“
一辆自动驾驶汽车驶入临时施工路段。
车道线突然消失,锥桶摆放杂乱,前车临时变道,一名骑行者又从车辆侧后方快速接近。
系统短暂犹豫,驾驶员接管了车辆。
对普通用户来说,这只是一次不够流畅的驾驶体验。
但对一家成熟的自动驾驶公司来说,真正的工作才刚刚开始:
这段数据能否被及时发现?
能否从海量行驶记录中找到相似场景?
能否快速完成清洗、标注和训练?
新模型能否解决问题,又不会让原本正常的场景出现退步?
验证完成后,新的能力能否安全地部署回车辆?
从一次接管,到下一次不再需要接管,这中间形成的完整链路,就是自动驾驶行业经常提到的 —— 数据闭环。
而今天,自动驾驶公司之间真正拉开差距的,可能已经不只是某一个模型有多先进,而是谁能更快、更稳定地完成这个闭环。
”
01
算法依然重要,但已经不是全部
自动驾驶发展的早期,行业讨论最多的是算法。
谁的目标检测更准?
谁的传感器融合更稳定?
谁的路径规划更聪明?
谁能在复杂道路上跑出更高的测试分数?
这些问题当然重要。
没有感知、预测和规划算法,车辆连基本的环境理解和驾驶决策都无法完成。
但随着论文、开源框架和基础模型不断成熟,先进算法的扩散速度正在变快。一个新的模型结构被发表后,其他团队可能很快就能理解、复现,甚至进行改进。
真正难以快速复制的,是算法背后的整套系统。
因为自动驾驶最终面对的,并不是一个固定的数据集,而是持续变化的真实世界:
有人突然横穿马路;
施工人员临时改变交通流向;
救护车从后方快速接近;
雨水遮挡了车道线;
一辆卡车装载着形状奇怪的货物;
骑行者做出了难以预测的动作……
这些低频、复杂、难以预先枚举的情况,构成了自动驾驶中的“长尾场景”。Waymo也将复杂交通参与者行为、天气变化和大量长尾情况视为真实世界自动驾驶的核心挑战。
因此,自动驾驶的竞争逐渐从:
谁能把一个模型训练出来?
转向:
谁能让模型持续从真实世界中学习,并且越来越可靠?
02
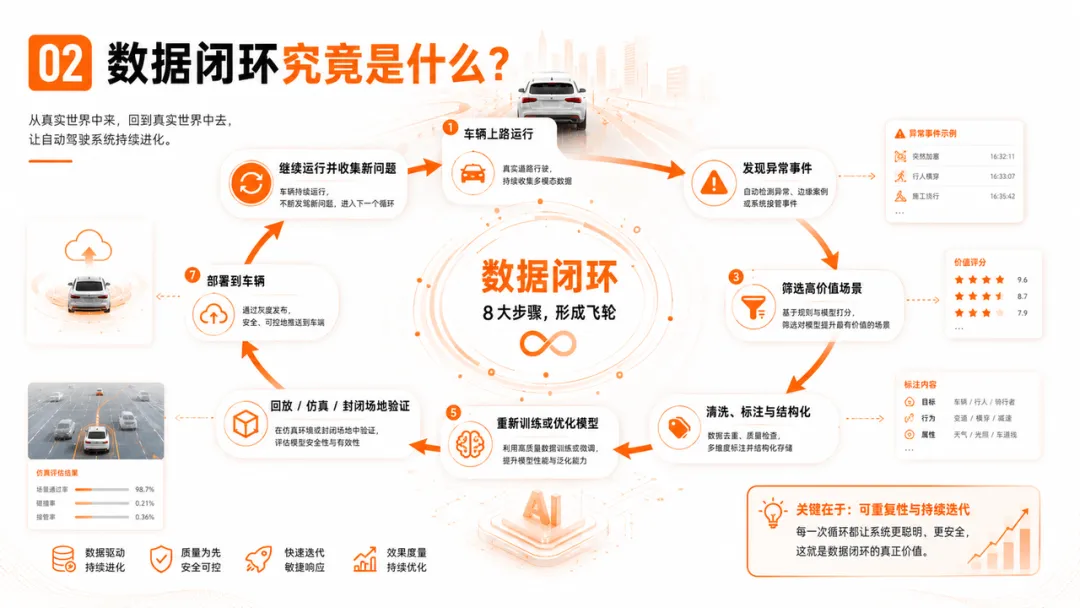
数据闭环究竟是什么?
