💥开篇暴击:打破“显存焦虑”与盲目采购
现在的智驾圈和AI圈,存在一种极其严重的“显存焦虑”和“算力攀比”。老板们一看竞品发了新模型,回头就问:“咱们的顶级旗舰算力卡到位了没?”工程师们为了跑通一个Demo,开口就要几千张卡。
但老兵我进过不少公司的机房看监控,发现一个扎心的真相:很多公司的算力利用率不到30%,大量的GPU都在空转等CPU搬运数据,或者在为了并不需要的FP32①精度浪费巨额功耗。
📝 术语小贴士:① FP32(单精度浮点数):32位浮点运算格式,精度高但功耗大。大模型推理场景中常可压缩至INT8(8位整数),在几乎不损失精度的情况下大幅降低算力消耗。
⚠️ 在大模型时代,算力就是真金白银。如果不懂Workload(工作负载)分析,盲目追求顶级芯片,你不是在搞研发,你是在帮某国际GPU巨头打工。
今天,我们就用第一性原理拆解,如何构建高ROI(投资回报率)的算力基建。“不懂负载分析就去买卡,无异于用拉力赛车的预算去跑网约车。”
◆ ◆ ◆
🧠底层逻辑:按需分配——大模型研发的三个核心战场
要提升算力的ROI,首先要建立“按需分配”的选型意识。大模型研发的流水线,对硬件的需求完全不同,可切分为三个核心战场:
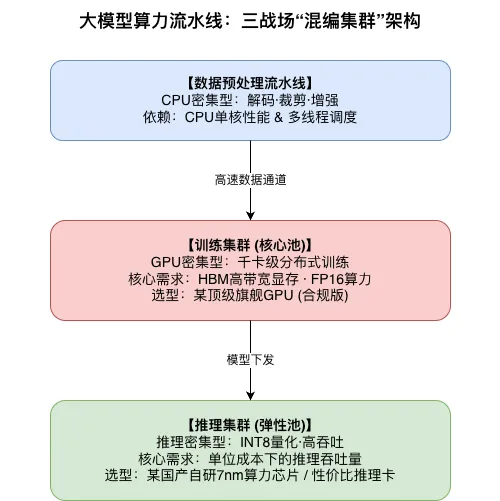
▲ 图:大模型研发流水线的三个核心战场及其硬件需求差异
📊 多维选型评分卡
▲ 表:GPU/CPU多维选型评分卡——量化评估每一份算力投资 | 知猷君整理
▲ 图:混编集群架构——按Workload类型精准匹配算力资源
🎯 认清你的真实负载,是摆脱“显存焦虑”的第一步。
◆ ◆ ◆
📓知猷回忆录:一场“混编集群”引发的口水战
聊到选型,我想起当年在某头部大厂负责高阶无人驾驶平台基建时的一场“口水战”。
当时我们自研的世界模型刚刚跑通,云端训练的算力缺口巨大。硬件采购部门给出的建议简单粗暴:全量采购当时最新最贵的旗舰算力卡。
💡 刚开始算法工程师们都担心国产芯的底层算子支持度不行,但当我们配合自研的SDK,实现跨平台无缝迁移后,奇迹出现了:整个集群的TCO降低了40%以上,而整体吞吐量反而提升了。真正的基建专家,不是会花钱,而是在预算锁死的情况下,把每一份算力压榨到物理极限。
◆ ◆ ◆
🛡️实战避坑:3条“防割韭菜”的铁律
◆ ◆ ◆
🛒闲鱼捡漏 · 选型对比PPT模版
一杯奶茶钱,买一份行业内头部的基建决策内功,绝不亏!用数据说话,让你的每一分基建预算都花在刀刃上。
📢 关于作者 | 知猷君
📱 微信公众号:知猷君
*关注我,拒绝碎片化,构建你的新能源技术护城河。
© 2026 知猷君 | 本文为“知猷”品牌原创,欢迎分享,转载请联系授权。专注新能源汽车与AI算力基建深度技术解析与行业洞察本文系知猷君原创,侵权必究。






 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
