VLA会取代世界模型吗?自动驾驶的终极猜想
- 2026-03-21 01:33:59

01#
什么是VLA模型?
在工程实现上,VLA模型并不是一个单一模型,而是一套多模块协同的系统架构。
在典型落地方案中,其数据流通常可以拆分为以下几个阶段:
首先是多摄像头感知输入,车辆通过环视摄像头(通常为6–12路)采集实时图像数据。这些数据会被送入视觉编码器(Vision Encoder),例如DINOv2、SigLIP等模型,将原始图像压缩为高维语义特征。这一步的关键不只是“看见”,而是尽可能保留空间结构信息,例如目标的相对位置、运动趋势等。
接下来是视觉特征的token化(Tokenization)过程。这一阶段的目标,是将连续的视觉特征转换为离散的token序列,使其可以被语言模型处理。工程上常见的方法包括基于VQ(Vector Quantization)的离散编码,或通过轻量化适配层直接映射到LLM的embedding空间。但这一过程不可避免地会带来信息压缩与损失,因此如何在“语义表达能力”与“几何精度”之间取得平衡,是VLA落地的关键难点之一。
随后,这些token会输入到**多模态大语言模型(Multimodal LLM)**中。在这一阶段,模型不仅需要理解当前帧信息,还需要结合时间序列(历史状态)、导航目标甚至交通规则进行推理。工程上通常会对LLM进行结构改造,例如引入时间编码(temporal encoding)、多模态attention机制等,使其具备处理连续驾驶任务的能力。
LLM的输出并不会直接控制车辆,而是需要经过规划与控制映射模块(Planner / Action Head),将语义推理结果转换为轨迹(trajectory)或控制指令(如方向盘角度、加速度等)。在实际系统中,这一层通常会加入物理约束检查,例如轨迹平滑性、加速度限制等,以避免“语义合理但物理不可执行”的情况。
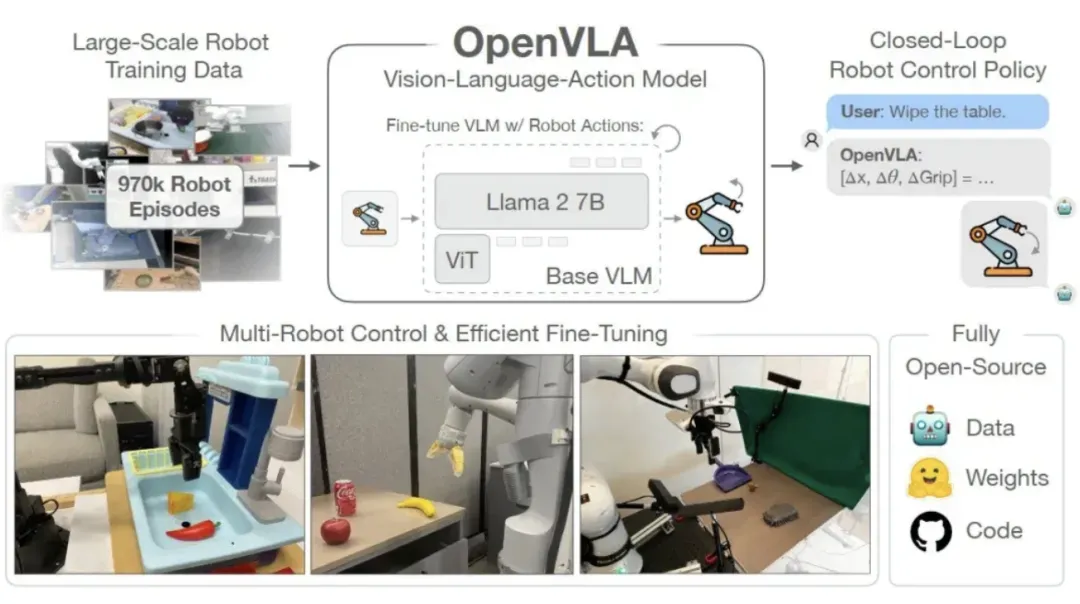
从工程角度来看,可以将VLA理解为一条“视觉→ 语义 → 行为”的链路,其核心挑战不在单个模块,而在于跨模态信息流的稳定性与可靠性。
进一步来看,VLA在实际落地中还面临几个关键工程问题:
实时性问题(Latency):大语言模型的推理延迟通常在几十到上百毫秒之间,而自动驾驶系统的决策周期通常要求在100ms以内,因此需要通过模型压缩、蒸馏或分层决策架构来优化性能。
安全约束问题(Safety Constraint):LLM本质上是概率模型,其输出不具备严格的物理约束,因此工程上通常需要额外引入安全模块,例如基于规则的过滤器或基于MPC(模型预测控制)的约束优化。
可解释性问题(Interpretability):虽然语言模型在语义层面“可解释”,但其内部推理路径仍然是黑盒,这在自动驾驶这种安全关键系统中,会增加验证和认证的难度。
因此,尽管VLA在语义理解与复杂场景处理上具有明显优势,但其工程落地往往需要配套一整套安全与控制机制,才能满足车规级要求。
什么是世界模型路线
从工程实现角度来看,世界模型路线本质上是将自动驾驶问题转化为一个“状态预测+ 策略优化”的问题。
在实际系统中,其核心可以拆分为三个关键部分:状态建模(State Representation)、动态建模(Dynamics Model)以及策略学习(Policy Learning)。
首先是状态建模。系统会基于多传感器(摄像头、激光雷达、毫米波雷达等)融合结果,构建一个统一的环境状态表示。这一状态通常包含自车状态(位置、速度)、周围动态目标(车辆、行人)、静态环境(车道线、路缘)以及不确定性信息。与VLA的“语义token”不同,这里的状态是连续的、可计算的,并且可以直接用于物理推演。
