作者 | Zisheng Chen, Yuping Qiu, Jianhua Han, Tao Tang, Xiuwei Chen, Likui Zhang, Ying-Cong Chen, Hang Xu, Xiaodan Liang
机构 | Sun Yat-sen University / HKUST(GZ) / Yinwang Intelligent Technology Co. Ltd.
论文标题 | Intend, Reflect, Refine: An Adaptive Multimodal Reflection Framework for Autonomous Driving
论文版本 | arXiv:2606.22913v1
关键词 | Autonomous Driving / Vision-Language-Action / Adaptive Reflection / Future BEV / NAVSIM / Reinforcement Learning / Planning前言
自动驾驶 VLA 模型这段时间有一个很明显的趋势:不再只做端到端轨迹回归,而是把 reasoning、CoT、future scene prediction、world model 等能力塞进规划模型里。
但这篇 IRR-Drive 提醒了一个更细的问题:推理本身不等于可靠规划,反思也不应该永远打开。如果模型只是生成一段看似合理的解释,然后直接输出轨迹,它其实没有真正检查这条轨迹未来会发生什么;如果每个场景都强行走完整反思流程,又会把推理成本拉得很高。
IRR-Drive 的答案是三个词:Intend, Reflect, Refine。先生成轨迹意图,再用未来 BEV 和文本反思检查复杂场景,最后修正意图并输出轨迹。
最值得记住的结论:IRR-Drive 把反思从“静态后处理”变成“按场景复杂度自适应启动的规划机制”。在 NAVSIM v1 上达到 91.3 PDMS,在 NAVSIM v2 上达到 89.0 EPDMS;自适应模式只需 1.70s,明显低于全反思模式的 3.03s。
资源链接
- arXiv 页面:arXiv:2606.22913v1
