日本SAKURA自动驾驶安全评价框架V4.0价值与挑战
- 2026-03-23 23:11:04

2026年3月,SAKURA项目正式结题,日本汽车工业协会(JAMA)发布了SAKURA自动驾驶安全评价框架的第四版——一份长达344页的技术文档。
这不是某个车企的内部报告,而是丰田、本田、日产、马自达、斯巴鲁、铃木、日野、三菱等几乎全部日本主流车企,加上博世日本、大陆日本等Tier 1,在日本经济产业省(METI)主导下,联合打造的国家级安全评价体系。
SAKURA项目主席Satoshi Taniguchi来自丰田,同时也是ISO 34502的项目负责人。该项目也与我们熟知的德国PEGASUS系列项目有密切联动和协作,并支持了第一个L3法规UNECE R157,换句话说,这份文档的方法论直接塑造了国际标准。
它为什么值得我们花时间读?读完又能用在哪里?
本文将从公司价值、工程师价值、核心方法论,一直到端到端AI时代的前沿挑战,做一个系统的解读。
一、先搞清楚:SAKURA到底在做什么
SAKURA的全称是Safety Assurance for automated driving using Knowledge-based Universal Risk Assessment。名字很长,核心思路却很简洁:
用物理原理,系统性地穷举自动驾驶需要面对的所有安全场景。
