
扫描下方二维码,添加交流群深入交流
自动驾驶想真正落地,有一个绕不开的终结难题:在车水马龙、人车混杂的街头,如何让AI像老司机一样,不仅看清眼前有什么,更能“读懂”这些物体之间千丝万缕的关系?今天,我们要深挖一个全新的框架——上下文中心特征融合(CCFF)。它不走寻常路,直接让模型学会了推理物体之间的“共现关系”,在几乎不增加算力负担的情况下,把那些传统模型难以捕捉的小目标、罕见物体的检测精度推向新高。
🔥 开源代码已放出:https://github.com/BinayKSingh/CCFF[1]
核心痛点:为什么你的检测模型总在街头“翻车”?
在标准的自动驾驶测试集上,很多检测器的分数已经卷到了天花板。但一到真实路况,问题就接踵而至。为什么?
因为现实场景充满了“歧义”。一辆部分被树木遮挡的汽车,或者一个逆光下模糊不清的行人,单靠局部外观做判断,极容易漏检或误判。更别提那些在数据集中本就低频的“稀有物种”——比如一辆老式有轨电车或一个骑马的骑手。
问题的根源在于,传统的检测流程,尤其是我们熟悉的Faster R-CNN等两阶段框架,处理每个候选区域时本质上是“孤立的”。它只盯着你给它框出来的那一小块区域提取特征,却完全忽略了周围环境能提供的强有力先验。比如,在人行横道旁,出现行人的概率自然更高;在拥挤的十字路口,车辆之间一定存在某种交互逻辑。
这种对“上下文关系”和“全局场景逻辑”的无视,让小尺度、严重遮挡或尾部类别的检测成了老大难。而今天解读的CCFF框架,就是为了从根源上解决这个“逻辑盲区”。
原理拆解:给检测器装上“逻辑推理引擎”
传统的检测头像一个近视的观察者,只盯着孤立的物体看。CCFF要做的,就是给它配上一副能洞察全局的“逻辑眼镜”。这副眼镜包含两个核心镜片,分别处理局部和全局的上下文信息。
我们先来看一下这套系统的全貌。
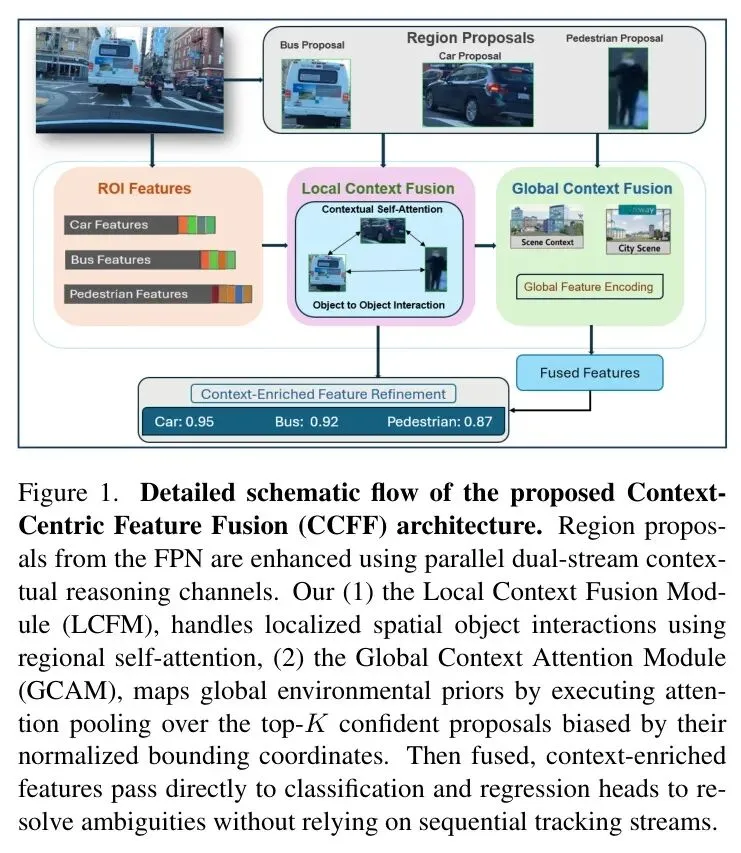 图1:Context-Centric Feature Fusion (CCFF) 整体架构图,展示了从输入图像提取ROI特征后,如何通过并行的局部与全局上下文模块进行特征增强,最终输出检测结果的完整流程。
图1:Context-Centric Feature Fusion (CCFF) 整体架构图,展示了从输入图像提取ROI特征后,如何通过并行的局部与全局上下文模块进行特征增强,最终输出检测结果的完整流程。这张架构图清晰地展示了CCFF的核心思想。输入图像经过基础的Backbone和FPN(特征金字塔网络)后,会生成一系列候选区域(Region Proposals)及其对应的ROI特征。在传统方法中,这些ROI特征会被直接送入检测头进行分类和回归。但CCFF在这里插入了一个关键的“上下文增强”阶段,它由两个并行的模块组成,共同为原始的ROI特征注入环境信息,然后再进行检测。接下来,我们就深入拆解这两个精妙的设计。
💡 局部交互:空间自注意力
