基于LiDAR的自动驾驶感知系统空间语义模糊测试
- 2026-03-16 23:31:19
A.Guo, Z.Su, X.Gao, et al. Spatial Semantic Fuzzing for LiDAR-based Autonomous Driving Perception Systems[J]. IEEE Transactions on Software Engineering,2025,Vol.52(1): 187-205.
摘要
自动驾驶系统(ADSs)通过先进的感知和反应能力,极大地提升了交通安全和出行效率。由于自动驾驶感知模块的失效,现实世界中仍发生了多起致命的交通事故。作为自动驾驶汽车的关键组件,基于激光雷达(LiDAR)的感知系统具有高复杂性和低可解释性,迫切需要开发有效的测试方法。
当前测试方法依赖于人工的数据采集和标注,这限制了其检测多样化错误行为的能力。本文基于蜕变测试理论,提出并实现了一个针对基于激光雷达的自动驾驶感知系统的模糊测试框架即LDFuzz。为提高测试效率并增加能够发现错误行为的测试用例数量,文章结合点云数据的特性引入空间覆盖率和语义覆盖率引导测试生成过程。在四个先进的3D目标检测感知系统上的实验表明,LDFuzz生成的测试用例比最优基线方法平均多检测出7.5%的错误行为,显著提升了失败测试用例的多样性。
引言
自动驾驶系统已经成为城市交通转型的关键。LiDAR传感器负责捕获周围环境信息,并将感知结果传递给下游的决策模块。现代基于LiDAR的感知系统主要依赖深度学习模型,需要大量标注的点云数据来学习决策逻辑。但在真实世界中,它们经常会因为感知错误而表现出意外的极端行为,甚至导致致命碰撞。因此对基于LiDAR的智能系统进行全面测试势在必行。
全面测试基于LiDAR的感知系统面临两大挑战:
从各种真实场景中收集大量点云耗时且费力。 为海量生成或变异的点云,人工标注边界框是不切实际的。
本文提出了一个高度自动化的空间语义模糊测试框架,命名为LDFuzz。其主要贡献包括:
空间语义模糊测试框架:LDFuzz利用种子选择、种子变异、引导和反馈的完整模糊测试流程,为各种架构的LiDAR感知系统生成海量带有测试预言的测试用例。 创新引导准则:设计了基于“空间覆盖率”和“语义覆盖率”的测试引导准则,全面揭示感知系统的潜在缺陷。 深度实证研究:在四个典型的LiDAR感知系统上进行实验,分析空间和语义视角下的常见错误行为。
## 研究背景
A.自动驾驶系统架构
高级别(如L4级)自动驾驶软件系统通常采用模块化架构,主要包括感知、规划和控制三大模块。感知模块负责识别车辆、行人等潜在障碍物,如图1。基于LiDAR的目标检测管道通常利用卷积神经网络(CNN)进行特征提取,采用卡尔曼滤波等数据融合技术整合不同管道的结果。