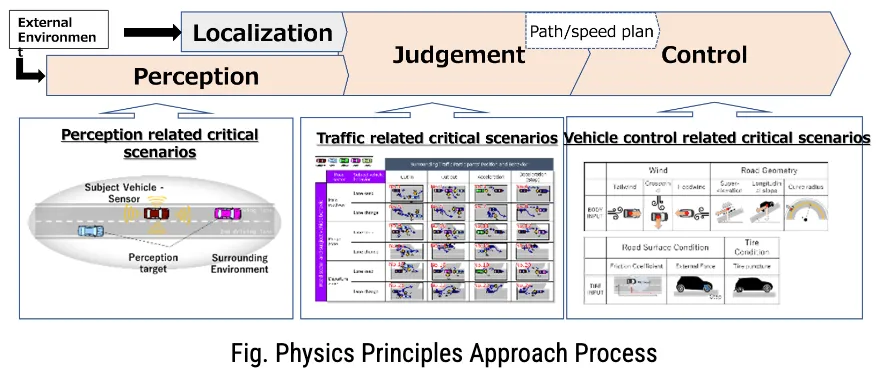
具体怎么做?框架把动态驾驶任务(DDT)拆解为感知→决策→操作三个过程,然后针对每个过程,基于物理原理识别可能的干扰因素:
- 感知干扰
传感器物理机制决定的——雷达的电磁波特性、LiDAR的红外光特性、摄像头的可见光特性,分别会在什么条件下"看不清" - 交通干扰
道路几何×自车行为×周围车辆行为的系统组合——什么样的交通态势会构成威胁 - 车辆动力学干扰
作用于车辆的物理力——路面状态、风力、轮胎性能如何影响控制
这套方法的精髓在于:不是从事故数据中倒推场景(数据驱动),而是从物理第一性原理正向推导场景(原理驱动)。好处是可以论证场景集合的完备性——你能说清楚为什么这些场景"够了"。
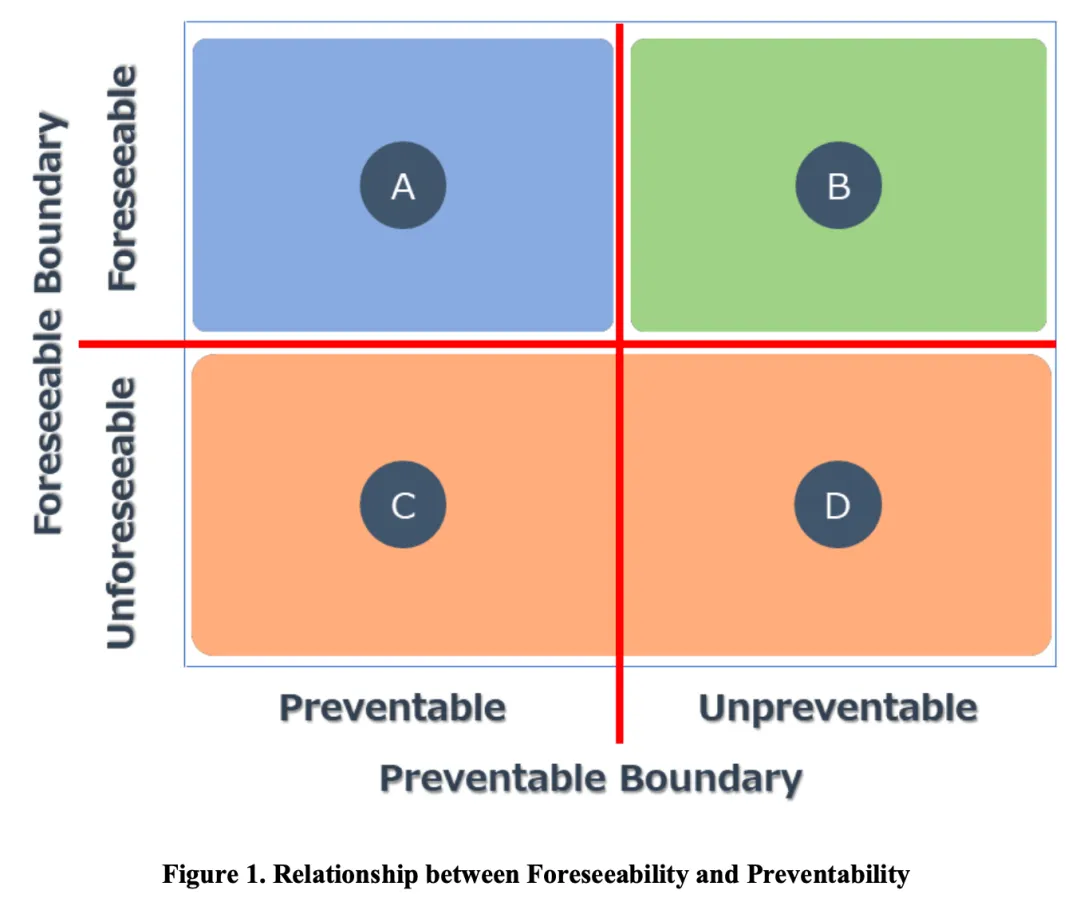
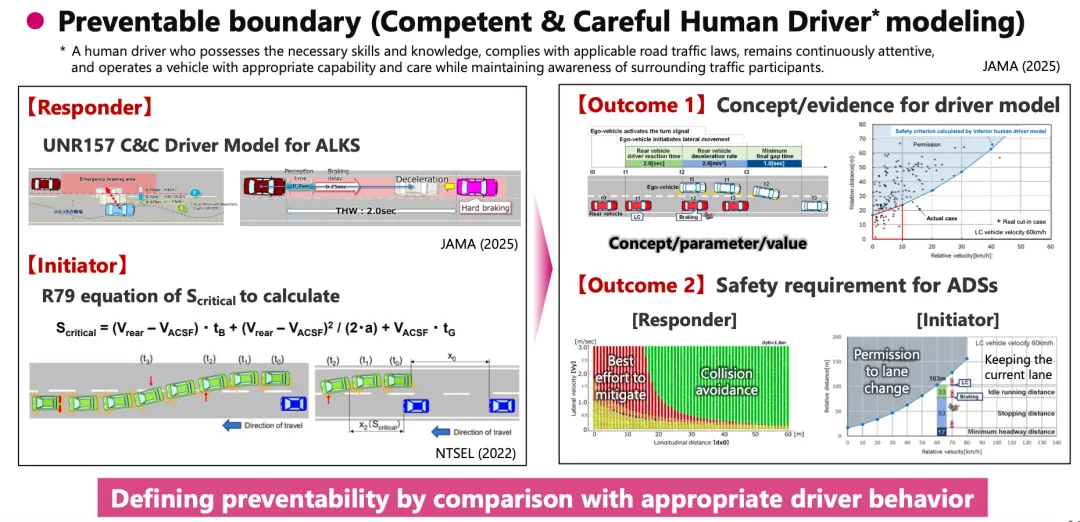
在此基础上,框架还建立了一个四象限模型:按"合理可预见性"和"可预防性"两个维度划分所有场景。核心评价对象是象限A——可预见且可预防的场景,自动驾驶系统在这些场景中不能出事故。
Ver.4.0相比之前的版本,最大的更新是在之前主要面向结构化道路的基础上,全面纳入了城市行车场景和弱势交通参与者VRU(行人和骑行者),并扩展了一般道路的遮挡场景考量。
二、这份文档对谁有用?
