同济|自动驾驶规划盘点:从模仿学习、强化学习、生成式到数据驱动的最优控制
- 2026-07-06 01:51:10
 「可解释的学习&带学习的控制」
「可解释的学习&带学习的控制」
规划控制作为整个自动驾驶算法流程中最下游的模块,直接决定着自动驾驶的安全性及舒适度。
当前运动规划的主流方案大致分两派:
传统方法结构清晰、可约束、便于验证,但在长尾场景和复杂交互里容易变得保守、僵硬;
学习方法适应性更强,能从数据中学到更自然的驾驶行为,但也面临可解释性、安全保证和落地成本等挑战。
同济大学最新综述沿着“传统规划流水线 → 三类学习式规划路线 → 数据驱动的最优控制”这条主线,梳理学习式运动规划的典型思路、优势与瓶颈,并给出目前更被看好的折中方向:在结构化控制框架下引入数据学习,让系统既能适应现实,又能守住安全约束。
运动规划在自动驾驶里做什么?
为了让读者有一个清晰的地图,先从运动规划的典型分工说起。常见系统会把规划拆成三层:
路线层:决定从起点到终点走哪条路,偏全局。
行为层:决定驾驶意图,例如跟车、变道、让行,核心是与周围参与者的交互。
轨迹层:将意图落成短时间内可执行的轨迹或控制指令,需要同时满足碰撞避让、车辆运动约束和舒适性。
这种分层结构的优点是清晰、可控、易调试,也便于加入安全约束。问题在于模块之间往往是“各管一段”,复杂场景下容易出现局部决策之间的不一致,于是就会出现看似合理却不够顺滑的驾驶表现。
理想的规划系统需要哪些能力?
在自动驾驶落地过程中,规划系统通常被期待具备以下能力(用更通俗的说法概括):
能泛化:换城市、换路况、换交通风格也能稳定运行。
够安全:不仅不撞,更要能约束、能验证、能解释为什么这么做。
可部署:车端实时计算可行,面对噪声、延迟与感知误差仍稳定。
会互动:不把周围车人当静态障碍物,而是能理解彼此影响与博弈。
可定制:驾驶风格可调,能在稳、快、舒适之间按需求取舍。
能覆盖长尾:真正致命的是小概率但高风险的场景,必须尽量减少“没见过就崩”的情况。
