STRIVE-D:自动驾驶视频复杂检索
作者 | Manyi Yao、Sparsh Garg、Christian Shelton、Amit Roy-Chowdhury、Abhishek Aich
机构 | NEC Laboratories America / University of California, Riverside
论文标题 | Driving Video Retrieval for Complex Queries with Structured Grounding
arXiv | 2606.09109v1
关键词 | 自动驾驶 / 视频检索 / Structured Grounding / LLM-as-Optimizer / Learning-to-Rank / Dense Retrieval / Rule Calibration / DrivingDojo前言
自动驾驶数据闭环里,有一个很现实但容易被低估的问题:车队每天产生大量视频,真正有价值的稀有事件却藏在海量正常驾驶片段里。工程师想找的往往不是“有一辆车”的场景,而是“前车从左侧 cut-in”“公交车切入 ego lane”“车辆撞上城市护栏”这类带对象、动作和时序关系的复杂事件。
这类查询对普通视觉语言检索并不友好。dense embedding 擅长抓全局场景相似性,但短时运动会被池化进一个整体向量里;关键词检索又依赖视频 caption 是否正好写出事件。结果就是:画面看起来相似的视频排到前面,真正发生 cut-in、急刹、碰撞因果的视频反而被漏掉。
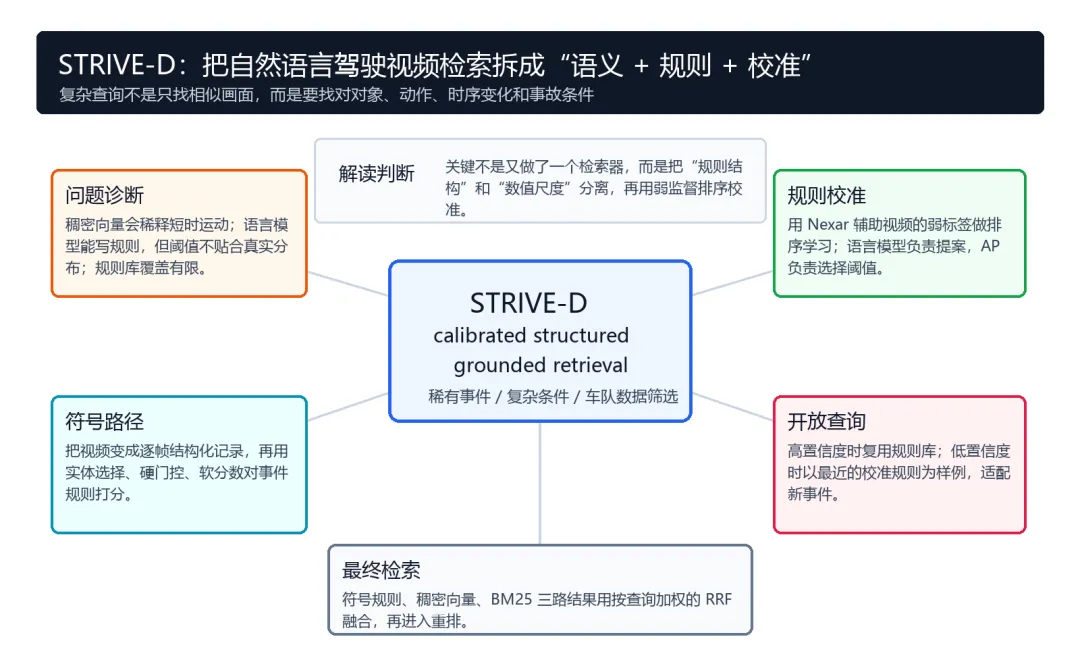
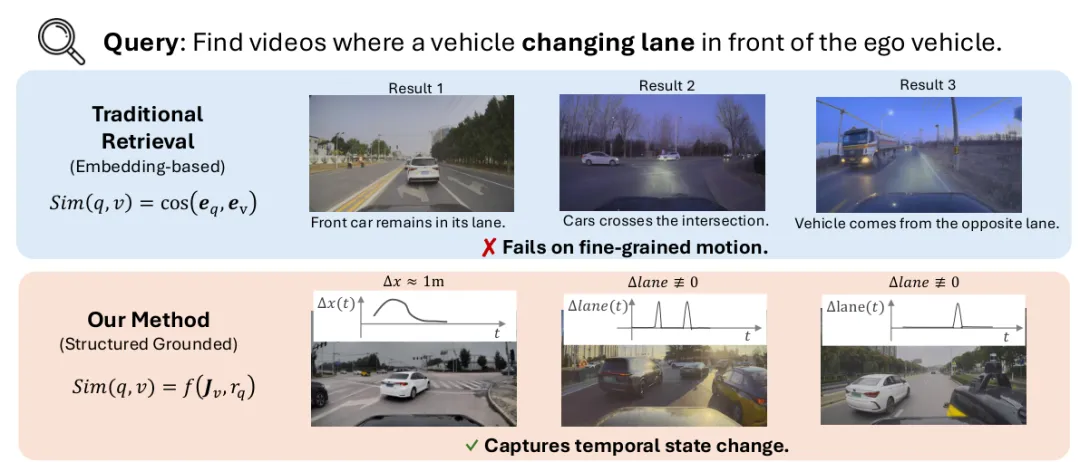
STRIVE-D 的核心判断是:复杂驾驶视频检索不能只靠 embedding,也不能只靠 LLM 现场写规则。更可靠的路线,是让 LLM 负责规则结构,让 in-domain 弱监督数据负责数值阈值校准,再把 symbolic、dense、sparse 三路检索融合起来。图 1:STRIVE-D 的动机。基于 embedding 的检索能抓到全局场景相似性,但经常忽略变道、急刹这类短时运动;结构化 grounding 会显式建模时序状态变化,因此能更准确地检索这类驾驶事件。