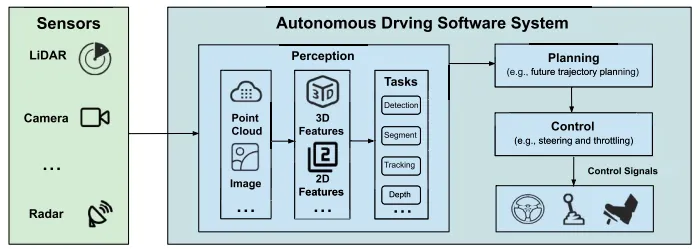
图1 自动驾驶汽车软件的架构
B.LiDAR点云的3D目标检测
LiDAR是一种先进的遥感技术,通过发射激光脉冲并测量这些脉冲从目标反射并返回所需的时间来计算与物体的距离。
给定点云作为输入,3D目标检测旨在对3D空间中的物体进行分类和定位,目前主要分为三类方法:
基于点:直接在原始点云上应用深度学习,如PointRCNN。 基于网格:将点云光栅化为离散网格,然后使用2D/3D卷积,如PointPillars, SECOND。 点-体素混合:结合上述两者的优点,如PV-RCNN。
尽管这些方法取得了显著进展,但在实际场景中仍面临点云稀疏性、恶劣天气噪声以及特定语义组合导致的失效问题。
本文利用了一个模糊测试框架,使用不同的转换操作符来产生大量的测试数据并执行自动化测试;引入空间覆盖率和语义覆盖率以指导测试过程,以通过考虑场景语义和障碍物的空间分布,彻底揭示基于LiDAR感知模型中的潜在缺陷。
方法论
A.框架概览
LDFuzz专门针对LiDAR点云数据进行了定制。
如图2,测试从真实世界数据集(如KITTI)中选择种子开始。LDFuzz会对种子进行天气变换和对象变换;引入语义感知和空间感知的测试指导来评估新生成的数据;随着种子数据集的扩展,LDFuzz利用种子选择策略来多样化种子集,进一步提高其整体性能;最后,LDFuzz根据系统预测的边界框生成测试报告,其中包括平均精度或平均精度指标,提供关于模型感知鲁棒性的反馈。
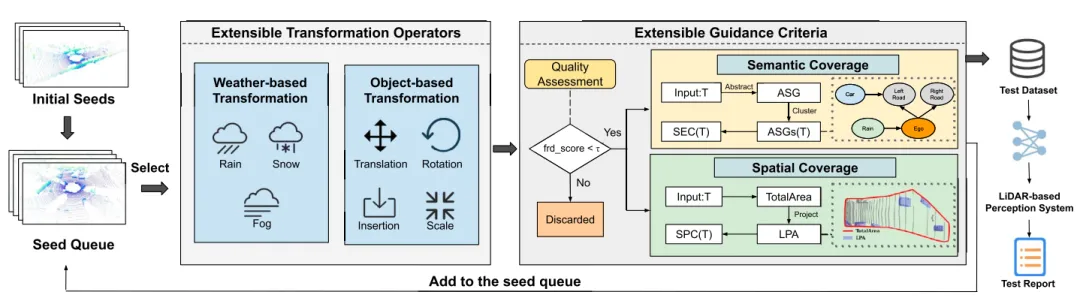
图2 LDFuzz的工作流程
算法1概述了LDFuzz为各种基于LiDAR的自动驾驶感知系统生成测试数据的过程。

B.基于变换算子的测试生成
1)、转换算子
为模拟现实世界中可能遇到的极端输入,LDFuzz实现了两类共7种变换算子:
基于对象的变换:现实中同一类别的物体形状各异,且位置和朝向动态变化。LDFuzz实现了四种操作:
平移: 改变物体位置。系统会自动提取路面数据,确保平移后的物体仍在路面上且不与其他障碍物碰撞。 旋转: 改变物体的航向角。 缩放: 改变障碍物的尺寸。 插入: 将一个真实的物体点云插入到当前场景的合理位置,保证不碰撞且位于可行驶区域。
基于天气的变换:LiDAR传感器对恶劣天气高度敏感,雨雪雾会引起激光反向散射和吸收,造成测量点丢失或产生噪点。
LDFuzz利用激光雷达光散射增强LISA模拟器,基于物理光学原理,实现了三种天气变换:降雨、降雪和起雾。每次转换过程中,实验都保持恒定的环境参数,并将转换应用于从种子队列中选择的种子。