这些目标经常互相拉扯:越强调形式化安全约束,越容易保守;越追求更像人,越可能变得黑盒。学习式规划方法的意义就在于尝试在这种矛盾中找到新的平衡点。
当然,无论技术路线如何演进,扎实的传统规控理论与工程实现能力(如PID, LQR, MPC, A*等)始终是自动驾驶工程师的入行基石,也是理解复杂上层算法逻辑的前提。如果你希望系统地掌握这些核心算法,从理论推导到C++代码落地,弥补项目实战经验的不足,推荐你关注深蓝学院的《自动驾驶控制与规划》课程。这是一门专为希望深入规控领域的同学打造的实战课,不仅涵盖了主流算法详解,更强调代码层面的实现与应用。感兴趣的朋友可以扫码咨询:

学习式规划通常可以归为三类:模仿学习、强化学习、生成式方法。每一类的核心思路并不复杂,但各有优势和硬伤。
模仿学习:从人类数据里学“像人开”
核心思想:用人类驾驶数据作为示范,直接学习输出轨迹或动作,目标是让驾驶行为更自然、更贴近人类习惯。
优势:
训练直观、容易收敛;
输出更像人,交互场景往往更顺;
在工程上可与传统规划结合,用学习补足“难写规则”的部分。
主要挑战:
需要大量高质量示范数据,采集和清洗成本高;
容易遇到“分布偏移”:训练数据覆盖不到的场景出现时,策略可能突然失真;
可解释与可验证仍不够强,出问题时溯源与定位较难。
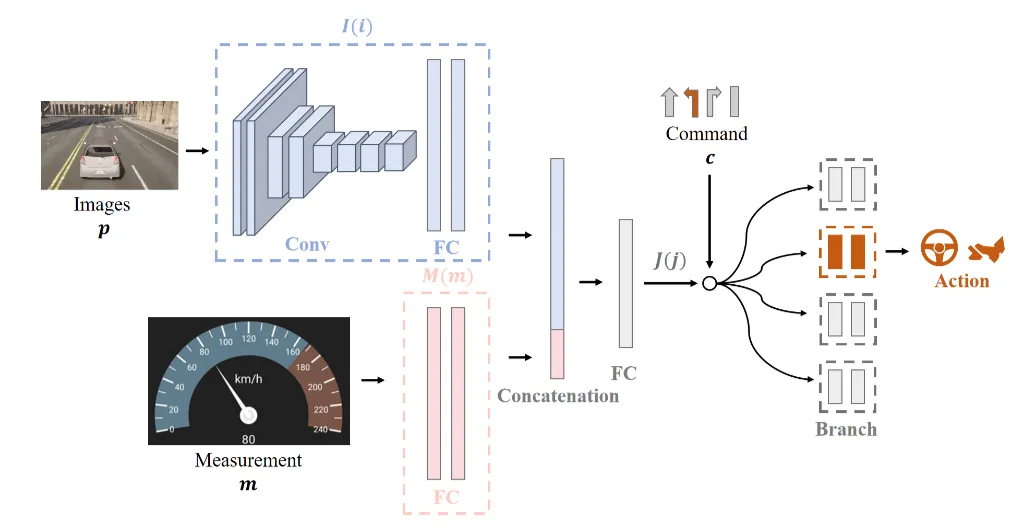
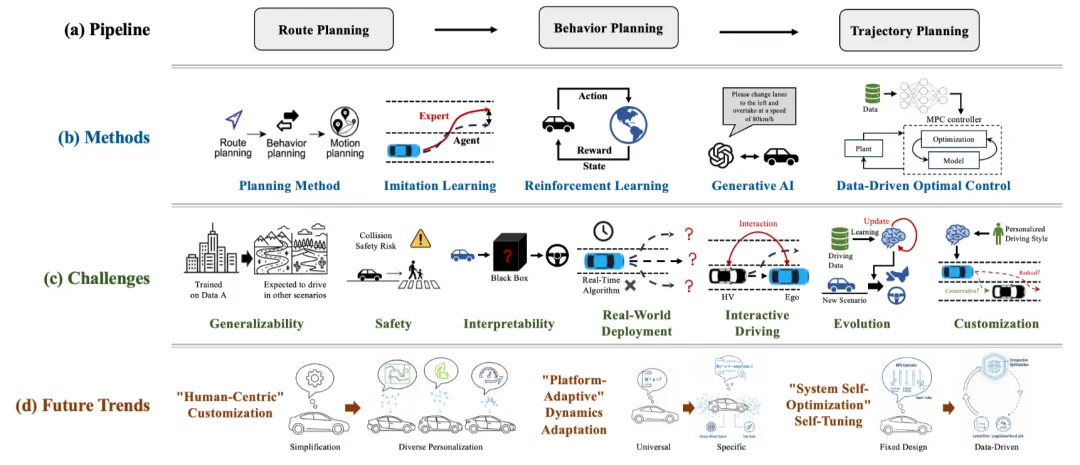
图1|一种典型的“条件模仿学习”结构示意。系统根据感知输入,再结合高层指令(例如“直行/左转/右转”这类驾驶意图),直接学习输出车辆的驾驶动作或轨迹,用数据让行为更接近人类驾驶风格©️【深蓝AI】编译
强化学习:通过试错学“更优的权衡”
核心思想:不只是学“像人”,而是通过奖励信号在环境中反复试错,学到在安全、效率、舒适等目标之间更优的权衡策略。
优势:
能优化长期目标与复杂权衡;
理论上可学到更强的决策能力,尤其在交互与复杂场景上潜力更大;
可与分层规划结合,把学习用于行为决策或局部策略。