图 1 给了一个直观例子。查询是“找出 ego 车前方有车辆变道的视频”。传统 embedding-based retrieval 返回的可能是前车仍在原车道、车辆通过路口、对向车出现等片段,因为这些视频在视觉场景上相似;但它没有真正检查“lane 是否发生变化”。
STRIVE-D 走的是另一条路:先把视频转成逐帧结构化记录,再把查询变成可执行规则。于是相似度不再只是向量余弦,而是可以显式检查对象位置、车道变化和时间窗口:
这里的 J_v 可以理解为视频的结构化状态序列,r_q 是查询对应的符号规则。这个转变很关键:检索对象从“这段视频像不像这句话”变成“这段视频是否满足这组事件条件”。
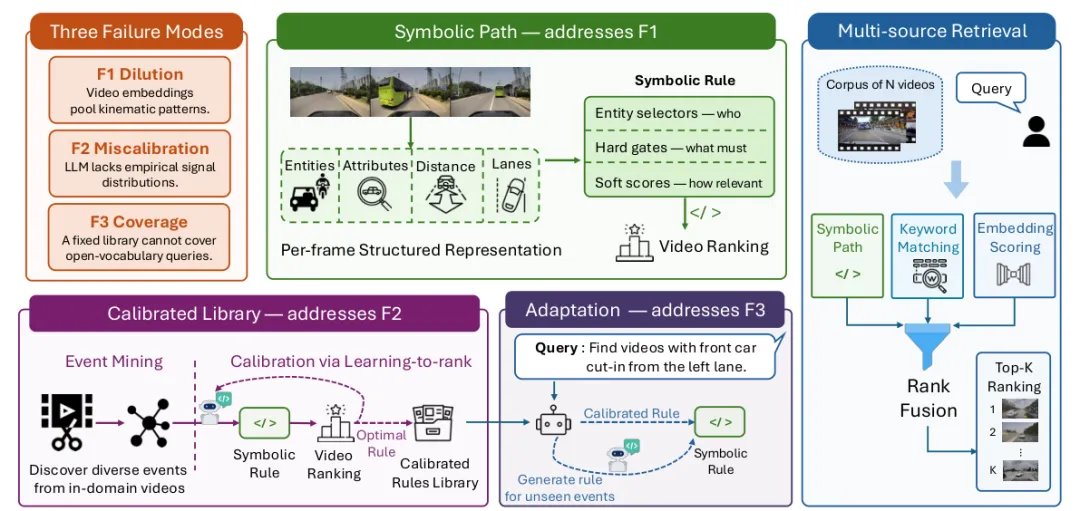
三个失败模式
论文把现有驾驶视频检索的问题拆得很清楚:
- F1:Dilution。 dense embedding 会把短时运动模式混进整体场景表征里,cut-in、hard braking 这类动态事件容易被稀释。
- F2:Miscalibration。 LLM 能写出看起来合理的规则,但距离阈值、速度变化、时间窗口这些数值,常常不符合真实感知管线的数据分布。
- F3:Coverage。 固定规则库不可能覆盖所有开放词表查询,遇到新事件或组合条件时,需要能适配。
这三个问题分别对应 STRIVE-D 的三个组件:symbolic path 解决运动信号被稀释,calibrated library 解决规则阈值不准,confidence-aware adaptation 解决规则库覆盖不足。最后再用 multi-source retrieval 把 symbolic、dense 和 BM25 融合。
图 2:STRIVE-D 总览。论文把驾驶视频检索的失败模式分成三类:运动信号被 dense embedding 稀释、LLM 生成规则与真实信号分布错配、固定规则库无法覆盖开放词表查询;对应组件是 symbolic path、calibrated library、adaptation 和 multi-source retrieval。
符号规则:不是把检索变成硬匹配
一个容易误解的点是:结构化检索并不等于简单 if-else。STRIVE-D 的规则由三部分组成:
- Entity selectors: 决定看谁,比如 car、truck、bus、pedestrian。
- Hard gates: 决定必须满足什么前置条件,比如距离 ego 小于某个阈值。
