点击下方卡片,关注“人工智能AI与算法”公众号
BeyondDrive 是目前把端到端自动驾驶的安全边界问题拉得最正的一篇 ECCV 2026 论文。不教模型怎么开车,而是教它“什么绝对不能做”。
在端到端自动驾驶领域,长久以来存在一个不成文的“金科玉律”:让模型的预测轨迹无限逼近人类专家的驾驶轨迹。
无论是早期的行为克隆,还是如今火爆的扩散策略(Diffusion Policy),其训练核心逻辑高度一致——计算预测轨迹与真实专家轨迹之间的均方误差(MSE)或平滑 L1 损失,然后梯度回传,让模型“模仿”得越来越像。
然而,这篇由中科院自动化所、小米和复旦联合完成的 ECCV 2026 中稿论文,却一针见血地指出了这一范式的致命漏洞:
“空间上的几何接近,绝不等于驾驶行为上的安全。”
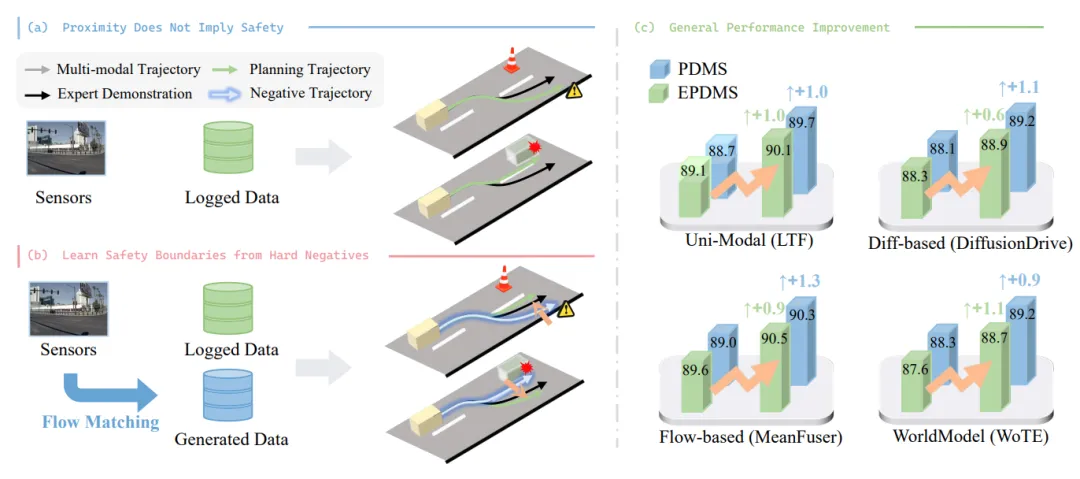
作者将这种现象定义为 “安全不对称性”(Safety Asymmetry) 。简单来说,有两条轨迹 A 和 B,它们与人类驾驶的“标准答案”在像素级坐标上只差了 5 厘米,但在现实物理世界中,轨迹 A 恰好避过了鬼探头,而轨迹 B 却把行人撞飞了。
传统模仿学习对此毫无感知,因为它的 Loss 函数里没有“碰撞”这个概念。模型只学会了“像人一样打方向盘”,却没有学会“打这个方向盘会死人”。
或许你会问:现在的端到端模型(比如 UniAD、VAD)不是已经引入多模态轨迹或规划评估模块了吗?它们难道不能识别危险?
