作者:巫婆塔里的工程师
地址:https://zhuanlan.zhihu.com/p/1964698024572880743
经授权发布,如需转载请联系原作者
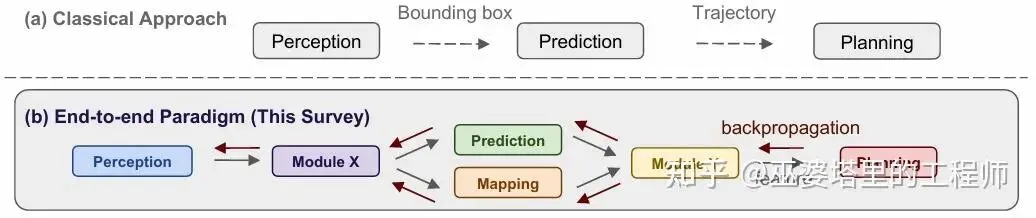
自动驾驶已经走过了二十多年的发展历程。从最初DARPA的无人车竞赛到今天商业化落地的RoboTaxi,行业中始终存在一个争论:究竟应该坚持分模块、层层递进的工程化方案,还是尝试“端到端”的方法,把感知、决策和控制融为一体?
在传统的自动驾驶架构中,系统往往被划分为几个核心模块:感知(检测和识别环境中的行人、车辆、道路元素)、预测(推测这些交通参与者未来的运动轨迹)、决策(生成合理的驾驶意图与路径)和控制(将路径转化为转向、油门、刹车等控制信号)。这种模块化架构的优势在于逻辑清晰、可解释性强,符合工程师们熟悉的分而治之的思路。也正是依靠这种模式,自动驾驶在过去十余年里走出了实验室,进入了量产落地阶段。
然而,模块化架构也有其局限性。首先,不同模块之间需要大量的接口与中间表示,信息在传递过程中可能丢失甚至被扭曲。比如,感知模块输出的是离散的检测框或语义标签,但这些结构化信息并不一定能完整保留原始传感器中的细节。其次,模块之间的误差可能会逐层累积,造成系统整体的不稳定。最后,随着场景复杂性的提升,模块之间的耦合关系愈加复杂,开发和维护成本也越来越高。
正是在这样的背景下,“端到端自动驾驶”开始受到关注。顾名思义,端到端方法希望从原始的传感器输入(比如摄像头图像、激光雷达点云)直接输出最终的控制信号(方向盘转角、加速度、刹车力度),中间不再显式拆分为多个模块。端到端方案的支持者们认为,系统应该像人类一样——司机开车时不会在大脑里画出bounding box,也不会显式预测周围每辆车的轨迹,而是凭直觉和经验,直接决定方向盘该往哪边打,油门和刹车该怎么踩。
对于这个观点我其实持有一定怀疑态度,因为人类驾驶员在驾驶过程中也要去识别周围的各种障碍物,只不过这些信息的表达并不是bounding box,也不是语义标签。人类驾驶员很显然具有独立的感知和决策模块,这些模块之间如何传递信息,我们其实并不十分清楚。
模块化 vs. 端到端(图片来自论文 End-to-end Autonomous Driving: Challenges and Frontiers)
言归正传,本文的重点是以时间为线索梳理端到端方案的发展历程。至于模块化和端到端哪个才是自动驾驶的答案,目前并没有定论。也许它们都不是,未来可能还会有更加颠覆性的架构。
端到端自动驾驶这个概念并不新鲜。早在上世纪八十年代末,美国卡内基梅隆大学的研究团队就提出了ALVINN(Autonomous Land Vehicle In a Neural Network)。它利用早期的神经网络,从摄像头图像直接预测方向盘转角,被视为端到端自动驾驶的雏形。虽然当时的计算能力和数据规模远远不足以支撑端到端训练,但这一工作却为后来的研究埋下了种子。
进入深度学习时代之后,端到端自动驾驶重新焕发了活力。2016年,NVIDIA提出了一种基于卷积神经网络的端到端驾驶方法,从车载摄像头输入直接预测转向角,并在高速公路等简单场景中展现出惊人的效果。这一工作引发了业界的广泛讨论:难道未来真的可以用一个“大网络”取代复杂的自动驾驶系统?
