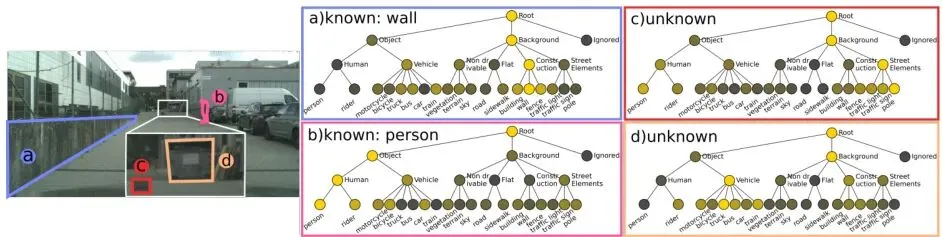
还有一个非常直观的可视化:将掩码嵌入与各层级锚点之间的双曲距离用热图展示。可以看到,对于未知物体(如Lost&Found中的障碍物),虽然它不接近任何叶子锚点,但靠近"物体"这个高层锚点,这说明模型确实学到了层级推理能力。图4: 层级距离可视化。未知区域的最近叶子锚点仍然是可解释的,表明嵌入遵循学到的层级结构。图4(原文): MS COCO使用的4级层级定义,红色标记的类被当作未知。5. 🤔 龙迷三问
这篇论文解决什么问题?这篇论文解决的是开放集全景分割(OPS)问题。核心挑战是:在测试时碰到训练时从未见过的物体类别时,模型不能把它们当背景忽略,也不能把它们错误分类到已知类别中,而要正确地分割成"未知"实例。例如自动驾驶场景中,路上突然出现训练集里没有的行李箱或动物,模型要能把它单独检测出来。
双曲空间和欧氏空间有什么区别?为什么双曲空间更适合表示层级?欧氏空间是"平坦"的,面积/体积随半径多项式增长;双曲空间是"负弯曲"的,面积/体积随半径指数增长。而树状层级结构中,每往下一层节点数也大致指数增长。例如"物体"下有10个类,每个类下又有10个子类。在欧氏空间中画这种树,越往外层越挤,必须扭曲。双曲空间天然为这种指数增长提供了"宽敞"的空间,所以表示层级结构更自然、失真更小。可以简单理解为:欧氏空间像一张A4纸,画一棵大树很快挤不下;双曲空间像一张喇叭形状的纸(越往外越大),画大树正好。
Hyp2Former的训练和推理流程是什么?训练分两步走:标准Mask2Former的欧氏空间损失(分类+掩码)保证已知类别精度;同时在双曲空间中计算层级代理锚点损失,让嵌入靠近对应类及其祖先锚点。推理时,先对每个查询计算已知类别概率,高置信度的直接参与掩码竞争。低置信度的查询用层级引导的未知挖掘:计算每个嵌入到所有双曲锚点的距离,找到最近锚点;如果该锚点属于物体子树,进一步计算物体性分数s(e),选取Top-K作为未知实例参与最终掩码竞争。整个过程不需要额外的OOD数据或聚类步骤。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~论文创新性分数:★★★★✰
将双曲空间层级表示引入开放集全景分割,并且设计了简洁有效的层级代理锚点损失和层级引导的未知挖掘,思路新颖。不是简单的"换个空间",而是从根本上解决了层级表示的自然性问题。扣一星是因为基座架构并非完全原创,基于Mask2Former。实验合理度:★★★★★
实验设计非常扎实。在三个主流数据集上评估,涵盖了标准评估、跨数据集泛化、真实机器人场景泛化等多种设置。对比方法涵盖了近三年所有代表性工作。消融实验完整,验证了每个组件的贡献。定量、定性结果充分,表格和可视化丰富。满分。学术研究价值:★★★★✰
为开放集感知提供了新范式:不依赖OOD数据或伪标签,仅利用已知类别的层级先验即可泛化到未知类别。对以后的无监督开放世界感知有重要启发意义。扣一星是因为纯粹从理论上来说,论文并未深入分析双曲嵌入相比欧氏嵌入的理论优势边界,更多是实验验证。稳定性:★★★★✰
从跨数据集的低ΔPQ来看,方法稳定性很好。在分布偏移下依然能保持已知类别的识别能力。但推理时Top-K选择未知实例的阈值设定需要调参,不同场景下可能略有波动。扣一星。适应性以及泛化能力:★★★★✰
在Lost&Found这种完全陌生的场景下泛化表现优秀,机器人场景零样本推理也证明了域适应能力。但层级结构是基于训练集已知类别预先定义的,如果测试集的未知物体完全超出了层级结构(比如外星人),泛化能力可能会下降。扣一星。硬件需求及成本:★★★✰✰
基于ResNet50和Mask2Former,推理速度约6.5 FPS(RTX 4060Ti测试),峰值显存6.2GB。虽然比P2F快得多(1 FPS),但距离实时(30FPS)还有差距。加上双曲空间计算带来额外开销。训练代价也比较高,需要96的batch size。不太适合边缘低算力设备。复现难度:★★★★✰
