最近几年,车行业有个非常明显的趋势:车企都开始自己做芯片。特斯拉FSD已经迭代到第五代,蔚来有神玑NX9031、小鹏自研图灵AI芯片、理想推出马赫M100,比亚迪、吉利、Momenta也都在自研芯片领域持续投入。
表面看,这一波热潮是车企想要减少对英伟达的依赖,也就是业内常说的“去英伟达化”。但只看到这一点,远远不够。真正的变化,不在供应链,而在自动驾驶模型本身。
自动驾驶模型正在快速迭代,从CNN到Transformer,再到现在的DiT架构和世界模型,整套技术范式已经换了赛道。过去适配旧模型的芯片设计逻辑,已经跟不上新一代自动驾驶的需求。这才是车企纷纷下场自研芯片的真实原因。
01自研不是为省钱,核心是掌握技术控制权
车企选自研还是外购芯片,看着是商业选择,本质是赌未来的技术路线。芯片研发周期极长,从定方案、做架构,到最终装车量产,一般需要2到4年,海外厂商甚至要3到5年。
也就是说,车企现在做芯片,赌的是未来5到8年的技术走向。一旦路线判断错误,芯片要么生命周期大幅缩短,要么直接用不上。车载芯片研发,本身就是一场高风险押注。
车企坚持自研,核心原因很简单:车企比外部芯片厂商更清楚,自己几年后要跑什么样的自动驾驶模型。3纳米、5纳米芯片研发成本极高,一次性工程费用加上IP授权,动辄数亿。单靠芯片出货,基本不可能赚钱。但这笔投入可以计入研发成本,同时提升企业的科技标签和资本市场估值,整体商业账是算得过来的。
同时,自研芯片的门槛其实在变低。现在IP生态、EDA工具越来越成熟,加上索喜这类专门帮车企做定制芯片的服务商出现,硬件层面的工程难度已经大幅下降。现在真正难的,是软件栈、编译器适配,以及长期的模型调优迭代,这部分高度定制化的工作,外部芯片厂商很难替车企完成。
02自动驾驶模型迭代,重构芯片设计逻辑
目前业内主流的自动驾驶技术路线分为三条,三条路线对芯片的要求完全不一样。没有车企敢只押一条路,基本都是同步布局,避免被技术迭代甩开。
第一条是分段端到端路线,也是目前大多数车企在用的方案,代表是Uni-AD,模型参数大多在5亿以内。第二条是VLA视觉-语言-行动路线,结合世界模型、扩散动作模块或MLP提升推理效果,多采用MoE架构,参数普遍在20亿到70亿。第三条是世界模型+扩散动作专家,目前还没有量产落地,真正上车的时间还不确定。
行业一直有个误区,认为芯片TOPS算力越高,性能就越强。这套逻辑放在老式CNN模型时代是成立的。但现在已经是CNN+Transformer的混合时代,未来会彻底转向Transformer+DiT。
单纯看TOPS已经没有意义。一颗5000TOPS的传统芯片,跑DiT架构,实际效果可能还不如一颗300TOPS的定制芯片。真正决定自动驾驶芯片性能的,是存储带宽、任务编排、分级内存耦合、SFU单元、可编程向量算力这些指标。行业单纯堆算力的TOPS崇拜,已经失效了。