自此之后,端到端自动驾驶逐渐形成了一个活跃的研究分支。世界各地的实验室和企业都在尝试不同的变体:有的引入中间“辅助任务”,让网络在预测控制信号的同时也学习路况特征;有的探索如何融合多模态传感器数据(比如图像与激光雷达);还有的研究如何在仿真环境中生成大规模驾驶数据,以弥补真实采集数据的缺失。比如,上海人工智能实验室提出的UniAD方法,就试图在统一框架下把感知、预测和决策组合为一个神经网络,并在公开数据集上取得了非常优异的性能。
当然,端到端方法也面临诸多质疑:模型的可解释性如何保障?面对稀有或危险场景时,是否足够可靠?在安全要求极高的自动驾驶领域,端到端模型的“黑箱性”会不会成为落地的最大障碍?这些问题至今仍在争论之中。
虽然仍有争议,但不可否认的是,端到端自动驾驶已经成为推动整个行业思考和探索的重要力量。它代表着另一条可能的而且充满潜力的道路:通过海量数据和大模型,直接学习驾驶行为,而不是依赖于繁复的人为设计与规则。随着计算资源的增长和数据采集手段的丰富,端到端方案正在逐渐成为自动驾驶系统的主流。
1980s–1990s:早期探索阶段
在今天看来,端到端自动驾驶似乎是深度学习时代的产物,但其实它的思想最早可以追溯到三十多年前。那时,还没有 GPU,也没有大数据,神经网络刚刚在实验室中崭露头角。尽管硬件能力有限,一些有前瞻性的研究者已经在尝试让机器“看图行车”,也就是用视觉输入直接驱动车辆控制。
1980s:ALVINN 的诞生
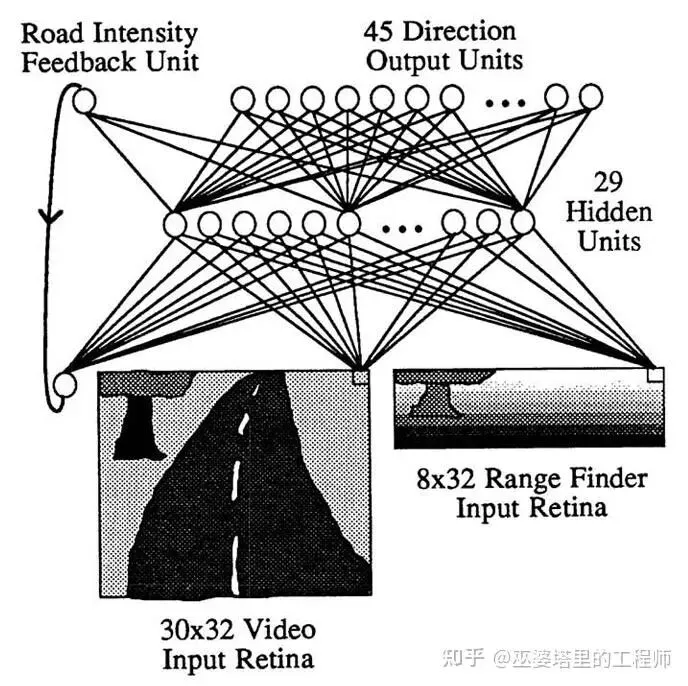
1989 年,卡内基梅隆大学(CMU)的Dean Pomerleau等人提出了一个划时代的系统——ALVINN(Autonomous Land Vehicle In a Neural Network)。这可以说是第一个真正意义上的端到端自动驾驶系统:
输入:车载摄像头采集的道路图像(灰度 30×32 像素);
输出:车辆的转向角;
模型:一个仅有三层的前馈神经网络(输入层—隐藏层—输出层);
训练方式:模仿学习(imitation learning)——让网络学习人类驾驶员的行为。
ALVINN的工作原理非常直观:输入一帧道路图像,神经网络输出一个连续的方向盘角度。Pomerleau用CMU的 NavLab平台在真实道路上进行了实验,车辆在约70km的封闭测试路段中完成了数十分钟的稳定行驶。这一成果在当时引起轰动,被认为是“让机器学会驾驶”的第一次成功尝试。
尽管模型极其简单,但它首次验证了一个关键命题: 不必显式识别车道线、障碍物等语义元素,神经网络能直接从原始图像中学习出对应的驾驶行为。这种“感知直接到控制”的思想,正是后来端到端自动驾驶研究的理论起点。
ALVINN网络结构
1990s:NavLab与PROMETHEUS项目
在ALVINN之后,CMU的NavLab(Navigation Laboratory)项目继续沿着端到端控制的方向推进,尝试将神经网络与传统控制方法结合。NavLab 的多代试验车(NavLab 1~5)在1990年代陆续问世,其中一些版本能在高速公路上以60 km/h的速度自动保持车道。虽然仍依赖于简单的视觉特征提取,但在当时代表了极高的自动化水平。
