汽车自动驾驶中的“端到端”是什么?
端到端(End-to-End,简称E2E)是当前自动驾驶领域最热门的技术方向,它代表了从传统模块化架构向数据驱动、深度学习主导的范式转变。简单来说,端到端自动驾驶是指通过一个统一的人工智能模型,直接将传感器输入的原始数据(如摄像头图像、激光雷达点云等)映射为车辆的控制指令(如方向盘转角、油门、刹车等),中间不经过人为划分的独立模块处理。
一、核心概念解析
1)输入端与输出端
- • 输入端:车辆的各种传感器数据,包括摄像头图像、激光雷达点云、毫米波雷达信号,以及车辆自身状态信息(如位置、速度、导航路径等)。
- • 输出端:直接生成驾驶指令,包括方向盘转动角度、加速踏板深度、制动力度,或者更高级的车辆行驶轨迹。
2)核心技术特点
端到端系统的本质是深度学习神经网络,它通过海量驾驶数据(包含传感器输入和人类驾驶行为)进行训练,自动学习从感知到决策的映射关系,而非依赖工程师手动编写规则。用通俗的话说,就像「卖家直接对接买家,没有中间商赚差价」,信息传递更高效、更透明。
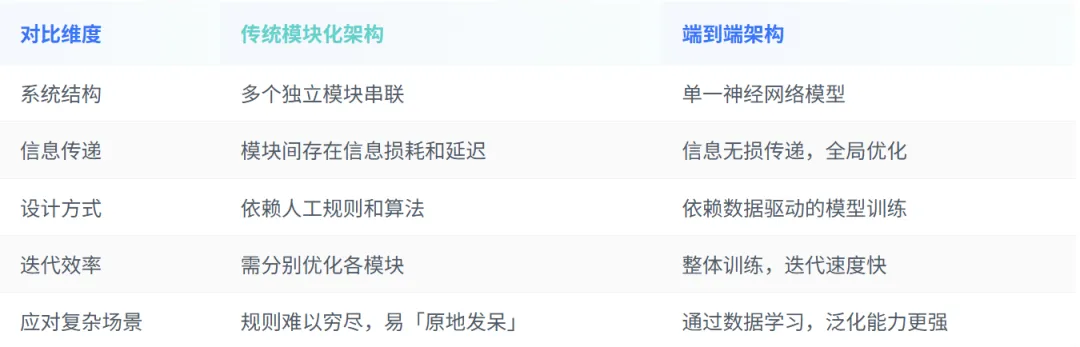
二、与传统模块化架构的对比
传统模块化架构的一个典型问题在于:感知、预测、规划、控制各环节独立,每个模块都要占用计算时间,整体响应较慢。例如,前车已经开走后,系统可能依然在制动,体验不佳。
三、端到端的主要优势
- • 简化系统设计:避免模块间复杂的协同和规则设计,降低了系统复杂性。
- • 信息无损传递:无需人为定义中间接口,避免了传统架构中因接口设计导致的信息丢失。
- • 更强泛化能力:模型能从大量数据中学习人类驾驶的隐性经验,更好应对长尾场景和突发情况。
- • 更拟人的驾驶体验:端到端系统的表现更「丝滑」,更像人类司机驾驶,而非机械化的规则执行。
- • 迭代速度快:数据驱动下,软件整体学习能力强,应对场景的能力提升更快。
四、面临的挑战与局限
- • 数据依赖性极强:需要海量高质量驾驶数据,且需覆盖极端天气、罕见事故等长尾场景。以特斯拉为例,其FSD已学习超过2000万个驾驶视频片段,仅采集成本就需50亿至80亿元。
- • 算力需求巨大:端到端大模型训练需要庞大的算力支持,国内车企算力增长普遍面临瓶颈。
- • 可解释性差(黑箱问题):模型决策过程不透明,难以验证安全性,难以定位问题根源。
- • 安全性验证困难:传统模块化方案可通过逐层验证保障安全,而端到端模型需整体验证,缺乏中间环节的监督信号。
五、端到端的实现形态
当前业界对端到端的实现路径尚未完全统一,主流的架构方案包括以下几种:
- • 模块化端到端:保留感知、预测、规划等模块结构,但各模块可联合训练,模块间传递的是特征向量而非人类可理解的中间结果。这种方式兼顾了可解释性与全局优化能力。
- • 双系统端到端(端到端+视觉语言模型):在端到端模型之外增加一个视觉语言模型(VLM)作为「慢系统」,负责复杂场景的语义理解和逻辑推理。例如理想汽车采用的方案:端到端神经网络负责日常驾驶(如跟车、红灯停),VLM负责处理限时公交车道、施工路段等复杂场景。
- • 单模型端到端(One Model):用一个统一的深度神经网络完成所有任务,从传感器输入直接输出车辆轨迹或控制指令。这是最彻底的端到端形态,代表如特斯拉FSD V12,技术上限更高,但可解释性和调试难度也最大。
六、发展现状与未来方向
2024年以来,端到端已成为自动驾驶行业最火热的技术词汇。特斯拉基于端到端的FSD V12形成了标杆示范效应,带动「蔚小理」等车企和华为、地平线等服务商纷纷转向。不过,端到端技术目前尚未大规模商用,更多仍与传统方法结合使用。
未来发展方向包括:
- • 混合架构:结合端到端模型与传统模块化方法的优势,平衡效率与安全性。
- • VLA多模态大模型:融合视觉、语言和动作能力,实现更完整的感知-决策-行动闭环。
- • 仿真与合成数据:通过虚拟环境生成极端场景数据,提升模型鲁棒性。
- • 可解释性增强:开发可视化工具或可解释模型结构,提升系统透明度。
