[T-ASE] 时空有向图赋能自动驾驶:实现混行交通下智能协商决策
- 2026-02-23 13:39:18

早晚高峰的路口,人类司机一个眼神、一次轻踩油门的试探,就能完成和邻车的并线协商;环岛里的车流通行,靠的也是彼此间无形的互动默契。但对于自动驾驶车辆来说,这种充满动态性、不对称性的人车交互,却是一道难以逾越的坎——传统算法要么靠死板规则应对,要么无法精准捕捉车辆间的互动关系,轻则通行效率低下,重则引发交通冲突。
在自动驾驶与人类驾驶混行的交通环境中,如何让自动驾驶车辆拥有和人类司机一样的“谈判能力”,做出自适应、合情理的决策?天津大学联合英国格拉斯哥大学的研究团队给出了答案。他们提出了图增强的协商感知策略优化(GNPO)框架,首次将交互感知融入自动驾驶决策的表征、理解、响应全环节,并设计了时空有向图(STDG) 精准刻画车辆间的动态不对称交互,让智能车真正学会了在复杂路况中与人类车辆“和谐相处”。为自动驾驶协商策略的研发提供了全新思路。
一、研究引言:自动驾驶交互决策的两大核心痛点
人车混行是当前自动驾驶落地的核心场景,想要让用户接受智能车,其行驶行为必须符合人类司机的社交预期,也就是“社交合规性”。强化学习(RL)因能通过与环境交互自适应不同交通场景,成为自动驾驶决策的主流方法,但在交互关键场景中仍存在显著短板,核心痛点主要有两点:
车辆交互状态表征难:传统方法无法有效构建和编码车辆间的交互状态,尤其难以捕捉人车混行中社交交互的时间变异性和不对称性,无法为协商策略学习提供有意义的车辆关系特征; 高交互环境下策略优化不稳定:稀疏的反馈信号、周围车辆的非平稳行为、多样的交互意图,导致强化学习在高交互场景中学习不稳定,难以在社交不确定性下平衡探索与利用。
为解决上述问题,研究团队提出GNPO框架,核心是通过时空有向图(STDG)实现车辆交互的精准表征,并设计交互关键的奖励函数和熵正则化的自适应策略优化方案,让自动驾驶车辆具备端到端的交互协商能力。
二、创新方法详解:GNPO框架全拆解,从交互表征到策略优化