与此同时,欧洲也在进行类似的尝试。其中最具代表性的PROMETHEUS项目(Program for a European Traffic of Highest Efficiency and Unprecedented Safety)。这是当时全球规模最大的智能交通与自动驾驶研究计划,历时8 年(1987–1995),总预算高达7.5 亿欧元,由欧洲19家汽车厂商、多所大学和研究机构共同参与。该项目的宏伟目标是:提升道路交通效率与安全性,让未来的汽车具备感知、理解与自主决策的能力。这在 1980年代末可谓是极具远见的构想——那时还没有“人工智能”的热潮,也没有深度学习。
在PROMETHEUS项目的资助下,德国慕尼黑联邦国防军大学与奔驰研发中心合作开发了两台自动驾驶试验车:VaMP和VITA-2。这两台车都配备了当时最先进的视觉系统:双目摄像头用于检测车道线与前车;视觉算法进行边缘提取、霍夫变换检测车道线;基于规则的控制器(rule-based controller)用于车道保持与变道;车辆配备 CAN 总线和电子控制系统,可执行自动转向与加减速。
在1995年的一次著名演示中,VaMP和VITA-2在慕尼黑–哥本哈根高速上完成了超过1000公里的自动驾驶行程——包括自动变道与超车。虽然驾驶员仍需在复杂路段介入,但约95%的行程由系统自动完成。这些系统从概念上说更接近模块化方案,但它们证明了“从视觉输入到控制输出”可以在实际道路中闭环运行,为后来端到端系统的出现创造了重要前提条件,因此也是非常值得了解的。
2010s:深度学习推动复兴
进入21世纪初,自动驾驶领域的主流方向从”端到端”完全转向了”模块化”。原因很简单——上世纪末的神经网络太“弱”了:计算能力不足、数据稀缺、网络训练不稳定。在这种条件下,“从图像到控制”的端到端系统几乎无法落地。
与此同时,模块化系统却发展得如火如荼。在DARPA的无人车竞赛中,所有获胜团队几乎都采用了分层式系统架构:
感知(Perception):使用激光雷达、毫米波雷达、摄像头检测障碍物;
定位(Localization):基于 GPS + IMU + 高精地图;
规划(Planning):采用A*、D*、RRT等路径规划算法;
控制(Control):采用PID或MPC实现轨迹跟踪。
这种架构逻辑清晰、可调可控,也容易通过工程团队分工协作。因此,在21世纪的前15年,大部分算法工程师(笔者也是其中一员)都致力于优化各个模块并将它们更好的组合到一起。至于端到端,在当时那只是一个不切实际的梦想。
2012年,AlexNet在ImageNet比赛中以压倒性优势击败传统方法,标志着深度卷积神经网络(CNN)的全面崛起。图像识别的成功让研究者重新思考:既然CNN能从图像中提取复杂语义,那是否也能学会驾驶行为?
图像分类:AlexNet(https://zhuanlan.zhihu.com/p/20328799359)
2016 – NVIDIA PilotNet
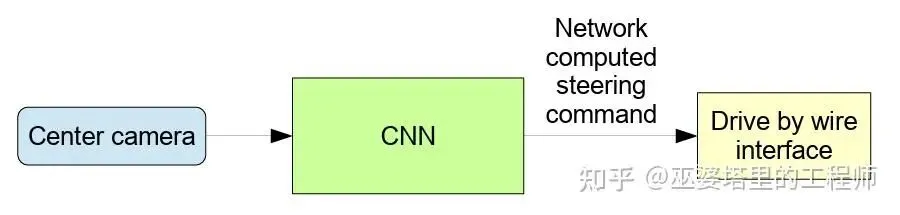
端到端自动驾驶重新回到自动驾驶的舞台,源自NVIDIA 2016年发表的论文《End to End Learning for Self-Driving Cars》,文中提出的CNN神经网络后来也被称为PilotNet。
