作者:静观波澜
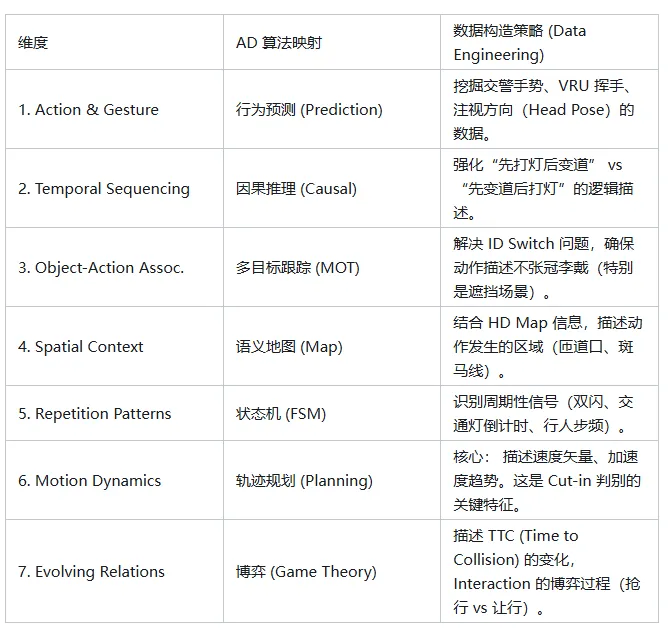
地址:https://zhuanlan.zhihu.com/p/1998914877360713932
经授权发布,如需转载请联系原作者
核心议题:在端到端(E2E)自动驾驶和 VLM 上车过程中,如何解决模型“高分低能”(识别准但博弈差)的问题?本文探讨一种基于结构化视觉提示(Structured Visual Prompting)的全自动数据工厂模式,并论证其如何通过符号化注入(Symbolic Injection)赋予模型细粒度的时空推理能力。
问题的本质:
为什么纯视觉模型读不懂“Cut-in”?
目前的 Vision-Language Models (VLMs) 或 E2E 模型在静态感知(Detection)上已趋于成熟,但在动态交互(Interaction)上存在显著缺陷。
例如,面对一个正在执行 Cut-in 的车辆,模型往往要等到车辆明显压线(物理距离侵入)才做出反应。根本原因在于模型缺乏对运动语义(Motion Semantics)的深层理解:
隐式特征的局限:模型仅仅通过卷积或 Transformer 关注像素变化(Optical Flow),但这是一种“隐式”的感知,缺乏物理约束。
What vs. How 的鸿沟:模型知道“那是车(What)”,但不知道“它是如何以此速度和角度切入我的未来轨迹的(How & Future)”。
FoundationMotion 的核心贡献在于提出了一套 Pipeline,通过显式的结构化数据强行“对齐”视觉特征与物理逻辑。
该 Pipeline 的核心逻辑不是简单的“自动标注”,而是一种多模态的思维链(Chain-of-Thought)构建。它通过两路信号强制模型进行推理:
1. 视觉流:Visual Anchoring (视觉锚点)
通过 Color-coded Bounding Boxes叠加,解决了 Attention Drift(注意力漂移)问题。
2. 数据流:Symbolic Grounding (符号接地)
这是您笔记中提到的重点。系统将轨迹数据(Trajectory)序列化为 JSON 文本注入 Prompt。
数据结构:{ID: 1, T0: [x0, y0], T1: [x1, y1], ...}
深度解读:这一步实际上是将“视频理解”降维成了“数学推理”。模型不再需要从像素中“猜”速度,而是直接通过 Token 及其数值差异($\Delta x, \Delta t$)计算出动力学特征。
深度辩证:
白盒数据 (White-box) vs. 视频管线
您在笔记中提出了一个极具深度的疑问:
“白盒信息(如模拟器真值/CAN总线)中有汽车运动的信息,为什么还需要模型从视频中生成?这个白盒可能相邻帧之间进行缺失,但是里面有描述汽车的运动,但是这个如何和视频理解进行关联?”
这是一个关于“监督信号源(Source of Supervision)”的关键问题。
1. 白盒数据的本质缺陷
白盒数据(Sim/Log)拥有完美的物理真值(GT),但它缺失了“视觉因果性”。
2. 视频 Pipeline 的不可替代性
FoundationMotion 这类 Pipeline 的真正价值在于构建映射:
一句话总结:白盒数据是“答案”,视频 Pipeline 生成的 Text/QA 是“解题过程”。我们用 Pipeline 生成数据来教模型学会“解题过程”。
您笔记中列出的七个维度,在自动驾驶算法栈中有着严密的对应关系。我们在数据构造时,必须针对性地强化这些维度:
1. 摄像机运动评分 S_m 的 AD 适配
您提到了公式:
2. 轨迹提取与 VLM 的交互
Teacher Role:利用 235B 强大的长窗口(Long Context),输入长达 10s 的 Video Clip。
Prompt 构造:不要只问 "What happened?"。要注入基于规则的先验。
Prompt 示例:"Here is the trajectory of Object A (Red Box): [Speed: 80km/h, Lateral_Vel: -1.5m/s]. Describe its interaction with the Ego vehicle based on the video visual cues (e.g., turn signals, tire angle)."
3. 下一步行动:构建“运动专家”数据集
数据清洗:使用 S_m变体公式筛选高动态场景,但需先做自车运动补偿。
结构化生成:利用现有的感知结果(白盒/伪标签)生成 JSON 轨迹。
VLM 标注:使用 Qwen3-VL 配合 Prompt,生成包含上述“七大维度”的细粒度 Caption。
模型微调:将生成的 <Video, Question, Answer>用于微调较小的端侧 VLM(如 Qwen2-VL-7B),让小模型习得大模型的“物理直觉”。
FoundationMotion 的本质不是创造新数据,而是显式化(Explicate)隐含在视频中的物理规律。对于自动驾驶,这正是打通“感知”与“规控”的最后,为了让模型真正理解“Cut-in”不仅仅是一个分类标签,而是一个涉及速度、空间博弈和时间序列的复杂物理过程。
注意这个为gemini根据我的笔记生成的。
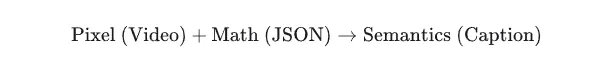
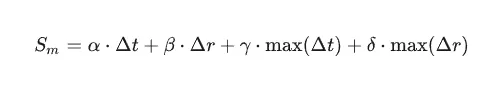

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