2)、测试预言
Oracle问题代表程序的执行结果无法预测,是软件测试中最具挑战性的任务之一。对于基于LiDAR的自动驾驶感知系统,我们无法自动获得任何输入测试场景的地面真实3D检测结果。LDFuzz引入了蜕变测试,通过定义输入输出之间的蜕变关系(MRs)自动构建测试预言。
对象变换的蜕变关系(MR1): 无论对象在场景中如何被平移、旋转、缩放或插入,系统对场景中未发生改变的其余对象的检测结果应与原图保持一致;同时,变换目标对象应被正确检测。
具体而言,我们将自动驾驶的感知系统表示为P,即检测对象。给定种子点云c∈C,对象o∈O将被转换或插入点云c中。本研究中采用的基于对象的MR可以通过转换的点云来测试P,形式化如下:
其中,σ为对象变换算子,是对象o(即对象检测任务中估计的边界框)的基本事实,并且是变换算子。对点云c中的对象o进行变换,生成变换后的点云,期望变换后的点云的对象检测结果与原始检测的变换结果一致。具体来说,原始检测的变换结果是先与进行减法运算,再与进行并运算得到的。
天气变换的蜕变关系(MR2): 无论给原始点云叠加了哪种天气噪声,系统对场景中原有对象的检测结果,应当与在原始晴朗天气下的检测结果高度一致。类似于基于对象的MR,形式化如下:
给点云全局施加天气噪声后,系统的预测结果应当与原始晴朗天气下的预测结果P[c]保持一致。
3)、质量评估
为了保证生成场景的质量,本研究对一次变换设置了保守的参数。但在模糊化过程中,点云可以从初始种子开始依次变换,这使得在一系列变换之后保持其真实感具有挑战性。变换过程可以定义如下:
定义3.1: 点云c是从c一次变换而来,如果c'是在c上经过变换σ(记为)后生成的,其中。如果c'是在一系列一次变换后生成的,点云c’是从c连续变换而来。
在连续的模糊迭代中,LDFuzz规定每个种子最多叠加一次天气变换。为了衡量点云的真实性,引入了FRD。FRD通过利用从预训练模型导出的特征向量来量化两组点云数据之间的相似性。本研究利用 RangeNet++ 提取高维特征,衡量生成点云与参考真实点云特征分布的Wasserstein距离。距离越小,点云质量越高越真实。
为了阐明LDFuzz计算FRD的过程,本研究引入参考点云的概念,定义如下:
定义3.2: 给定一个点云,它是从(初始种子中的点云)一次性变换或顺序变换的,即,其中n≥1,参考点云(表示为)定义为:
对于经过多轮序列变换生成的点云,其质量评估公式为:
C.引导准则设计
传统的代码覆盖率对深度学习黑盒模型无效。LDFuzz提出了两大全新的感知引导准则:
1)、空间覆盖
评估自车对不同空间位置实体的感知广泛度。