一个完整的自动驾驶数据闭环,大致包含以下过程:
车辆上路运行 → 发现接管、急刹、低置信度等异常事件 → 从海量数据中筛选高价值场景→ 完成清洗、标注与场景结构化 → 重新训练或优化模型→ 通过回放、仿真和封闭场地进行验证→ 将新版本部署到车辆→ 继续运行并收集新的问题
关键不在于这条流程“跑过一次”,而在于它能够不断重复。
车辆每一次运行,都可能暴露新的问题;
每一个问题,都可能转化为新的训练数据;
每一次模型升级,又会进入下一轮真实环境验证。
于是,车辆既是产品,也是数据采集设备;既在完成驾驶任务,也在不断为下一代模型积累经验。
这才是“闭环”的真正含义。
03
有很多数据,不等于拥有数据闭环
乍一看,只要车辆足够多、行驶里程足够长,就能获得数据优势。
但事实并没有这么简单。
假设一家公司每天采集数百万段城市道路视频,其中绝大多数都只是车辆正常直行、跟车和等待红绿灯。
这些数据虽然数量庞大,却可能高度重复。
相比之下,一段只有十几秒的视频——例如施工人员突然改变手势、车辆错误理解临时交通指示——反而可能更有训练价值。
因此,数据闭环首先要解决的,并不是“如何存下更多数据”,而是:
如何从海量普通数据中,找到真正值得学习的数据。
系统需要识别接管、急刹、轨迹异常、模型不确定性升高等信号,还要对相似场景进行聚类和去重,避免反复训练同一种情况。
找到问题之后,还要把原始传感器数据转化成模型能够学习的内容。
这可能不仅包括车辆、行人和道路的二维框,还包括:
物体的三维位置与运动轨迹;
道路结构和交通规则;
不同交通参与者之间的交互关系;
自车采取的动作及其结果;
驾驶员为什么接管车辆。
数据量只是起点。
数据能否被发现、理解、加工并重新用于训练,才决定它是否真正有价值。
04
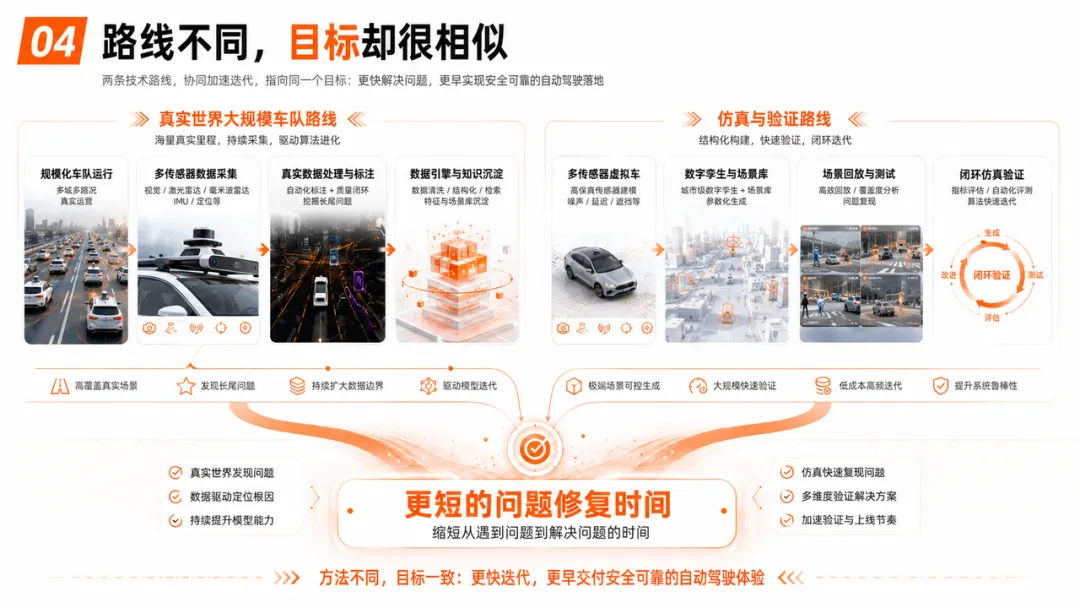
自动驾驶公司走的路线不同,目标却很相似
不同自动驾驶公司的数据获取与训练路径并不相同。
以特斯拉为代表的路线,更强调依靠大规模量产车队获取真实道路数据,并通过数据引擎持续挖掘长尾场景与失败案例。其公开资料与技术分享中,多次提到数据规模扩展与自动化数据闭环在系统迭代中的核心作用。
以Waymo为代表的路线,则更加重视多传感器融合、结构化测试与仿真系统建设。其仿真平台可以对真实道路场景进行回放与编辑,也能够生成新的虚拟交通场景,用于系统在复杂环境下的训练与验证。
相关研究显示,随着训练数据与计算资源的增加,运动预测与规划模型性能呈现稳定提升趋势,并且这一提升在闭环仿真评估中同样能够得到体现。
近年来,Waymo也持续推进生成式仿真能力的发展,使仿真系统能够更灵活地构造复杂交通场景,并生成多传感器数据,用于覆盖现实中难以大规模采集的极端情况。
这些路线并不相同:有的依赖大规模真实车队的数据闭环;有的依赖高精度传感器与结构化仿真体系;有的逐步走向端到端学习系统;也有的仍强调模块化结构与安全验证。
但它们最终都在解决同一个问题:
如何缩短从“问题在真实世界中出现”,到“问题被识别、修复并重新验证”的完整闭环周期?”