答案是:能识别,但学不到教训。
目前主流的带评分的多模态轨迹生成方法(如 DiffusionDrive 等),其工作流程是:生成 N 条候选轨迹 -> 用评分器(Scorer)打分 -> 选出最高分的一条执行。
在这个过程中,评分器确实能发现那条会导致碰撞的“坏轨迹”(负样本),并将其排在最后。但问题出在训练阶段——当评分器把坏轨迹排在最后时,反向传播的梯度主要在优化“排序分数”,而不是在优化“特征表征的安全性”。
更糟糕的是,这些模型从未被强制要求去深刻记忆那条坏轨迹为什么坏。在巨大的 L2 损失主导下,模型依然倾向于生成与专家轨迹“长得像”的轨迹,即使它隐含碰撞风险。模型处于一种“知其然(知道怎么做),却不知其所以不(不知道绝对不能怎么做)”的混沌状态。
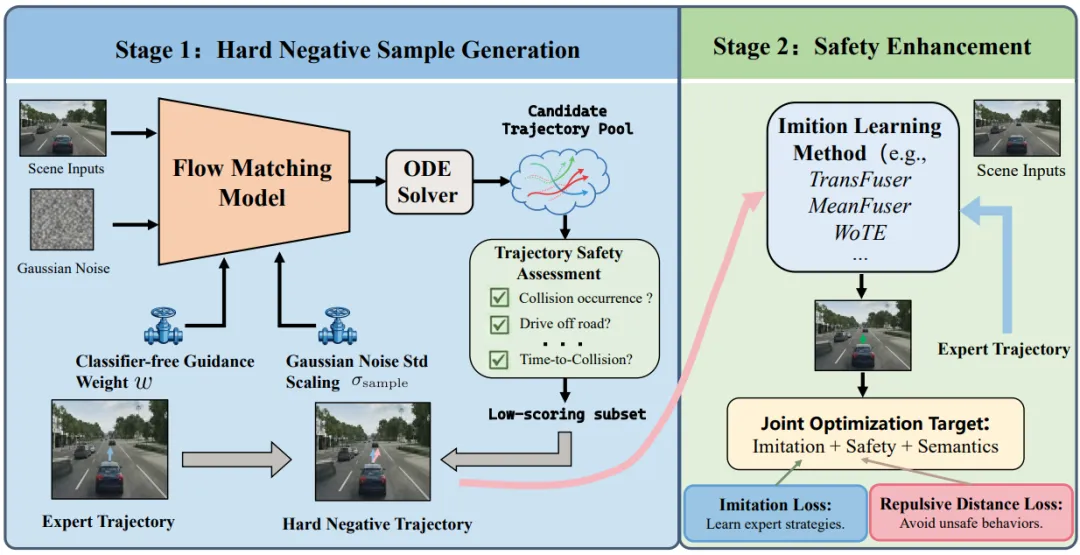
TransFuser v7(BeyondDrive)的“难负样本”革命因此,研究团队提出了名为 BeyondDrive 的全新框架(基于 TransFuser v7 架构实现)。其核心哲学极其硬核:
从“正向模仿”转向“双向边界学习”——不仅要拟合正样本(专家轨迹),更要显式地利用“难负样本(Hard Negatives)”构建安全边界。
下面拆解这项工作的三大核心技术突破:
1. 什么是“难负样本”?
团队并没有简单地使用随机噪声或任意错误轨迹作为负样本。他们挖掘的是 “Hard Negatives” ,即那些在几何指标(L2误差)上与专家轨迹极其相似,但在安全评估(碰撞检测、舒适度)上极其失败的轨迹。
这些“伪装者”轨迹是传统模型最难辨别的,也是导致事故的主要原因。通过在训练集中显式注入并标注这些 Hard Negatives,模型被迫去观察微小的轨迹偏移(比如偏离中心线 0.3 米)所带来的巨大安全后果。
2. 核心算法:安全感知的对比学习与边界损失
为了利用 Hard Negatives,BeyondDrive 在训练中引入了安全感知的对比损失(Safety-aware Contrastive Loss)。
正样本对:专家轨迹及其高安全分数特征。
难负样本对:生成的碰撞轨迹及其低安全分数特征。
