
虽然没有百度Apollo那样的规模,但我们都知道阿里巴巴一直在从事自动驾驶的研发工作,从2019年开始阿里的自动驾驶负责人就开始在各种媒体上谈到阿里巴巴的自动驾驶策略了,但直到这几天的云栖大会上阿里正式推出自己的自动驾驶物流小车——阿里小蛮驴,才真正唤起大众关注的目光。因此,小编觉得有必要今天在这里花一个篇幅,来分析和推测一下什么是小蛮驴,什么是阿里所坚持的自动驾驶技术策略。

阿里巴巴起步就是电商,拥有天然的配送属性,也有完全属于自己的物流公司(菜鸟),因此我们毫不怀疑阿里在“小蛮驴”上的产品属性定义和实现,那肯定是专家级别的:
1物理尺寸:小蛮驴的尺寸为2100*900*1200mm(加上激光雷达高1445mm)。小蛮驴车厢格口可以自由定制,按照最多每车满载50件常规尺寸的快递/包裹/外卖、每天送货10次计算,机器人峰值运力可达一天500单;【注,没有在园区场景下实际经营外卖送货体系的经验,是不可能理解小蛮驴绝对不只是个自动驾驶的问题。如何对最终用户鉴权、如何设计隔舱尺寸、如何让小蛮驴和上游物流系统对接、如何维持低成本高效率。这都是阿里的绝对技术核心,其它自动驾驶企业可能学不来。】
2 车速:考虑末端场景的安全需要,小蛮驴的最高速度设定为20km/h。【注,限定最高速度,将自动驾驶的技术难度降低,20kmph和园区网络道路的适应能力,基本可以让小蛮驴逃脱Level几的限定。】
3 续航和功耗:小蛮驴采用抽拉式充电电池,每次充电4度、续航里程102公里。其行驶100公里所耗费的电量,还不到吃两小时火锅用的电。功率仅有615w,不到戴森吹风机的一半(1600w),不到常规家用电磁炉的三分之一(约2000w)。【注,抽拉式电池箱,满足园区网络配送中心的工作环境,符合设备维护人员的操作习惯,这也是经验的体现。】
4 传感器:激光雷达*2(阿里定制,速腾聚创提供),环视摄像头*6,IMU+GPS综合套件(阿里定制),超声波or红外防撞传感器(不详)。【注,传感器的数量及规格等级,由于是在低速园区网络的限定场景使用,因此成本可控。同时Lidar来自阿里的控股企业,成本可以进一步限定。】
如果不考虑车载的中央处理单元,可能包含CPU、GPU和专用的FPGA,我们可以看到整车的设计,可靠性和成本是同样重要的,同时产品的易用度和可维护性,也是小蛮驴设计的重要方向。
当然,我们更关心的是小蛮驴的自动驾驶体系设计。按照阿里在各种技术场合下的公开资料表明,阿里对于低速园区网络的自动驾驶系统的设计、训练、测试和维护/迭代,有着自己完全不同于业界主流的看法(阿里观点)和实现,这就是一件非常有意思的事情了。
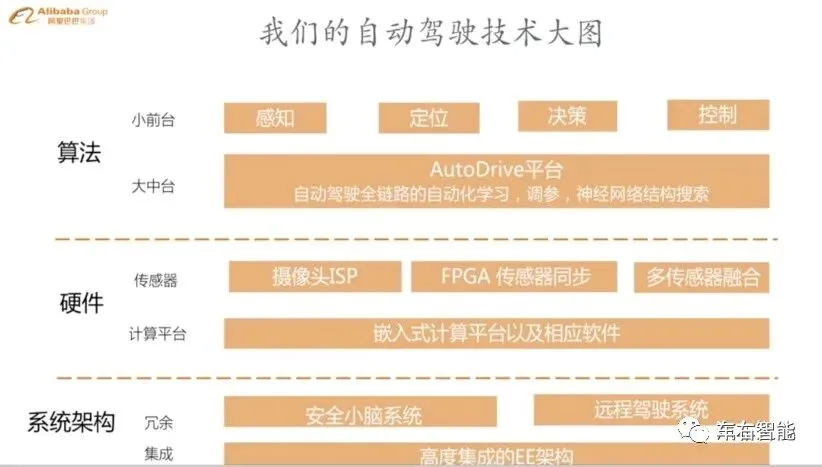
去年阿里云栖大会上,自动驾驶负责人曾经介绍过关于阿里独特的自动驾驶算法,小编第一次听到自动驾驶的“中台”概念。对于IT公司特别是和提供运维服务的IT实体来说,中台/数据中台往往是个可怕的架构,往往意味着要处理无限的数据量和无限的数据增长,往往意味着人力黑洞和成本黑洞。参看上图,阿里把中台概念带入自动驾驶体系,并命名为“AutoDrive平台”。
按照阿里方面公开的技术介绍,如下:
目前制约自动驾驶发展的最大瓶颈依然是算法不够优秀,所以就算把当今世界上最先进的传感器、计算单元都集成到一辆车上,这辆车仍然无法实现完全自动驾驶。正因此,阿里在自动驾驶算法的研发上投入了更多的精力,并提出了「小前台、大中台」的概念。
「小前台」指的是感知、定位、决策、控制这样的自动驾驶算法模块,这些是所有自动驾驶研发企业都必须开发的算法;「大中台」则是阿里团队自主打造的 AutoDrive 平台,这个平台由自动调参模块、网络结构搜索模块、主动学习模块、框架和基础集群平台组成,可以大大提升自动驾驶技术研发迭代的速度。如果将车辆的自动驾驶任务比作是一场攻坚战,那「小前台」扮演的就是冲锋队的角色,而「大中台」则是后续的飞机、坦克编队。「大中台」将为「小前台」提供强有力的支持。