在拥挤的交通场景中,物体的命运往往紧密相连。一辆车旁往往有其他车,行人周围也总会有关联的物体。为了建模这种邻近物体间的交互,作者设计了局部上下文融合模块(LCFM)。
它的核心思想非常直接:利用ROI到ROI的自注意力机制。这就像让每个候选框都“看一眼”场景中的其他所有候选框,自己判断谁跟自己关系密切。
具体来说,对于N个ROI特征,我们首先通过可学习的线性投影,为每个ROI特征 计算出它在注意力机制中的Query、Key和Value:
有了这些,我们就可以计算任意两个ROI之间的注意力权重,它代表着ROI 对ROI 的重要性:
这个公式的本质,是在为每个ROI计算所有其他ROI对它而言的“信息价值”打分。最后,ROI 的局部上下文特征,就是所有其他ROI的Value特征加权求和的结果:
最终,这个包含局部交互信息的特征会通过一种残差连接的方式,增强原始的ROI特征。这相当于告诉模型:你不再仅仅是你自己,你还承载着你与邻居的互动信息。
这样一来,一个部分被遮挡的车辆,就能通过它旁边清晰可见的车灯或另一辆车,获得更强的特征补充,从而被更稳定地检测出来。
💡 全局先验:以目标为中心的注意力
局部交互虽然强大,但始终是“只见树木,不见森林”的。一个在城市街道上行驶的自动驾驶系统,需要理解更高层面的场景逻辑。以往的方法可能会对整个特征图进行全局池化,计算开销巨大且可能引入噪声。
CCFF提出了一个极其高效而优雅的设计——全局上下文注意力模块(GCAM)。它的关键创新在于:**不直接从像素级特征图提取全局信息,而是从已经提取好的ROI特征中进行筛选和聚合。**这就好比,要理解一个会议的氛围,你不需要观察会场里每个人的每一个细微表情,只需要听少数几个关键人物的发言就够了。具体怎么做呢?分三步走。**第一步:Top-K筛选。**我们不需要所有N个候选ROI来代表全局,只需要选出那些“最有话语权”的K个(K远小于N)。选择标准可以是它们的“物体性”(objectness)得分或者分类置信度。这些高置信度的Top-K ROI(比如一辆大卡车、一个明显的行人),构成了场景全局语境的核心表征。**第二步:几何感知注意力。**单纯的视觉特征在被聚合成全局上下文时,常常会忽略一个关键信息:位置和尺度。比如,交通信号灯通常位于图像上方,而路面标记在下方;远处的物体通常更小。为了让模型敏锐地捕捉到这些规律,GCAM在计算每个Top-K ROI的注意力得分时,显式地注入了几何偏置。
它将ROI的坐标和尺寸编码成一个几何向量:
最终的注意力打分,由“内容分”和“几何分”两部分构成:
这个设计太巧妙了!它让模型不仅能“看”到什么物体是重要的,还能“感知”到这些物体在空间中的典型位置和尺度,从而彻底理解了场景的结构。例如,模型会学到,在图像上方区域出现的、具有较大尺寸的实体,可能是一个关键的地标性建筑或大型车辆,对理解整个场景至关重要。