- 代码状态:PDF、arXiv 页面和公开检索中暂未发现作者提供的项目页或代码仓库链接。
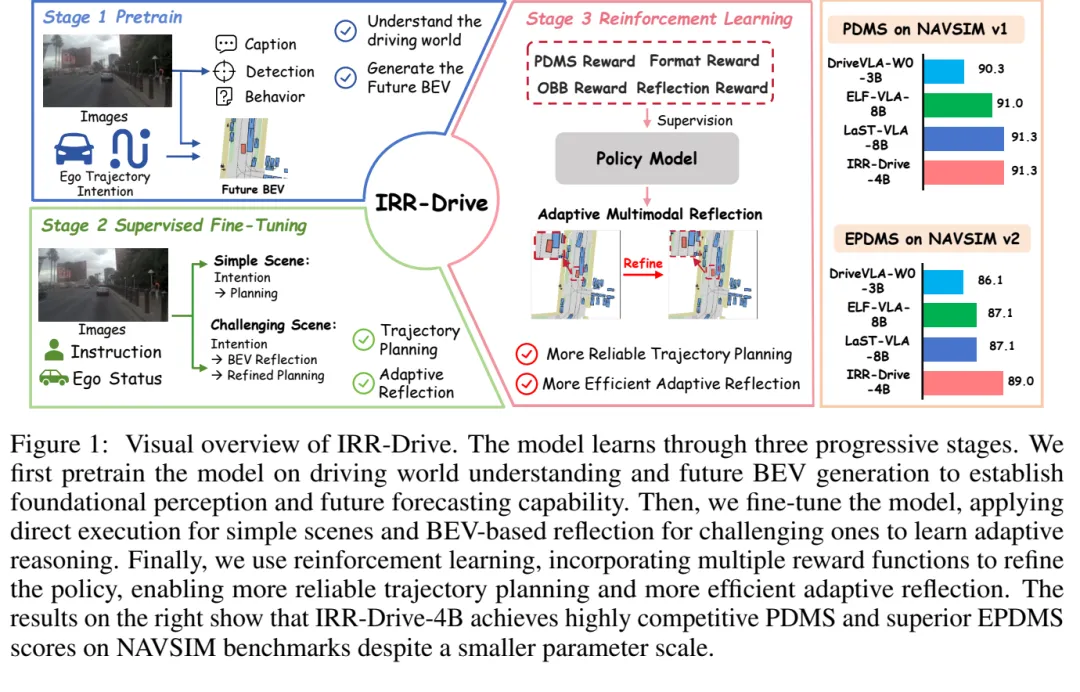 图 1:IRR-Drive 总览。论文将模型训练拆成三阶段:预训练驾驶世界理解和未来 BEV 生成,SFT 学习简单场景直出/复杂场景反思,最后用强化学习优化规划和自适应反思。
图 1:IRR-Drive 总览。论文将模型训练拆成三阶段:预训练驾驶世界理解和未来 BEV 生成,SFT 学习简单场景直出/复杂场景反思,最后用强化学习优化规划和自适应反思。这篇论文真正想解决什么
已有 VLA 驾驶模型通常有两类做法:一类直接输出 trajectory,另一类在输出前生成 reasoning。问题在于,reasoning 往往只是语言层面的解释,和真实物理约束之间仍然隔着一层。
IRR-Drive 认为,自动驾驶规划里的“反思”必须满足两个条件:
- 要 grounded:不能只在文字里说“应该减速”,还要看到未来 BEV 里是否会压线、碰撞或离开可行驶区域。
- 要 adaptive:简单场景不应该浪费推理预算,复杂场景才需要额外反思和修正。
这也是标题里 Intend, Reflect, Refine 的含义。Intend 生成初始轨迹意图;Reflect 用 Text + BEV 预测未来后果并生成反思;Refine 根据反思修正意图和最终轨迹。
这篇论文的重点不是“让 VLA 多说几句话”,而是让模型在必要时用未来 BEV 作为空间证据,检查初始意图是否会带来不安全后果。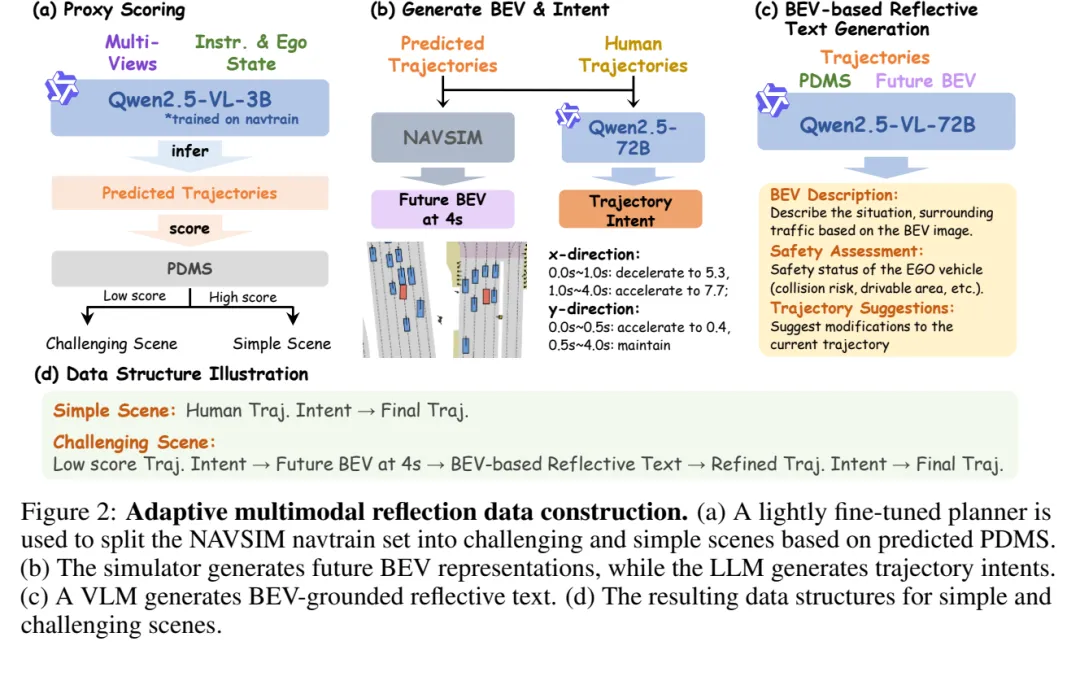 图 2:自适应多模态反思数据构造。先用轻量规划器按 PDMS 把 NAVSIM navtrain 分成简单/复杂场景,再为复杂样本生成未来 BEV、轨迹意图和 BEV-grounded reflective text。
图 2:自适应多模态反思数据构造。先用轻量规划器按 PDMS 把 NAVSIM navtrain 分成简单/复杂场景,再为复杂样本生成未来 BEV、轨迹意图和 BEV-grounded reflective text。训练数据:先知道哪些场景值得反思
