
⚡️《CoWorld-VLA: Thinking in a Multi-Expert World Model for Autonomous Driving》
📖 导读
在端到端自动驾驶的火热赛道中,视觉-语言-动作(VLA)模型正试图一统天下。然而,当前业界正陷入一个进退两难的泥潭:主流模型往往喜欢用“文本思维链(Textual CoT)”来解释驾驶决策,但这会严重丢失复杂的 3D 空间与时间几何特征;而另一种极端的“纯隐式世界模型(Latent World Models)”虽然懂物理,其特征却像个黑盒,极难直接转化为精准的车辆控制指令。
为了彻底跨越这道鸿沟,千挂科技(Afari Intelligent Drive)联合电子科技大学、上海交大、北邮与天津大学的顶尖团队,重磅推出了 CoWorld-VLA 架构!该研究开创性地提出了“在多专家世界模型中思考(Thinking in a Multi-Expert World Model)”的全新范式。它抛弃了干瘪的纯文本推理,构建了由“语义交互、几何结构、动态运动、驾驶意图”四大专家组成的潜在思维链(Latent CoT)。通过将这些异构的世界先验知识注入到基于扩散模型(Diffusion)的轨迹规划器中,CoWorld-VLA 在复杂路口的博弈与轨迹生成上实现了断层式的性能飞跃。这是下一代端到端大模型不可不读的落地级架构指南!
📷 核心图表
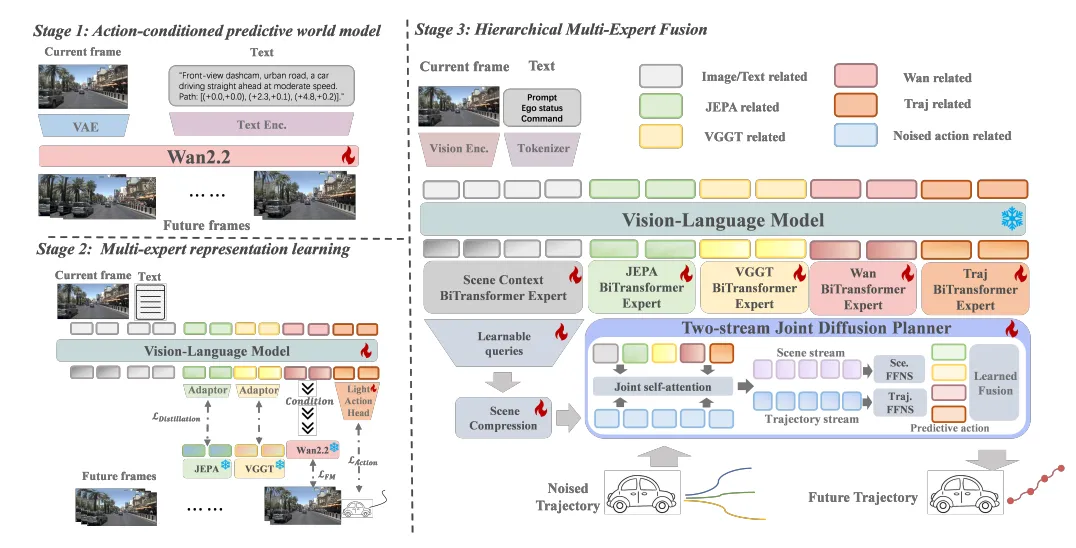
图1 | CoWorld-VLA 多专家世界模型架构蓝图(对应原论文核心架构)注:传统的 VLA 模型直接从视觉/文本映射到动作,犹如“盲盒开盲猜”。而 CoWorld-VLA 在动作输出前,强行插入了一个“多专家思考”阶段(Latent CoT)。它通过多源监督信号,分别提取出环境的几何、语义、动态和自身意图特征,让大模型在下达方向盘指令前,真正在隐空间里完成了一场严谨的“物理时空预演”。

图2 | 复杂博弈场景下的轨迹规划对比(对应原论文 Figure 7)资料来源:论文定性展示。在极度考验交互能力的“车道保持、无保护左转、动态超车”等场景中,缺乏专家先验的传统基线(Stage 2)常常规划出穿模、偏离几何边界的危险轨迹。而搭载了 HMEF(异构多专家融合)的 CoWorld-VLA(Stage 3),其生成的轨迹严丝合缝地贴合了物理路网,展现出了如同人类老司机般的极强动态避让与空间约束能力。
📑 核心信息提炼
文献题目: CoWorld-VLA: Thinking in a Multi-Expert World Model for Autonomous Driving(《CoWorld-VLA:在自动驾驶多专家世界模型中思考》)
作者团队: Minqing Huang, Jingqi Wang, Yujiao Xiang, Zihan Liang, Jiajie Huang 等(千挂科技 Afari Intelligent Drive,电子科技大学,上海交大,北邮,天津大学)
发表平台: arXiv(2026年5月13日)
核心数据/指标:
复杂场景断层领先:在车道保持、十字路口转向和变道绕行等高难度评测中,多专家融合策略的轨迹贴合度与安全性显著优于传统回归基线。
几何与动态约束:通过异构多专家融合(HMEF)机制,大幅降低了规划轨迹在真实物理世界中的碰撞率与越界率。
核心发现/战绩:
- 严厉指出了纯“文本思维链(Textual CoT)”在自动驾驶中的致命缺陷:语言可以描述“前方有车”,但语言无法精确表达“前车与自车在 3.5 秒后在 2D 鸟瞰图上的重叠概率”。
- 证实了将“世界模型表征”作为显式条件,直接引导扩散模型(Diffusion)进行动作生成,是解决端到端幻觉的终极杀器。
核心创新点:
- **多专家潜在思维链 (Latent CoT)**:将世界知识解耦为四类 Token(语义交互、几何结构、动态运动、机动意图),实现了从“黑盒感知”到“白盒多维认知”的跨越。
- **异构多专家融合 (HMEF)**:在 Diffusion-based 的动作生成流中,完美融合了上述四大专家先验,让规划出的轨迹天生自带物理与几何免疫力。
核心主题: 视觉-语言-动作模型 (VLA), 自动驾驶 (Autonomous Driving), 世界模型 (World Models), 潜在思维链 (Latent CoT), 异构多专家融合 (HMEF)
核心受众: 端到端自动驾驶规控工程师、多模态大模型架构师、具身智能决策研究员
❓ 行业发展的 4 大“核心痛点”
- 文本思维链的“纸上谈兵”: 如今很多大模型喜欢用语言输出“因为左边有行人,所以我应该刹车”。但自动驾驶是连续控制的艺术,干瘪的自然语言根本无法保留至关重要的连续时空结构(Continuous spatiotemporal structure)。
- 纯隐空间预测的“落地死锁”: 虽然视频生成(如 Sora 变体)能在隐空间预测未来,但这种黑盒特征对后端的控制模块(Planner)来说如同天书,极难直接转化为方向盘转角和油门开度。
- 单体特征堆叠的“信息过载”: 传统端到端网络把图像、雷达数据混成一团塞给 Transformer。在复杂路口,网络根本分不清哪部分特征代表“静态马路牙子”,哪部分代表“动态的加塞车辆”,导致常常在博弈中发生灾难性忽视。
- 开环规划与闭环常识的脱节: 仅靠模仿专家轨迹的回归模型,无法理解“为什么要这么开”。一旦遇到微小的环境扰动,由于缺乏底层的几何与运动常识支撑,生成的轨迹极易发生严重的“物理穿模”。
🔧 核心真相:终极拆解“CoWorld-VLA 的四大架构逻辑”
1. 表征真相:用“Latent CoT”替代干瘪的文本推演
- CoWorld-VLA 彻底抛弃了让大模型写小作文的执念。它引入了“潜在思维链(Latent CoT)”,让网络在隐空间内生成蕴含高维时空信息、但对下游 Planner 极度友好的中间态特征,保留了自动驾驶最急需的“几何直觉”。
2. 解耦真相:四大专家(Multi-Expert)分而治之
- 面对复杂的物理世界,一个脑袋不够用。团队通过多源监督信号,在网络内部训练了四位“专家”:Semantic(懂红绿灯和交通标志)、Geometric(懂车道线和路沿边界)、Dynamic(懂其他车辆的运动轨迹)、Intention(懂自车的高层导航意图)。各司其职,彻底解除了特征纠缠。
3. 生成真相:Diffusion 赋予轨迹规划以“想象力”
- 动作的生成不再是死板的一步回归(Regression),而是被建模为一个基于扩散模型(Diffusion-based)的去噪过程。这意味着模型可以在连续的空间中探索多条潜在可行的安全轨迹。
4. 融合真相:HMEF 是约束想象力的物理缰绳
- 扩散模型虽然强大,但容易放飞自我。此时,异构多专家融合机制(HMEF)闪亮登场。在去噪的每一步中,四大专家的先验知识被作为显式条件强行注入(Conditioning),就像给轨迹生成带上了四个“物理防撞护栏”,确保最终输出的动作 100% 合法且安全。