定义3.3 LiDAR感知区域:给定初始种子及其迭代生成的点云序列,其覆盖的感知区域定义为所有生成对象边界框(PR)在2D平面投影的并集:
定义3.4 空间覆盖率:给定m个初始种子的集合S和生成的点云T,空间覆盖可以表示为:
空间覆盖率等于生成的对象投影总面积占可行驶路面总面积的比例。SPC越高,意味着生成的障碍物在物理空间中的分布越广泛。
2)、语义覆盖
为了衡量测试用例在“语义关系”上的多样性,LDFuzz引入了场景图(SG)。
语义覆盖的计算包括以下步骤:首先,使用场景图生成器将真实世界的点云转换为场景图;然后,对生成的场景图进行抽象聚类;接着,将抽象场景图划分为等价类。
场景图的数学表示如下:
LDFuzz重新标记了原始场景图中的不同对象标识符。例如,场景图使用不同的标识符来描述左道路车辆“car_1”和右道路车辆“car_2”,这些标识符与车辆之间的位置关系无关;如果重新贴上“汽车”标签,抽象过程计算效率高,可以有效地扩展到包含大量对象和复杂关系的场景,抽象生成的由每个初始种子组成的场景图所需的平均时间(包括KITTI和nuScenes)。图3是一个场景图及其抽象表示的例子。
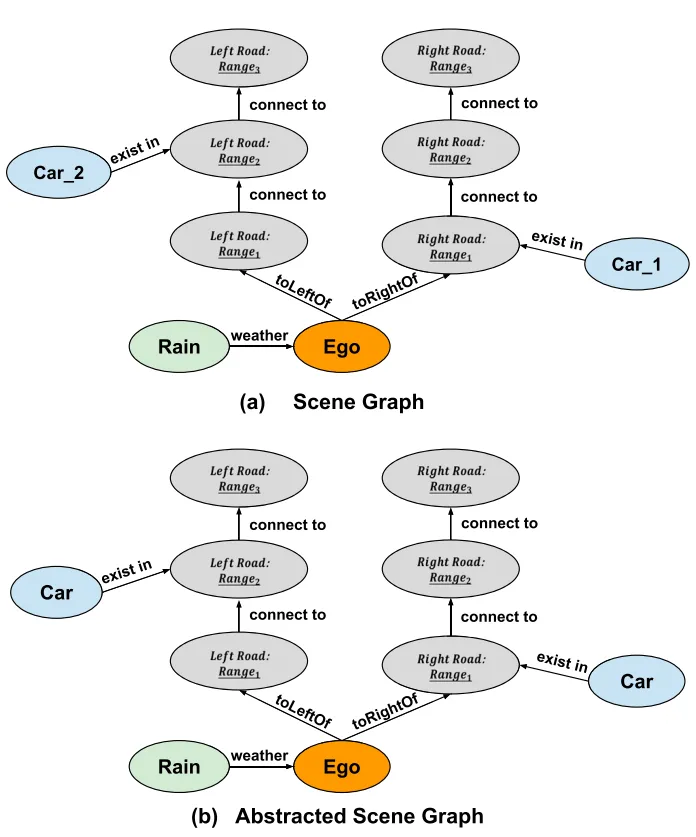
图3 生成的场景图及其相应的抽象表示的示例
该图描述了右侧Range 1段中障碍车辆的存在;道路和左侧道路的Range 2路段在下雨条件下的情况。
定义 3.5 语义覆盖率SEC:将具体车辆ID抽象化后,同构的场景图被归为同一等价类, 语义覆盖率计算公式为:
分子为当前模糊测试已触发的抽象场景图等价类数量,分母为初始种子库理论上可能生成的所有语义等价类总数。SEC越高,测出的“罕见语义组合/边缘场景”越丰富。
D.种子选择策略
为防止系统在少数几个种子上“过度变异”,LDFuzz遍历种子队列,并根据其概率确定当前种子是否被选中。它通过将高概率分配给种子队列中具有很少变体的原始种子及其对应的变换数据来施加偏差。选择种子s的概率计算如下:
g(ori(s))代表该初始种子目前已衍生出的变异体数量。衍生体越多的种子,其再次被选中的概率呈平方级下降。这一公式有效迫使Fuzzer不断探索库中那些未被充分发掘的稀有场景种子。
实验设计
本节介绍实验设置,包括研究问题、模糊框架的实现细节、实验数据集、被测系统和评估指标。
A.研究问题
RQ 1(变换算子): 不同的变换方法对基于LiDAR的感知系统生成测试的有效性如何?
RQ2(测试有效性): 检测基于LiDAR的感知系统的错误行为的不同指导标准的有效性如何?
RQ3(错误多样性): 在模糊化过程中,不同的种子选择策略和指导标准发现的错误行为有多大差异?
