自动驾驶Diffusion+RL 研发流程
- 2026-06-08 13:33:40
点击下方卡片,关注“之心智能EDU”公众号
作者丨知乎健壮壮
编辑丨之心智能EDU
https://zhuanlan.zhihu.com/p/2039667146515538016
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个自动驾驶全栈学习社区:自动驾驶之心知识星球(戳我),这里包含所有你想要的。
记得上次写文章的时候,还是在广州XP的时候。感恩当时遇到非常nice领导和有趣的同事。期间技术栈也发生了很大的变化,由规则驱动转化为数据驱动的范式。目前已转向RL技术栈(model-free的ocp问题),外加ai coding的提效, 后面会附demo
RL 应用场景
1.1 游戏:(环境已知,reward已知 ---> 效果可超越人类) 星际争霸、flappy bird
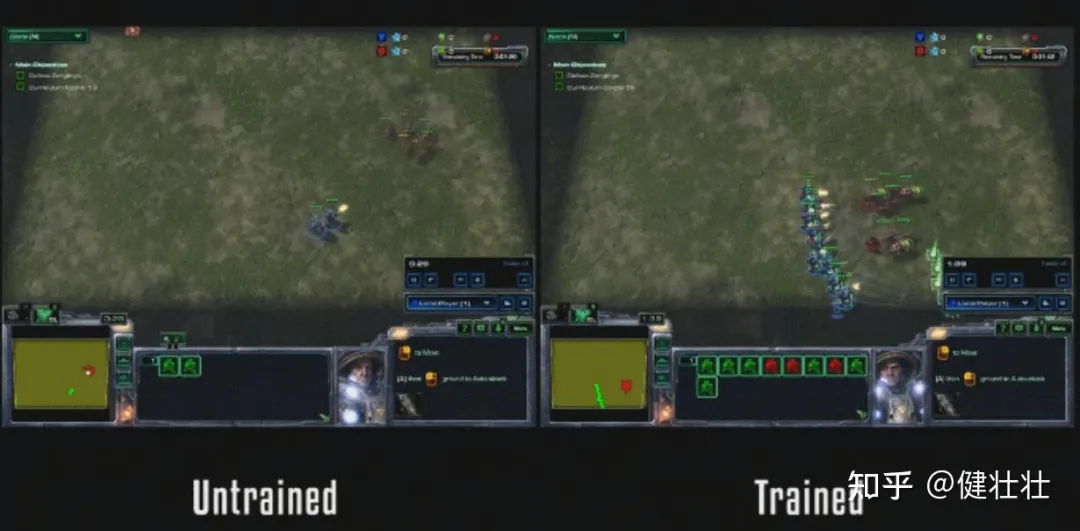
1.2 Post training:(大模型、VLA后训练微调)
预训练模仿学习(初解),基于初解,reward探索,微调;
1.3 运动控制(被控对象复杂的具身机器人):

具身智能研究大量依赖于仿真平台。MuJoCo/Gazebo/Isaac Sim;Sim2Real迁移技术减少虚实差距(Domain Randomization):在训练时随机关节扰动
2 强化学习理论
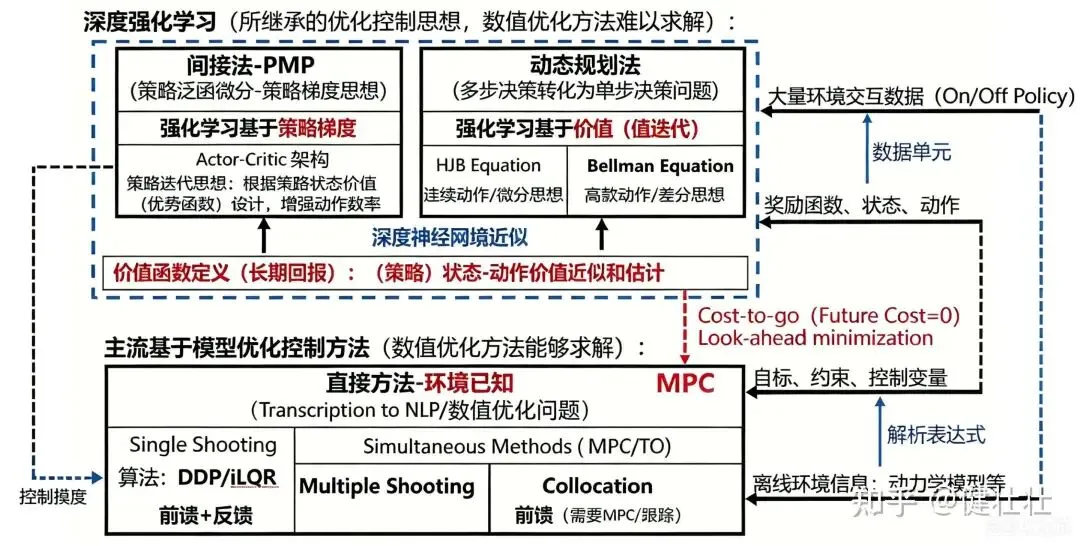
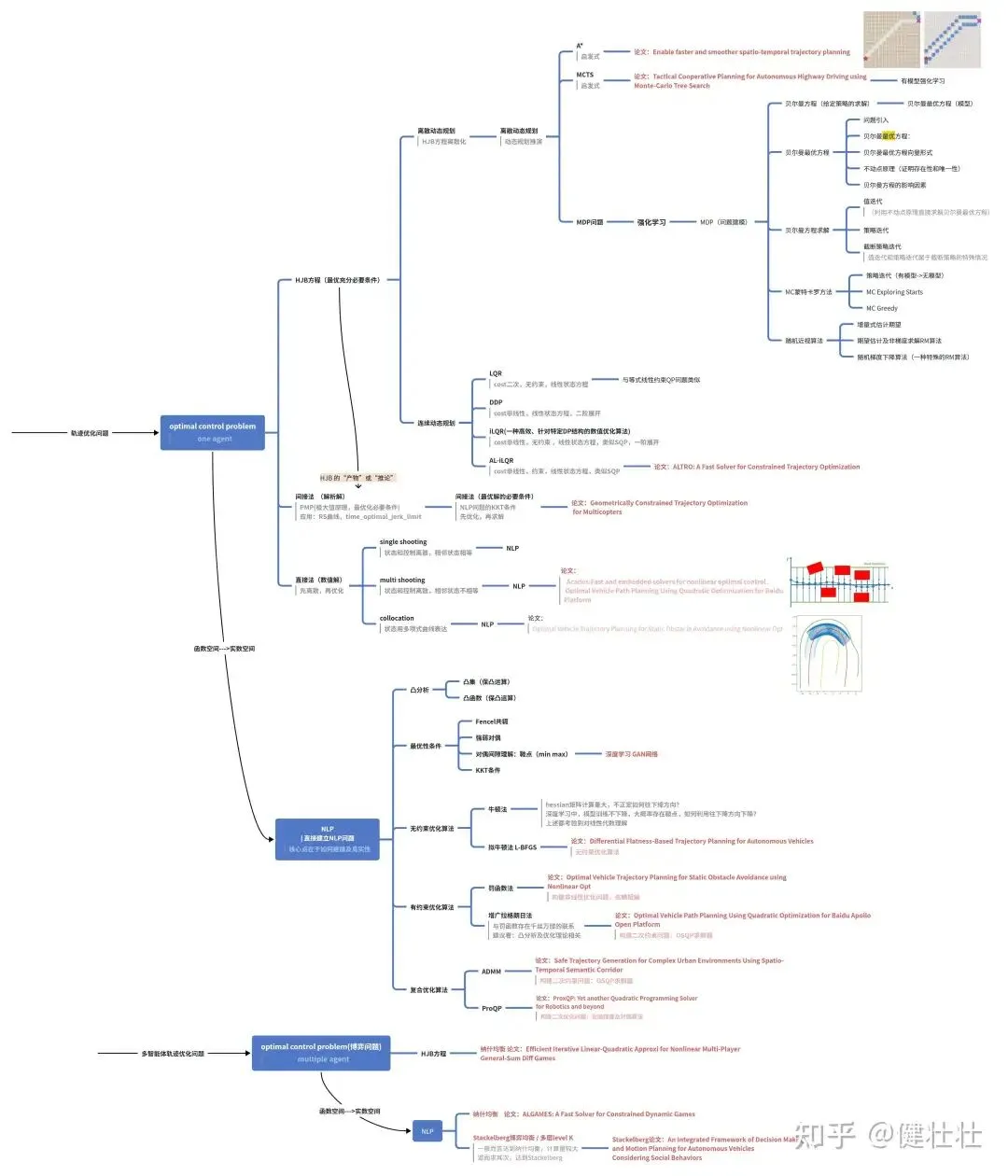
强化学习理论,是model free的ocp问题;我这里用一张图片来展示强化学习与优化、应用领域决策规划的关系;总体上需要较强的数学基础和理解能力。强化学习和优化领域参考资料参见:强化学习的数学原理(赵世钰),凸优化(StephenBoyd),最优控制理论方法与应用(王青),大家自行搜索