📊 关键内容与数据看板
表1:端到端自动驾驶“推理与表征”范式大对比
| | | | |
|---|
| 无解释纯黑盒 | | | | |
| 文本思维链 (Text CoT) | | | | |
| [Ours] 潜在思维链 (Latent CoT) | CoWorld-VLA | 多维结构化特征 Token | 极高(四大专家各司其职) | 极佳(HMEF 原生无缝融合) |
表2:复杂博弈场景轨迹规划性能演进(基于原论文定性评估)
| | HMEF 多专家融合 (Stage 3) 的表现 | |
|---|
| 无保护左转 (Intersection) | | 弧线极其平滑,严格遵守几何边界 | |
| 动态超车 (Active Overtaking) | | 精准预判目标,留出充足安全冗余 | Dynamic 专家与语义专家的深度介入发挥了作用。 |
注:论文通过 Figure 7 的定性结果无可辩驳地证明,引入“多专家世界先验”作为生成轨迹的条件约束,是消灭自动驾驶模型“常识性违规”的最有效手段。
💬 深度 Q&A
- Q1:既然已经有了强大的 4D 占用网格(Occupancy)或 BEV 预测,为什么 CoWorld-VLA 还要搞这一套“多专家 Token”?A: 4D Occupancy 确实好,但它太“重”了,本质上还是在做纯粹的视觉感知。它无法理解“红绿灯亮起(Semantic)”和“我的导航要左转(Intention)”与“这块砖头能不能压过去(Geometry)”之间的逻辑耦合。CoWorld-VLA 的高明之处,在于它将这四类维度的知识从冗杂的像素场中提取成了高维抽象的“专家 Token”,这让后续的控制头能在概念层面上进行轻量级的交叉注意力计算,而不是被淹没在海量的像素点云里。
- Q2:用 Diffusion 去生成自车的轨迹(Action Generation),算力延迟吃得消吗?A: 这确实是目前学术界向工业界转化时面临的共性挑战。但正如论文中所展示的,Diffusion 在这里解决的是传统回归模型无法处理的“多模态分布(比如路口既可以左转也可以直行)”问题。通过引入多专家条件的强力引导(HMEF),实际上极大地缩小了扩散模型的搜索空间,使得去噪步数有望被大幅压缩。结合一致性蒸馏(Consistency Distillation)等后处理技术,上车实时化是一条必然打通的路径。
- Q3:这个架构对目前的“具身智能(机械臂等)”有参考价值吗?A: 降维打击级的参考价值!具身操作同样面临这个问题:机械臂不仅要知道杯子在哪(几何),还要懂“易碎品不能用力捏(语义)”,更要预判“水会不会洒出来(动态)”。CoWorld-VLA 的这套“将世界模型解耦为多个显式专家特征,再统一融入动作生成”的理念,可以直接平移到千行百业的通用具身大模型中。
🎯 深度点评
- 核心贡献: 千挂科技与顶尖高校的这项联合研究,极其精辟地回答了“世界模型如何真正赋能自动驾驶”。它既没有盲目迷信 LLM 的文本推理,也没有陷入像素级视频生成的算力黑洞,而是以“多专家潜在思维链”的形式,巧妙地在感知与控制之间架起了一座物理逻辑的坚实桥梁。
- 亮点总结:① 清醒的解耦美学:将混沌的物理世界精细拆解为四个维度的专家,让“懂常识”变得可计算。 ② Latent CoT 的崛起:彻底打破了语言模型在自动驾驶中的过度包装,回归了物理控制的空间本质。 ③ 约束即安全:HMEF 将世界先验化作不可逾越的护栏,证明了生成式规划一样可以绝对靠谱。