PilotNet的结构和训练方法(模仿学习)和ALVINN非常类似,只是网络规模更大更深。它没有显式地识别车道线或车辆,但它通过网络内部特征自动学习到与“车道几何”和“道路边缘”相关的表示,并最终输出方向盘转角的值。
PilotNet的工作流程
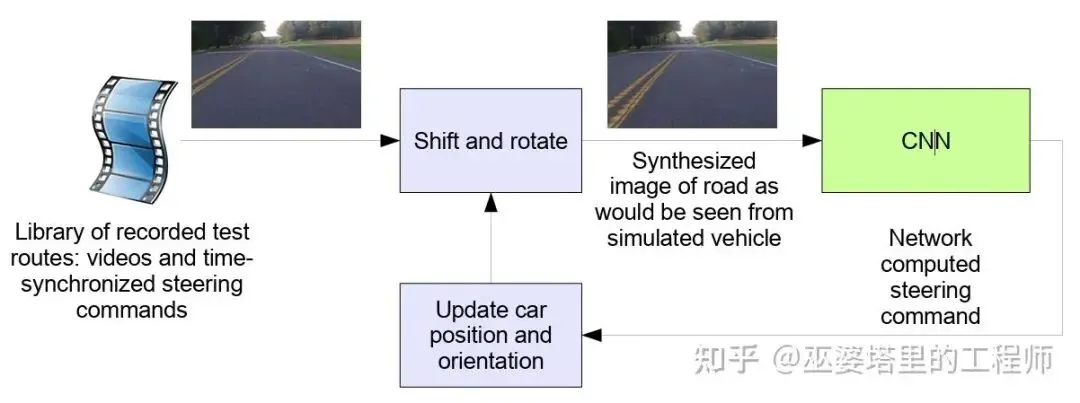
值得注意的是,这篇论文不仅提出了端到端的卷积网络,还首次设计了一个闭环仿真测试系统。该系统通过左右摄像头采集图像,可以模拟车辆在不同转角时看到的场景。神经网络基于当前输入图像给出转角后,仿真系统可以模拟车辆转动后看到的图像,神经网络基于该图像再继续给出转角,以此往复循环。这样,就可以在不使用真实车辆的情况下评估模型能否长期使车辆不偏离车道。这套机制后来成为几乎所有端到端驾驶研究的评测模板,可以说PilotNet不仅重新点燃了端到端的概念,也为它建立了验证方法论。
PilotNet的闭环仿真系统
2018 – Conditional Imitation Learning (CIL)
PilotNet的成功只是起点。学术界很快意识到,直接预测转向角虽然简单,但无法处理复杂驾驶意图(如左转、右转、停车)。此外,若训练数据只覆盖部分场景,模型容易在未见过的情况中“发疯”(即 covariate shift 问题)。于是,一系列改进方法出现,最具代表性的是《End-to-end Driving via Conditional Imitation Learning》中提出的条件模仿学习。
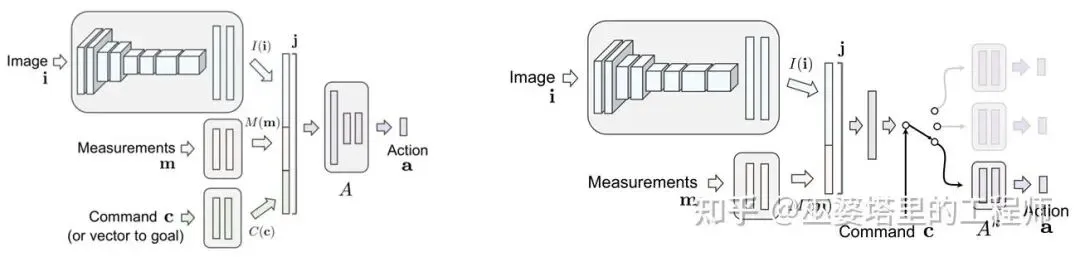
传统端到端方法学习的是”在当前图像下怎么开“,但驾驶行为还取决于”你打算去哪里“。这就像一个司机到路口时,必须知道“左转”还是“直行”,否则单凭前方图像是无法做出正确决策的。因此,CIL的核心思想就是:让端到端网络在输入图像的同时,再输入一个高层指令(command),使模型在学习驾驶行为时能够根据任务意图调整输出。
CIL的训练依然基于模仿学习:网络观察人类驾驶员的行为,学习“在什么视觉场景下该怎么做”。不同之处在于,CIL的输入不仅包括图像,还包括命令条件(command),比如"Follow lane","Turn left","Turn right","Go straight"。所以,模型实际上在学习四种条件下的驾驶策略。
CIL的两种网络架构
CIL 的出现不仅让端到端模型“听得懂指令”,还在一定程度上缓解了长期困扰端到端学习的covariate shift问题。通过引入命令条件与任务分支,CIL将原本混乱的驾驶数据划分为多个子分布,使模型在每个任务上学习得更稳定,也更容易泛化。不过,它并没有从根本上解决由于模型误差导致的输入偏移问题。
2018~2020 – 从模仿学习到强化学习
从模仿学习到条件模仿学习,端到端自动驾驶系统中仍然存在一个关键问题没有解决:模型仍然是离线训练,无法在仿真或真实环境中自主改进。因此,一旦遇到训练分布之外的情况(covariate shift),系统很可能会跑偏。