3 Flow matching建模
diffusion + flow matching是目前比较快的生成模型,主要应用于图像生成和自动驾驶机器人领域。生成建模学习本质:从噪声分布到真实分布的过程,本质上是一种数学建模过程。扩散模型爆火核心内因就是:它数学建模逻辑极度贴合现实世界的物理客观规律
GAN:直接凭空硬造一张图,一步到位,跳变太大 AR 自回归:从左到右逐像素硬填,不符合视觉生成逻辑 VAE:强行压缩再解压,强行拟合,不自然
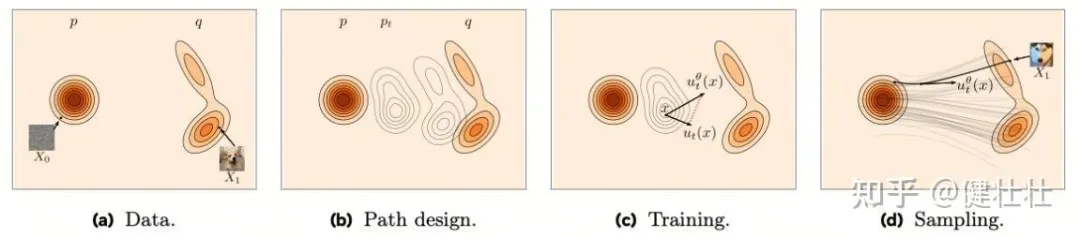 Flow 是什么,Flow 是一种连续可微变换 ,并定义如下
Flow 是什么,Flow 是一种连续可微变换 ,并定义如下
这个变换是个恒等变换,随着 逐步增加这个变换逐渐可微的渐变。Flow matching 学什么,他学习的速度场,给定任意数据 他的真实速度 和 网络的差的期望
但这个值显然不好计算,一方面 未知,一方面 未知,下图给出了一个示意,但符号使用上以 代表数据, 代表噪声。但其实不必去求 FM loss(有证明),我们只需要知道他的梯度就行,我们其实是想学极值点。可以证明下面公式的梯度和 FM loss 等同。
我们可以稍微展开看看
上式中 和网络无关,代表真实的速度场,所以无需关心
上式可以说明 CFM 和 FM 梯度的第一项相等,第二项证明有点绕,我们先引入场的连续性方程;类似流体力学里的连续性方程(Continuity Equation),即流体密度时间变化率加上质量通量密度的散度(梯度的加权和)等于零。
有了连续性条件我们得出一个中间结果:
上面第一步使用了边缘分布和条件分布的关系
比较等式两边散度算子内的项可得:
于是第二项相等得证:
CFM 显然比 FM 可操作,最起码数据的分布我们知道的或者可以采样近似,我们也可以自己控制
接下来用高斯函数表达 probability path,我们考虑如下的概率路径:
并定义 ,,,。这可以理解从数据分布到一个标准正态分布的一个路径,并考虑一个特定的 flow
在上两个规定下的特殊情形我们有:
证明了为符号简化,记 ,令 对于
整理为 对于 他的表达式为
同时我们有
整理上面结果可得
到这一步 CFM 中的所有东西都能给出,但为了更加简单,我们可以进一步
在这种简化下
也就是 Flow 是一条直线路径,速度就是噪声到数据的距离,从这里我们看到了问题从泛化到特化,从复杂到简单,最后的算法其实非常简单直接,他的算法流程如下:
数据集 向量场模型 基分布 Step 1. 采样 从数据分布采样: 从基分布采样: 采样时间: Step 2. 构造中间状态 Step 3. 构造监督信号真实速度: Step 4. 计算 Flow Matching Loss Step 5. 参数更新
4. Diffusion + NFT(强化学习微调)
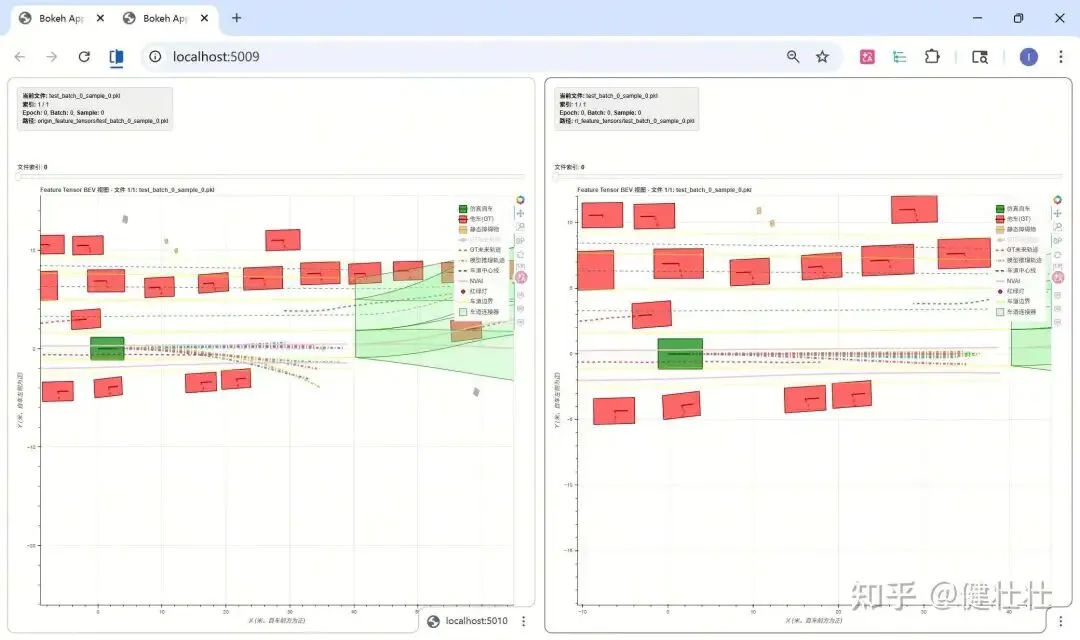
我们使用Flow Matching的Diffusion planner 并用 Diffusion NFT来做微调,在nuplan上实现离线开环微调初步效果。
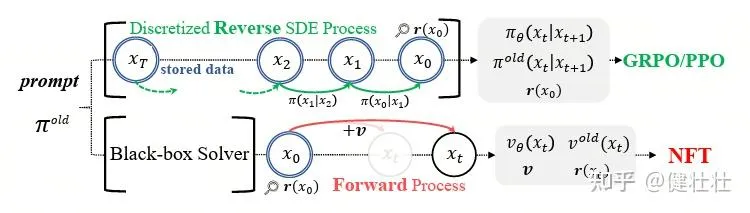
FlowGRPO 将去噪采样过程离散化为马尔科夫过程,通过近似相邻步骤之间的高斯转移核近似GRPO算法;算法专注反向过程,破坏正向一致性;依赖SED采样,无法使用ODE等确定性采样器;需存储完整的采样轨迹(包括中间状态),以计算策略梯度,存储和计算开销大。
DiffusionNFT 使用监督模型范式,通过对比正负样本定义策略模型改进方向,将强化信号直接融入到标准的扩散过程中,无需似然估计;保持正向一致性,同时完全解耦策略训练与数据采样,允许使用任意黑箱求解器(包括ODE和高阶方法),提升采样效率与质量。有下列优点:
不需要走反向生成轨迹不需要似然、 不需要概率 训练只看「清晰样本 + 前向加噪」,和你用什么采样器完全无关 采样可以随便换黑箱 ODE、高阶求解器,不受训练约束扩散模型通过前向过程逐步对干净数据添加高斯噪声,学习连续数据分布;再学习逆过程生成数据。 前向加噪过程存在闭式转移核,可重参数化为:
扩散模型的一种学习方式是采用速度参数化 ,预测轨迹切线,通过最小化目标损失训练:
在线强化学习:给定预测轨迹扩散策略 和提示词 ,每轮迭代为提示 采样 张图像 ,用标量奖励函数
评估每张图像,代表最优概率。采集数据可随机划分为两个虚拟子集:图像 以概率 归入正样本集
,否则归入负样本集 。无限样本下,两个子集的底层分布分别为:
强化学习要求每轮迭代执行策略提升,优化策略 满足:
同样容易证明:
为了利用 ,强化引导我们认为负反馈对策略提升至关重要。不将 作为优化点,而是同时利用正负数据指导提升方向 ,训练目标定义为:
其中 是扩散模型速度预测器, 为超参数。该形式与 CFG 等扩散引导类似,我们称 为强化引导, 为引导强度。根据公式(18-19)可定义和证明:
其中
为标量系数;该式给出提升 的理想引导方向 ,适当引导强度可保证策略提升;(策略优化):训练目标为:
其中:
训练目标梯度:
那么将训练目标梯度积分从优化器方向理解:
第一项:优化方向
第二项:约束松弛项
无限数据与模型容量下,最优解满足:
5 Diffusion Planner(预训练) + Diffusion NFT (RL微调)Demo
参考:
https://github.com/ZhengYinan-AIR/Diffusion-Planner
https://github.com/NVlabs/DiffusionNFT
Diffusion Planner 是基于扩散模型与 Transformer 的自动驾驶闭环规划器,核心特点是统一预测与规划、多模态生成、灵活引导、高速推理、强泛化与低后处理依赖;
核心架构:DiT 扩散 Transformer、Flow matching
Diffusion 的多模建模天然适合RL