第三步:上下文注入。对得分进行Softmax归一化后,对所有Top-K ROI的特征进行加权求和,就得到了一个紧凑的、以目标为中心的全局上下文向量。最后,这个承载着全局先验的向量,会被广播并添加到每一个原始的ROI特征上,让每个局部的检测都带上了全局视野。
💡 终极融合与训练
最终,每个ROI都获得了三重信息:原始的外观特征、编码了邻居交互的局部上下文特征,以及代表了整个场景逻辑的全局上下文向量。CCFF将这三种特征拼接起来,通过一个轻量级的MLP进行融合,生成最终的、富含上下文的特征表示。
整个流程从头到尾都是可微的,这意味着模型可以端到端地、优雅地学习如何进行上下文推理,而无需任何额外的人工标注或复杂的监督信号。模型的损失函数依然是标准的分类和回归损失:
这个思考过程,是否让你对目标检测中的“上下文”有了全新的认识?我们不再需要依赖笨重的全图级Transformer,而是可以用这样精巧的结构化设计,高效地达到同样的目的。
实验验证:数据会说话,关系能被“看见”
光说不练假把式。为了证明CCFF的有效性,作者在两个核心的自动驾驶数据集Cityscapes和BDD100K上进行了严苛的验证。除了标准的AP指标,他们还特别引入了CoAP(共现平均精度)和CCS(类别级一致性策略),专门用来衡量模型对物体间关系和场景结构逻辑的理解能力。
🏆 SOTA对比与定量分析
首先,让我们来看看在Cityscapes数据集上的消融分析。
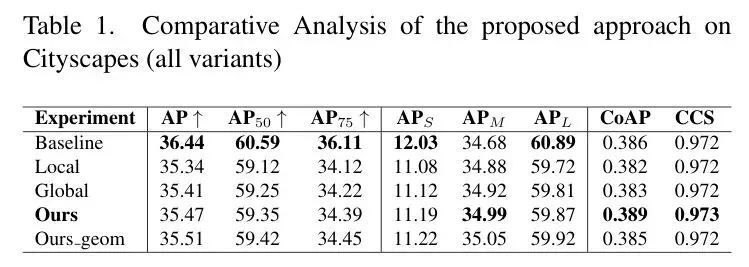 表1:Cityscapes数据集上对各组件的消融实验,对比了Baseline、Local、Global、Ours及Ours_geom等配置的性能。
表1:Cityscapes数据集上对各组件的消融实验,对比了Baseline、Local、Global、Ours及Ours_geom等配置的性能。从表1中,我们能读到几个非常振奋人心的信息。首先,看关系指标。开启完整CCFF的模型(Ours),CoAP达到了0.389,CCS达到了0.973,显著优于Baseline模型。这表明模型不再是把检测看成一个个孤立的事件,而是真正学会了捕捉物体间的语义依赖,它预测出的检测结果,在空间排序和上下文精度上与真实的驾驶场景布局保持高度一致。
其次,在极度考验逻辑推理能力的中等尺度目标(AP_M)上,CCFF达到了34.99%,超越了Baseline的34.68%。这个尺度的物体是典型的“关系型”目标,它们需要借助周围的物体来消除自身的歧义。这个结果恰好完美验证了CCFF的设计初衷——通过邻近实例的特征来增强自身,正是解决歧义的关键。
再来看更挑战的BDD100K数据集,这个数据集包含多样的天气和光照条件,对模型的泛化能力要求极高。
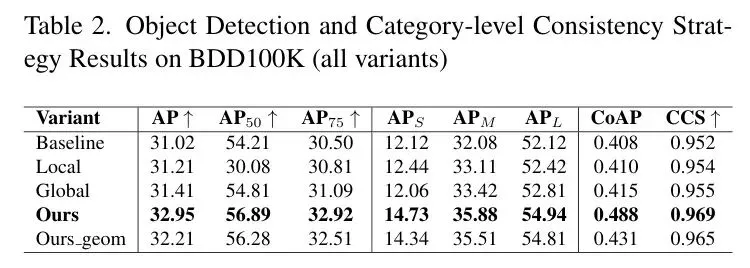 表2:BDD100K数据集上的消融实验,验证了类别级一致性策略及各组件的有效性。