- Soft scores: 决定匹配强度,比如横向位移在一个时间窗口内变化多少。
最终运动相关性分数可以概括成:
hard gate 负责把明显不合格的视频过滤掉,soft score 负责区分“强匹配”和“勉强匹配”。这也是它比二值规则更适合排序的原因:视频检索的核心不是只判 yes/no,而是把最相关的视频排到最前面。
Listing 1:cut-in 事件的校准符号规则。规则结构固定为实体选择、硬门控和软分数;距离阈值、时间窗口、运动幅度等数值由 learning-to-rank 在辅助数据上校准。
Listing 1 展示的是 cut-in 事件。规则结构并不复杂:对象限定为 car / truck,距离要小于 40m,再检查横向位置 loc_x 在 4 秒窗口内是否有足够变化。真正重要的是,40.0、4.0、14.0 这些数不是拍脑袋写的,而是被校准出来的。
这篇论文最值得看的技术点,正是把“LLM 写规则”和“数据校准数值”拆开。LLM 擅长提出结构,但不擅长知道当前感知系统里的 14 米横移到底代表强 cut-in 还是噪声;这个尺度必须从实际数据里学。用弱监督校准规则
STRIVE-D 不使用目标 benchmark 的标签来建规则库,而是从 1,147 个 Nexar 训练视频里挖事件。流程是:视频 captioner 先生成偏运动描述的 caption,LLM 从 caption 中抽取事件类别,把含有某事件的视频当作弱正样本,其余当作负样本。随后,在这些视频的逐帧结构化记录上运行候选规则。
校准目标是 average precision:
LLM 在每轮提出一组数值约束,系统计算这组规则对正负样本排序的 AP,再把当前 AP 和历史最好规则反馈给 LLM,让它继续修正。循环最多 20 轮,最后把 best-so-far 规则写入 calibrated library。
这个设计有两个细节很有意思。
第一,caption 只用来提供弱标签,不直接参与检索打分;真正打分的是结构化感知记录。
第二,AP 会在许多正负样本上平均掉 caption 噪声,比“每个视频 caption 和 query 直接匹配”更稳。
开放查询:复用还是生成
规则库只有 21 个事件类别,不可能覆盖所有自然语言查询。所以 STRIVE-D 在查询时会先让 LLM 找最接近的库内事件,并给出置信度 s_conf。当 s_conf >= 0.6 时直接复用校准规则;否则让 LLM 以最近的校准规则为 in-context exemplar,生成一个适配当前查询的新规则。