05
真正的护城河,是一套不断积累的系统
算法通常可以被描述为代码、模型结构和训练方法。
而数据闭环涉及的远不止算法团队。
它还需要:
车辆与传感器采集系统、
数据上传和存储基础设施、
场景检索与数据挖掘工具、
自动标注和人工审核体系、
模型训练平台、
仿真与回放系统、
安全评测标准、
版本管理和车辆部署能力。
更重要的是,这套系统具有积累效应。
车辆发现过的异常场景,可以沉淀为场景库;
解决过的问题,可以加入回归测试集;
积累的标注数据,可以训练下一代自动标注模型;
升级后的模型,又可以更准确地寻找新的困难样本。
于是,闭环会越转越快。
竞争对手或许能够复现一篇论文,却很难在短时间内复制另一家公司长期积累的场景库、数据标准、工具链和验证体系。
当然,数据本身也不会自动形成护城河。
没有有效筛选和治理的海量数据,最终可能只是昂贵的存储负担;没有严格验证的快速迭代,也可能把新的风险带到道路上。
所以,真正重要的从来不是简单地“拥有多少数据”,而是:
能否持续发现有价值的问题, 将问题转化为高质量数据, 再将数据转化为经过验证的新能力。
06
自动驾驶比拼的,是持续进化的速度
我们可以把一家自动驾驶公司的长期竞争力,大致理解为:
高价值数据发现能力 × 数据处理与标注能力 × 模型训练能力 × 安全验证能力 × 部署迭代能力
这是一道乘法题。
任何一个环节过慢,都会限制整个系统的进化速度。
两家公司即使使用相似的模型,面对同一个新场景时,也可能表现出完全不同的迭代效率:
一家公司需要数周才能找到数据、完成标注并验证新版本;
另一家公司可能已经拥有自动触发、场景检索、自动标注、仿真回放和回归测试系统,可以更快完成一轮经过验证的升级。
一次迭代的差距或许并不明显。
但当这样的过程重复成百上千次,差距就会不断累积。
需要强调的是,闭环速度并不等于盲目追求上线速度。
真正有价值的速度,是从发现问题,到形成一个经过验证、可以安全部署的解决方案所需要的时间。
写在最后
自动驾驶不是训练一个模型,然后把它装进汽车里。
它更像是在建设一套能够不断观察真实世界、发现自身不足、重新学习并验证结果的复杂系统。
算法决定了一辆车能否学会驾驶。
而数据闭环决定了它能否持续学习,能否处理越来越多没有见过的情况,能否从一次次失败中真正获得进步。
因此,自动驾驶公司真正争夺的,可能不是某一次模型发布时的领先,也不是某一张排行榜上的分数。
而是:
谁能让真实世界中的每一次问题, 更快地变成下一次更可靠的能力。
这或许才是自动驾驶行业最难建立,也最难被复制的长期壁垒。
ZiKi Robot Data Lab|知几机器人数据实验室
我们关注机器人数据、具身智能与 AI 数据基础设施建设。
持续分享:
🟧 行业观察
🟧 技术实践
🟧 第一视角数据
🟧 AI 自动标注
🟧 三维重建
🟧 数据集构建
下一篇预告:
《特斯拉 FSD 背后的秘密:数据飞轮如何滚起来》




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