03世界模型核心DiT架构,现有芯片无适配方案
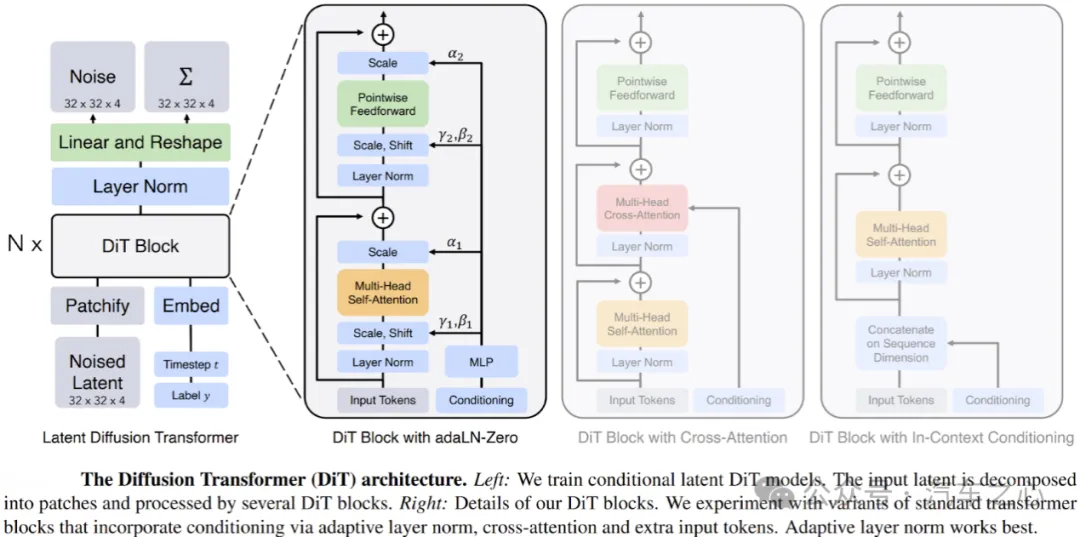
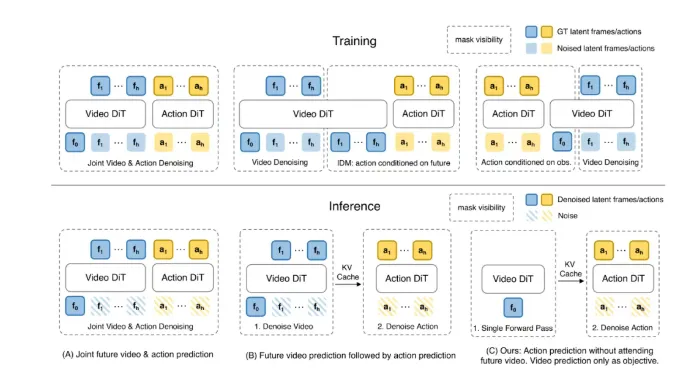
世界模型的核心架构是DiT,这套技术在去年才算真正成型。DiT最大的特点是擅长处理时序信息,不只是用来生成图像,更适配视频、动态场景、自动驾驶决策和具身智能的迭代需求。
不管是先模拟再执行,还是训练建模、推理直接输出动作,主流世界模型方案都离不开DiT架构。
但目前市面上,没有任何一颗量产芯片是专门为DiT推理设计的。扩散模型的推理流程非常繁琐,传统高算力芯片只能处理规整的矩阵乘法,也就是去噪循环里的基础计算。大量不规则计算、向量编码、内存敏感运算,都要靠CPU和通用算法兜底,对芯片架构要求极高。
因此,坚定走世界模型路线的车企,不想被动等待通用芯片升级,就只能自己自研。
04存储带宽,是自动驾驶芯片的核心瓶颈
不管走哪条技术路线,存储带宽都是自动驾驶芯片的关键瓶颈,带宽越大,整体运行效率越高。这一点在VLM视觉语言模型上最突出,解码是VLM最耗时的步骤,而解码速度完全由存储带宽决定,相当于VLM的整体性能,基本绑定芯片带宽。这也是特斯拉在AI4、AI5芯片上拼命拉高带宽的原因。
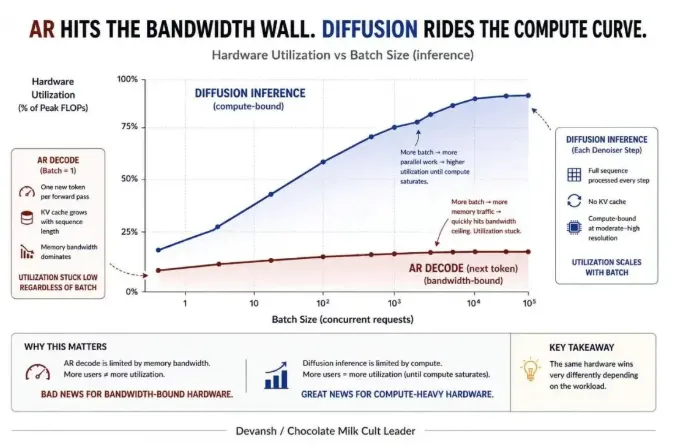
自回归架构的解码阶段非常吃内存,算力再高也没用,最终速度只看带宽和调度延迟。一些小型模型,甚至在CPU上跑比GPU更快。
扩散模型则高度依赖批处理数量Batchsize,批次越大,矩阵计算的利用率越高。但批次一大,非规整运算和调度开销会暴涨,整体延迟大幅上升。自动驾驶对延迟非常敏感,实际可用Batch大多只有1到4,基本不超过8。这就导致高端GPU纸面算力很高,但在车载场景里大量算力闲置、浪费。
05三大芯片核心架构,对应三种计算哲学
自动驾驶芯片的核心是AI加速器,当前行业的加速器路线之争,本质是三种不同的计算思路。根据矩阵运算单元的架构差异,基本分为大核心、中核心、小核心三类,各有优劣,也各有适配场景。
(1)大核心:极致效率主义
大核心主要采用脉动阵列架构,谷歌TPU、AWSTrainium、英特尔Gaudi,以及特斯拉HW3.0、蔚来神玑、小鹏图灵、高通AI100等芯片,都属于这一类。以TPUv5为例,单核心256×256阵列,拥有65536个MAC计算单元,数据一次流入、脉动传输,减少频繁读写内存的压力。在大批次、规整的LLM、VLM模型中,能效和性价比优势非常明显。