这样做比完全从零生成规则更稳。新规则可以改变结构以适应开放查询,但仍能继承相近事件的阈值尺度,避免回到“LLM 自己猜数值”的老问题。
最后,STRIVE-D 不把 symbolic path 当成唯一入口,而是与 dense embedding 和 BM25 做 query-conditioned weighted reciprocal rank fusion:
dense path 负责补场景语义和视觉描述,BM25 负责稀有实体和词面线索,symbolic path 负责精确运动事件。三者不是替代关系,而是互补关系。
主结果:提升主要发生在榜首精度
实验覆盖三套驾驶视频数据:DrivingDojo 关注细粒度运动事件,CarCrashDataset 关注事故原因,MM-AU 关注事故描述。评价指标包括 Acc@K、MRR 和 mAP。
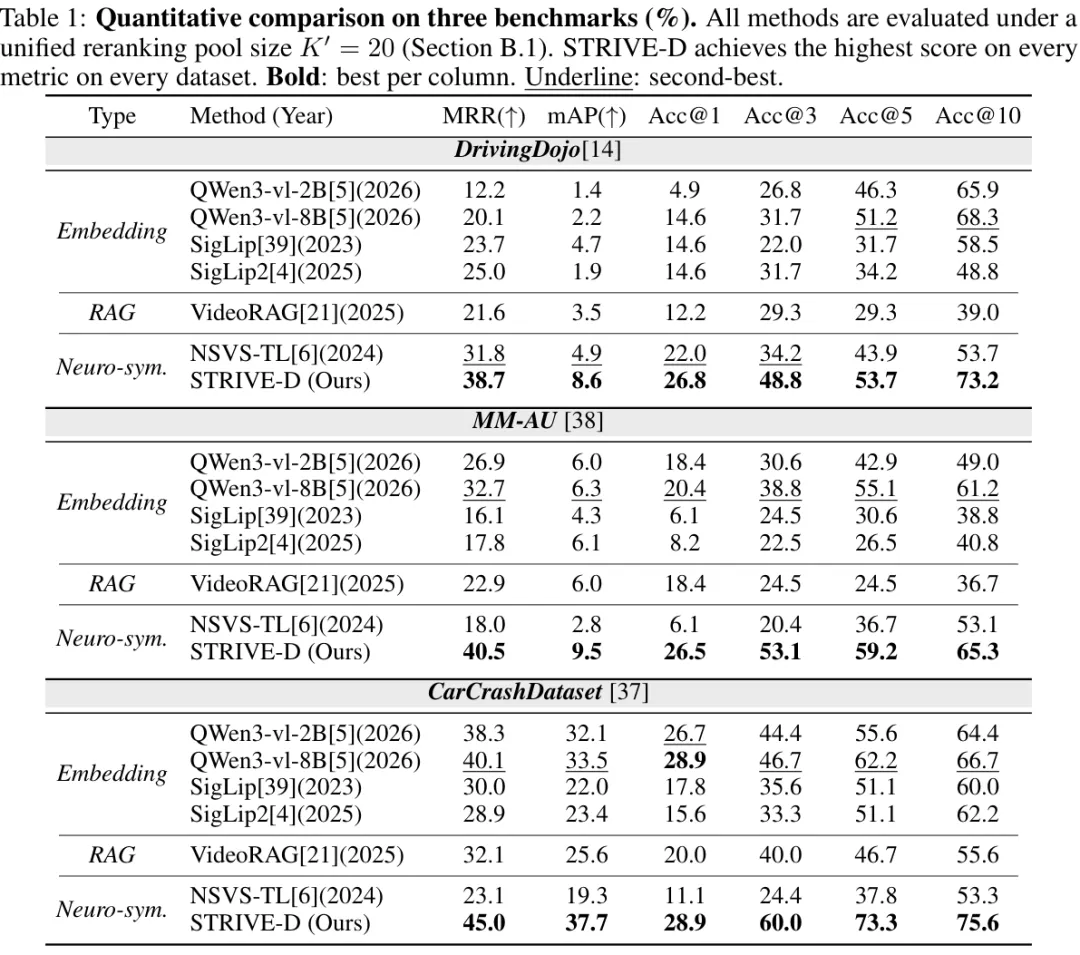
表 1 里最值得看的是榜首精度。DrivingDojo 上,STRIVE-D 的 Acc@1 是 26.8%,最强 dense baseline Qwen3-VL-8B 是 14.6%,相对提升 83.6%;mAP 从 4.7% 提到 8.6%。MM-AU 上 Acc@1 从 20.4% 提到 26.5%。CarCrashDataset 上 Acc@1 与最强 baseline 打平,但 MRR、mAP、Acc@3/5/10 全部更高。
表 1:三套 benchmark 的量化对比。所有方法使用统一的 reranking pool size K'=20;STRIVE-D 在 DrivingDojo、MM-AU、CarCrashDataset 的所有指标上都取得最高结果。
这说明 STRIVE-D 的优势不主要体现在“广义召回”,而是体现在 top-of-list precision。换句话说,它更擅长把真正满足复杂条件的视频放到最前面,这正是数据筛选和安全验证最关心的位置。
对于车队数据检索,Acc@10 很重要,但 Acc@1 / MRR 更接近真实使用体验。工程师希望第一批打开的视频就是对的,而不是翻十几个相似场景后才找到目标事件。消融:三条路径都不能少
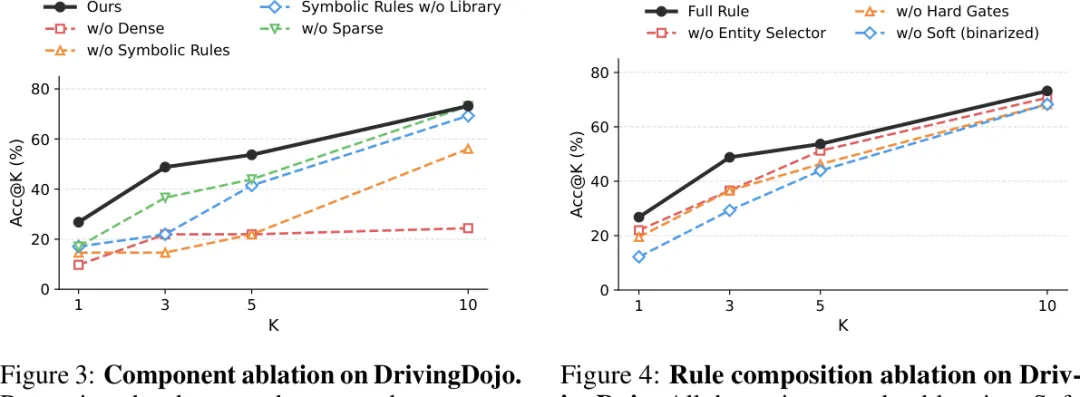