总的来说,端到端代表了自动驾驶向更智能化、数据驱动化方向发展的关键路径,但大规模落地仍需突破安全性验证、数据获取和可解释性等核心瓶颈。
七、特斯拉FSD与华为乾崑智驾的端到端技术路线对比
1)特斯拉FSD的端到端水平:行业标杆级
特斯拉的端到端技术目前处于全球领先地位,其FSD(Full-Self Driving)系统经过V12到V14的三代迭代,已经相当成熟。
- • 技术架构的彻底性:特斯拉FSD V12是行业第一个真正意义上的端到端自动驾驶系统——输入是摄像头的视频流,输出直接是方向盘转角和油门刹车指令,中间没有感知、决策、规划等独立模块。到了V14版本,特斯拉进一步实现了「光子进,控制出」(Photon In, Control Out)的完整端到端架构,代码量从V11版本的30万行C++代码锐减至V12的约2000-3000行。
- ◦ 横穿美国:2025年12月,一辆搭载FSD V14的Model 3完成了从洛杉矶到南卡罗莱纳州约4400公里的行程,全程0接管。
- ◦ 横穿加拿大:2026年5月,FSD再次完成6051公里零干预的壮举,期间遇到野生动物横穿、异形交叉口、非标准化临时交通标志等复杂场景。
- ◦ 安全数据:截至2026年5月,FSD全球累计行驶里程突破161亿公里,重大碰撞事故率低至每530万英里1起,优于人类驾驶员平均水平。
- ◦ 迭代速度:FSD V14版本在城市街道的干预里程已比V12提升5-8倍,部分测试者反馈1000英里才需干预1-2次。
- • 核心技术优势:特斯拉端到端的核心竞争力在于其数据飞轮效应。全球700万辆保有量中约300-400万辆激活FSD,每天产生海量真实驾驶数据。此外,特斯拉还通过「影子模式」让未激活FSD的车辆也在后台运行神经网络,与人类驾驶行为比对,自动采集有价值样本。
2)华为乾崑智驾ADS的端到端技术路线
华为乾崑智驾ADS同样是端到端架构,但其实现路径与特斯拉存在显著差异。
- • 华为的端到端演进:华为ADS 3.0(2024年9月推送)已率先实现「端到端」大模型,在算法范式上与特斯拉FSD没有代差。到ADS 4.0(2025年4月发布),华为搭载了WEWA架构(World Model + End-to-End),通过「云端训练+车端推理」协同范式重构智驾逻辑。2026年4月发布的ADS 5.0则更进一步,采用世界行为模型(WA),直接输入多模态感知数据,输出行驶轨迹控制指令,没有语言层中介。
- • 与特斯拉的根本区别:华为的技术路线核心特征是**「端到端+激光雷达」的多传感器融合**,在神经网络感知之上增加了一层物理安全冗余。具体而言:
- ◦ 传感器配置:华为采用896线激光雷达+毫米波雷达+摄像头的三重冗余方案,而特斯拉坚持纯视觉(仅8个摄像头)。
- ◦ 决策逻辑:华为认为VLA(视觉-语言-动作模型)的「语言层」是累赘,每多一次转换就多一次信息损失和延迟,因此直接走WA路线。
- ◦ 安全哲学:华为的核心理念是「冗余即安全」——当摄像头因强逆光暂时致盲时,激光雷达仍可准确探测;当激光雷达因暴雨产生噪点时,毫米波雷达可穿透雨幕。
- ◦ 本土数据:华为乾崑智驾本土累计辅助驾驶里程突破111亿公里。
- ◦ 安全数据:搭载乾崑智驾的车辆每10万公里碰撞率比行业平均值低30%以上。
- ◦ 复杂场景:在上海16公里城区测试中实现零接管,暴雨环境接管率仅3%。
- ◦ L3商用先发优势:ADS 4.0已获得高速L3商用准入许可,这是特斯拉目前在中国尚未实现的。
3)核心结论
两者都是端到端,但技术哲学截然不同:特斯拉追求「少即是多」,用算法代偿硬件;华为追求「多一层保障就多一分安全」,用冗余换取可靠。在中国复杂的路况环境下(人车混行、非标路口、高频道路变更),华为的多传感器融合方案具有天然的适应性优势;而在北美相对规则化的道路上,特斯拉的纯视觉端到端方案已经证明了其极限能力。
这场竞争不是简单的技术优劣对决,而更像是两种工程哲学在不同应用场景下的最优解探索。未来可能的趋势是两种路线互相借鉴、融合升级,而非单一技术垄断市场。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