GNPO框架整体分为特征提取层和策略层两大核心部分,前者通过时空有向图和多模态融合实现交互状态的全面理解,后者通过定制化的奖励函数和自适应优化实现协商策略的高效学习,整体架构见图1。
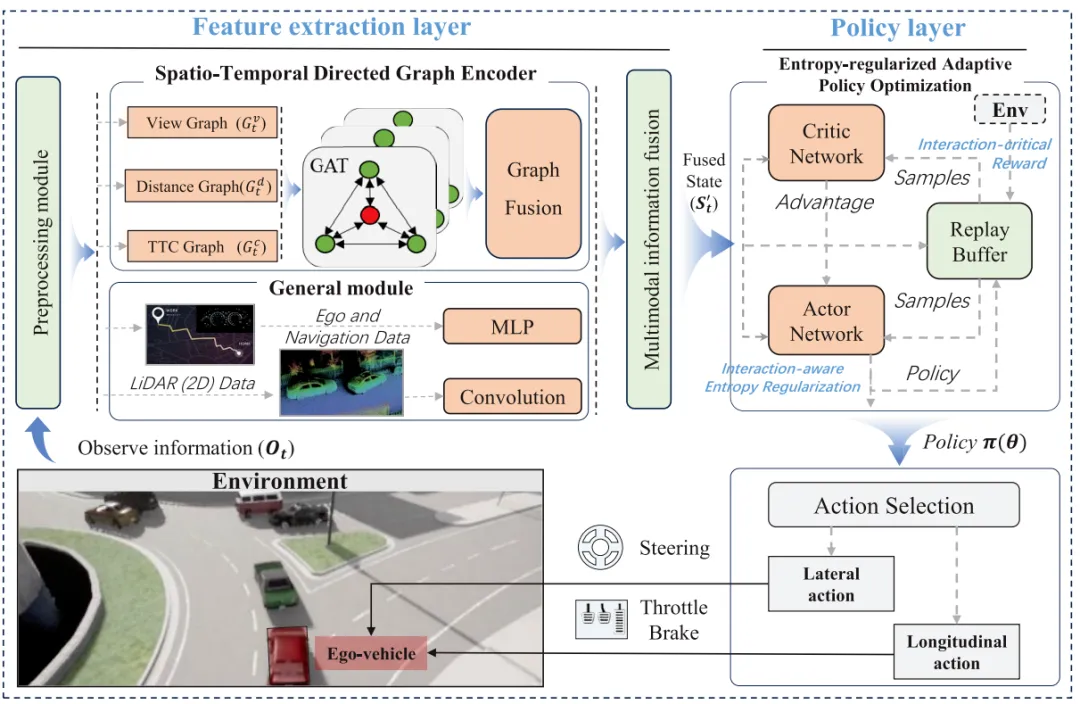
图1:利用时空有向图的图增强型谈判感知策略优化框架概述。
(一)基础问题建模:定义动作、观测与图表示
研究首先明确了自动驾驶决策的动作空间、观测空间和图表示基础,为后续建模奠定框架:
动作空间:智能车的动作由归一化的纵向/横向输入(范围[-1,1])映射为实际的转向、加速、制动信号,公式如下:
其中、、分别为最大转向角、最大加速力、最大制动力。 2. 观测空间:包含智能车自身状态、导航信息、周围车辆状态、240维2D激光雷达点云四大类,覆盖驾驶决策所需的全维度信息;
3. 图表示基础:用有向图描述t时刻车辆间关系,为节点特征矩阵(代表车辆),为邻接矩阵(代表车辆间加权交互关系,权重0-1,值越大交互越强),并通过公式实现从环境状态到驾驶动作的映射。
(二)核心创新1:时空有向图(STDG)——精准刻画车辆动态不对称交互
这是研究的核心突破点,团队设计了视角图(VG)、距离图(DG)、碰撞时间图(CG) 三个有向子图,从不同维度编码车辆交互的先验知识,共同构成时空有向图,直观展示见图2。三个子图各司其职,且均为有向结构,完美契合车辆交互的不对称性(如A车能看到B车,B车未必关注A车)。
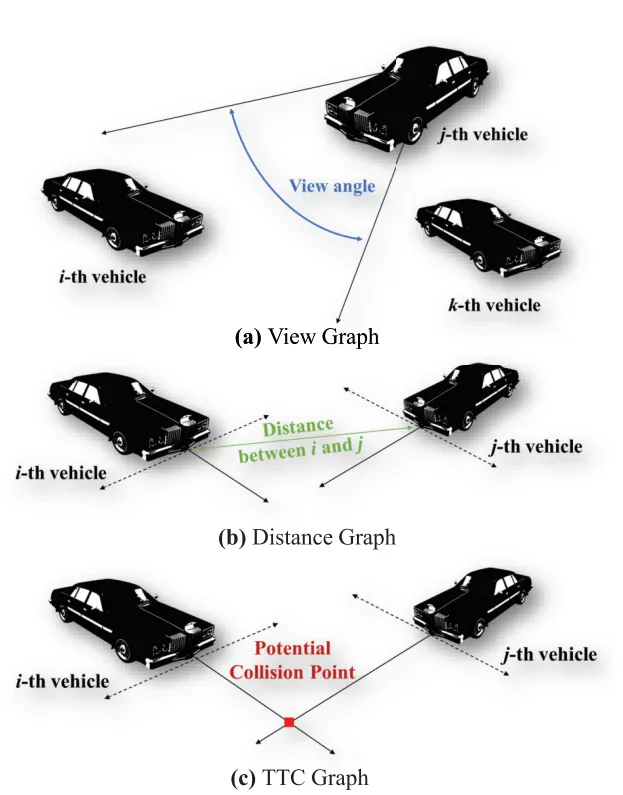
图 2. 三种图形模型的示意图:视图图、距离图和 TTC 图。
视角图(VG):基于车辆视角角构建,捕捉“视线范围内的交互影响”。若j车在i车的视角范围内,便建立从j到i的有向边,边权重通过视角角计算:
其中,为i车运动方向,为i到j的方向向量。智能车的视角角设为,实现全向感知。
2. 距离图(DG):基于车辆间物理距离构建,捕捉“距离带来的交互强度差异”,边权重为两车间的欧式距离:
碰撞时间图(CG):基于车辆运动方向的潜在碰撞点构建,捕捉“冲突风险带来的交互”。若两车间存在潜在碰撞点,边权重为两车到碰撞点的碰撞时间差,否则为0:
为融合三个子图的特征,团队采用图注意力网络(GAT) 分别提取各子图的交互特征,再通过多层感知机(MLP)融合为统一特征,公式如下:
其中GAT的核心计算通过注意力系数实现节点特征聚合,保证对重要交互关系的重点关注。
(三)核心创新2:多模态特征提取网络——融合全维度驾驶信息
在时空有向图特征的基础上,团队设计了多模态特征提取网络(架构见图3),融合智能车与导航数据、图结构车辆数据、2D激光雷达数据三大类信息,形成全面的状态表征:
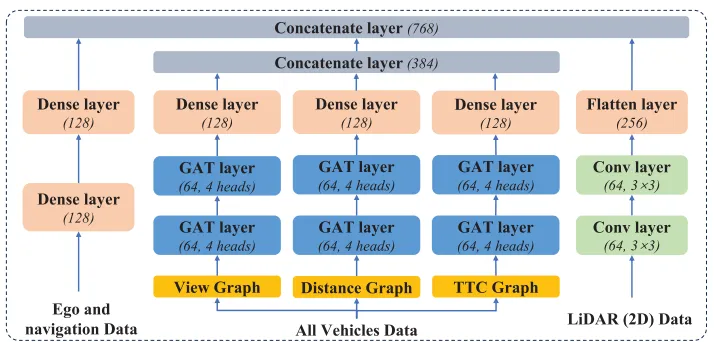
图 3. 多模态特征提取网络架构。
智能车与导航数据:经两层全连接层提取特征,得到; 图结构车辆数据:即上述STDG融合后的特征; 2D激光雷达数据:经两层卷积层提取空间特征,再通过Flatten层转为一维向量。
最终通过拼接操作得到融合特征:
该网络让智能车既能捕捉车辆间的交互关系,又能感知环境障碍物、自身状态和导航目标,实现对驾驶场景的全局理解。
(四)核心创新3:图增强协商感知策略优化——让智能车学会“友好谈判”
基于多模态融合特征,团队设计了交互关键奖励函数和熵正则化自适应策略优化两大模块,构成GNPO的策略层(见图4),核心是引导智能车做出兼顾自身利益和交通全局的协商决策。
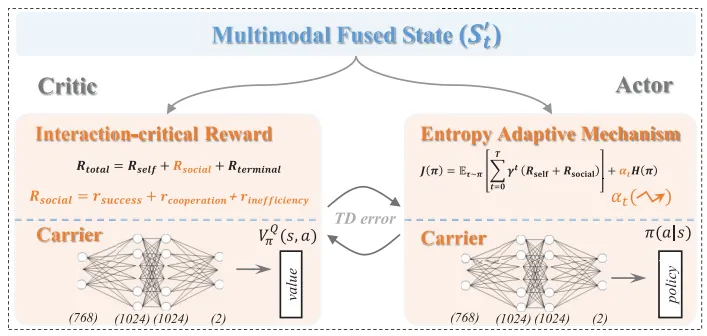
图 4. 基于演员-评论家框架的图增强型谈判感知策略优化方法示意图。
交互关键奖励函数:打破传统强化学习“自利型”奖励设计,引入自奖励和社交奖励,总奖励(为终端奖励,奖励任务完成、惩罚违规),计算逻辑见算法1:
自奖励:由目标奖励、效率奖励、平滑奖励加权组成,引导智能车朝目的地行驶、保持高效且平稳的驾驶; 社交奖励:仅在检测到交互事件时触发,由成功奖励(协商动作完成)、合作奖励(周围车辆的合作行为)、低效惩罚(引发交通效率下降)组成,引导智能车与周围车辆和谐交互。 熵正则化自适应策略优化:解决社交奖励稀疏导致的学习不稳定问题,通过动态熵系数平衡探索与利用,熵系数计算公式:
其中为初始熵权重,为衰减因子,为社交奖励的影响系数——社交奖励越高,熵系数越小,策略从“探索”转向“利用”;反之则增加探索,优化协商策略。
在此基础上,采用演员-评论家(AC)框架进行策略优化,演员网络通过策略梯度生成驾驶策略,评论家网络通过时序差分(TD)学习评估策略价值,实现策略的迭代优化。
三、实验效果验证:仿真+数字孪生双验证,性能全面超越基线方法
为验证GNPO框架的有效性,团队搭建了泛化仿真环境和真实数据数字孪生环境两大实验平台,设计了对比实验、消融实验等多维度验证,并采用成功率(S.R.)、碰撞率(C.R.)、完成任务总时间(T.T.)三大核心指标评估性能。
(一)实验平台与设置
环境分类(见图5):①泛化仿真环境(基于MetaDrive):包含环岛、路口、并线三大高交互场景,设置正常/高密度两种交通流量;②真实数字孪生环境:基于Waymo开放数据集,提取200个复杂城市交通案例,分为训练集(70%)和测试集(30%),并在测试集加入模拟传感器噪声(SSN) 验证鲁棒性。
图 5. 通用化与实际数字孪生环境概述
背景车辆模型:设计5类不同动力学和行为策略的背景车辆(见表I),模拟人类司机的多样化驾驶行为,让实验更贴近真实交通。 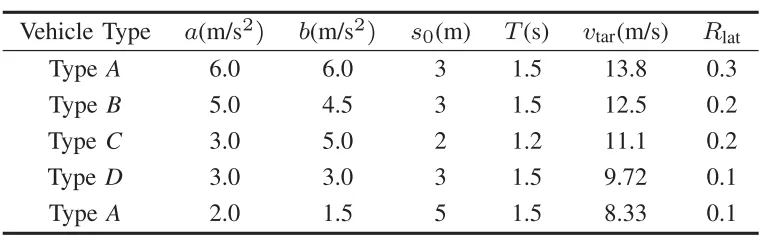
表一 环境车辆模型的描述
对比算法:分为三类,①纯强化学习方法(PPO、SAC、DDPG);②图强化学习方法(Rate GQN、DGAAC);③模仿学习方法(BC、GAIL),所有对比算法均调至最优超参数,保证公平性。
(二)核心实验结果
与纯强化学习方法对比(见图6、表II):GNPO的核心策略模块ERAPO在所有场景中均显著优于PPO、SAC、DDPG。正常密度下,基线方法成功率比ERAPO低4.38%-8.44%;高密度下,成功率差距扩大至8.31%-15.67%,且碰撞率更高、完成时间更长,证明交互关键的奖励设计和自适应优化能有效提升高交互场景的决策性能。
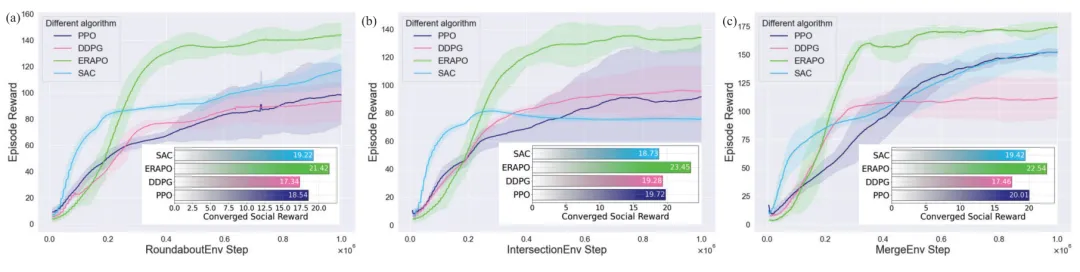