为了解决这些问题,研究者开始思考:能否让自动驾驶系统在仿真环境中通过“试错”不断改进?能否让它不仅模仿人类,还能自己积累经验、优化策略?这也就引发了下一阶段的探索,也就是把强化学习纳入到端到端框架中。
模仿+强化
2019年,Intel实验室提出了CILRS (CIL with Reinforcement and Speed Input),它被认为是CIL的“闭环进化版”。与CIL相比,CILRS主要有以下3点改进:
输入:除了图像 + 命令,还加入了车辆当前速度(speed input),目的是让模型感知动态信息,区别转弯/加速/减速场景。
学习方式:结合监督模仿学习 + 基于奖励的强化调整,实现部分的在线优化,从而减少covariate shift。
仿真平台:CARLA 1.0(支持高保真闭环),提供安全的试错环境。
CILRS仍然使用CIL的条件分支结构,但在每次训练迭代后,它会在仿真环境中“跑一圈”,观察模型的行为表现,再根据奖励信号进行参数微调。奖励函数包含三部分:保持车道(正奖励),碰撞或越界(负奖励),平滑驾驶(速度与加速度惩罚)。这样模型在模仿的基础上学会自我调整,逐步形成闭环学习。
在CARLA的通用化测试(新城市、新天气)中,CILRS相较于 CIL:成功率提高35%,碰撞率降低约40 %,在未见过路口下仍能遵循指令完成驾驶。CILRS首次让端到端驾驶模型在仿真中具备“自我修正”能力,这是从纯模仿学习到闭环自适应学习的重要转折点。
纯强化学习
虽然采用了闭环学习进行微调,CILRS仍然需要模仿学习来进行生成一个基础模型。更进一步,强化学习 (Reinforcement Learning, RL)完全摒弃了模仿步骤,让系统直接依靠奖励信号自己探索驾驶策略。这种方式在理论上能让系统真正“理解”驾驶目标,而不是被动模仿。以下是该方向的两个代表性工作。
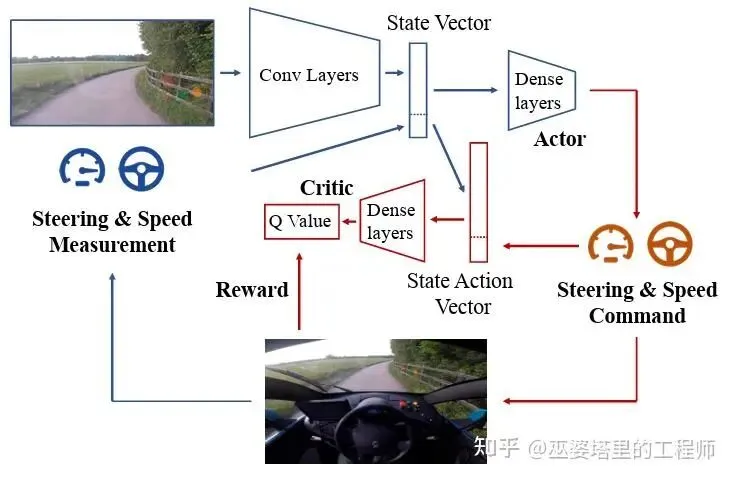
这个工作来自于Wayve公司,首次展示了在真实车辆上,仅使用单目摄像头作为输入,通过端到端的深度强化学习,从零开始成功学会了车道保持任务。在不依赖任何人类驾驶数据或预训练模型的情况下,只需要大约20分钟的交互式训练后,车辆就能在宁静的乡村道路上实现稳定的车道保持。这是强化学习在自动驾驶应用中的一个里程碑。
在强化训练的每一步,只要驾驶员没有进行干预(接管),神经网络就会获得一个小的正奖励。一旦驾驶员介入,奖励会重置为0,并且当前回合结束。这个奖励函数极其简洁,它不要求人工定义“什么是好的车道居中”(如计算到车道线的距离),而是将“好”的行为定义为“不需要人类接管”。这有效地将“什么是安全驾驶”的判断交给了人类专家,让神经网络自己去探索和发现能够最大化无接管时间的驾驶策略。
论文使用Deep Deterministic Policy Gradient(DDPG)算法,这是一种适用于连续动作空间(如转向角度)的强化学习算法。
强化学习的训练流程
在真实环境中采用强化学习训练存在安全性、成本、效率等各种问题,而仿真环境则提供了一个绝对安全、成本低廉且具有无限数据的解决方案。目前常用的仿真器包括NVIDIA DRIVE Sim, CARLA, LGSVL等,它们使用游戏引擎渲染,并集成高精度物理模型。