表2:BDD100K数据集上的消融实验,验证了类别级一致性策略及各组件的有效性。结果更加令人惊喜。表2中,完整CCFF的CoAP飙升至0.488,CCS也高达0.969,再次碾压Baseline。更关键的是,在**小目标检测(AP_S)上,CCFF取得了惊人的14.73%的AP,提升巨大。这充分证明了,通过利用高置信度大目标的特征来“激活”远处或模糊的小目标,CCFF成功恢复了那些传统模型几乎完全丢失的信息,让整体AP达到了32.95%**的竞争力水平。
📊 可视化:当逻辑变得可见
数据之外,我们能更直观地通过可视化结果感受到CCFF的“逻辑推理”能力。
 图2:Cityscapes街景中的语义共现关系推理可视化,彩色连线揭示了CCFF学习到的物体间交互逻辑。
图2:Cityscapes街景中的语义共现关系推理可视化,彩色连线揭示了CCFF学习到的物体间交互逻辑。图2非常震撼。模型不仅准确地检测出了行人、汽车、自行车等常规目标,更重要的是,它输出了一张“关系图谱”,用彩色连线直观地揭示了“人-车”“人-自行车”等显式的共现关系。连线的粗细甚至代表了注意力的置信度!这根本不是简单的检测,这是对场景结构的深度理解。值得注意的是,即使是对“骑手”这类尾部类别,模型也达到了89%的高置信度。
再看一个更复杂的场景。
 图3:CCFF在异构城市驾驶环境中的尺度鲁棒性展示,可见其利用高置信度锚点(如火车)稳定识别远处和遮挡目标的优势。
图3:CCFF在异构城市驾驶环境中的尺度鲁棒性展示,可见其利用高置信度锚点(如火车)稳定识别远处和遮挡目标的优势。图3展示了CCFF惊人的尺度鲁棒性。一辆巨大的有轨电车以99%的置信度被检测出来,成为了场景的“上下文锚点”。然后,模型利用这个高置信度锚点,通过“人-公交车”等共现链接,成功地恢复并识别出了画面远处和阴影中那些尺度极小、面临严重遮挡的背景实例。这张图是CCFF设计哲学的最佳体现:用已知推理未知,用“整体”理解“局部”。
🔬 深度消融:谁才是真正的功臣?
为了搞清楚局部、全局和几何先验各自扮演的角色,作者进行了更精细的消融。
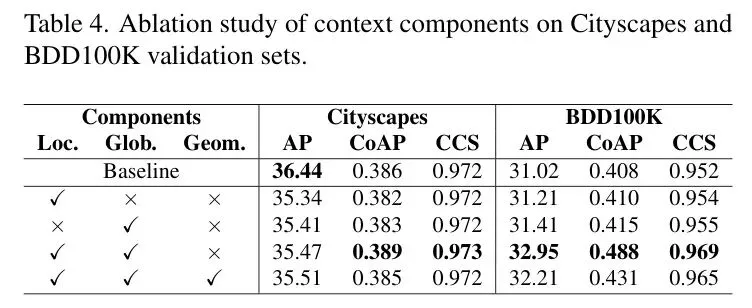 表4:上下文组件(Local, Global, Geometric)的消融研究,揭示了各模块联合使用的必要性。
表4:上下文组件(Local, Global, Geometric)的消融研究,揭示了各模块联合使用的必要性。表4清晰地展示了“1+1>2”的效果。单独引入局部或全局模块,相比Baseline均有增益,但只有将两者结合起来,性能才实现质的飞跃。在BDD100K上,Local+Global的组合直接将AP推至32.95,CoAP达到0.488的峰值。而进一步加入几何偏置(Local+Global+Geometric)虽然AP略有不同,但它在Cityscapes上贡献了35.51的组件最高AP,并在多个数据集上提供了更稳定的性能,扮演了“结构稳定器”的角色。这完美印证了,在复杂场景中,同时理解“邻居在做什么”和“整个场景是什么”是至关重要的,而几何位置信息则是不可或缺的定海神针。
最后,效率如何?