整车企业(OEM)
安全论证结构。文档展示了一套完整的、与ISO 21448对齐的安全保障流程——从ODD定义到安全评估的闭环。OEM安全部门可以直接参照搭建自己的安全论证体系。
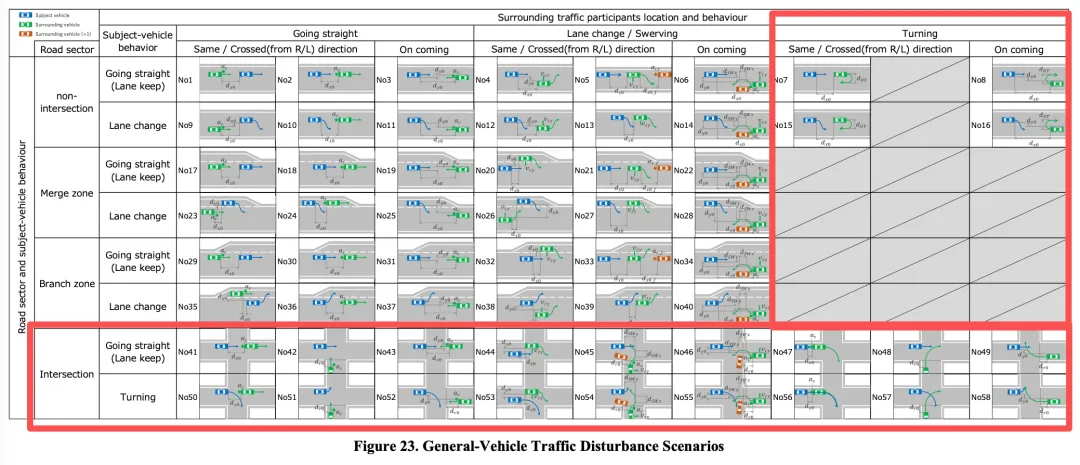
场景矩阵。框架通过系统组合构建了58类交通干扰场景,为测试场景库建设提供了结构化起点。不用再从零开始拍脑袋。
C&C Driver模型。这是文档技术含量最高的部分之一——将人类驾驶员的碰撞规避行为量化为具体参数:感知延迟0.75秒、最大减速度0.774G。这些数字直接定义了安全判据的基准线。
自动驾驶科技公司
合规出海的核心参考。Annex G直接对应UN R-157法规的仿真验证要求。如果你的AD系统要出海,这一章是必读。
Pass/Fail的量化依据。文档给出了Cut-in、Cut-out、Deceleration三类典型场景的可预防性边界——绿色区域表示系统应当能避免碰撞。这是算法测试判据的直接来源。
传感器供应商
Annex E大约100页,是全球最系统的传感器物理原理干扰场景建模文档之一。毫米波雷达5类干扰、LiDAR 3类干扰、摄像头3类干扰,每类都从物理原理出发建立了完整的干扰模型。传感器团队的必读材料。
研究机构
Physical Principle Approach本身就是方法论创新。C&C Driver模型的局限性(仅覆盖制动、仅覆盖安全维度、参数区域局限)是明确的open research question。VRU场景的量化方法尚在发展中。
三、工程师应该怎么读
不同角色的工程师,关注点差异很大。
算法工程师
应该重点理解场景不是随机产生的,而是通过DDT过程分解+物理原理推导出来的。重点看第5章——Cut-in场景如何从数据采集→参数提取→分布估计→概率阈值设定,一步步定义出"合理可预见"的参数范围。以及第6.4节的可预防性边界——这直接决定了你的规划模块应该设置多大的安全裕度。
功能安全/SOTIF工程师
应该关注第3.1节的安全保障全流程图——它清晰展示了SAKURA如何将ISO 21448的四象限与WP29的四象限关联起来。C&C Driver模型本质上回答了一个SOTIF核心问题:系统需要达到什么水平,才能证明事故是"可预防的"?Annex D的覆盖度验证方法(与GIDAS、NHTSA、ITARDA三大事故数据库交叉验证,覆盖率约90%)直接支撑"触发条件充分识别"的论证。
测试工程师
应该从第4章的三层场景抽象体系(功能场景→逻辑场景→具体场景)开始,理解测试用例的设计粒度;然后看第5章的参数化方法和Annex G的仿真验证标准。
传感器工程师
直接去看Annex E和F——从物理第一性原理出发的系统化失效模式识别方法,比传统的经验性枚举强太多。
四、对中国标准工作的启示
说完了SAKURA本身,更重要的问题是:对我们有什么用?
