25年12月来自字节Seed和香港科技大学(广州分校)的论文“UniUGP: Unifying Understanding, Generation, and Planing For End-to-end Autonomous Driving”。
由于世界知识有限且视觉动态建模能力较弱,自动驾驶(AD)系统在长尾场景中面临诸多挑战。现有的基于视觉-语言-动作(VLA)的方法无法利用未标注视频进行视觉因果学习,而基于世界模型的方法则缺乏大语言模型的推理能力。在本文中,构建多个专用数据集,为复杂场景提供推理和规划标注。然后,提出一种名为 UniUGP 的统一理解-生成-规划框架,该框架通过混合专家架构协同实现场景推理、未来视频生成和轨迹规划。通过集成预训练的视觉语言模型和视频生成模型,UniUGP 利用视觉动态和语义推理来增强规划性能。它以多帧观测和语言指令作为输入,生成可解释的思维链推理、符合物理规律的轨迹和连贯的未来视频。引入一种四阶段训练策略,该策略结合多个现有自动驾驶数据集和提出的专用数据集,逐步构建这些能力。
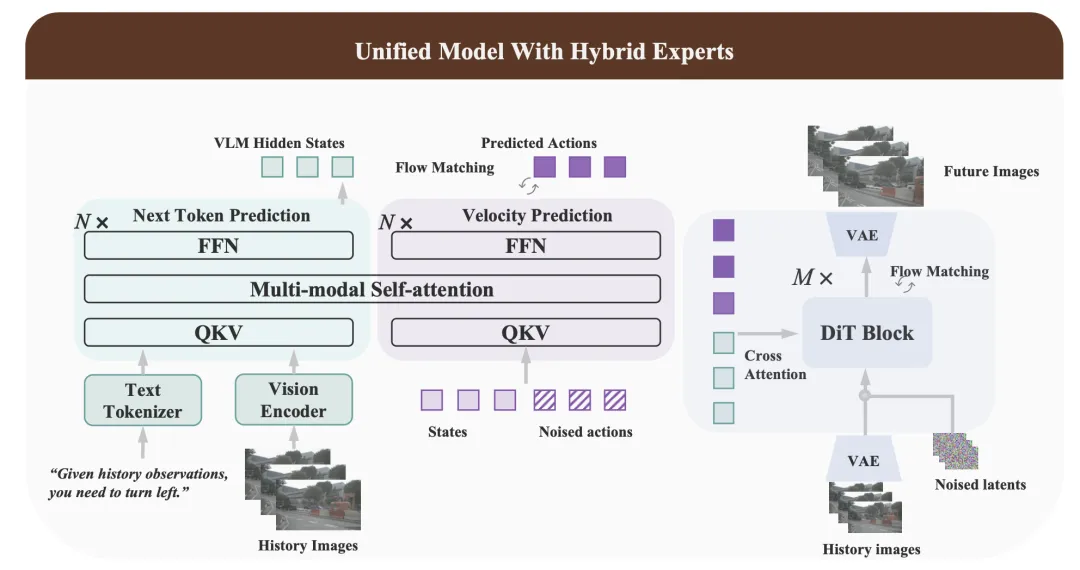
UniUGP 是一种用于理解、生成和规划的统一模型,旨在进一步增强跨不同模态的因果推理能力:1)收集并处理大规模的挑战性数据对,用于训练和评估统一模型的理解、推理、生成和规划能力。2)一个精巧的统一框架结合了 VLA 和世界模型的优势。3)精心设计的训练策略使统一模型能够从不同数据集的不同模态中充分获取知识。如图所示:
基于现有工作 [3, 14, 47, 57] 的有效性验证,理解和规划专家构成一个混合 Transformer (MoT) 架构,如上图所示。对于理解专家,选择 Qwen2.5-VL [1] 作为其骨干模型。文本指令和观察图像分别通过文本token化器和 ViT 编码器,首先被映射到对齐的跨模态理解token。
生成专家。生成专家与理解专家和规划专家以串行方式交互。在移动设备上,可以禁用生成专家以节省计算资源,而不会影响前述专家的性能。
生成专家与规划专家一样,通过流匹配过程生成未来视频。它由多个 DiT [54] 模块组成。实际上,采用 Wan2.1 [65] 作为基础模型,并继承其预训练参数。值得注意的是,任何其他基于 DiT 的视频生成模型在这里都是可行的。
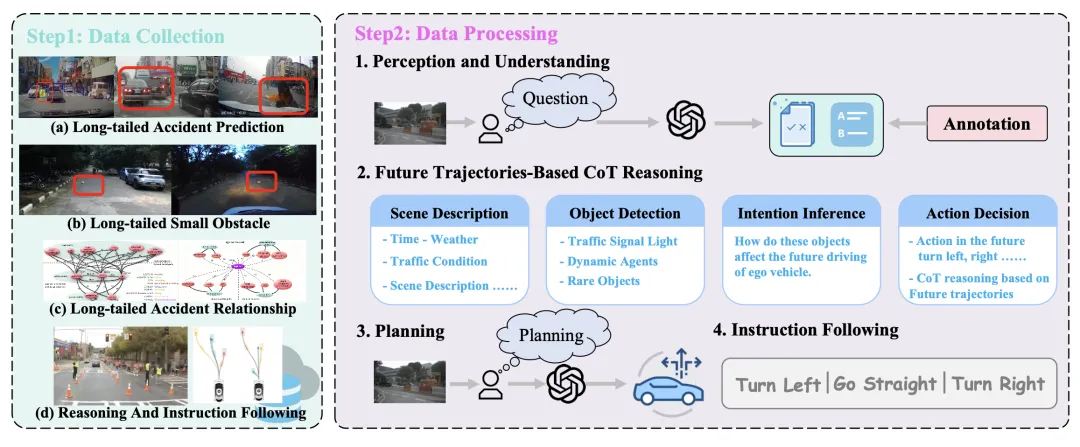