RQ4(缺陷分析): 深入分析LDFuzz检测到的错误。
B.实现细节
本研究在Python 3.7和Pytorch 1.13.1上实现LDFuzz。
所有测试的基于LiDAR的感知系统都是根据本文给出的参数进行复制的,并在Ubuntu 20.04.6 LTS服务器上构建,配备NVIDIA Geforce RTX 4070Ti和12GB图形内存。
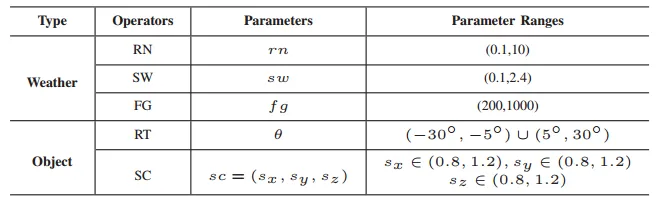
在我们的实验设计中,每个转换的候选参数如表2所示。当将转换运算符应用于选定的种子数据时,LDFuzz会随机选择每个特定转换的参数。
表2 LDFUZZ生成变换后驾驶场景的变换参数
C.数据集和基于LiDAR的感知系统
研究使用两个广泛采用的数据集KITTI 和nuScenes来评估所提出方法的有效性。
对于激光雷达3D物体检测系统,本研究基于开源平台OpenPCDet选取了四种主流架构的先进模型:PointPillars、SECOND、PointRCNN、PV-RCNN。
D.评估指标
采用3D平均精度 (AP/mAP),并引入 基尼杂质指数(Gini Impurity) 来定量评估检出错误的多样性:
结果分析
A.RQ1 解答
结果: 图4和图5比较了KITTI和nuScenes数据集的原始种子集(TO)与转换后的测试集(TA)上所有测试模型的AP和mAP(分别为AP和mAP)。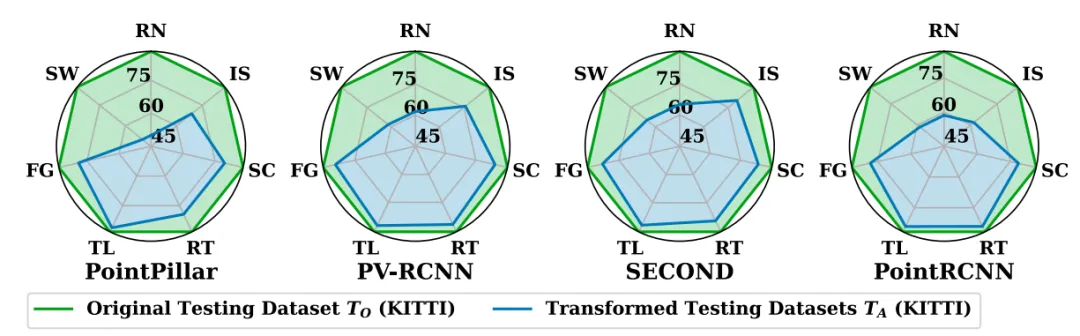
图4 在KITTI数据集上使用七个转换运算符测试不同模型的结果