但大核心的短板也很明显,极度依赖规整的数据矩阵形状。256×256的阵列结构,要求计算维度必须对齐256,一旦对不齐,就要做切片、补零、布局转换等大量预处理工作。即便编译器优化做得很好,算力利用率也很难超过40%,优化不到位甚至不足10%。自动驾驶视觉模型多是稀疏、非规整计算,大核心天生适配性差。即便后续新增稀疏核心,也会进一步加重软件调度负担。同时大核心需要庞大的软件团队支撑,软硬件投入极不对称,长期很难盈利。
(2)小核心:极致灵活主义
小核心本质是多核CPU架构,典型代表是特斯拉Dojo,由384个独立核心组成,每个核心都有独立控制逻辑和本地SRAM。优势是兼容性极强,任意数据形状、Batch=1的极小批次都能保持高利用率,适配解码、MoE路由、KV缓存、稀疏运算等各类复杂场景。测试数据显示,75%稀疏度下,小核心速度是稠密架构的2.5倍,这是大核心做不到的。
但小核心的代价也很高,每个核心都要配套独立的控制、译码、寄存器资源,同等算力下,芯片面积和成本是脉动阵列的2到5倍,成本劣势非常明显,这也是业内很少有人纯做小核心架构的原因。
(3)中核心:平衡主义
英伟达走的是中间路线,不极致偏效率,也不极致偏灵活。GPU的TensorCore采用16×16中核心负责稠密算力,CUDA小核心负责控制流和稀疏计算,两套架构并存。通过调度机制抹平形状适配问题,不规整的计算由CUDA核心补齐。英伟达真正的优势,从来不是纸面算力,而是在效率、灵活性和开发生态之间做到了最好的平衡。这也是车企普遍喊“去英伟达化”,但绝大多数依旧离不开英伟达的核心原因。
理想、Momenta、华为车载芯片,基本都是中核心思路,特斯拉下一代AI5也大概率转向中核心。高通的升级逻辑也类似,从SA8155到SA8797,矩阵单元规模不变,一直在加强标量、矢量线程能力,用来适配越来越复杂的推理场景。
06没有完美芯片,只有路线押注
三种架构都有明显短板。大核心适合规整、高密度的大模型,模型越大优势越明显,但跑DiT、扩散模型这种混合密度、强串行、不规则计算的场景很吃力。小核心适配DiT和稀疏场景,但成本太高、性价比不足。英伟达中核心兼顾两端,但面对新一代扩散、世界模型,依旧存在性能瓶颈。
而且车载场景无法像云端一样跑超大参数模型,内存和成本都不允许,所以“中核心+小核心”的混合架构,是目前最务实的方案。
目前小米、吉利、比亚迪、Momenta的自研芯片项目都在稳步推进,技术落地没有硬性障碍。唯独传统车企,依旧倾向于外购芯片、尽量不自研。这种选择无可厚非,但在自动驾驶模型快速迭代的当下,这种保守路线的压力会越来越大。
自动驾驶芯片真正的难点,从来不是造出芯片,而是在当下,提前押中未来五年的AI技术方向。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