- 不足与局限:多专家特征的训练依然需要强依赖于“多源监督信号(Multi-source supervision)”(如需要精准的车道线、轨迹等 Ground Truth 标签来分别预训练专家),这在一定程度上限制了其在无人工标注的海量野外驾驶数据(In-the-wild driving logs)上的 Scaling Law 上限。
🌟 总结金句
自动驾驶的终局,绝不是让大模型盲目地做文本选择题,而是在丰富的多专家“潜在思维链”中,精准勾勒出安全的物理未来。
📌 互动引导
在端到端自动驾驶(E2E AD)到底需要怎样的“思维链(CoT)”上,您更支持哪一种路线?
✅ A. 坚决支持 Latent CoT:像 CoWorld-VLA 这样,用隐空间的高维特征保留 3D 几何与物理直觉!
✅ B. 文本 CoT 依然为王:只有自然语言才是最通用的,模型能用语言解释自己的决策才是安全的底线!
✅ C. 不需要 CoT:纯粹大力出奇迹,Sora 能模拟世界,那丢入一万亿英里数据,控制模型自己就会涌现!
✅ D. 大一统方案:小孩子才做选择,文本和 Latent 我全都要,用大语言模型去解读 Latent 特征!
欢迎在评论区留下你的真知灼见! 👇
🧩 研究方向展望
针对冲刺 CVPR / ICCV / NeurIPS / CoRL 等顶级会议的自动驾驶、强化学习及端到端大模型研究者,基于 CoWorld-VLA 提供以下延伸思路:
- 基于自监督解耦的“无标注”多专家世界模型 (Unsupervised Multi-Expert Disentanglement): 针对当前 CoWorld-VLA 四大专家严重依赖显式监督信号(如车道线标签、目标轨迹标签)的痛点。探索在 Latent CoT 生成阶段引入信息瓶颈(Information Bottleneck)或正交约束(Orthogonal Regularization),让网络在仅输入海量无标注第一人称驾驶视频的前提下,自发解耦涌现出代表“静态几何”与“动态意图”的正交专家 Token,极大拓展模型的 Scaling 潜力,适合投递
NeurIPS 或 ICLR。 - 融合 4D 物理风险场的动态专家增强 (4D Risk-Field Enhanced Dynamic Expert): 提升现有的 Dynamic Expert(动态专家)。不仅预测周围车辆的离散轨迹,而是利用条件流匹配(Flow Matching)在隐空间内生成连续的“4D 时空碰撞风险流体场(4D Risk Fluid Field)”。将该连续风险梯度作为 HMEF 中的底层强力软约束,彻底杜绝端到端生成轨迹中的长时空穿模与挤压问题,适合投递
CVPR 或 ICCV。 - 面向 VLA 的闭环强化学习专家微调 (Closed-loop RL for Latent CoT Alignment): 探索将强化学习(RL)算法整合进 CoWorld-VLA 的后训练阶段。在仿真器中,将自动驾驶的碰撞、通行效率、舒适度等实际闭环反馈信号作为奖励(Reward)。利用 PPO 或 DPO 算法,反向微调(Fine-tune)潜在思维链中的四个专家分配权重,让大模型真正学会“针对不同路况,自适应决定该听哪个专家的话”,适合投递
CoRL 或 ICML。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