接下来是世界模型的核心——动态模型(World Dynamics Model)。其目标是学习环境的演化规律,即在给定当前状态和动作的情况下,预测未来状态:
S(t+1) = f(S(t), a(t))
在工程实践中,这一模型可以基于神经网络实现,例如Transformer或隐变量模型(latent model)。一些先进方案甚至会引入类似Dreamer或MuZero的框架,在潜在空间中进行预测与规划,以降低计算复杂度。
第三部分是策略学习(Policy Learning)。在拥有可预测的世界模型之后,系统可以在仿真环境中进行大规模试错,通过强化学习不断优化驾驶策略。这种方式的优势在于可以生成大量“长尾场景”数据,例如极端天气、突发事故等,而这些场景在真实世界中难以采集。

在工程架构上,世界模型通常采用云端训练+ 车端部署的模式:
云端:进行大规模仿真、模型训练与策略优化
车端:运行压缩后的模型,进行实时推理
这一架构的关键在于模型压缩与蒸馏技术,需要在保证性能的前提下,将复杂模型缩减到车规芯片可以承载的规模。
不过,世界模型路线同样面临显著的工程挑战:
仿真与现实差距(Sim2Real Gap):仿真环境再精细,也难以完全复现真实世界的复杂性,因此需要通过域随机化(domain randomization)、真实数据回灌等方式进行修正。
算力与成本问题:高保真仿真和大规模训练通常需要大量GPU资源,这对企业的基础设施提出了很高要求。
传感器依赖问题:为了保证状态建模精度,很多方案依赖激光雷达等高精度传感器,这会直接影响整车成本和规模化能力。
总体来看,世界模型更像是一种“工程可控性优先”的路径,其优势在于结果可验证、行为可约束,更符合安全关键系统的设计原则。
02#
两条路线的核心差异
从工程系统的角度来看,两条路线的差异不仅体现在模型形式上,更体现在整个技术栈的设计理念上。
在“世界表示”层面,VLA采用的是离散的语义token,这种表示方式更接近人类认知,有利于引入规则与知识;而世界模型采用的是连续状态空间,更适合进行物理建模与预测。在实际工程中,这意味着前者更偏向“认知驱动”,后者更偏向“物理驱动”。
在“决策生成”层面,VLA依赖LLM进行推理,其优势在于能够处理复杂上下文和长时序依赖,但需要额外模块保证物理可行性;而世界模型则直接在状态空间中进行优化,其决策过程天然满足动力学约束,更容易进行形式化验证。
在“数据闭环”方面,两者差异尤为明显。VLA更依赖真实世界数据和人工标注,这对数据采集和标注体系提出了很高要求;而世界模型则依赖仿真数据,可以在短时间内生成大量训练样本,但需要解决仿真与现实之间的偏差问题。
在“部署策略”上,VLA通常需要分层架构,例如将高层语义推理放在云端或离线训练中,而将低层控制模块部署在车端;世界模型则更倾向于端到端的车端部署,但其训练过程高度依赖云端资源。
从工程实践来看,这两条路线实际上代表了两种不同的优化方向:
VLA:降低规则复杂度,提高泛化能力
世界模型:提高系统可控性,增强安全性
03#
最后的话
从工程角度来看,VLA与世界模型并不是简单的“谁替代谁”的关系,而更像是两个在不同维度上优化的技术方向。
VLA更接近于自动驾驶系统的“认知层”,擅长理解复杂场景、推断行为意图以及处理长时序决策问题;而世界模型则更接近“执行层”,强调物理一致性、可验证性以及对安全约束的严格遵守。
在实际系统设计中,这两种能力往往是互补的。未来的主流架构,很可能会采用一种分层融合的方式:
上层:VLA负责语义理解与高层决策
下层:世界模型负责轨迹生成与物理约束
这种“语义 + 物理”的结合,有望在保证安全性的前提下,进一步提升系统对复杂环境的适应能力。
换句话说,自动驾驶的最优解,或许并不在于选择哪一条路线,而在于如何将两者的优势,在工程上进行有效融合。
资料来源于网络整理,如有侵权即删,请联系小编
扫描下方二维码,添加智驾派小助理微信,领取以下材料