EPFL最新自动驾驶世界模型MAD:推理速度提升3.6倍,效果媲美闭源SOTA!
- 2026-07-02 05:57:46


论文标题: MAD: Motion Appearance Decoupling for efficient Driving World Models
机构:洛桑联邦理工学院 (EPFL), Valeo.ai, 索邦大学 (Sorbonne University) 论文地址: https://arxiv.org/abs/2601.09452 项目主页: https://vita-epfl.github.io/MAD-World-Model/ 代码仓库: https://github.com/VITA-EPFL/MAD-World-Model
最近,通用的视频生成模型(VGM)在生成照片级真实感和时序连贯的视频方面取得了巨大成功。然而,当这些模型被直接应用于自动驾驶领域时,它们往往力不从心。自动驾驶不仅需要好看的画面,更需要对结构化运动和物理一致性的深刻理解。
直接将这些通用视频模型微调以适应驾驶领域,虽然前景可观,但通常需要海量的领域专属数据和极其昂贵的计算资源。有没有一种更“聪明”的方法,能让我们以更低的成本,将强大的通用视频模型“改装”成一个可靠的自动驾驶世界模型呢?
来自洛桑联邦理工学院(EPFL)等机构的研究者们给出了一个优雅的答案。他们提出了一种名为 MAD (Motion-Appearance Decoupling) 的高效适配框架,其核心思想借鉴了动画制作的经典流程:先解耦运动学习与外观合成。
简单来说,就像动画师会先画出简单的“火柴人”草图来敲定故事的节奏和动态,然后再精细地绘制光影和纹理一样,MAD也采用了一个两阶段的过程:首先,让模型学习以简化形式(骨架化的智能体和场景元素)预测结构化运动,专注于物理和社会交互的合理性;然后,复用同一个模型骨干网络,在已生成的运动序列基础上合成逼真的RGB视频,相当于为动态“骨架”穿上华丽的“外衣”。
这种“先推理动态,再渲染外观”的解耦方法被证明异常高效。实验表明,基于SVD模型进行改造,MAD仅用不到 6% 的计算资源,就达到了先前SOTA模型(如VISTA, GEM)的水平。
背景与动机:昂贵的“世界模型”
“世界模型”是自动驾驶领域的一个重要概念,它旨在学习环境的动态变化规律,预测未来可能发生的场景。一个强大的世界模型,不仅能用于生成大规模的合成数据,还能让智能体在“内心世界”里进行规划和演练,从而提升决策的鲁棒性。
然而,构建一个同时精通“物理动态”和“逼真外观”的世界模型,计算成本极高。例如,VISTA模型和GEM模型分别耗费了25,000和50,000个GPU小时来微调SVD模型。而像NVIDIA的Cosmos-Predict这类更强大的模型,更是基于海量私有数据从头训练,其所需的计算资源令多数研究机构望而却步。
高昂的成本阻碍了学术界和更广泛的社区充分利用日新月异的通用视频模型技术。因此,MAD的目标就是打破这一僵局。
方法详解:MAD如何实现“运动”与“外观”的解耦?