主要挑战:
数据效率低,需要大量交互才能稳定学习;
真实道路难以安全试错,训练往往依赖仿真,迁移到真实会遇到差距;
仍存在黑盒问题,安全边界与稳定性难以工程化证明。
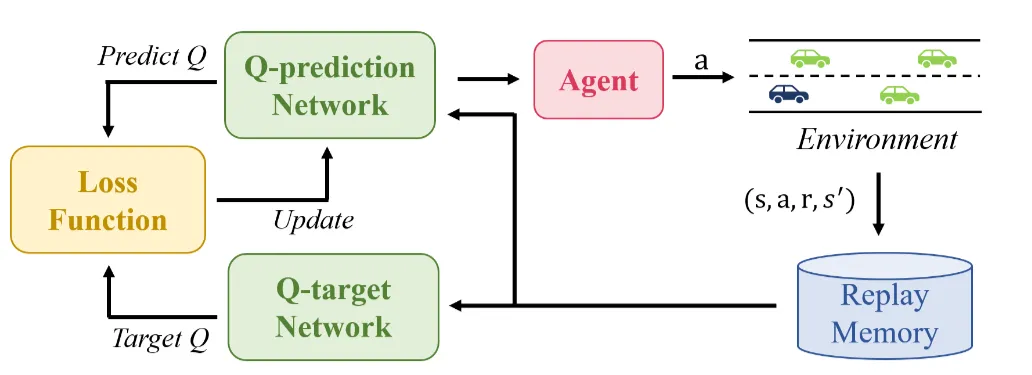
图2|基于强化学习的一种端到端自动驾驶结构示意。系统通过“试错+奖励反馈”的方式学习驾驶策略:模型从感知输入出发,评估不同驾驶动作的好坏,并逐步学会在不同交通情境下选择更合适的动作(更安全、更高效或更舒适)©️【深蓝AI】编译
生成式方法:生成多种候选,再在约束下挑选
核心思想:不再只输出一个轨迹或一个动作,而是生成多个可能候选,再结合约束与评估机制选择更合理的方案。它更接近“先想多种可能,再选最稳的”。
优势:
表达能力强,能覆盖更多可能性;
对复杂场景的多解性更友好,有利于减少“被单一路径卡死”;
在融合高层语义信息、规划多样性方面具有吸引力。
主要挑战:
车端实时性压力大,算力与延迟是硬约束;
生成越自由,越需要更强的可控性与一致性机制,否则难以保证稳定与安全;
评测与验证标准仍不成熟,落地路径尚不统一。
图3|生成式方法网络结构示意。模型用两条并行分支处理不同来源的感知信息(例如摄像头与其他传感器),并在不同尺度的特征层上进行交互融合;融合后的信息再用于预测未来的行驶轨迹,实现“看见环境→融合信息→生成未来路径”的一体化流程©️【深蓝AI】编译
数据驱动的最优控制
在三类学习方法之外,一个越来越重要的趋势是:让学习融入结构化控制框架,而不是完全替代它。这类思路通常被概括为“数据驱动的最优控制”,核心要点可以用一句话说明:
在可约束、可解释的控制框架中,用数据持续学习与修正关键组件,让系统既能适应现实变化,又能守住安全底线。
这条路线被重视,主要因为它试图同时满足两件事:
保留结构化控制方法的优势:约束清晰、可验证、实时性可控;
引入学习的优势:能从数据中吸收经验,适应车辆与环境变化。
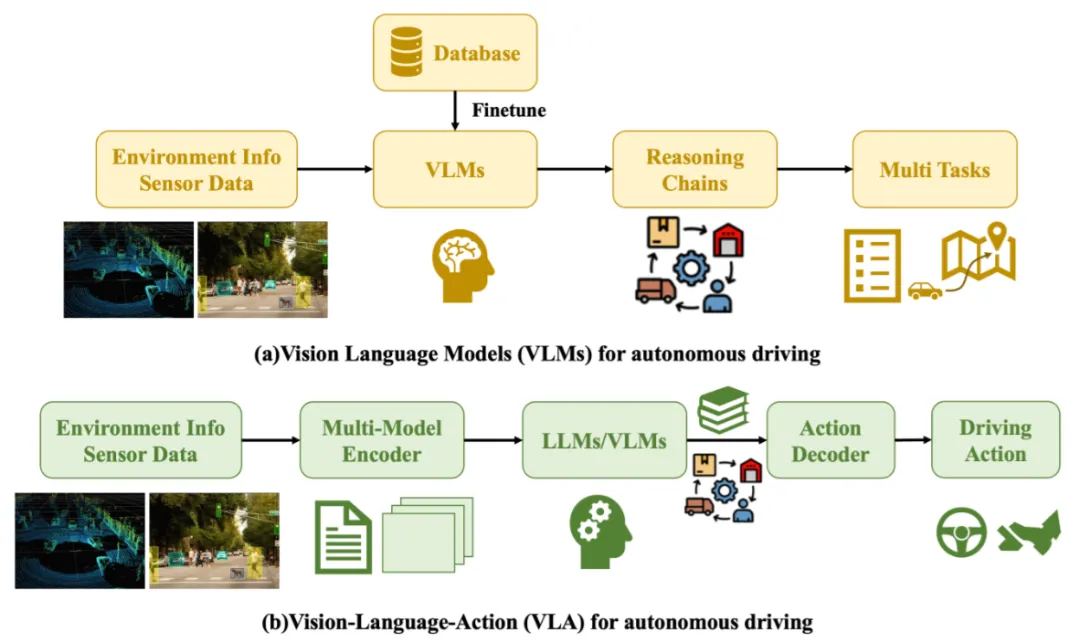