IRR-Drive 的数据构造很实用。它先训练一个 base VLA,在 NAVSIM navtrain 上跑出 predicted PDMS,然后把低分样本当作 challenging scenes,高分样本当作 simple scenes。
简单场景的数据结构比较短:Human Trajectory Intent → Final Trajectory。复杂场景则多了几个环节:Low-score Trajectory Intent → Future BEV at 4s → BEV-based Reflective Text → Refined Trajectory Intent → Final Trajectory。
也就是说,反思不是凭空来的。低分 trajectory 先被投到未来 BEV 中,碰撞风险、安全距离不足、可行驶区域偏离等问题会变成空间可见证据,再交给 VLM 生成反思文本。
这个设计很像给规划模型建立一套“错题本”:先找出 base planner 容易失败的场景,再把失败后果显式放进 future BEV,让模型学习什么时候需要慢下来检查。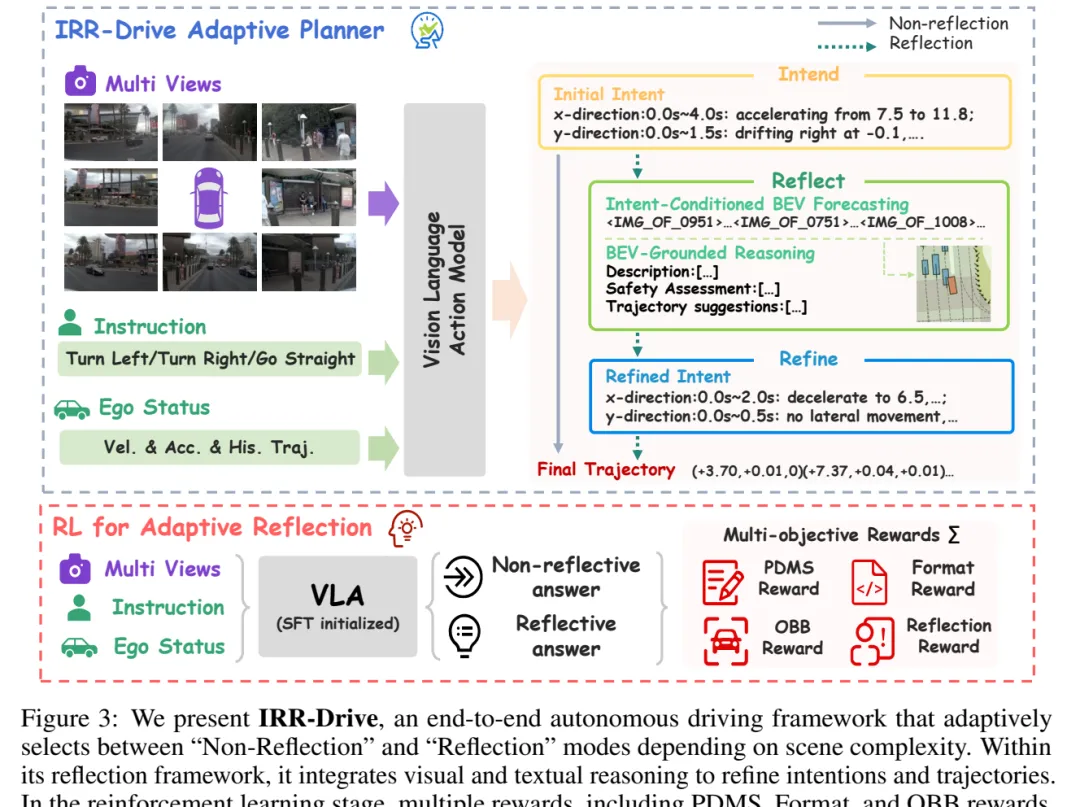 图 3:IRR-Drive 的 adaptive planner。输入多视图、指令和 ego status 后,模型先生成 initial intent;复杂场景会预测 intent-conditioned BEV 并生成 BEV-grounded reasoning,再 refine 成最终意图和轨迹。
图 3:IRR-Drive 的 adaptive planner。输入多视图、指令和 ego status 后,模型先生成 initial intent;复杂场景会预测 intent-conditioned BEV 并生成 BEV-grounded reasoning,再 refine 成最终意图和轨迹。方法:反思被嵌进规划流程,而不是外挂解释