MAD的整体框架可以看作一个“思维链”:模型先通过生成中间步骤(运动草图)来进行“思考”,然后再产出最终答案(渲染视频)。整个过程巧妙地复用了同一个预训练视频生成模型(如SVD或LTX)的骨干网络,并通过轻量化的LoRA进行微调。
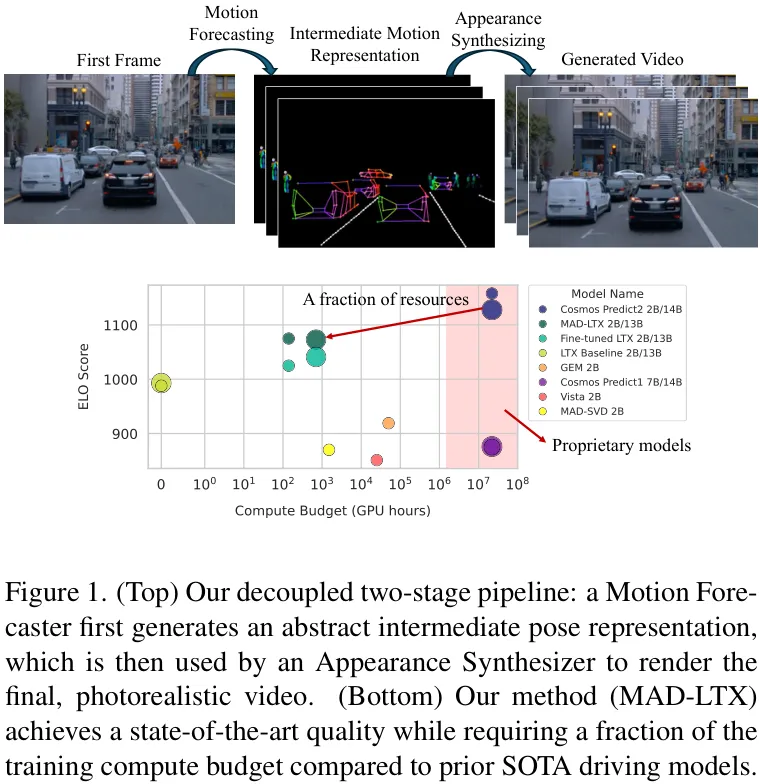
如上图所示,MAD的核心是一个两阶段的生成管线:
第一阶段:运动预测器 (Motion Forecaster)这一阶段的目标是“画草稿”,即生成一个只包含场景动态信息的抽象“姿态视频”。这个视频由车辆、行人的骨架以及车道线等关键静态元素构成,背景为黑色。研究者们通过现成的姿态估计算法,从真实视频中大规模地提取这些姿态作为伪标签,无需任何手动标注。
如下图(a)所示,运动预测器以带噪声的姿态视频、文本提示、第一帧RGB图像(提供上下文)以及可选的控制信号作为输入,其任务是去噪并预测出未来一系列连贯的姿态。
第二阶段:外观合成器 (Appearance Synthesizer)这一阶段的目标是“上色”,即为第一阶段生成的动态“骨架”穿上逼真的外衣。如下图(b)所示,外观合成器以上一阶段生成的姿态视频为核心条件,结合文本提示和第一帧RGB图像,渲染出最终的、照片般真实的RGB视频。