但是,无论多逼真,仿真器都很难100%的模拟真实环境,这就导致学习到的模型在真实场景中有些“水土不服”。因此,目前更主流的方案是先在仿真环境中进行预训练,然后在真实环境中再进行微调,比如Wayve的在线强化学习方法或者模仿学习。
CARLA生成的虚拟场景
2020s:规模化与多样化探索
进入2020年代,端到端自动驾驶从简单的“能跑通、能听懂指令”逐步迈向“能规模化训练、能多模态协同、能闭环评测”。这一阶段的主旋律可以概括为三点:统一多模态表示、大数据驱动、闭环训练和测试。
统一多模态表示,就是让不同传感器在统一坐标中“对话”。目前最常用也是最自然的方法就是BEV(鸟瞰图)表示:它把相机、激光雷达、毫米波雷达等传感器的信息统一映射到BEV空间,在此空间内进行多模态融合、长时序融合、并最终输出规划控制的结果。因此,目前的端到端模型大多采用BEV Transformer的神经网络架构。
至于规划控制的输出,目前主要有两种思路,也对应了端到端系统的两条发展路线。
端到端模型输出驾驶意图(比如加速10kph,左转10°等),或者未来几秒内的轨迹点,然后再由底层控制器给出具体的车辆控制信号并执行。 这种方式在工程上更稳健,易与现有控制器对接,也便于加入约束(速度、舒适度、安全边界)。
端到端系统最初采用的就是这种方式,也就是从传感器输入直接推理车辆控制信号,比如油门、刹车和转向。这种方式的优点是链路短、直接优化最终目标,难点是可解释与稳定性。目前业界流行的VLA(Vision-Language-Action)模型,也是采取的这种方式。如果去除语言模型的部分,只包含视觉输入(比如PilotNet),那其实就是Vision-Action(VA)。
代表性方法
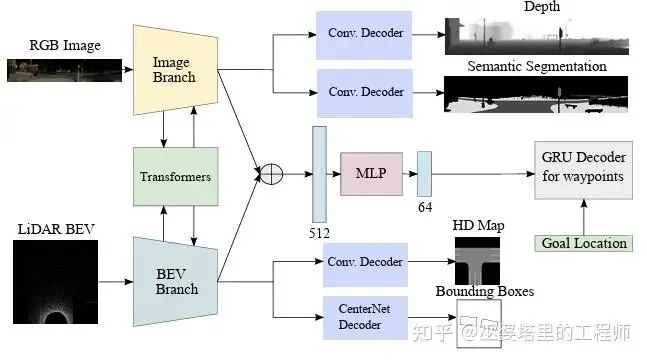
TransFuser(2021)
该方法融合了图像和激光雷达输入,并以此预测未来的位置轨迹(waypoint)。多模态融合的方式非常简单,但是与传统感知任务的中的特征融合方法有很大差别。比如,在目标检测中,图像特征和点云特征一般会统一到BEV特征空间,对齐空间位置后再进行融合。而TransFuser通过average pooling直接把图像和点云特征压缩为长度相同的两个特征向量,然后直接把两个向量相加,跳过了特征对齐的步骤。
融合后的特征通过GRU进行一个Auto Regressive的推理,预测未来几个时间点自车的位置。如前所述,这些位置点通过一个底层控制器,得到车辆的最终控制信号。
除了直接根据位置点的真值(通过Carla数据库中的一个expert程序给出)计算网络损失,该方法还采用了多个附加任务,分别是基于图像数据的深度估计和语义分割,基于激光的目标检测和局部地图。这些任务的输出虽然不会被直接使用,但是可以用来辅助端到端神经网络的训练。这也是一个常用的训练技巧。
TransFuser的网络结构
TransFuser在Carla数据库中进行训练和闭环评测,其性能显著优于前面介绍的CILRS,当时也是Carla数据库上表现最好的方法之一。
World on Rails(2021)
传统端到端自动驾驶网络通常只能输出一条确定性轨迹或单个转向角,这种方式无法刻画驾驶中存在的多样化可行决策(例如:在交叉路口左转或右转都合法)。该论文提出,自动驾驶系统应学习一个轨迹分布,从而在保持安全与合理的前提下,保留人类驾驶的多样性与不确定性。