场景完备性论证方法的缺口。中国标准目前多采用典型场景枚举方式,缺乏SAKURA这种基于物理原理的系统性推导。这不只是方法论的差异,更是安全论证说服力的差异——你能不能说清楚"为什么这些测试场景是够的"。
驾驶员模型亟需本土化。SAKURA的C&C Driver参数基于日本驾驶员数据。已有研究表明,中国驾驶员在切入场景和跟车行为上与欧日驾驶员存在显著差异——直接复用这些参数不适用。
VRU场景的特殊性。中国城市道路的人车混行程度远高于日本和欧洲,行人和骑行者场景的参数化和安全判据必须基于中国本土数据建立。
五、C&C Driver的进化方向:驾驶员基础模型
C&C Driver是个好模型——思路清晰、参数明确、可操作性强。但它有三个硬伤:只考虑制动避险、只评价安全维度、参数来源区域受限。
驾驶员基础模型(Driver Foundation Model, DFM)的概念提供了一条突破路径。
DFM的核心思路是:不再依赖理论推导的刚性安全边界,而是从大规模真实驾驶数据中"萃取"涵盖安全、效率、舒适性等多维度的柔性行为基准。

☕️ DFM 方案详见:自动驾驶到底该"开得像谁"?—— 驾驶员基础模型给答案
DFM跟DriveGPT、GAIA-1这些模型有本质区别。后者是"行为生成范式"——学会开车;DFM是"行为评价范式"——学会评价。DFM不生成轨迹,它输出的是"能力信封"——多维度的条件概率分布,告诉你"优秀驾驶员在这个场景下的行为分布是什么样的"。
DFM与SAKURA有天然的对接点:
SAKURA的场景参数(如Cut-in场景的6个参数)直接作为DFM的输入条件变量 DFM的能力信封可以扩展C&C Driver的二值Pass/Fail为连续分布评价 DFM通过百分位选择机制从大规模数据中定义"优秀驾驶员"基准,比少量实验数据更具统计代表性
对我们的启示:利用中国本土大规模驾驶数据训练DFM,建立反映中国交通特征的"胜任且谨慎的驾驶员"量化基准,这不仅是学术问题,更是UN R-157中国化实施的数据基础。
六、端到端时代:场景测试方法的根本性挑战
最后一个议题,也是最深层的:当端到端自动驾驶成为主流,SAKURA这类基于场景的测试框架还管用吗?
五个根本性挑战:
中间状态不可观测。 SAKURA的三类干扰隐含了模块化假设——感知、决策、操作可以分别评价。E2E把这三个过程融为一体,"系统是否正确感知了目标"不再可观测。
因果链条断裂。 模块化架构中,碰撞可以归因到"感知漏检"或"规划失误"。E2E的行为是涌现性的,归因成为难题。
行为不确定性。 基于E2E的自动驾驶在同一场景输入可能产生不同输出。传统框架假设系统行为是确定性的。
长尾场景组合爆炸。 E2E模型对微小输入变化可能产生截然不同的输出(蝴蝶效应),参数空间的覆盖难度指数级增长。
覆盖幻觉(Coverage Illusion)。 这是最深刻的挑战——场景枚举本质上是在连续状态空间中采样离散点,而安全违规往往发生在结构化的边界附近。"生成了足够多场景"并不等同于"系统足够安全"。即便是AI驱动的场景生成器,也倾向于强化训练数据的统计中心,而安全违规恰恰存在于低概率的分布尾部。
场景数量不能替代结构化的安全保证。那怎么办?
我认为未来的自动驾驶安全评价需要三层方法协同工作:
第一层:形式化规格。 形式化验证和可达性分析回答的是"无论什么场景,什么不能发生"。它不依赖场景枚举,而是在结构层面提供覆盖信息——哪些状态空间是可证明安全的?哪些仍然未知?