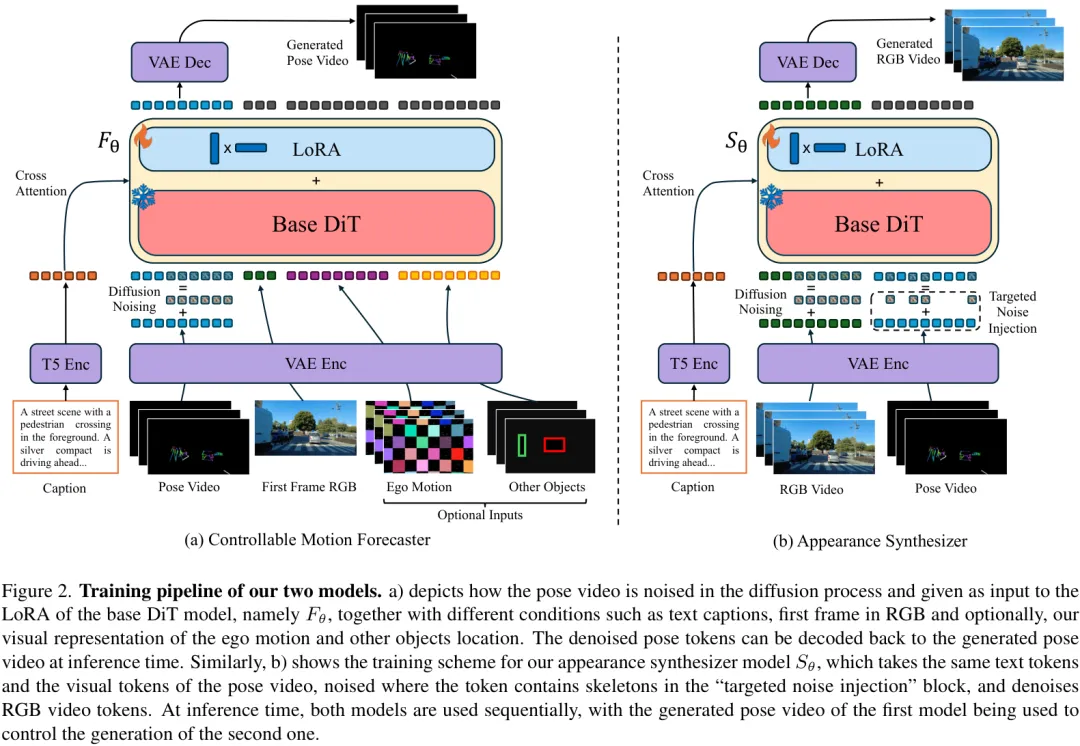
这里有一个非常关键的设计:在训练外观合成器时,研究者们会对其作为条件的“姿态视频”进行靶向噪声注入 (Targeted Noise Injection) 。这是因为在实际推理时,运动预测器生成的姿态可能会有模糊、断裂等瑕疵。通过在训练中模拟这种不完美,外观合成器能学会对这些瑕疵进行“脑补”,从而变得更加鲁棒,最终生成的视频质量也更高。
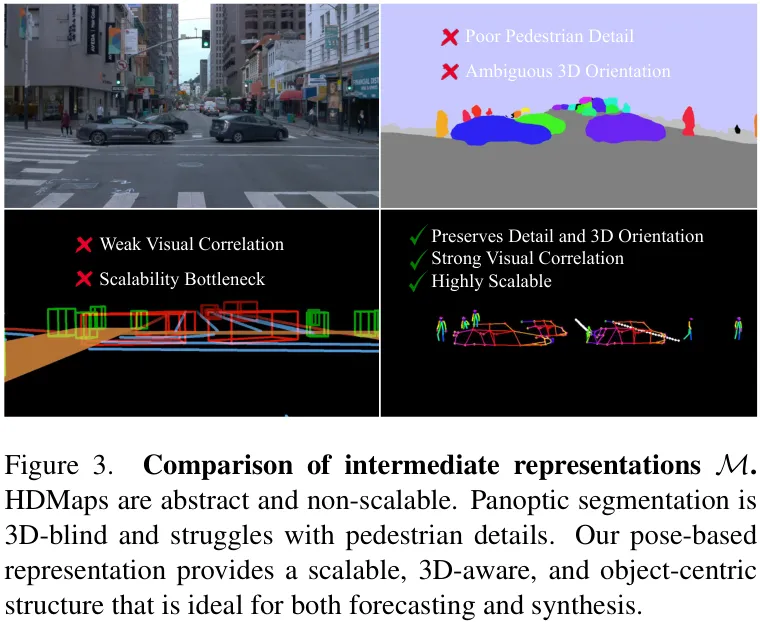
值得一提的是,研究者们对比了多种中间表征,包括HDMap和语义分割。实验证明,基于姿态的表征在预测和合成之间取得了最佳的平衡:它既为运动预测提供了足够的3D感知和对象结构化信息,又为外观合成保留了像素对齐的细节。
实验与结果:效率与性能的双重胜利
MAD框架的有效性在基于SVD和LTX两个不同基础模型的实验中得到了充分验证。
首先,作为一个概念验证,MAD-SVD在效率上取得了惊人的成功。如下图所示,与同样基于SVD的VISTA和GEM模型相比,MAD-SVD在性能相当的情况下,计算成本分别只有它们的6% 和3% 。

当扩展到更强大的LTX基础模型上时,MAD-LTX更是展现了全面的SOTA性能。