之前的基准测试侧重于结构化场景和基于模拟器的评估 [10, 63, 67],但忽略了长尾驾驶事件带来的挑战。为了解决这个问题,本文收集大量具有挑战性的长尾驾驶视频,包括 Waymo-E2E [79]、DADA2000 [13]、Lost and Found (LaF) [55]、StreetHazards (StHa) [18]、SOM [59] 和 AADV [7]。
对这些数据集进行进一步处理,以便分别用于训练和评估感知能力、因果推理能力、规划能力以及遵循指令的能力。对于理解任务,设计三个子任务:小目标检测、事故主体关系和事故预测。这些任务的问题和答案是基于数据集提供的标签和先进的 VLM 模型进行标注的。
CoT 推理:利用未来规划的结果和合理的提示来促使先进的 VLM 生成准确的 CoT。对 CoT 进行人工校准。最后值得一提的是,在未来为每条预测轨迹分配相应的指令,从而使模型具备遵循指令的能力。
如图所示描绘数据收集(整合多个具有挑战性的驾驶数据集)和数据处理(包括四个任务类别:理解、思维链、规划和指令遵循)的流程,旨在在一个统一的问答框架内训练和评估端到端自动驾驶模型的认知能力。
本文设计一个四阶段训练框架,该框架依次构建基础场景理解、视觉动态建模、基于文本的推理和多能力融合。
第一阶段:基础场景理解的持续训练旨在使理解专家能够全面理解各种驾驶场景,涵盖常见的交通情况和长尾案例。在此阶段仅训练理解专家。此阶段的训练数据集包括标注的长尾数据集和 ImpromptuVLA(来自 8 个开源大型数据集的 80,000 个精心挑选的视频片段)[10]。
第二阶段:视觉动态建模和规划训练侧重于学习视觉动态和运动规划能力。在此训练阶段,用包含轨迹的驾驶视频来训练生成专家和规划专家。用多个公共数据集,包括:nuScenes [4]、NuPlan [5]、Waymo [60]、Lyft [35] 和 Cosmos [56]。
第三阶段:用于因果验证的文本推理学习将 CoT 推理集成到理解专家中,使模型能够使用自然语言验证其感知和规划的逻辑。此阶段增强模型的可解释性,并确保决策基于明确的因果推理。这部分使用自己标注的 CoT 数据集进行训练。
第四阶段:多能力融合的混合训练解决各个阶段之间潜在的错位问题,并增强跨场景的泛化能力。在第四阶段,三个专家被联合训练以实现一致的端到端性能。以固定的比例混合使用来自第一阶段到第三阶段的数据集,以平衡基础能力、推理能力、规划能力和生成能力。总体目标 L_total 是三个子目标的加权和:
L_total = α·L_und + β·L_plan + γ·L_gen
其中 α = 0.3,β = 0.5,γ = 0.2。这种对齐确保模型作为一个统一的系统运行,而不是一组孤立的组件。