模型被强制要求将正负样本的特征表征在隐空间中拉开明确的距离。这相当于给模型划定了一条“安全边界(Safety Margin)”。在这个边界内,L2 误差可以有弹性;但只要触碰了这条安全红线,Loss 会急剧上升。
这种机制彻底改变了模型的决策逻辑:模型不再盲目追求“像人类”,而是先确保“绝对安全”,再在安全域内寻找最像人类的轨迹。
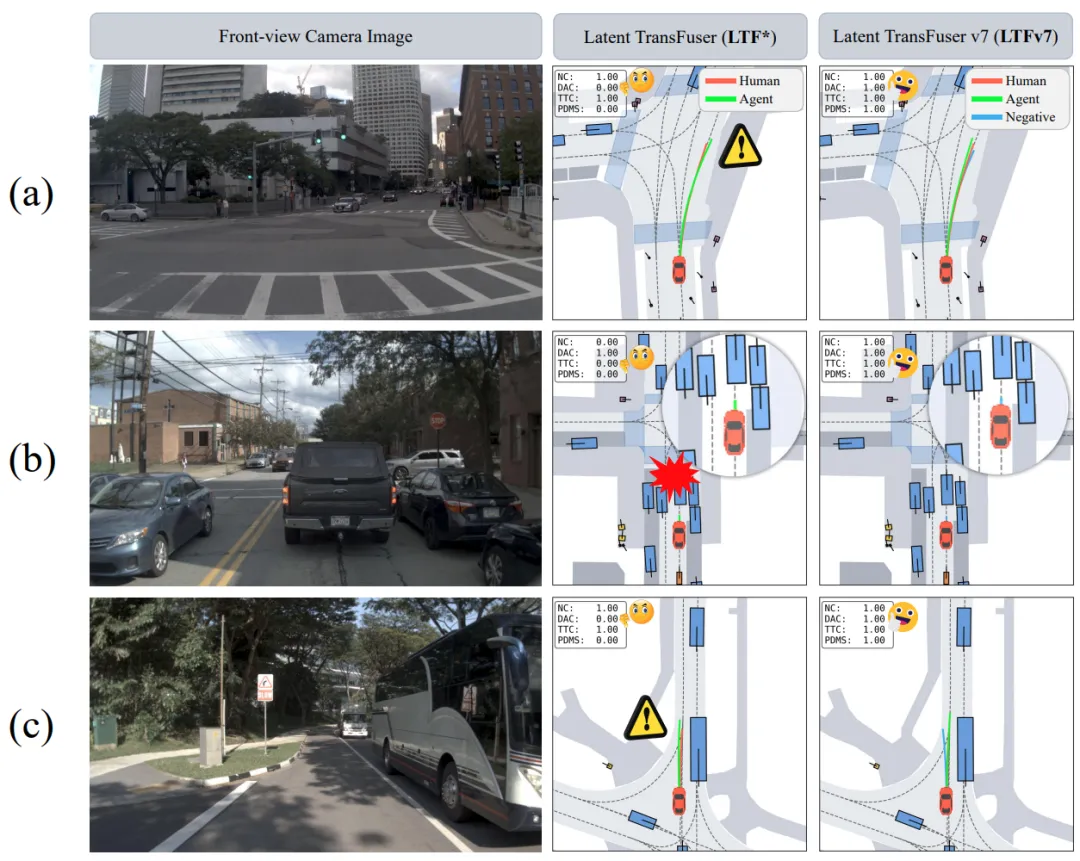
3. 端到端架构升级:TransFuser v7 的实时安全栅栏
作为 TransFuser 系列的最新版本(v7),BeyondDrive 在原有的 LiDAR-摄像头融合 Transformer 基础上,新增了一个轻量级的安全价值头(Safety Value Head)。
这个头并不参与最终的轨迹回归,而是作为一个动态的“安全栅栏”。在推理阶段,它会实时对扩散或采样的候选轨迹进行二进制安全分类。一旦检测到 Hard Negative 倾向的轨迹,v7 的采样器会立即拒掉该轨迹,并从备选的“安全子空间”中重新采样。
论文在多个主流闭环仿真基准(如 CARLA、nuPlan)上进行了极致测试,有几个数据极其震撼:
更令人惊艳的是:在 Ablation Study(消融实验)中,团队发现,仅仅引入 5% 的 Hard Negative 数据参与训练,就足以让模型产生显著的“安全泛化能力”——它不仅能避开训练集见过的危险场景,更能举一反三,在从未见过的陌生地图中主动规避未知风险结构。
这篇 ECCV 2026 的论文,其最大的学术贡献在于重新定义了端到端自动驾驶的 Loss 空间。
更是宣告:单纯依赖“模仿”已经走到了尽头。未来的端到端模型必须具备“避险直觉”。这种直觉无法通过观看老司机的“正常操作”来获得,必须通过大量“车祸临界点”的负反馈来形成肌肉记忆。
数据层面:不要再只标注重采样的成功轨迹。尝试利用模拟器或规则碰撞检测,自动化挖掘那些“差一点就撞了”的 Hard Negatives,这是比堆算力性价比更高的安全提升手段。
算法层面:强烈建议在现有的回归 Loss(L1/L2)基础上,嫁接基于安全边界的对比学习或排序学习(Ranking Loss),让模型拥有“拒绝危险”的权利。
评价体系:是时候将“碰撞率”提升为比“L2误差”更高优先级的首要指标了。