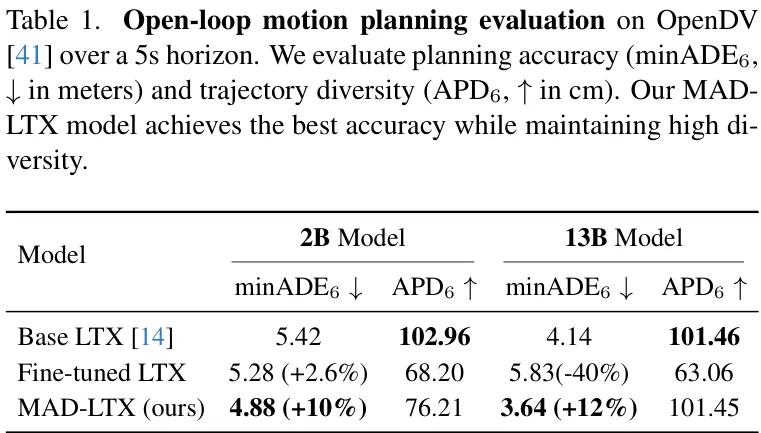
规划精度SOTA:在开环运动规划任务中,MAD-LTX实现了当前最佳的规划精度,同时保持了预测轨迹的高度多样性,有效避免了模式崩溃。如下表所示,其13B模型的minADE6指标达到了 3.64米,比 Base LTX (4.14米) 提升了约 12%。。
推理速度大幅领先:如下图所示,MAD-LTX模型的推理速度比同等规模和性能的竞品快了高达 3.6倍,这对于实际应用至关重要。
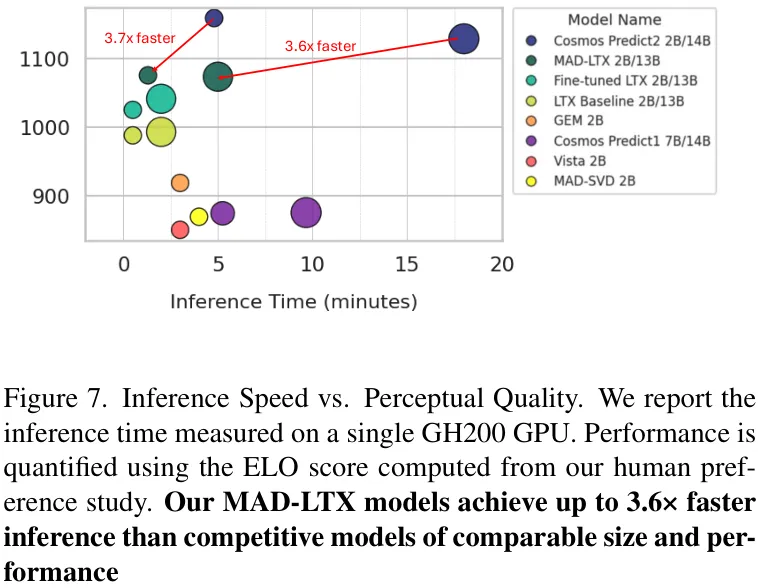
人工评估大获全胜:在最能反映真实感受的人工评估中,MAD-LTX在“综合质量”、“运动真实感”和“视觉质量”等多个维度上,全面超越了所有现有的开源驾驶世界模型。其表现甚至能够媲美顶级的闭源模型Cosmos-Predict2。

写在最后
MAD的提出,为如何高效地将通用基础模型适配到特定专业领域提供了一个极具启发性的新范式。它证明了通过巧妙的“解耦”设计,我们可以在不牺牲性能的前提下,大幅降低对计算资源的依赖。
这种“先规划动态,再渲染外观”的思路,不仅在自动驾驶领域取得了成功,也为机器人、人本视频生成等其他依赖姿态和运动的领域指明了一条充满潜力的道路。我们期待看到MAD的思想在更多场景中开花结果。