Figure 3 的 component ablation 很直接:移除 dense path 后,Top-1 从 26.8% 掉到 9.76%,说明 symbolic + sparse 不能完全替代视觉语义;移除 symbolic rules 或 calibrated library,也会明显伤害 Top-3 / Top-1,说明运动规则和阈值校准确实在工作。移除 sparse retrieval 对 Top-10 影响小,但会轻微伤害 top-rank precision,符合它主要补稀有实体的定位。
Figure 4 则说明规则内部也不能随便删。把 soft scores 二值化后,Acc@1 从 26.8% 掉到 12.2%;去掉 hard gates 会损失 7.3 个点;去掉 entity selector 损失 4.8 个点。结论是:软分数负责排序强度,硬门控负责排除假阳性,实体选择负责对象对齐。
图 3 / 图 4:DrivingDojo 消融实验。移除 dense path、symbolic rules、calibrated library 或 sparse retrieval 会对应暴露不同失败模式;规则内部的 entity selectors、hard gates、soft scores 也都承担有效作用。
泛化与效率
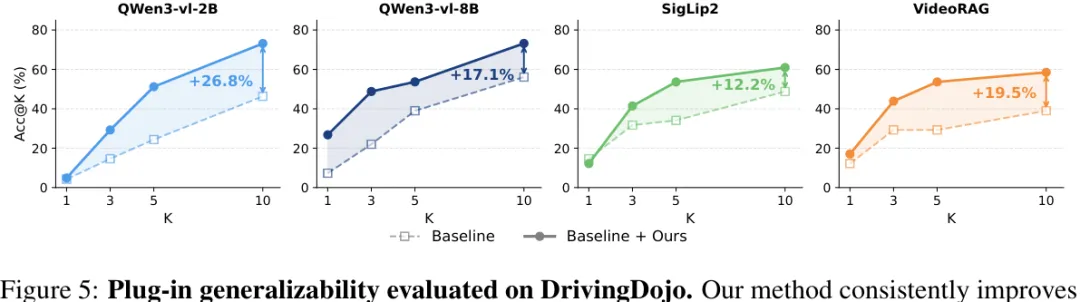
STRIVE-D 还验证了一个 plug-in 用法:把它的 symbolic-rule pathway 接到不同现成检索器上。Qwen3-VL-2B、Qwen3-VL-8B、SigLIP2、VideoRAG 四个骨干上,Top-10 accuracy 都提升,增益从 12.2 到 26.8 个百分点不等。
图 5:作为 plug-in 的泛化性。在 Qwen3-VL、SigLIP2、VideoRAG 等不同检索骨干上加入 STRIVE-D 的符号规则路径,Top-10 accuracy 均有提升。
效率上需要分开看。STRIVE-D 平均每个 query 需要 3.10 秒,比纯 embedding 检索的几十到一百多毫秒慢很多;但相比 NSVS-TL 的 4868.05 秒,约快 1500 倍。这说明它不是最轻的第一阶段召回器,更适合作为面向复杂事件的精排/重排路径。