(向后)多步降噪过程看成MDP,然后套到强化学习框架里,比如GRPO,或者策略梯度法,PPO,我们知道flow matching的过程是一个ODE过程,为了获得随机性,将ODE过程转换为SDE,然后就可以生套强化学习框架了。这套框架本质上是把 PPO/GRPO 移植到 diffusion model 的去噪过程上:把每条去噪轨迹看作一episode,每个 timestep 的 SDE 采样步骤看作一个 action,用 importance sampling 做 off-policy 修正,用 per-prompt 归一化稳定训练。LoRA 减少可训练参数,FSDP 支持大模型分布式,GRPO-Guard 防止 reward hacking。 (向前)DiffusionNFT, 在采样到样本之后,对样本重新进行加噪来训练,加噪方式和loss都与Diffusion基本一致,只是在最终loss的前边套上了advantage作为loss weight,只不过存在类似拉格朗日项(约束项),DiffusionNFT略慢但优化稳定我们使用Flow Matching的Diffusion planner 并用 Diffusion NFT来做微调,在nuplan上实现离线开环微调初步效果如下;(左边:预训练;右边:RL微调)(bokeh交互式工具可视化)
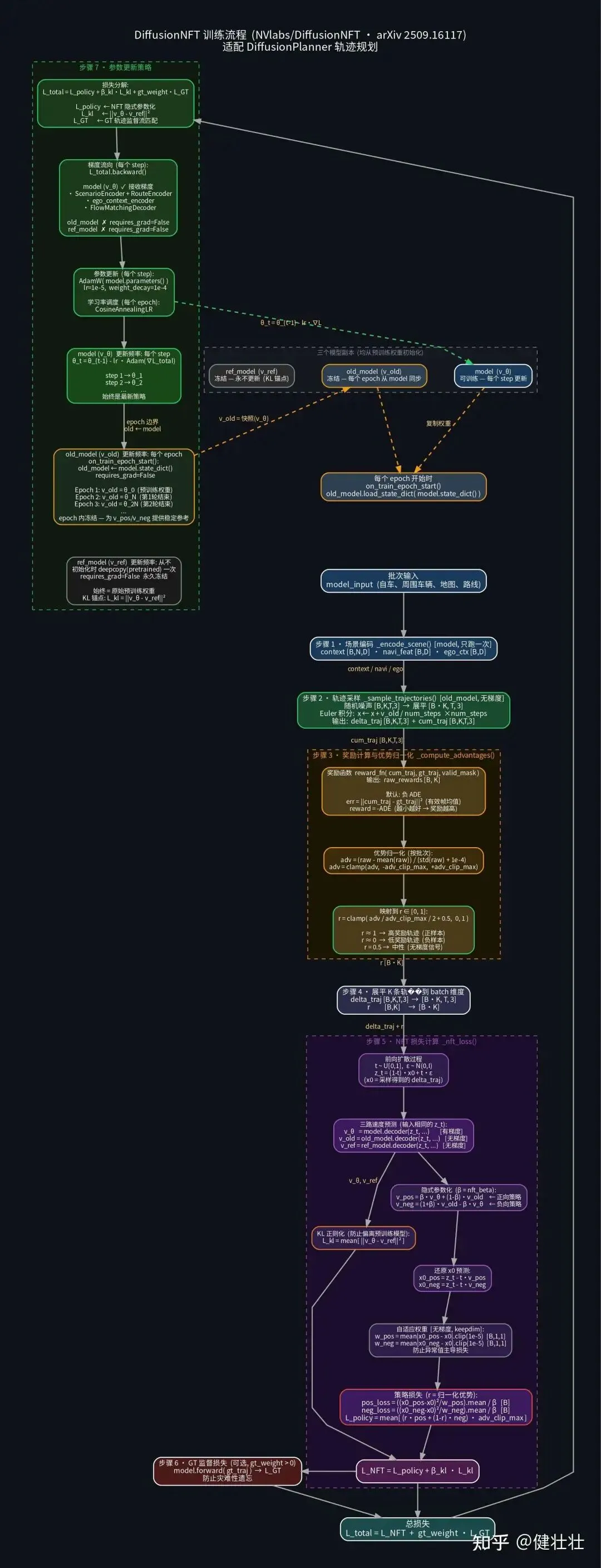
下面是RL架构简略图(目前demo设定的是离线强化学习,后续可引入闭环强化学习架构,一段式模型引入3DGS)
demo链接(comming soon大约一周时间):https://github.com/chaoren718718-jpg/diffusion-rl
6 研发流程及评测重要性
https://www.zhihu.com/question/1964369389823427262/answer/1964907507454550287
参考FSD AI研发范式:
端到端模型架构的必要性:对人类价值观进行编码极其困难 \ 感知、预测与规划之间的接口定义模糊。FSD介绍比较关键内容:
维度灾难;(丰富的数据资源、NN挖掘各种corn case) 高维到低维的映射很难 人类价值观进行编码极其困难 解决方案:挖掘数据 可解释性和如何保证安全性; 推理语言输出解释性 feedforward 3dgs (最难) 如何正确合理评估自动驾驶系统的能力: 仿真评测、3Dgs重建闭环评测 世界模型生成场景评测
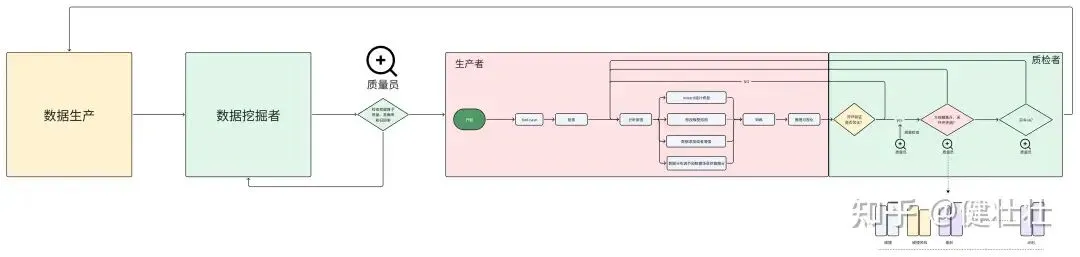
Ai是第四次工业革命,意味着生产效率的提升,AI开发的产品线符合工业流水线(本质上兼顾效率和质量);有些部分工具可以无人自动化,有些部分还需要人类;但所有生产者生成的内容都需要有个质量检查体系来校验;其背后的核心原理本质是: 效率和质量极致管理,这条流水线的各个部分不能有明显的短板,否则就会影响效率和质量,折射出一号位对工程和产品、技术的理解和管理水平,也就是所谓的“体系”。为啥需要这套流水线? 人不是神,代码肯定会犯错。如果不有效(自动化)仿真拦截错误,直接现实中测试,效率极低,本质上是提高生产效率。
例子1:开发手机软件的一个小模块,开发人员无法保证该改动会不会对其他模块性能有影响;实际测试可能又测试不到该场景。那就需要有性能监控和反馈,导致进度有问题
例子2:Ai Coding类似的逻辑: 人类是总监,提出详细需求,将问题拆解,将“工产流水线”系统流程搭建好; AgentA , AgentB提出方案 ----> AgentC , AgentD review方案 ----> AgentE , AgentF实施方案 ----> AgentG , AgentH 质量检查 ----> 反馈
所以ai时代,面向产品的开发,更加考验组织团队的效率,工具的效率和工程细节打磨(真正优秀的产品是无数个细节累加而成,这些可以说都是脏活累活);而非期待有颗银子弹搞定一切。
7 强化学习和预训练的如何分工?