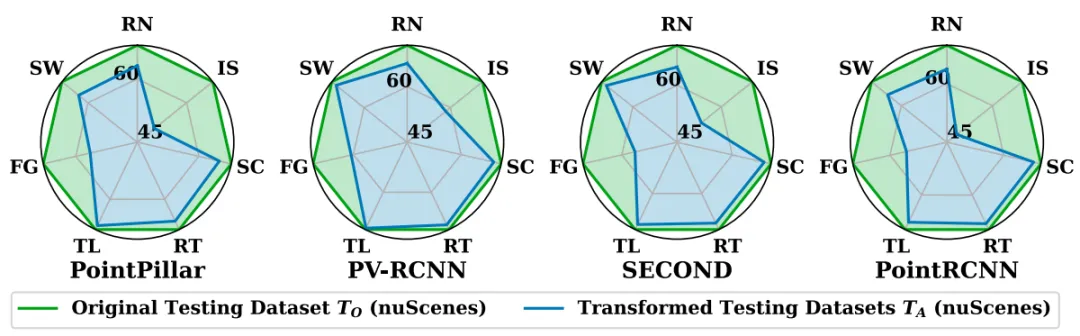
图5 在nuScenes数据集上使用七个转换运算符测试不同模型的结果
在大多数转换后的测试集上,所有测试模型的AP和mAP都显著下降。
在将变换算子应用于nuScenes数据集之后,模型表现出以下mAP减少:7.7%(RN)、4.9%(SW)、18.0%(FG)等。恶劣的天气条件会严重影响LiDAR的准确性。结果表明,所有提出的转换算子对模型测试过程有积极的影响。
分析: 恶劣的天气条件会显著影响基于LiDAR的感知系统的检测性能。系统更容易受到基于天气的转换所生成的数据的影响。
当前先进的自动驾驶系统可能无法在下雨或下雪的条件下有效运行,从而带来重大的安全风险。因此,开发能够适应不利条件是ADS技术进步的关键一步。
B.RQ2 解答
结果: 这五种策略在每个测试系统上产生的错误行为数量如图6所示。
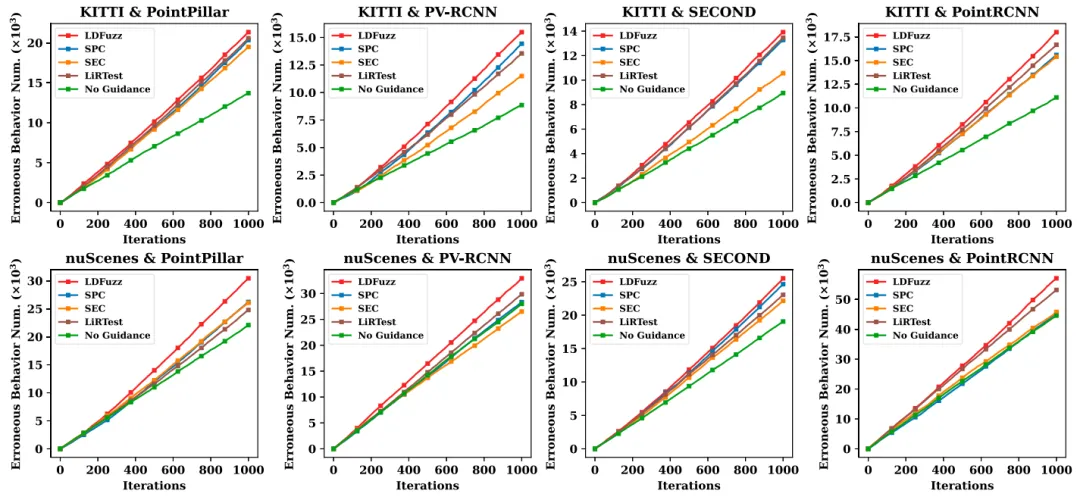
图6 根据不同的测试生成准则生成测试集
使用这两个测试标准作为指导(LDFuzz)生成的测试集的错误行为数量高于其他基线。
进行模糊测试后,LDFuzz在KITTI和nuScenes上的表现分别优于最佳基线5.6%和9.3%。表3显示了不同测试指导标准在检测错误行为方面的效率。在所有配置下,LDFuzz在检测错误行为方面优于其他基线。
表3 不同测试指导准则对检测错误行为的有效性
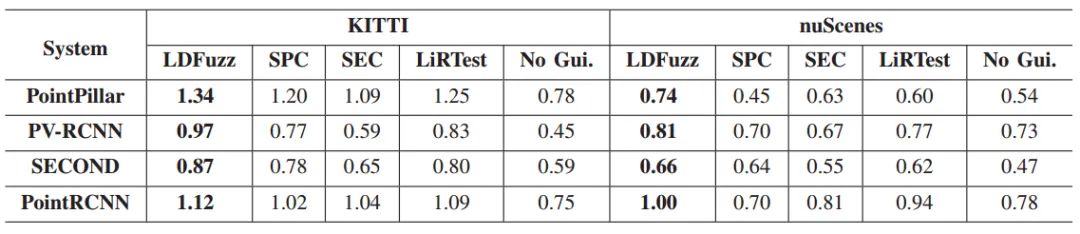
