【AI布局】自动驾驶AI模型布局!
- 2026-07-05 01:49:11
一、什么是 VLA?自动驾驶的 “统一大脑”
在 VLA 出现之前,自动驾驶系统更像 “拼接体”:视觉感知、语言理解、动作规划是三个独立模块,数据流转割裂,难以实现真正的 “端到端优化”。而 VLA 的核心突破,是打造了一个 “全程可求导” 的统一架构 —— 将 “看(视觉)、想(语言推理)、做(动作执行)” 融为一体。
简单说,VLA 是 “视觉 - 语言 - 动作” 的三位一体模型:
传统方案(E2E+VLM):视觉输出图像特征,语言模型输出文本,动作模块再 “翻译” 文本生成轨迹,全程非可求导,存在 “语义鸿沟”; VLA 方案:从传感器输入到轨迹输出,形成 “V→L→A” 的串行统一模型,数据无缝流转,可端到端联合优化,决策更连贯、更类人。
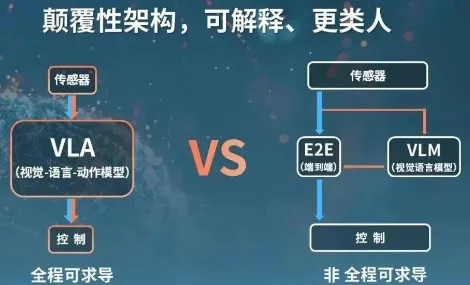
其本质是让自动驾驶系统具备 “认知能力”:不仅能 “看到” 路况,还能 “理解” 自然语言指令(如 “避开路边行人”),更能 “规划” 出符合人类习惯的平滑轨迹 —— 就像经验丰富的老司机,而非只会执行固定指令的机器。
二、VLA 核心技术拆解:眼睛、大脑、手脚的协同革命
VLA 的强大,源于三大核心模块(V/L/A)的精密配合,每个模块都藏着关键技术突破:
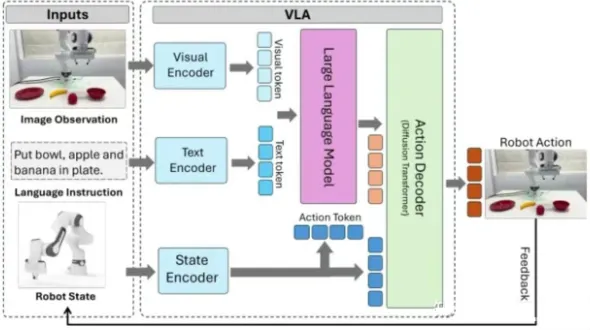
1. 视觉模块(V):从 “平面感知” 到 “3D 数字孪生”
视觉是 VLA 的 “眼睛”,核心任务是精准理解空间场景。主流技术路线分为两类:
通用方案(SigLIP+DINOv2 双编码器):SigLIP 负责 “认内容”(比如 “这是行人”),DINOv2 负责 “懂空间”(比如 “行人在车前方 3 米”),两者特征融合后,通过 MLP 投影器与语言模块对齐; 理想 MindVLA 方案(3D 高斯建模 3DGS):彻底抛弃传统 BEV 的离散栅格,用数百万个连续的 “高斯球” 重建 3D 场景,形成高保真的 “数字孪生世界”,无需依赖人工 3D 标注,直接为后续推理提供原生 3D 输入。
2. 语言模块(L):从 “文本生成” 到 “决策核心”
语言是 VLA 的 “大脑”,负责跨模态推理和意图输出。主流选择与优化方向:
模型选型:LLaMA 家族(开源标配,如 Llama 2 7B)、阿里 Qwen 系列(车端适配性强)、自研模型(如理想 MindGPT); 关键优化: 小米 ORION:基于开源 LLM+LoRA 轻量化微调,用 QT-Former 处理长时程历史信息,解决 “Token 长度限制”; 理想 MindGPT:从零预训练,以 3D 高斯特征为 “母语”,通过 MoE(混合专家)+ 稀疏注意力降低算力消耗,并行解码实现 30Hz 实时响应,天生适配驾驶场景的物理因果律。
3. 动作模块(A):从 “轨迹点” 到 “拟人化黄金轨迹”
动作是 VLA 的 “手脚”,核心是将决策转化为可执行的控制信号。目前最受青睐的方案是:
扩散模型(Diffusion Transformer):擅长建模复杂多模态动作,生成的轨迹不再是 “机器化的直线 + 圆弧”,而是像 “旋轮线” 一样平滑、拟人,兼顾安全、效率与舒适度; 工程突破:通过 ODE 采样器将 “去噪迭代” 从数百步压缩到 2-3 步,满足自动驾驶 33 毫秒的实时控制要求; 进阶能力:理想 MindVLA 实现 “多智能体集体建模”,不仅规划自车轨迹,还能预判周边车辆、行人的行为,从 “反应式” 升级为 “博弈式” 决策。
三、主流玩家路线之争:理想 “自研重构” vs 小米 “巧劲对齐”
目前 VLA 领域有两大代表性技术路线,分别以理想 MindVLA 和小米 ORION 为代表,各有侧重:
理想 MindVLA:全栈自研,重构驾驶智能
核心逻辑:从视觉、语言到动作全链路自研,打造原生适配 3D 驾驶场景的统一模型; 关键突破:3DGS 视觉革命、MindGPT 原生 3D 推理、Diffusion 动作生成,三者深度协同,追求 “极致性能上限”; 优势:无模块割裂,3D 空间理解和时序推理能力更强,轨迹生成更拟人; 挑战:研发投入巨大,对数据和算力要求极高。
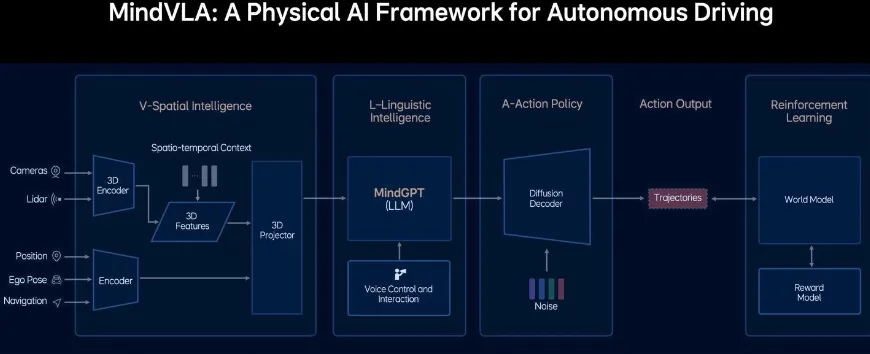
小米 ORION:开源底座 + 精准对齐
核心逻辑:基于成熟开源 LLM(如 Vicuna v1.5),通过 “规划 Token” 弥合 “语义鸿沟”; 关键突破:QT-Former 解决长时程时序问题,VLM 生成抽象 “规划 Token”(如 “减速让行”),再由生成模型转化为轨迹,专业分工明确; 优势:开发速度快,复用社区成果,轻量化部署更灵活; 挑战:依赖开源模型底层能力,3D 物理世界原生理解稍弱。
两条路线殊途同归:都是为了让自动驾驶从 “被动执行” 升级为 “主动决策”。
四、VLA 的进化飞轮:数据、RLHF 与世界模型的协同
VLA 的 “类人智能” 并非一蹴而就,而是靠 “数据 + RLHF + 世界模型” 的闭环飞轮持续进化:
1. 数据:三模态对齐的 “黄金燃料”
VLA 的进化遵循 “数据规模定律”,但需要的是 “视觉(V)+ 语言(L)+ 动作(A)” 三模态对齐的数据 —— 比如 “看到行人(V)→ 想‘要减速’(L)→ 执行刹车(A)”。这种数据极其稀缺昂贵,目前主要通过 “自动标注 + 人工筛选” 的 “数据炼金术” 获取。
2. RLHF:价值观校准器
单纯的模仿学习会让 VLA “学坏”(比如模仿驾驶员的危险操作),而 RLHF(人类反馈强化学习)通过 “采样 - 打分 - 优化” 三步,让 VLA 的行为对齐人类偏好:安全、舒适、合规,避免成为 “只会模仿的机器”。
3. 世界模型:无限虚拟训练场
世界模型以 3DGS 为基础,构建 “数字孪生世界”,让 VLA 可以在其中无限试错学习 —— 比如模拟 “行人突然横穿马路”“暴雨天视线受阻” 等长尾场景,无需承担真实道路风险。理想 MindVLA 通过这项技术,让训练速度提升了 7 倍。