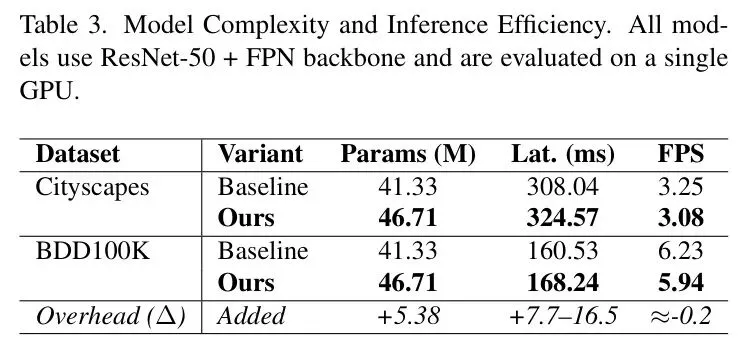 表3:模型复杂度与推理效率分析,显示CCFF在仅增加少量参数和延迟的情况下实现了显著的性能提升。
表3:模型复杂度与推理效率分析,显示CCFF在仅增加少量参数和延迟的情况下实现了显著的性能提升。从表3可以看出,CCFF仅增加了5.38M参数,推理延迟增加7.7~16.5毫秒,FPS仅下降约0.2。这点微乎其微的开销换来的是对复杂场景理解能力的巨大飞跃,可以说性价比极高,完全具备实时部署的可行性。
客观评价
尽管CCFF效果惊人,但它并非万能。作为一个插拔式模块,其增益高度依赖于基线检测器生成的候选框质量。如果RPN阶段就漏掉了关键目标,后续的上下文推理也就无从谈起。
此外,Top-K的选择策略虽然巧妙,但固定的K值在面对目标数量差异极大的场景(如空旷的高速 vs 拥挤的闹市)时,可能无法做到最优。这为未来的自适应K值选择研究留下了空间。其以0.2 FPS为代价的性能提升,证明了在严格的时间预算内,旨在关系的结构化推理比盲目的全图全局池化更为高效。
价值升华
CCFF的出现,为自动驾驶中的目标检测指出了一个更具潜力的方向:从“我看到了什么”转向“我看到了什么,并且它们之间意味着什么”。它的价值不仅在于性能数字的提升,更在于其设计哲学上的启发。
- 结构化先验胜过暴力计算:通过ROI-to-ROI的自注意力和基于Top-K的全局池化,CCFF用精巧的结构设计,实现了媲美复杂Transformer的上下文建模能力,同时保持了轻量和高效。
- 显式关系推理是可解释性的基石:可视化中的“关系连线”让我们得以一窥模型的决策逻辑,这对于提升自动驾驶系统的安全性和可信性至关重要。
- 解决长尾问题的新范式:利用高置信度的常见目标作为“锚点”去激活罕见目标,是解决自动驾驶长尾分布问题的绝佳思路。
🤔 深度思考:你认为这种显式的物体关系推理,最可能率先颠覆自动驾驶的哪个子任务?是预测、规划,还是仿真模拟?欢迎在评论区留下你的观点!
💝 支持原创:如果本文帮到了你,点个赞和在看就是最好的支持!分享给你的技术伙伴,一起深挖AI前沿!
🔔 关注提醒:设为星标,不错过每一次深度技术解读!
#AI技术 #深度学习 #目标检测 #自动驾驶 #论文解读 #上下文推理
参考
Context-Aware Feature-Fusion for Co-occurring Object Detection in Autonomous Driving
引用链接
[1]: https://github.com/BinayKSingh/CCFF

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