论文还测试了一个直觉 baseline:直接问 Qwen3-VL-8B-Instruct“这个视频是否包含 q?”再按 yes 概率排序。结果 Acc@1 只有 2.4%,加 reranker 也只有 7.3%,远低于 STRIVE-D 的 26.8%。这基本说明:对复杂驾驶事件,逐视频 yes/no VLM 判别并不是一个强检索方案。
表 2 / 表 3:延迟与 VLM 二分类基线。STRIVE-D 每个查询平均 3.10 秒,明显慢于纯 embedding 检索,但远快于 NSVS-TL;直接问 VLM“这个视频是否包含查询事件”在 DrivingDojo 上效果并不理想。
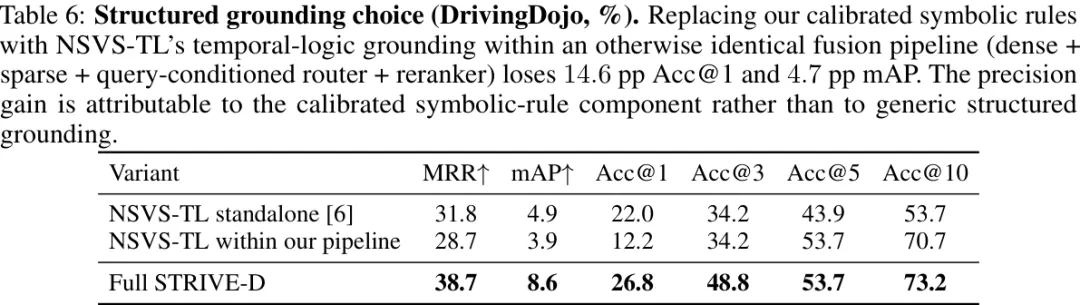
附录里还有一个很重要的对照:把 STRIVE-D 的 calibrated symbolic rules 替换成 NSVS-TL 的 temporal-logic grounding,但保留同样的 dense+sparse+router+reranker 管线。结果 Acc@1 从 26.8% 掉到 12.2%,mAP 从 8.6% 掉到 3.9%。
表 6:结构化 grounding 选择消融。把 STRIVE-D 的校准符号规则替换为 NSVS-TL 的时序逻辑 grounding,即使保持同样的 dense+sparse+router+reranker 管线,Acc@1 仍下降 14.6 个百分点。
这就把贡献定位得更清楚了:提升不是简单来自“用了结构化 grounding”或“用了融合管线”,而是来自有校准尺度的、可产生 graded score 的符号规则。
表 7:STRIVE-D 延迟拆分。rule synthesis 和 multi-source fusion 两个 LLM 阶段占总延迟约 87%;sparse、dense、rule matching 三个检索分支合计约 384ms。
质性案例
Figure 6 的案例很贴近真实检索痛点。对于 bus cut-in,SigLIP2 和 Qwen3-VL 能找到公交车,但没有找到切入动作;对于 car collision with city guardrails,基线可能找到碰撞但没有护栏,或者找到护栏但没有碰撞。
图 6:质性检索对比。对于 bus cut-in,基线能找到公交车但漏掉 cut-in 动作;对于 car collision with city guardrails,基线只匹配到碰撞或护栏的一半语义,而 STRIVE-D 同时匹配对象和事件。