Scaling Test-Time Compute Without Verification or RL is Suboptimal
链接:https://arxiv.org/abs/2502.12118
基座模型必须具备的 4 个核心先决能力:
基座已有的能力里 “挑出最好的解”。所以基座必须:会很多解法、偶尔能做对。
预训练是模仿学习,泛化弱,未见场景极易出错,只能复刻已有数据,无法自主探索优化;RL强化学习,可提高模型泛化性;可在线交互试错,动态适配变化环境;能探索最优策略,突破人类现有经验;那么RL 取决于环境和reward;
游戏领域(已知,real环境),reward(已知),可以学习出超越人类的game player 运动控制领域(已知 , sim环境),reward(已知, 轨迹跟踪相对简单),但需要解决sim2real问题;有时候只要被控对象模型精确,传统算法更加有优势,比如汽车轨迹跟踪控制(MPC算法等) 自动驾驶领域(已知,sim环境),reward(人类定义,高维reward难以设计), 需要解决sim2real和reward问题
自动驾驶领域;完全靠强化学习非常难
sim2real技术难度非常,相当于要把真实的世界模型建立出来;如果用规则建立真实的世界模型,那么就不会用ai来实现了,直接用规则可实现自动驾驶;世界模型训练,会出现ai 训练 ai的问题,可能结果不可信 real中训成本高(会撞车或者生命危险) 强化学习的reward比较难设计;规则时代,3维的人类设计高维的reward本身就非常困难,而且从感知bev特征就存在传递消息缺失,也不好建模,比如盲区监测限速,绕水坑等;规则设计的reward也不一定sim2real(非常精准表达人类价值观优势);可能有个比较好的方式采用专家数据fit reward
预训练"初解" + RL "优化微调"
与纵向规划一样,算法模块提供ref ,在经过动力学优化器(apollo)。预训练的初始结果就比较好,然后通过强化学习微调(这样可大大降低reward设计的复杂性和精细度);或结果不好,看是否通过强化学习微调修掉,过度依赖reward 就会陷入设计规则的跷跷板;如果信息传递存在丢失的场景或者需要高级语义理解的场景,大概的解决方案:挖掘数据,调节分布;否则可以通过rl微调解决。总之预训练和rl应该是相辅相成的,但在自动驾驶领域预训练还是大头,远没有预训练和强化学习55开的情况。
8 个人总结
Ai 可以把原来的差异成倍的放大,专业能力极其重要(PS: demo中没有一行代码是我自己写的)
Lecun "我们应该学习数学、建模的基础知识, 学习如何学习",保持对基础知识的掌握会让你事倍功半
END


求点赞

求分享

求喜欢

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 奇瑞瑞虎9看着很值,但12万多买中型SUV先别只盯着动力
- 大众途锐:当年136万的旗舰SUV,现在50万起还值得认真看吗
- 2026款宝马M5轿车,豪华和脾气都很鲜明
- 有谁知道这部轿车的来历吗?
- 深圳到那曲轿车托运 深圳到那曲物流公司 那曲到深圳汽车托运
- 4月纯电SUV前十,Model Y仍是硬通货
- 标准 | 《智能网联汽车 自动驾驶数据记录系统》(附下载)
- 15万纯电轿车,大众这张牌打出来,比亚迪秦L EV的日子不好过了?
- “司机激活智驾,双手脱离方向盘”,江西轿车撞上货车致3人死亡,调查报告公布
- 揣着20万预算买家用SUV,不拼“冰箱彩电”的途观L,凭什么让你开5年不后悔?