IRR-Drive 的输入包括 multi-view images、instruction、ego status,以及速度、加速度和历史轨迹等状态。模型先输出 initial intent,例如未来 4 秒 x/y 方向的加减速和横向漂移描述。
如果判断为复杂场景,系统会进入 Reflect:根据 initial intent 预测 future BEV,再生成 BEV-grounded reasoning,包括全局场景描述、安全评估和轨迹修改建议。最后,Refine 阶段把这些反思压回 refined intent 和 final trajectory。
简单场景:Intention → Final Trajectory复杂场景:Intention → Future BEV → Reflective Text → Refined Intention → Final Trajectory这和很多“先规划、再解释”的方法相反。IRR-Drive 的反思文本不是事后说明,而是参与轨迹修正的中间变量。
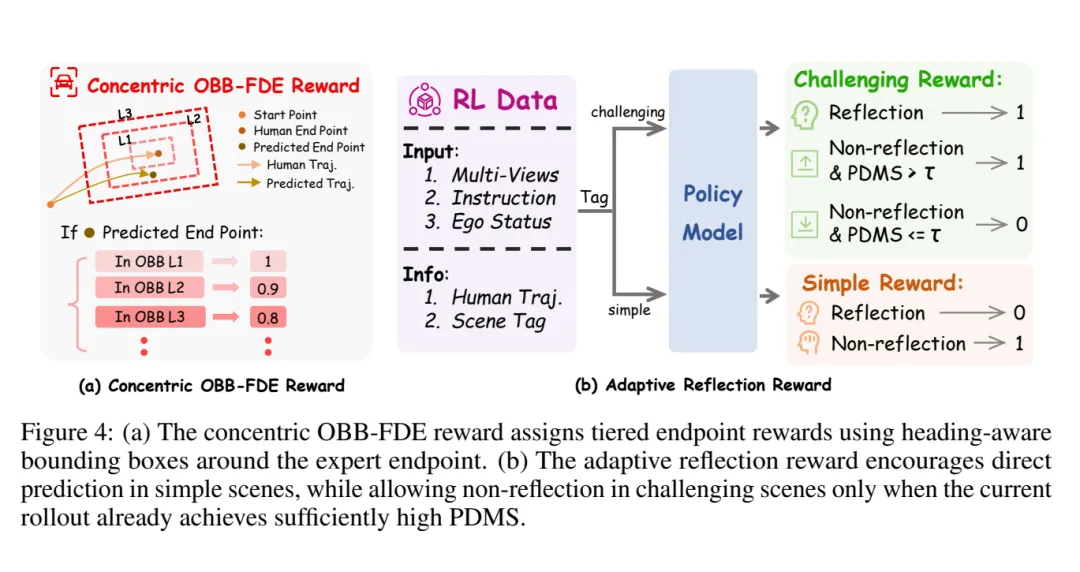 图 4:两类关键奖励。Concentric OBB-FDE 用朝向感知的同心 OBB 给终点误差分层奖励;adaptive reflection reward 鼓励简单场景不反思,复杂场景按需要反思。
图 4:两类关键奖励。Concentric OBB-FDE 用朝向感知的同心 OBB 给终点误差分层奖励;adaptive reflection reward 鼓励简单场景不反思,复杂场景按需要反思。奖励:既要会规划,也要会省计算
强化学习阶段是 IRR-Drive 的另一个关键点。论文把多个 reward 放在一起:PDMS reward、format reward、Concentric OBB-FDE reward,以及 adaptive reflection reward。
其中 Concentric OBB-FDE reward 很有工程味:它不是只看终点 L2 距离,而是以 expert endpoint 为中心构造带朝向的多层 OBB。预测终点落在越内层,奖励越高。这比二值 collision penalty 更平滑,也更贴近车辆几何。