分析: LDFuzz同时采用的空间覆盖和语义覆盖识别出更多的系统错误行为。随着迭代轮数的增加,LDFuzz识别的错误行为数量与基线方法发现的错误行为数量差距扩大。
C.RQ3 解答
结果: 表4显示LDFuzz方法的Gini杂质指数高于随机方法和LiRTest。
表4 不同种子选择策略下FUZZ试验中发现的多样性
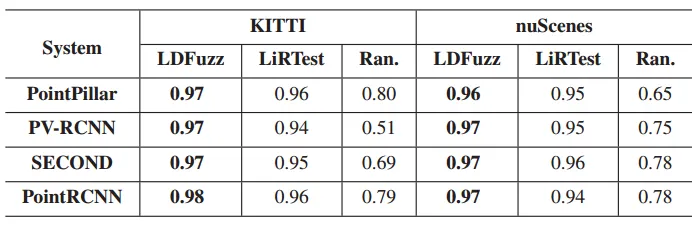
图7和图8显示LDFuzz在所有配置中检测空间感知错误时都取得了最佳结果。
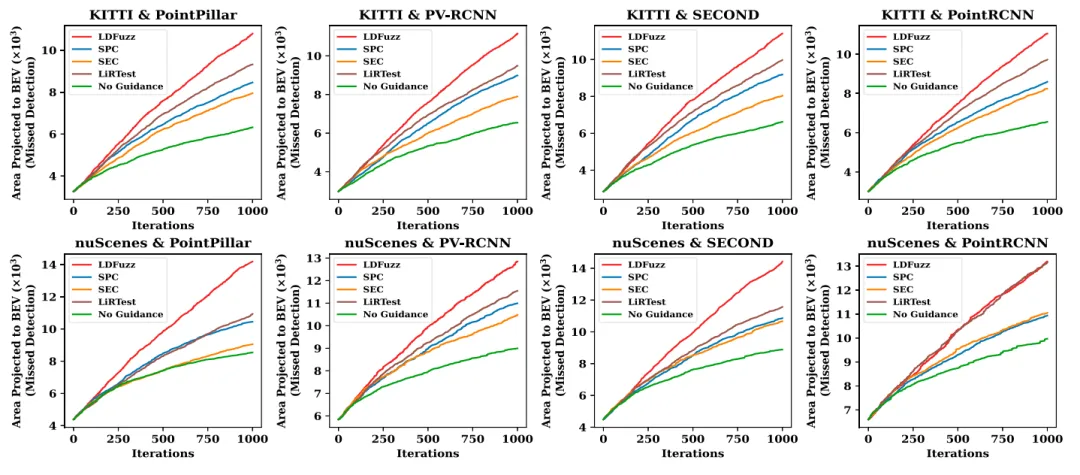
图7 根据各种指导准则生成的测试数据所覆盖的漏检测对象和虚假检测的区域(鸟瞰图)
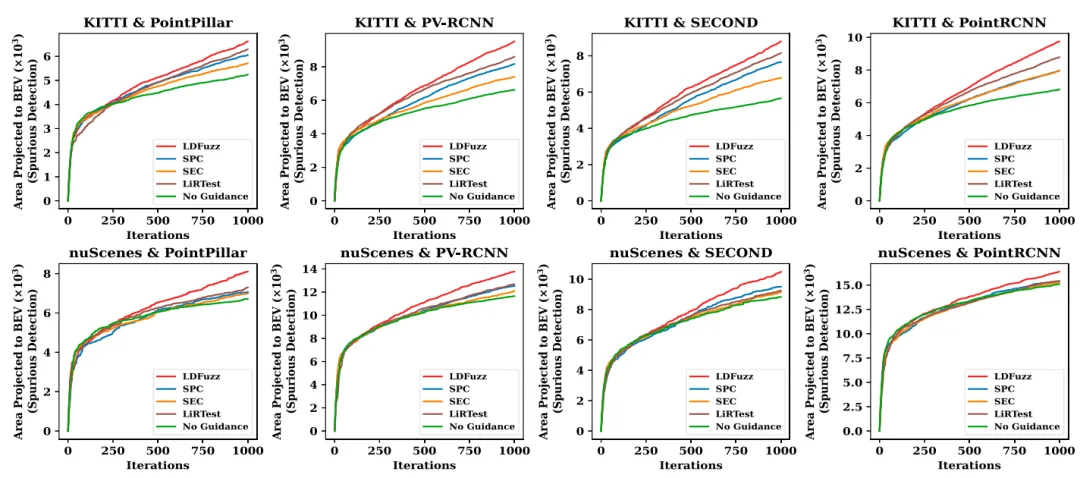
图8 同图7
图9示出根据各种引导准则生成的包含漏检测对象的测试数据所表示的场景图的等价类数;图10示出根据各种引导准则生成的包含伪检测的测试数据所表示的场景图的等价类数(原文展示)。
LDFuzz在检测方面始终优于所有其他方法。以上表明,LDFuzz可检测到的错误行为是多种多样的。
分析: 图7和图8示出了在绝大多数配置中,SPC可以在比SEC更宽的感知空间上识别错误行为。相反,图9和图10证明了与SPC相比,SEC擅长于检测与多样化感知语义相关的错误行为。给定框架的可扩展性,发展更有效的指导标准和种子选择策略是未来研究的方向。
D.RQ4 解答
结果: 表5展示具有空间遮挡关系的物体的漏检率平均比没有这种关系的物体高32.9%。随着迭代次数的增加,LDFuzz生成的数据中对象的漏检率继续上升。