模型在学习过程中并不只是死板的认为只有一条最优路径,而是学到多种合理的可能性,再用规则或风险评估从中选出当前最安全的一条。这种流程也更符合现实世界的规律。
系统输出多条轨迹并选择最优的一条
在具体实现的过程中,世界被抽象成若干“rails”(轨迹轨道),每条轨迹代表一种合理驾驶行为(直行、变道、绕行)。网络不再输出单条轨迹,而是输出一组可能轨迹的概率分布。概率建模是通过Conditional Variational Autoencoder (CVAE)来完成的。模型训练时,要同时考虑重建真值专家轨迹(重建损失),同时也保持采样的多样性(用KL散度来衡量)。
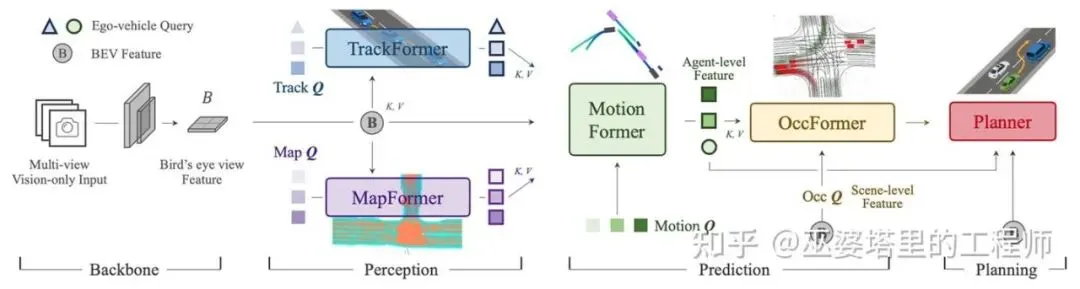
UniAD(2023)
UniAD(Unified Autonomous Driving) 是近几年端到端自动驾驶研究中里程碑级的工作之一,被普遍认为是 “统一学习范式” 的代表。它首次在同一个模型中同时学习感知(Perception)、预测(Prediction)、规划(Planning) 三个核心子任务,并通过时空Transformer实现端到端联合优化。
如果说2016年的PilotNet让汽车学会了“看”,2018年的CIL让它学会“听懂指令”,那么2023年的UniAD则让它学会了“思考全局”。
UniAD与其他方法的对比
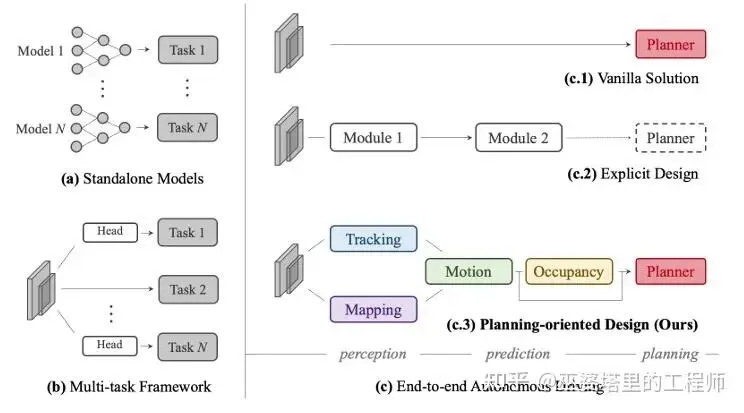
从分类上来说,UniAD是“分段式”端到端,而我们前面介绍的方法大都属于“一段式”端到端。一段式的系统直接由传感器输入推理规划控制信号,而分段式系统更接近于传统的模块化设计,只不过所有模块可以串联起来进行端到端训练。这种方式相比与一段式的“黑盒子”,保留了任务的可解释性,也兼顾了工程上的可控性。
与之前很多分段式的方法相比,UniAD集成了更多的子模块,包括目标检测和跟踪、局部地图构建、占据栅格、目标轨迹预测,并最终得到规划的输出。UniAD的各个子模块之间通过统一的Transformer结构进行交互。每个子模块有自己的query,key和value则来自上游模块。
UniAD的网络结构
UniAD将多个模块联合起来统一训练,这些模块间并没有互相干扰,反而相互促进。各个子模块的性能都超过了单独训练的基准方法。但是,它的缺点在于计算开销比较大,多任务联合监督需要完整标注(检测、轨迹、规划)。
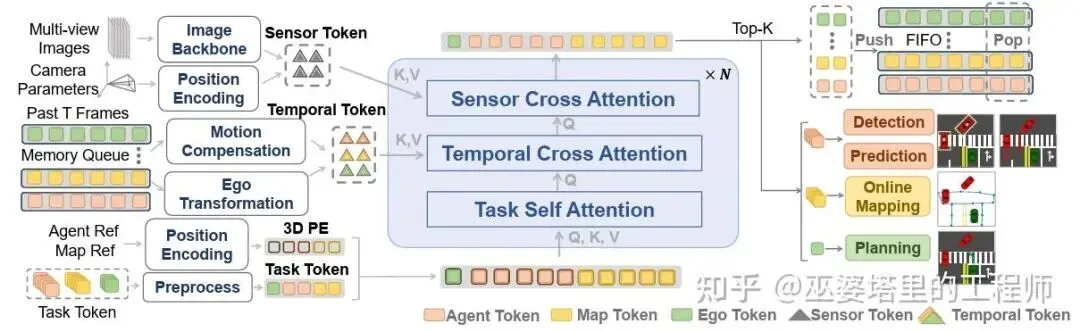
DriveTransformer(2025)
DriveTransformer是继UniAD之后又一篇极具代表性的统一端到端自动驾驶方法,被普遍认为是 “从统一任务到统一时空交互” 的重要跨越。如果说UniAD把感知、预测、规划整合进一个统一框架,那DriveTransformer则进一步强化了这一框架的时空一致性与多智能体交互理解能力。
尽管UniAD已经实现了感知-预测-规划一体化,但是它需要进行分段式训练:首先预训练一个BEVFormer的encoder,然后训练TrackFormer和MapFormer,最后训练MotionFormer和Planner。这种碎片化的训练增加了复杂度,也不利于工业级应用部署。这种人为定义的顺序也限制了模块之间的协作能力。