论文声称代码和模型将开源。基础架构是Mask2Former,容易获取。双曲空间相关操作有现成库(如geoopt)可复用。主要困难在于层级结构的定义和超参数调优。扣一星是因为目前尚未开源。产品化成熟度:★★★✰✰
在自动驾驶和机器人场景中展示出较好的零样本未知检测能力,具备产品化潜力。但需要更多实际场景验证,比如处理密集行人、恶劣天气、夜间等复杂情况的速度和稳定性。当前计算速度还不够快,对算力要求较高。产品化还需进一步优化。可能的问题:层级结构需要人工预定义,不同数据集层级定义不统一,这限制了方法的自动化程度。当未知物体与所有已知类别的祖先都不属于同一子树(例如真正的"外星人物体"),层级先验可能失效。另外,双曲空间中的数学操作比欧氏空间复杂,代码实现上坑多。这篇论文给我们的启发是:不要只盯着"未知"本身去做文章,而是从已知的结构化知识中获取泛化能力。很多问题越是想直接解决越困难,换个角度利用领域先验就能迎刃而解。双曲空间的选择非常巧妙,在需要表示层级结构的任务中(如图谱嵌入、分类层级、文档结构等)都可以借鉴这个思路。另外,耦合双曲损失与欧氏损失的联合优化框架也有通用性。[1] Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R.: Masked-attention mask transformer for universal image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1290-1299 (2022)[2] Gasperini, S., Marcos-Ramiro, A., Schmidt, M., Navab, N., Busam, B., Tombari, F.: Segmenting known objects and unseen unknowns without prior knowledge. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 19321-19332 (2023)[3] Schmidt, S., Körner, J., Fuchsgruber, D., Gasperini, S., Tombari, F., Günnemann, S.: Prior2former-evidential modeling of mask transformers for assumption-free open-world panoptic segmentation. arXiv preprint arXiv:2504.04841 (2025)[4] Khrulkov, V., Mirvakhabova, L., Ustinova, E., Oseledets, I., Lempitsky, V.: Hyperbolic image embeddings. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6418-6428 (2020)[5] Mettes, P., Ghadimi Atigh, M., Keller-Ressel, M., Gu, J., Yeung, S.: Hyperbolic deep learning in computer vision: A survey. International Journal of Computer Vision 132(9), 3484-3508 (2024)[6] Desai, K., Nickel, M., Rajpurohit, T., Johnson, J., Vedantam, S.R.: Hyperbolic image-text representations. In: International Conference on Machine Learning. pp. 7694-7731 (2023)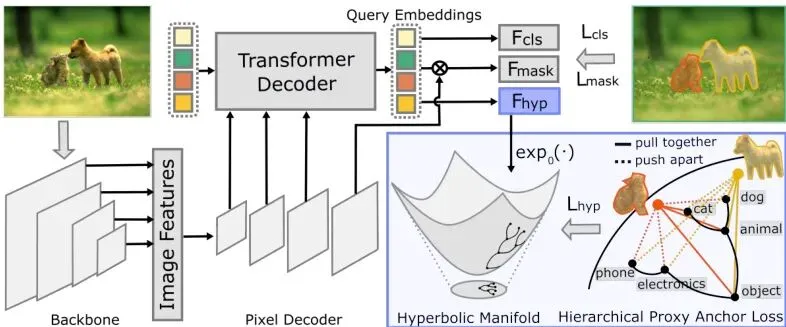






 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