图 6. 在多种场景下,ERAPO 与代表性强化学习方法的训练性能对比。
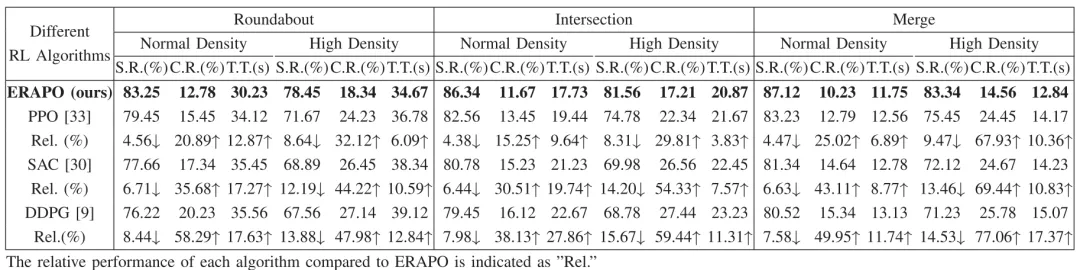
表 II ERAPO 与代表性 RL 方法的性能比较
与图强化学习方法对比(见表III):GNPO在环岛、路口、并线场景的正常/高密度条件下,成功率均为最高(90.22%-96.88%),且碰撞率最低、完成时间最短。而Rate GQN、DGAAC在高密度场景中性能大幅下降,证明STDG能更精准地捕捉车辆交互,相比传统静态/对称图结构,更适配真实交通的动态不对称特性。
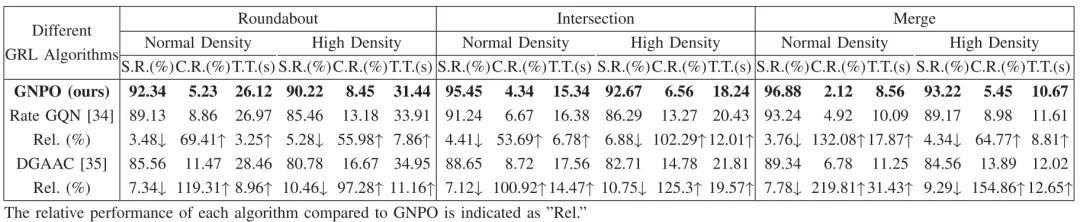
表三 GNPO 与代表性基于图的强化学习方法的性能对比
消融实验(见表IV):移除STDG中的任意一个子图(VG/DG/CG),均会导致性能显著下降。其中移除碰撞时间图(CG)的影响最大,成功率最高下降7.32%,碰撞率最高上升123.11%,证明三个子图各司其职、缺一不可,共同构成了完整的车辆交互表征。
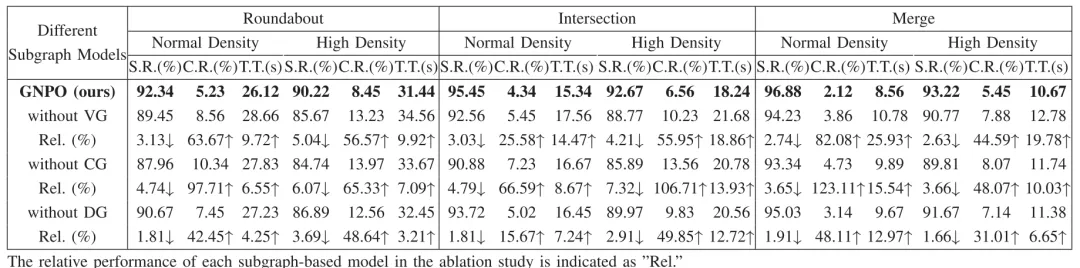
表 IV 在消融研究中子图模型的相对性能
真实数字孪生环境验证(见表V):GNPO在干净测试集(无SSN)和噪声测试集(有SSN)中均保持最优性能,成功率分别为88.26%和87.37%,碰撞率仅6.48%和7.27%,性能下降幅度极小。而模仿学习方法(如GAIL)虽在训练集表现优异,但测试集成功率暴跌超10%,纯强化学习方法则整体性能低下,证明GNPO具有极强的泛化能力和鲁棒性,适配真实的感知噪声环境。
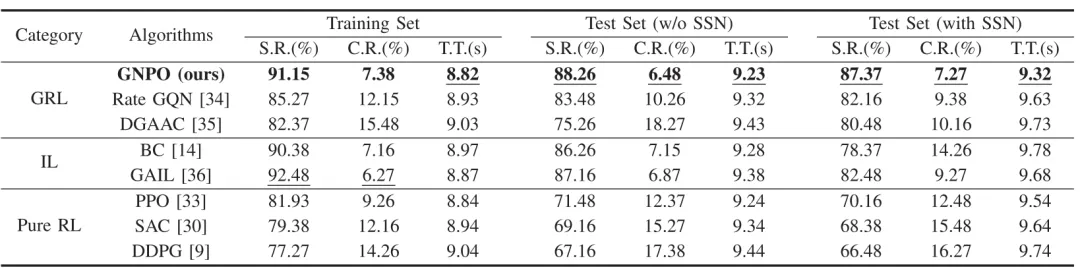
表 V 在清亮测试条件和有噪声测试条件下,GNPO 方法与基准方法的泛化能力及稳健性比较
(三)定性分析:智能车展现人类般的协商行为