STRIVE-D 的优势在于,它不是只匹配“bus”“guardrail”“collision”这些局部语义,而是把对象和事件组合起来检查。这类组合条件,正是自动驾驶安全分析里最常见、也最容易被普通检索漏掉的部分。
局限
这篇论文的限制也比较明确。第一,STRIVE-D 依赖上游感知管线,把视频转成对象类别、距离、lane assignment、lateral offset 等结构化记录;如果感知出错,规则检索也会被带偏。第二,规则库只有 21 个事件,虽然有 adaptation,但复杂开放查询仍可能生成不够稳的规则。第三,GPT-4.1 参与规则合成、matcher 和 fusion router,3.10 秒的延迟对离线数据挖掘可接受,但对高并发交互式检索还需要缓存和工程优化。
因此 STRIVE-D 更像是一个“复杂事件检索增强器”,而不是要替代所有 dense retrieval。它适合用于稀有事件挖掘、长尾安全 case mining、事故/near-miss 数据筛选这类需要高精度结构条件的场景。结论
STRIVE-D 的贡献可以概括成三点:
- 第一,它把驾驶视频检索的失败模式拆清楚了。 dense embedding 会稀释运动,LLM 规则会错配阈值,固定规则库会有覆盖缺口。
- 第二,它提出了可校准的结构化规则路径。 LLM 负责结构,learning-to-rank 用弱监督辅助视频校准数值,让规则从“看起来合理”变成“在真实数据分布上可排序”。
- 第三,它证明 symbolic、dense、sparse 应该融合。 复杂查询既需要场景语义,也需要稀有词面线索,更需要对象和运动约束。
这篇论文最值得保留的判断是:面向自动驾驶的数据检索,下一步不只是更大的 VLM embedding,而是要把语言查询落到可校准、可解释、可组合的时空结构上。
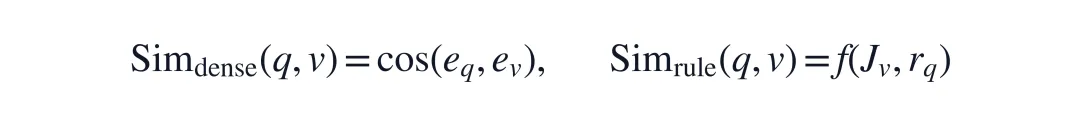
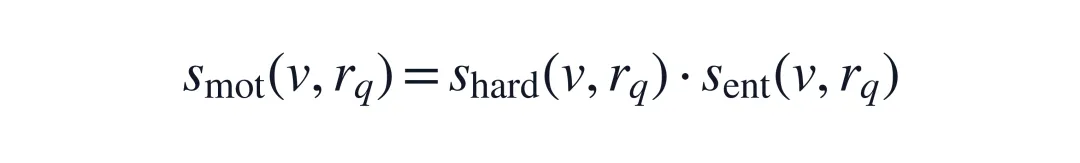

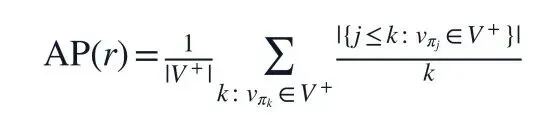
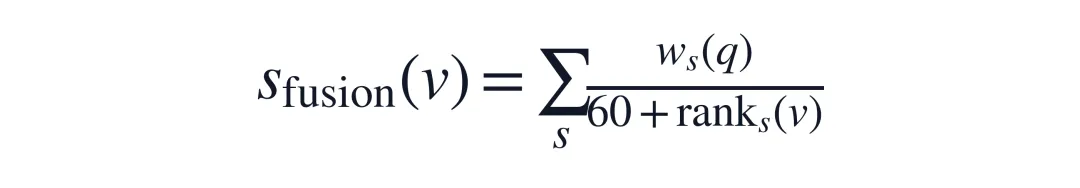



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