Adaptive reflection reward 则负责避免模型塌缩成一种模式:简单场景鼓励 non-reflection;复杂场景允许 reflection,但如果 non-reflection 已经达到高 PDMS,也可以不反思。
R = R_PDMS + R_format + R_OBB + R_reflection这部分最有意思的地方在于,论文不是单纯奖励“多反思”,而是奖励“该反思时反思,不该反思时直接走”。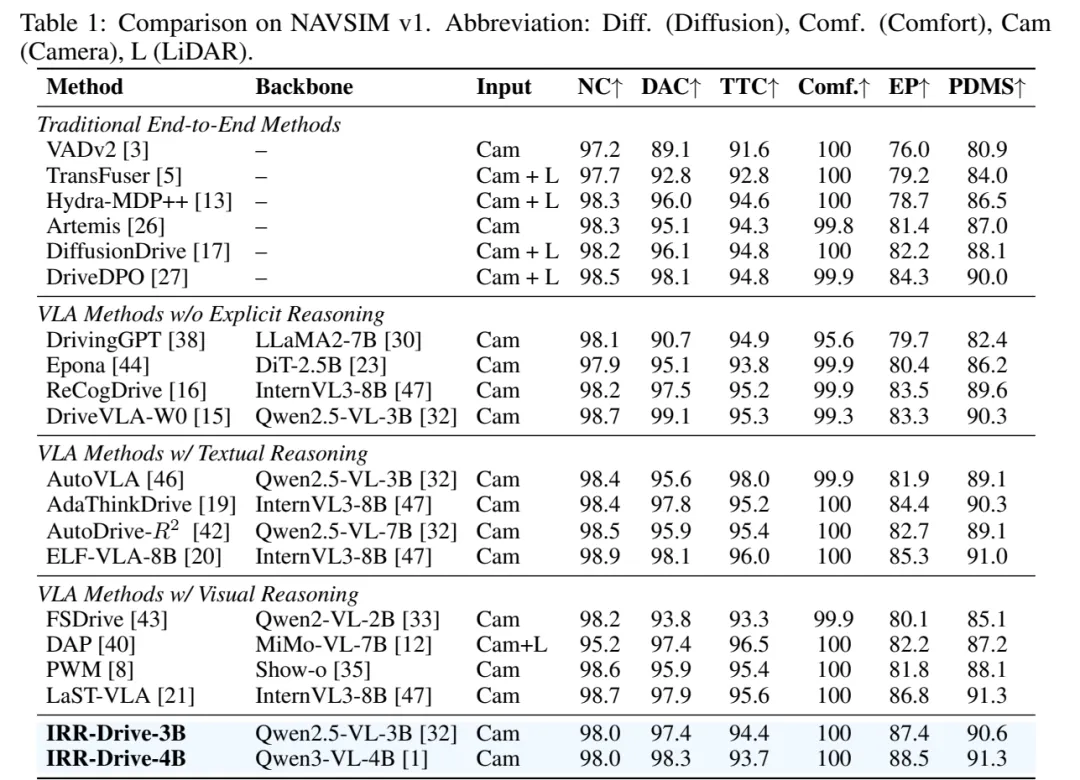 表 1:NAVSIM v1 主结果。IRR-Drive-4B 达到 91.3 PDMS,与 LaST-VLA-8B 持平,同时 EP 达到 88.5;IRR-Drive-3B 也达到 90.6 PDMS。
表 1:NAVSIM v1 主结果。IRR-Drive-4B 达到 91.3 PDMS,与 LaST-VLA-8B 持平,同时 EP 达到 88.5;IRR-Drive-3B 也达到 90.6 PDMS。关键结论一:NAVSIM v1 上达到一线水平
表 1 是 NAVSIM v1 的主结果。IRR-Drive-4B 使用 Qwen3-VL-4B,仅摄像头输入,得到 91.3 PDMS,与 LaST-VLA-8B 持平,超过 DriveVLA-W0 的 90.3、ELF-VLA-8B 的 91.0。
更值得注意的是 EP 指标。IRR-Drive-4B 的 EP 为 88.5,高于 LaST-VLA 的 86.8 和 ELF-VLA 的 85.3。EP 更接近轨迹端点表现,说明它的反思机制确实在轨迹质量上产生了收益。
IRR-Drive-3B 也达到 90.6 PDMS,说明框架本身并不完全依赖大模型尺寸;即使用 3B 级 VLM,也能接近强 baseline。
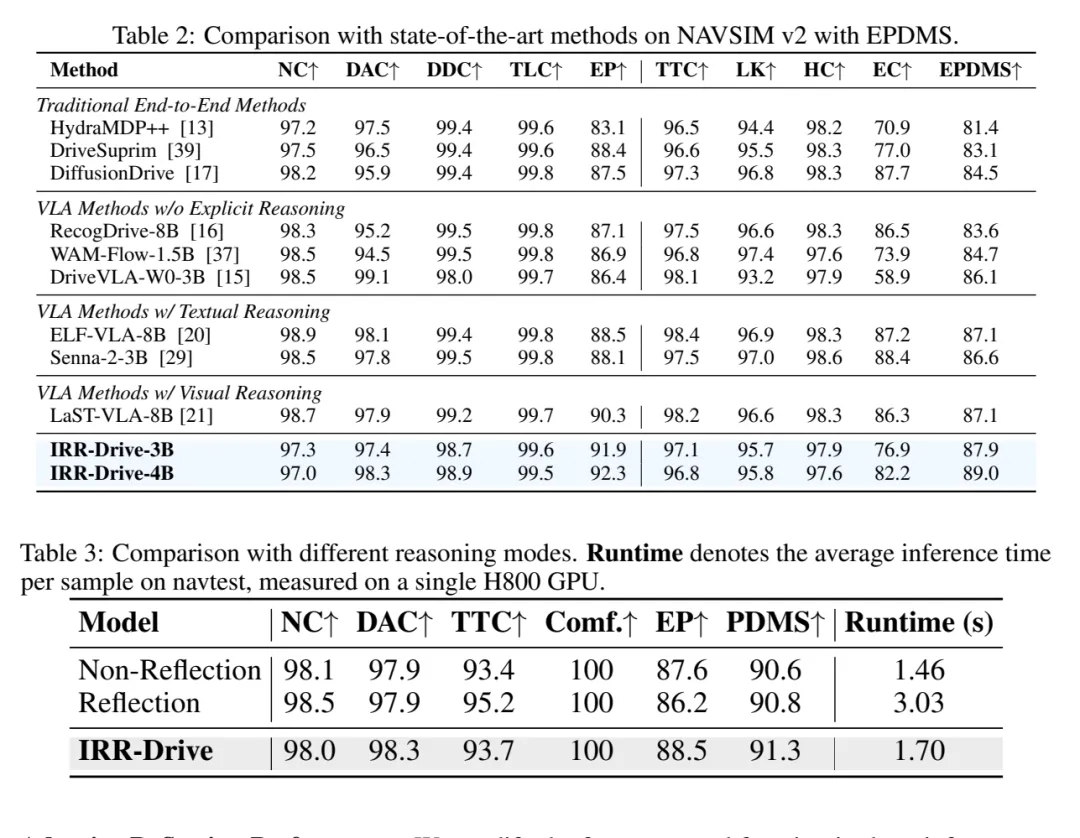 表 2/3:NAVSIM v2 和推理模式对比。IRR-Drive-4B 在 NAVSIM v2 上达到 89.0 EPDMS;自适应模式用 1.70s 达到 91.3 PDMS,比全反思模式 3.03s 更高效。