动态仿真和数字孪生的可视化结果(见图7、图8)显示,GNPO框架下的智能车能展现出类人的合作与竞争结合的协商行为:在并线、环岛等场景中,必要时会通过轻微加速等“试探性”竞争行为引导周围车辆配合;当不具备通行优势时,会主动礼让,避免交通冲突。在真实数字孪生案例中,智能车还能完成掉头、右转等复杂动作,并在路权博弈中做出合理决策,真正实现了与人类车辆的“和谐谈判”。
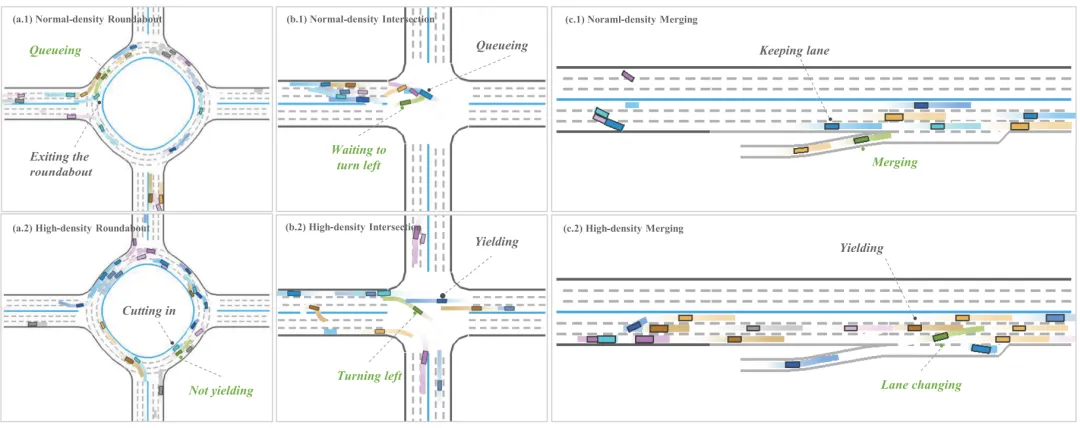
图 7. 对 GNPO 的定性分析涵盖了不同的场景和交通密度情况,并通过可视化方式进行了展示,以供说明之用。
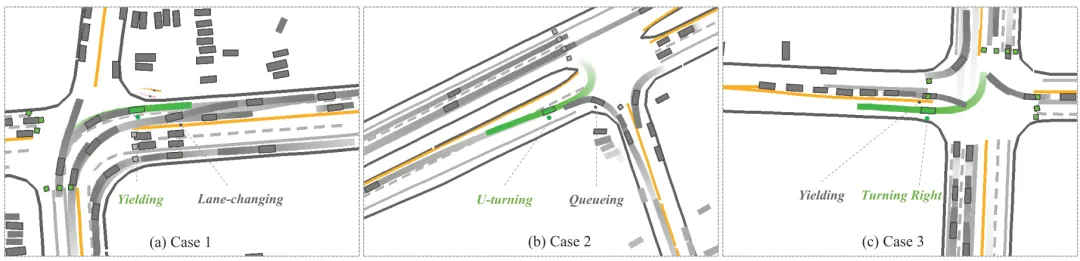
图 8. 展示了代表性的真实世界数字孪生案例,这些案例展现了 GNPO 类似人类的交互行为。
四、总结思考:自动驾驶协商决策的新方向
本研究的核心贡献在于,首次将交互感知全面融入自动驾驶协商策略的表征、理解、响应全环节,通过时空有向图(STDG)解决了车辆动态不对称交互的表征难题,再结合多模态特征融合、交互关键奖励函数和熵正则化自适应优化,构建了端到端的图增强协商感知策略优化(GNPO)框架。
大量实验证明,GNPO在仿真和真实数字孪生环境中,均在成功率、安全性、效率上全面超越传统方法,且能生成类人的驾驶协商行为,为人车混行场景下的自动驾驶决策提供了全新的技术方案。
对于未来的研究,团队指出两大方向:①加入稀有交互场景和对抗行为的训练,进一步提升策略的鲁棒性;②结合更多的感知冗余设计,适配真实世界中更复杂的传感器噪声和环境不确定性,让自动驾驶的协商决策更贴近落地需求。
从“死板执行规则”到“灵活学会谈判”,时空有向图为自动驾驶的交互决策打开了新的大门。相信随着交互建模和强化学习技术的不断融合,智能车终将真正融入人类的交通体系,实现安全、高效、和谐的自动驾驶。

END
东南 SG-CADVLM:上下文感知解码赋能,让自动驾驶危情模拟更真实
[ ICRA 2026 ] 车辆感知加持,3D 行人姿态预测新成果
ScenePilot:3847 小时跨 63 国驾驶数据,打造自动驾驶 VLMs 评估新标杆
清华 & 现代汽车 音频-情绪-视觉协同:EchoVLA 的多模态 CoT 推理与自动驾驶优化