此外,稠密的BEV特征提取计算量非常大,尤其是需要远距离感知的场景。时序融合通常需要存储历史的BEV特征,也会带来额外的计算量,同时也把时序和空间处理割裂开来。
为了解决以上问题,DriveTransformer重新回到“一段式”的框架,但是附加了多种任务作为辅助。这些任务被统一到Transformer的框架下,通过并行交互处理,挖掘其中的关联。其中关键的设计包括:
所有的处理都由Token来完成,避免“昂贵”的稠密特征提取。
任务之间通过Task-Self-Attention进行交互,这里同时还包括了自车和地图的信息(也用Token表示)。
时序融合模块保留之前多帧的Query,作为Memory来和当前帧进行交互。
多传感器数据通过空间位置编码实现融合,与时序模块组合后形成一个时空统一的特征。
时空特征最终被解码为多个任务的输出,其中Planning是主任务,其他都是辅助任务。
DriveTransformer的网络架构
DriveTransformer在开环(nuScenes)和闭环(Bench2Drive)测试中都达到了SOTA的效果,运行速度上也具有明显的优势。
未来趋势
回望近四十年的发展历程,端到端自动驾驶从1980s的神经网络试验车出发,穿越了规则控制、模块化架构、模仿学习、强化学习与多模态统一学习的长河。它几经沉浮,从最初“让汽车学会开车”到如今“让系统理解世界”。在2020s,我们看到端到端范式终于走出了实验室,成为产业界认真讨论的工程方案。
可解释与可验证:从“黑盒”到“灰盒”
早期端到端网络被诟病最多的一点,是它的“黑箱性”。工程师无法清楚解释模型为何打方向、为何加速、为何在某个交叉口犹豫。这让它在功能安全(ISO 26262)和预期功能安全(SOTIF)体系下难以通过认证。
未来的发展方向之一,就是让端到端模型具备“灰盒可解释性”,比如增加模块化设计、增加附加任务,甚至引入大语言模型等等。端到端不再意味着完全黑箱,而是成为一种“可度量、可解释、可验证”的智能体系统。
世界模型与虚拟驾驶:让模型“学会想象”
未来五年最具潜力的方向,是端到端系统与世界模型 (World Model) 的结合。当前的 DriveTransformer、UniAD仍属于“感知 + 规划”框架:它们能理解当下世界,却难以在脑中“想象未来”。
而世界模型的目标,是让系统能够在内部重建可预测的动态环境,比如“如果我现在加速,会不会与前车相撞?”、“如果对方车辆变道,我该如何应对?”通过在预测空间中进行未来推演,系统不再依赖外部仿真器,就能在自身神经表示中进行规划与评估。
最终形态:从驾驶模型到认知体
当端到端系统具备统一感知、预测、规划、世界想象、自我评估与安全闭环时,它的本质已经超越了“开车”这一具体任务。它将成为一个具有世界常识的认知体(Cognitive Agent),能够在真实环境中感知、预测、推理、决策、学习。届时,“自动驾驶”只是它的一个应用,而“具身智能”才是它真正的形态。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