表5 各系统对LDFUZZ产生的数据中包含和不包含的数据的感知性能
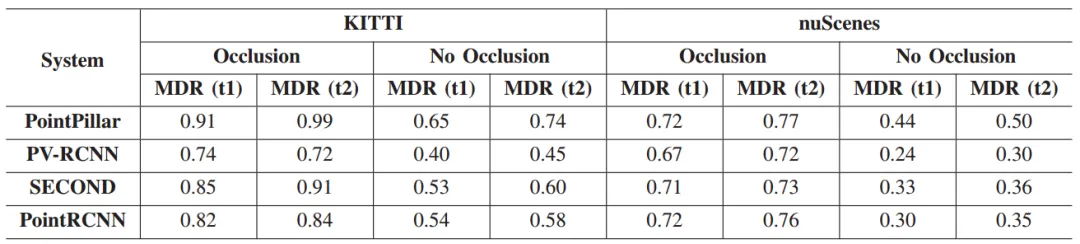
表6 LDFUZZ生成的测试集在不同路段上对不同系统的漏检率和误检率
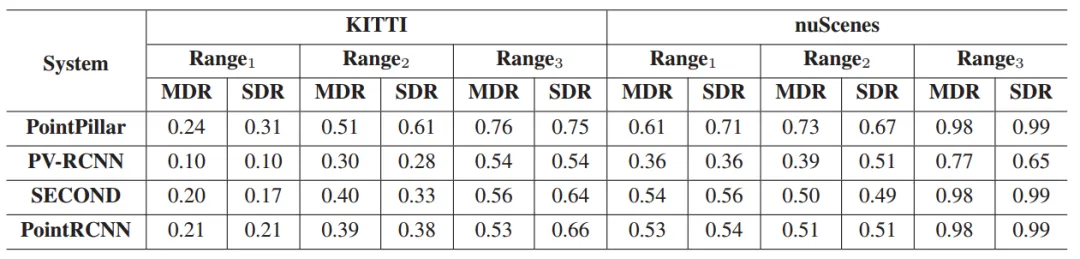
实验证明LDFuzz可以检测不同路段上的错误系统行为。
分析: 现有的基于LiDAR的感知系统在检测遮挡物体时存在明显的不足。随着LDFuzz生成的遮挡关系数量的增加,这些物体的漏检率也随之上升。
开发人员应推进高性能探测器并实施V2X协作感知方法,以提高基于LiDAR的感知系统的有效性。
相关工作
A.自动驾驶感知系统的测试与验证
现有研究如MetaOD侧重于摄像头图像合成,而 LiRTest 虽针对点云,但在高度自动化及引导机制上仍显薄弱。
B.ADS的模糊测试
AV-Fuzzer、DriveFuzz等多聚焦于系统级的规划和轨迹层;LDFuzz则创新性地填补了LiDAR感知模块设计的空间与语义双重引导模糊测试空白。
结论
本文提出并评估了一个基于LiDAR感知系统的空间语义模糊化框架LDFuzz,实现了两种变形变换来生成测试点云;提出了两个测试指导准则,即空间感知覆盖率和语义感知覆盖率,提高故障多样性和测试效率。
LDFuzz已在四个最先进的基于LiDAR的感知上进行了评估。结果表明,LDFuzz应用的转换可以检测基于LiDAR的自动驾驶感知系统中的大量错误行为。本文对基于LiDAR的感知系统中存在的错误行为进行了全面分析,并认为LDFuzz是ADS测试和分析的基础框架。


推荐阅读