浙大 & 港大 AutoDriDM: 给自动驾驶 “AI 大脑” 做决策考试,VLMs 的能力边界被说透了!
【TR-C】南理工 & 华科:博弈 + 稀疏性双 buff!自动驾驶极端场景生成算法,精准戳破算法漏洞
复旦 & 理想 & 同济等 SGDrive: 用场景 - 智能体 - 目标三层认知,让 AI 像老司机一样思考
慕尼黑工业提出:聊天控车的LLM 驱动框架,让自动驾驶语音指令精准落地!
CAR 实验室 & 特华拉 DAVOS:毫秒级响应 + 隐私防护双 buff,让自动驾驶又快又安全
清华 & 港中文 & 滴滴 ColaVLA:用 latent 推理 + 并行解码实现高效安全驾驶
西交 & 南理工 HOCD:融合司机意图与状态的协作驾驶方案,冲突率大降 2.4+
华科 & 小米 DriveLaw:让自动驾驶兼具场景想象力与行驶稳定性
港理工 UrbanV2X 多传感器车路协同数据集:3 大场景、含 7 类车载 + 3 类路侧设备,破解城市峡谷自动驾驶定位难题

分享

收藏

点赞

在看
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 等等党赢了!国产又一款大6座SUV,能跑1508km,智己LS9
- 起亚硬派“大块头”SUV焕新!长超5米,比汉兰达大气,配2.5T混动
- 预算想买燃油轿车?我把艾瑞泽8高能版2.0T摸了个遍:这台A+级,真有点“越级”
- 2025年MPV卖了103万辆,6座SUV根本拦不住
- 预算15万 第一辆燃油轿车怎么选?
- 10万内买轿车别碰合资!这3台国产神车:4.8米车长+181马力才6.89万,插混续航128km仅7万
- 星越L成了燃油SUV销量冠军,看看老陈怎么说?
- 五六万买辆SUV,三年后真能卖三万?,保值率第一的车到底靠不靠谱?,开三年再看值不值.
- 日系轿车天花板?!我摸完雷克萨斯LS500h臻越版,只想先把话说在前面
- 10万级国民SUV标杆还得看它?我体验了第四代全新哈弗H6:优点很猛,槽点也不藏