表 2/3:NAVSIM v2 和推理模式对比。IRR-Drive-4B 在 NAVSIM v2 上达到 89.0 EPDMS;自适应模式用 1.70s 达到 91.3 PDMS,比全反思模式 3.03s 更高效。关键结论二:自适应反思比全反思更划算
NAVSIM v2 更难,指标也扩展成 EPDMS。IRR-Drive-4B 在表 2 中达到 89.0 EPDMS,高于 LaST-VLA-8B 和 ELF-VLA-8B 的 87.1,也高于 DriveVLA-W0-3B 的 86.1。
表 3 则直接证明“不是反思越多越好”。Non-Reflection 是 90.6 PDMS / 1.46s;统一 Reflection 是 90.8 PDMS / 3.03s,耗时翻倍但提升很小;IRR-Drive 自适应模式是 91.3 PDMS / 1.70s。
这组数字其实是全文最关键的行业信号:在部署场景里,推理预算不是无限的。一个反思模块只有能判断什么时候该启动,才有工程价值。
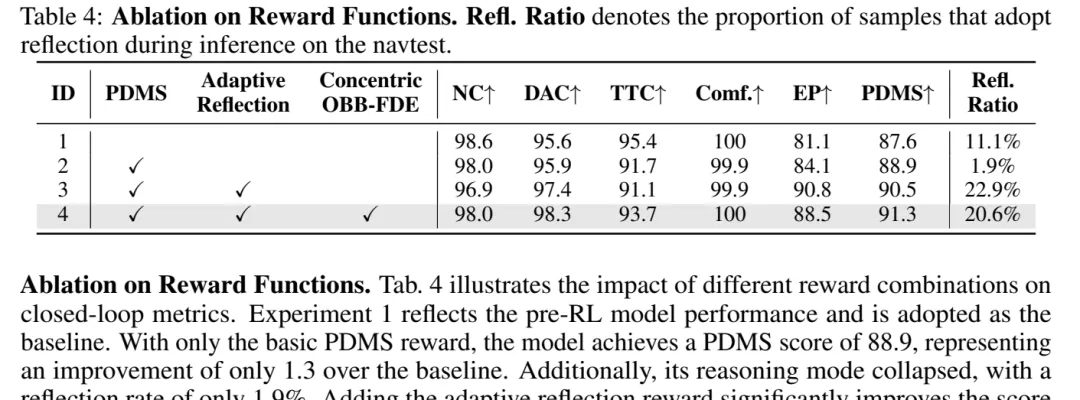 表 4:奖励消融。PDMS reward、adaptive reflection reward 与 Concentric OBB-FDE reward 组合后,PDMS 提升到 91.3,反思比例稳定在 20.6%。
表 4:奖励消融。PDMS reward、adaptive reflection reward 与 Concentric OBB-FDE reward 组合后,PDMS 提升到 91.3,反思比例稳定在 20.6%。关键结论三:奖励函数决定反思行为是否稳定
表 4 从 reward 角度拆解了结果。只用 pre-RL baseline,PDMS 是 87.6,反思比例 11.1%。只加 PDMS reward 后,PDMS 到 88.9,但反思比例塌到 1.9%,说明模型容易学成“几乎不反思”。
加入 adaptive reflection reward 后,PDMS 到 90.5,反思比例 22.9%;再加入 Concentric OBB-FDE reward,最终达到 91.3 PDMS,反思比例稳定在 20.6%。