三者形成闭环:数据喂饱模型,RLHF 校准方向,世界模型加速进化,让 VLA 从 “新手” 快速成长为 “老司机”。
五、大规模落地:四大挑战待突破
尽管 VLA 技术前景广阔,但要走进寻常百姓家,还需跨越四大 “拦路虎”:
1. 算力之墙:大模型塞不进车端芯片
VLA 的 “大脑”(如 7B 参数的 LLM)参数量巨大,而车端芯片(如 Orin-X)功耗和成本有限,还要满足 30Hz(33 毫秒 / 帧)的实时响应。目前通过 MoE 稀疏激活、模型量化、并行解码等技术优化,但仍需硬件与算法的深度协同。
2. 数据之渴:高质量数据稀缺
三模态对齐数据收集难、标注贵,尤其是 “长尾场景”(如极端天气、罕见事故)样本极少,成为 VLA 进化的 “瓶颈”。
3. 安全之问:避免 “智能幻觉”
LLM 的 “幻觉” 问题可能导致致命风险 —— 比如误判不存在的障碍物而急刹,或误解语音指令(如 “floor it” 被字面理解)。如何验证 “黑箱推理” 的安全性,仍是行业未解难题。
4. 感知之差:用户难以直观感受
现有 L2 + 系统已能满足大部分场景需求,VLA 的提升更多是 “从 L2.5 到 L2.9” 的长尾优化,用户感知不明显,难以形成付费意愿。
六、不止于车:VLA 开启具身智能新时代
VLA 的价值远不止自动驾驶。开源项目 OpenVLA 已证明,其技术栈(Llama 2+DinoV2+MLP)可直接迁移到机器人领域,在抓取、放置等复杂操作中,成功率超越谷歌 RT-2-X。
未来,VLA 将成为具身智能的基石:
基础物理大模型:一个模型适配汽车、机器人、无人机等多种设备; 神经 - 符号安全内核:用 “符号逻辑” 为神经网络决策加 “安全气囊”; 标准化交互语言:让车与车、人与机器人用统一语言协作。
结语:从 “机器执行” 到 “类人智能” 的跨越
VLA 技术的核心,是让智能体从 “被动响应环境” 升级为 “主动理解世界”—— 它不仅能 “看到”“做到”,更能 “想到”“说到”。
尽管落地挑战重重,但随着算力优化、数据积累和安全技术的突破,VLA 终将改写自动驾驶的规则,让汽车不再是冰冷的交通工具,而是真正懂你、护你、陪你的 “移动智能伙伴”。
自动驾驶的 “类人时代”,已在路上。你准备好迎接这场革命了吗?
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 非共识:全自动驾驶和人形机器人
- LOFIC技术如何攻克纯视觉自动驾驶复杂光照下的感知瓶颈?
- 在小区安装电动汽车充电桩,需要满足什么条件?
- 【智驾技术】小马智行L4 自动驾驶布局!
- 中加电动车关税安排深度解析:从“象征性破冰”到中国产业链核心竞争力展望
- 加拿大公交公司总裁:“坐等看中国廉价电动车在加拿大的冬天彻底趴窝,想想都觉得好笑”
- 紧急提醒!广州650万电动车车主注意:3月1日前这事不办半天白干
- 波兰军队考虑禁止中国电动汽车进入军事基地,理由是存在收集敏感数据的风险,外交部回应→
- 中国的电力需求如何改变全球AI与电动汽车竞争格局
- 电网都没铺好!非洲电动车却找到野路子