现阶段,整个自动驾驶算法研发链路中还存在大量人工设计的环节,例如数据预处理、感知模块的神经网络结构/超参数、定位模块中的融合参数、决策模块中的规则及参数等等。这些人工设计的环节很大程度上限制了算法研发进度,让算法研发人员需要花大量的时间去调参,质量差、效率低。为了减少人工设计,阿里的 AutoDrive 平台能够基于海量自动驾驶数据,用搜索/优化的方式去自动化地学习更优的网络结构/参数/数据预处理等等,从而实现计算替代人工。
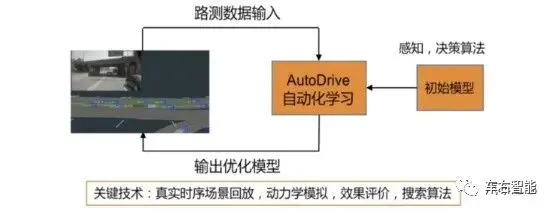
不同于业界的 AutoML 的部分在于:AutoDrive基于复杂的多模态的时序的自动驾驶数据进行自学习,并且能服务自动驾驶整个链路的算法模块,包括感知、决策规划和定位。举个例子,在面对一些比较典型的识别和检测任务时,如果人工设计一个检测网络,由于不知道哪些部分是最核心的网络,就可能带来冗余,但经过 AutoDrive平台的优化之后,网络复杂度将大大降低。因为自动驾驶对实时性要求非常高,所以降低网络复杂度可以提升整体效率以及降低对硬件的依赖程度。AutoDrive的背后,阿里也搭建出了自己的自动驾驶云平台,海量的数据(场景数据库、自动驾驶车数据、数据采集车数据)都被搬到了阿里云上。
【以上插图和文字描述来自于“汽车之心”相关文章的引用,URL:https://zhuanlan.zhihu.com/p/123326280】
如果是长期关注我们车右智能公众号的读者,其实看过阿里的这个AutoDrive平台介绍之后,应该都会有似曾相识的感觉。其实在小编看来,不论是“大中台-小前台”的深度学习结构概念,还是基于时序的自动驾驶数据收集和训练闭环,其实和Tesla的“多任务学习网络”以及“Data Engine循环”概念和方法几乎如出一辙。
差别在于,对于Tesla的多任务学习网络来说,是尽可能利用基础深度网络做一般性的数据处理,然后再根据手动定义的筛选规则,让处理过的meta数据流向不同的功能网络。比如以识别功能为例:静态目标、动态目标、交通信号、交通标识线等等;而对于阿里的Autodrive方法来说,大中台是个数据基座,经过基座的数据已经从头到尾处理完毕,深度网络在大中台上不仅按照功能/场景,甚至是非常细分的场景已经划分完毕了。举个例子:阿里说,光小蛮驴的Cut-in动作就细分了20种以上,借助20种以上的模型实现。从而实现了精准细分和精准训练。理论上讲,模型功能越单一,模型越容易收敛,而且模型输出的准确度也就越高,时延还更好。
但也不是没有问题,过于细分的场景,必须依赖更多的投入在前端的筛选,要么人力要么算力,都要慎重对待,如果数据流向了错误的模型/细分场景,那就张冠李戴,输出结果可想而知了。阿里的说法就是实现了这一部分的自动化,不清楚具体的效果,但想想这是低速的园区网络大环境,也许可靠性是足够的。
另外是训练的闭环,阿里和Tesla的这个data-engine的宣传重点都是自动化。阿里这里说的很模糊,而Tesla那一侧,关于shadow-mode和最近刚披露的时序数据自动化处理方法专利、以及Karpathy在很多场合头提到过的Vacation mode,其实都是这个意图,尽可能第一时间实现对于车队上报信息的处理,尤其是高价值的Long-tail数据。
小蛮驴的下一步,相信就是在园区开始大规模推广,可能目前依然无法克服不能坐电梯的限制,可能还有这样那样的问题,但是我们自动驾驶行业的从业者,其实最期待的就是规模应用。应用规模的突破,必然会带来高价值和高质量的技术迭代、升级并日趋完善。同理,我们也希望百度的Apollo能够尽快在合适的园区范围实现自动乘用驾驶技术的规模落地,这是我们保持和waymo差距的最佳方法。
大家加油!
车右智能
一个一直用心仿真的自动驾驶技术信徒
info@co-driver.ai
备注:
1 题图来自互联网搜索, https://baijiahao.baidu.com/s?id=1678170121722872301&wfr=spider&for=pc;
2 文中插图1,来自百度搜索;
3 文中插图2/3,来自汽车之心的知乎相关文章,链接:https://zhuanlan.zhihu.com/p/123326280;