图4|两类“带大模型”的自动驾驶模式对比。(a) “会解释的驾驶模型”:引入自然语言推理,让系统能用更接近人类的方式描述自己的理解与决策理由,但核心仍偏向“先感知再解释”。(b) “一体化驾驶模型”:把环境理解、决策推理与动作输出更紧密地连起来,目标是在闭环驾驶中做到更可控、更稳,同时也更容易给出可解释的决策依据©️【深蓝AI】编译
这种“学习 + 控制”的结合通常被用于支撑三类能力目标:
驾驶风格可定制
驾驶风格并非只有“激进/保守”两档,而是对跟车距离、加速响应、舒适性偏好、能耗取舍等一系列权衡。数据驱动方法可以把这些偏好转成可解释的参数或权重,并随用户或场景调整,实现“可控的个性化”。
动力学与工况自适应
车辆在不同载重、不同路面、不同轮胎状态下响应会变化。依赖固定模型的方案容易积累误差,影响稳定性。数据驱动更新机制可以持续校准,使控制策略更贴合真实车况。
自调参与自我优化
传统控制系统大量依赖工程师手动调参,面对多车型、多城市、多工况的部署成本很高。数据驱动的自调参机制将调参转为基于反馈的持续优化过程,在安全约束下追求性能稳定与体验一致。
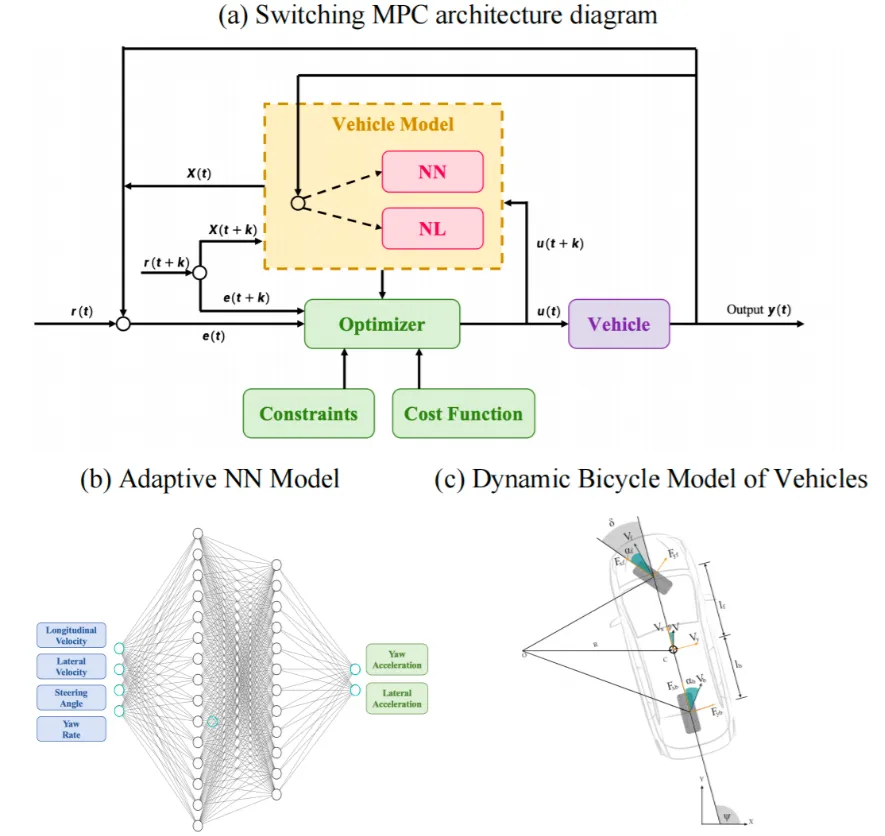
图5|“可切换的控制框架”示意:学习模型与传统物理模型协同工作。在运行初期或遇到新工况时,因为数据不足,纯数据学习的模型可能不够可靠,此时系统更依赖传统的物理模型保证稳定;随着在线数据积累与持续适应,学习模型逐渐变得更贴合真实车况,并在某些场景下表现更好©️【深蓝AI】编译
面向更大规模真实部署,当前路线的共识趋势大致集中在几件事:
更强的预测能力:更准确地预测未来几秒的场景变化,使规划更从容;
更深的混合范式:学习与结构化控制更紧密融合,减少“黑盒不可控”;
更普遍的自适应:对用户偏好、车辆状态、环境差异的适应成为标配;
安全验证仍是底线:越智能、越自适应,越需要把约束与验证机制做实,否则难以进入规模化上路阶段。
学习式运动规划的发展脉络可以概括为:
模仿学习让系统更像人,强化学习追求更优权衡,生成式方法提升了多样性与表达力。但要真正走向真实道路,单靠“更聪明”不够,还需要“更可控”。因此,“数据驱动的最优控制”这类融合路线受到关注,它试图在结构化约束的底座上引入数据学习,让系统既能适应复杂现实,又能工程化地守住安全与稳定。
这条主线提供了一个清晰判断标准:自动驾驶规划下一步的关键,不是某个方法名词更响,而是谁能把“适应性”和“可验证性”同时做到位。
审编|阿蓝
Ref:https://arxiv.org/pdf/2512.11944 作者:Jia Hu, Yang Chang, Haoran Wang
商务推广/稿件投递请添加:xinran199706(备注商务合作)


· 计划周期:深蓝学院将以3个月为一个周期,建立工程师&学术研究者的「同好社群」
· 覆盖方向:自动驾驶、具身智能(人形、四足、轮式、机械臂)、视觉、无人机、大模型、医学人工智能……16个热门领域
扫码添加阿蓝
选择想要加入的交流群即可
(按照提交顺序邀请,请尽早选择)
👇

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 加拿大放开中国电动车的背后原因
- 红旗真猛将!插混SUV补贴2.9万,4C快充+续航1650km+四驱,太卷!
- 全民投票:如果由你决定电动车的命运,你会投“赞成”还是“反对”?
- 13.38万级合资SUV王炸!途观L两驱龙腾版直降5.3万,实力与性价比双在线!
- 星光560购车手册:6万级“硬派”SUV,实用大空间,推荐次低配
- 预告|“高级别自动驾驶的法治需求与天津实践”研讨会
- 颠覆传统!端到端自动驾驶:是终极答案,还是潘多拉魔盒?
- 种5亩就能换1辆轿车?引种10年后,浙江农户“血亏”一斤卖两三块
- 五菱入局六座SUV!首款车型撞脸路虎,造型吸睛!
- 深圳市自动驾驶安全实验室成立:汇聚同济大学、电子科大深圳院、比亚迪、美团、小马智行、华为、百度、九识、白犀牛等全产业链力量,