第二层:结构化场景测试。 就是SAKURA做的事——基于物理原理构建有限且完备的场景分类体系,提供可操作的测试方案。
第三层:AI驱动的场景生成。 利用世界模型和生成模型在参数空间中进行高效探索和边界压力测试。
三层各有所长、各有所限。关键在于建立协同机制:形式化方法定义安全边界→SAKURA式方法将边界转化为可操作的测试场景→AI驱动的生成方法在这些场景空间中进行高效探索。
在这个框架下,场景不再是安全性的独立"证据",而是"证人"——通过的场景见证了与安全性质的一致性,失败的场景见证了反例的存在。每个场景可追溯到一个形式化性质、一个状态空间区域或一组假设。这种可追溯性,是监管机构日益要求的。
七、总结
JAMA SAKURA Ver.4.0是当前全球最系统的基于场景的自动驾驶安全评价方法论文档之一。它的价值不仅在于344页的技术细节,更在于它展示了一种从物理第一性原理出发、系统性构建安全评价体系的方法论范式。
对中国自动驾驶产业而言,核心建议是:
以SAKURA框架为方法论基础,融合数据驱动的DFM理念,引入形式化方法的结构性保障,构建适应端到端时代的多维度、概率化、本土化安全评价体系。
这不是一件容易的事,但这是一件必须做的事。
参考文献与链接
三篇核心文献
[1] Automated Driving Safety Evaluation Framework Ver. 4.0 -Guidelines for Safety Evaluation of Automated Driving Technology
JAMA官网:https://www.jama.or.jp/english/reports/framework.html SAKURA项目官网:https://www.sakura-prj.go.jp/project_info/
[2] Zhang Y, Wang C, Shum H P H. Benchmarking Autonomous Vehicles: A Driver Foundation Model Framework. CARS@EDCC, 2026.
arXiv全文:https://arxiv.org/html/2602.08298v1
[3] Zhang Z . Beyond Scenarios: Why AI-Driven Scenario Testing Is Incomplete Without Formal Methods(2026)
- Zengjie Zhang blog: https://zhang-zengjie.github.io/blogs.html?blogId=20260220
文中引用的其他参考文献
端到端自动驾驶综述
Chen L et al. End-to-End Autonomous Driving: Challenges and Frontiers. IEEE TPAMI, 2024.
DriveGPT — 大规模自回归驾驶行为模型
Huang X et al. DriveGPT: Scaling Autoregressive Behavior Models for Driving. ICML, 2025.
DiffusionDrive — 扩散模型驱动的端到端自动驾驶
Liao B et al. DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving. CVPR 2025.
GAIA-1 — 生成式世界模型
Hu A et al. GAIA-1: A Generative World Model for Autonomous Driving. arXiv:2309.17080, 2023.
C&C Driver模型实证验证
Olleja P et al. Validation of Human Benchmark Models for Automated Driving System Approval: How Competent and Careful Are They Really? Accident Analysis & Prevention, 2025.
中国驾驶员行为与ECE R157对比
Liu R et al. Comparison Between Cut-In Performance Model of ECE R157 and Behaviors of Chinese Drivers. Automotive Innovation, 2025.Springer
中德跟车行为对比
Li Z et al. Development of Human-Like Automated Driving Following Rules: A Comparison between China and Germany. Transportation Planning and Technology, 2025.Taylor & Francis
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 全新车奔驰eQE SUV指导价48.6万,现在包牌过户27.99万
- 月销1.2万台的秘密!卡罗拉SUV凭2.0L混动+5.1L油耗,稳坐家用销冠
- 国产又一大6座SUV,车长5265mm,2+2+2座椅,两种动力
- 瑞虎8 PRO,为什么说它是十几万燃油SUV里的全能选手?
- 吉利首款硬派SUV,定名为银河战舰700,外观很方正硬朗,年内上市
- 工信部曝光五款SUV真实续航!2026年新能源“神仙打架”的胜负手在这
- 大众新SUV定档,3月31日,正式上市
- 26.98万起!问界全新SUV发布
- 福特硬派SUV上新,越野迷直呼过瘾
- 吉利终于放大招!国产全地形SUV命名战舰700!这价格多少能卖爆?