这说明反思行为本身也需要被训练和约束。否则模型要么过度反思,成本太高;要么完全不反思,复杂场景风险无法被纠正。
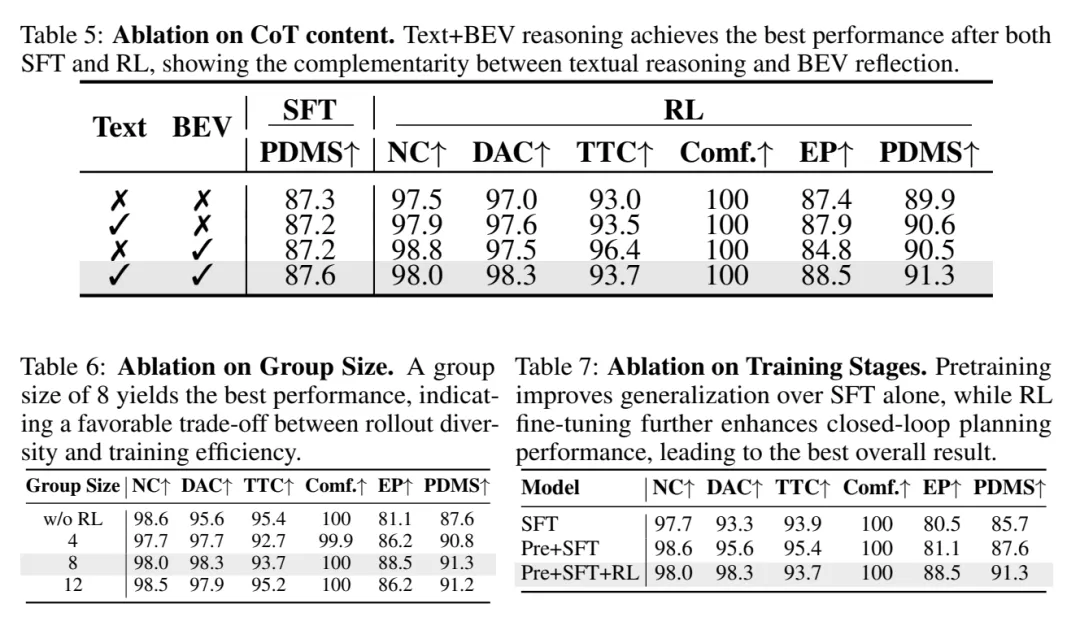 表 5/6/7:Text+BEV CoT、group size 和训练阶段消融。Text 与 BEV 结合后 PDMS 达到 91.3;group size=8 最优;Pre+SFT+RL 相比 SFT 提升 5.6 PDMS。
表 5/6/7:Text+BEV CoT、group size 和训练阶段消融。Text 与 BEV 结合后 PDMS 达到 91.3;group size=8 最优;Pre+SFT+RL 相比 SFT 提升 5.6 PDMS。消融:Text 和 BEV 缺一不可
表 5 是 CoT 内容消融。只用 Text,RL 后 PDMS 为 90.6;只用 BEV,为 90.5;Text+BEV 组合达到 91.3。这说明文本 reasoning 和 BEV 空间证据是互补的。
表 6 显示 group size=8 最合适:从 4 到 8,PDMS 从 90.8 到 91.3;继续到 12 反而略降到 91.2。表 7 则说明三阶段训练有效:SFT 是 85.7,Pre+SFT 是 87.6,Pre+SFT+RL 最终到 91.3。
这里可以把 IRR-Drive 的训练逻辑概括成一句话:预训练建立驾驶世界理解,SFT 教模型区分简单/复杂和生成反思链,RL 再把闭环指标与反思开关对齐。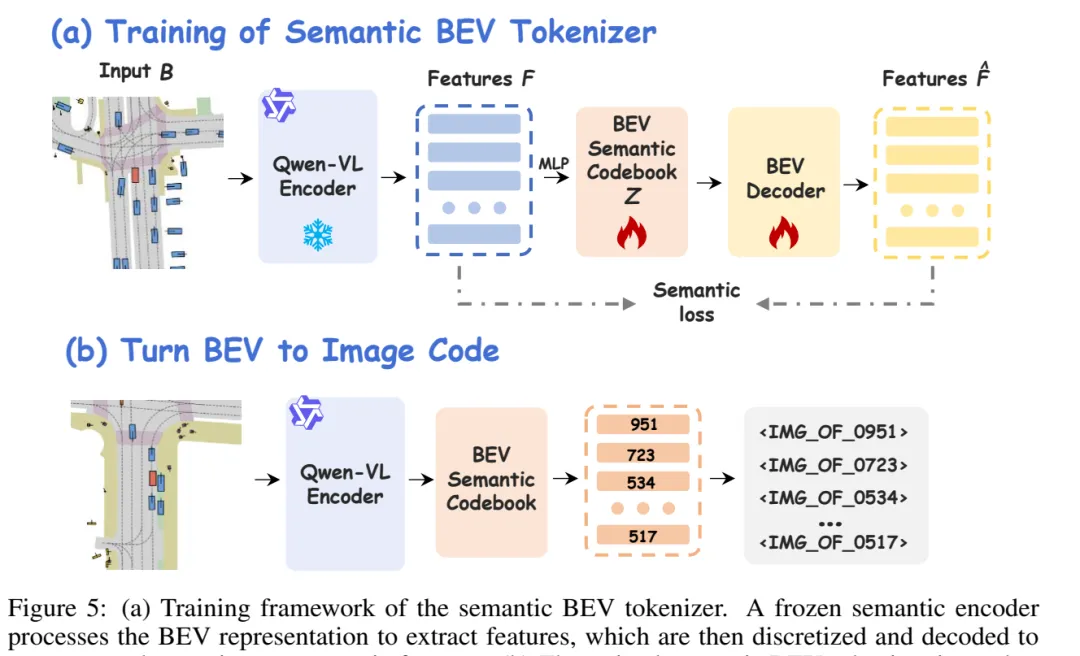 图 5:semantic BEV tokenizer。它把 BEV 表示离散成类似 <IMG_OF_XXXX> 的特殊 token,使未来 BEV 能接入自回归 VLM 工作流。
图 5:semantic BEV tokenizer。它把 BEV 表示离散成类似 <IMG_OF_XXXX> 的特殊 token,使未来 BEV 能接入自回归 VLM 工作流。为什么需要 semantic BEV tokenizer
IRR-Drive 要把未来 BEV 放进自回归 VLM 的推理链里,因此需要把 BEV 表示离散化成 token。图 5 展示了 semantic BEV tokenizer:冻结 semantic encoder 提取 BEV 特征,再通过 codebook 量化成离散 code,最后映射为类似 <IMG_OF_0951> 的 special tokens。
这个设计让未来 BEV 不再只是外部图片,而是可以被 VLM 作为 token 序列处理。换句话说,模型的反思空间同时包含语言 token 和 BEV token。
局限与判断
论文也有比较清楚的边界。第一,实验主要在 NAVSIM 上验证,仍需要更多真实闭环和交互式仿真验证。第二,反思数据依赖 base planner 的低分样本划分,以及 VLM 生成 reflective text 的质量。第三,虽然自适应反思降低了成本,但相比纯 non-reflection 仍有额外推理开销。
不过方向很明确:自动驾驶 VLA 的下一步,不只是让模型能解释驾驶行为,而是让模型能在执行前用未来后果检查自己,并且根据场景复杂度决定是否值得花这笔计算。
IRR-Drive 的价值在于,把“反思”从语言层面的解释,推进到规划层面的可执行机制:先预测未来,再看哪里不安全,最后只在必要时修正轨迹。结论
IRR-Drive 不是单纯追求更长 CoT,而是把反思变成一个可训练、可度量、可调度的规划模块。它用未来 BEV 给高层意图提供物理证据,用 adaptive reflection reward 控制推理成本,再用 RL 对齐闭环规划指标。
对自动驾驶 VLA 来说,三个结论最值得记住:
- 反思要有空间证据,Text+BEV 比纯文本推理更可靠。
- 反思要自适应,简单场景直接规划,复杂场景再进入 Reflect/Refine。
- 规划模型的 reasoning 不应只服务可解释性,还应该直接服务轨迹修正和闭环评分。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
