
引子:一个正在发生的范式冲突
2024年,自动驾驶行业发生了一个不太被安全工程师关注、但可能深刻改变他们工作方式的变化:
端到端(End-to-End)架构开始从论文走向量产。
特斯拉FSD V12全面转向端到端神经网络。华为、理想、小鹏、蔚来相继发布或预告了各自的端到端方案。学术界,UniAD拿下CVPR 2023最佳论文,DriveTransformer登上ICLR 2025,DiffusionDrive成为CVPR 2025 Highlight。
但与此同时,全球自动驾驶安全评价体系的基石——基于场景的开发与测试方法——仍然建立在一个核心假设之上:自动驾驶系统可以被分解为感知、规划、控制三个模块,分别识别各模块的干扰因素,进而构建测试场景。
当端到端把这三个模块融为一体,这套方法还能用吗?
这不是一个学术问题。这是每一个正在做L2+/L3产品的SOTIF工程师、测试工程师和安全架构师,今天就需要面对的实际问题。
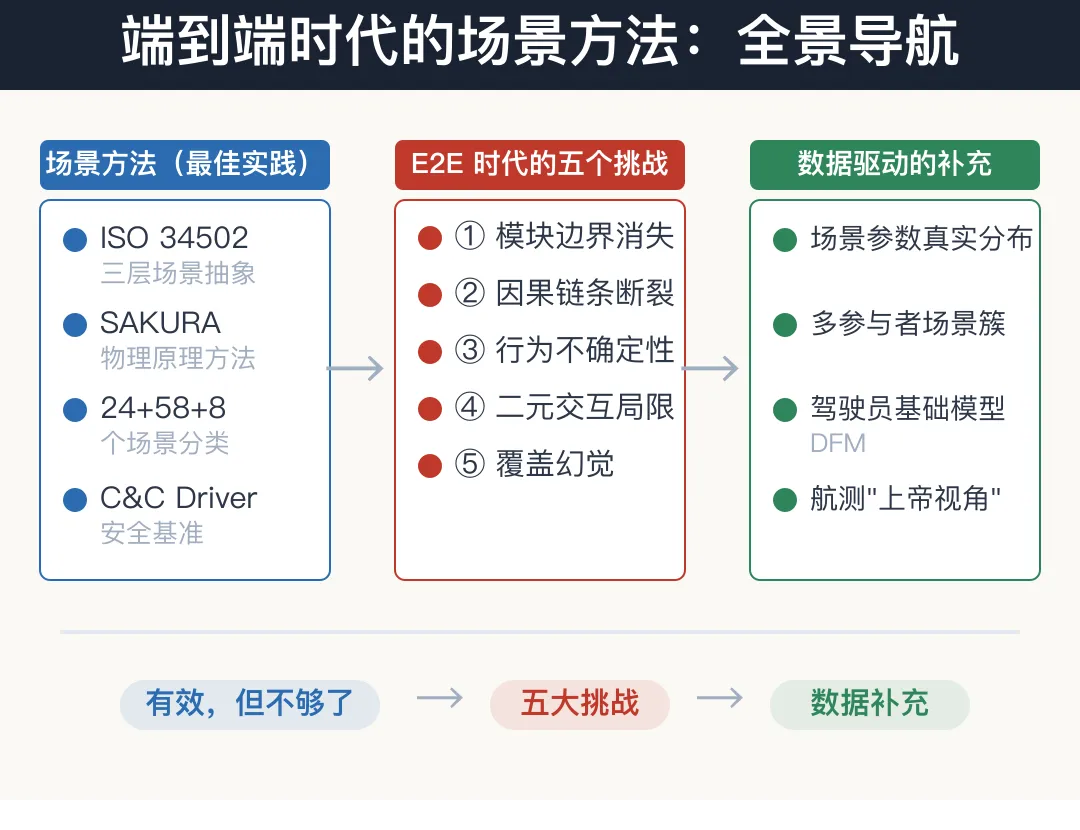 图1 文章全景导航图
图1 文章全景导航图
一、先理解场景方法的技术内核
在讨论"还有效吗"之前,必须先理解基于场景的方法到底在做什么。很多人对它的理解停留在"就是列一堆测试场景"的层面,这远远不够。
1.1 ISO 34502:场景的三层抽象
ISO 34502:2022是当前基于场景的安全评价领域最重要的国际标准,由日本SAKURA项目主席Satoshi Taniguchi(丰田)主导制定。它定义了一个三层场景抽象模型:
| | |
|---|
| 功能场景 | | |
| 逻辑场景 | | 切入角度5°-30°,相对速度10-40 km/h,横向距离1.5-3.5 m |
| 具体场景 | | 切入角度15°,相对速度25 km/h,横向距离2.0 m |
这个三层模型的价值在于:它把"无穷多的驾驶情况"转化为"有限且可管理的场景空间" 。功能场景用于专家讨论,逻辑场景用于参数化测试设计,具体场景用于可复现的仿真测试。
 图2 ISO 34502 三层场景抽象模型
图2 ISO 34502 三层场景抽象模型1.2 SAKURA从物理原理推导场景
上一篇文章详细介绍了SAKURA框架。这里聚焦它最核心的方法论——物理原理方法(Physical Principles Approach)。
SAKURA把动态驾驶任务(DDT)分解为三个过程,然后针对每个过程,基于物理原理系统性地识别干扰因素:
感知过程 → 传感器物理干扰 ├── 摄像头:可见光特性 → 强光、反光、低光照 ├── 毫米波雷达:电磁波特性 → 多径反射、相互干扰 └── LiDAR:红外光特性 → 雨雪吸收、灰尘散射规划过程 → 交通干扰 ├── 道路几何 × 自车行为 × 周围车辆行为 └── 24个高速场景 + 58个车辆交通模式 + 8个VRU模式控制过程 → 车辆动力学干扰 ├── 路面状态(湿滑、积水、冰雪) ├── 风力(侧风、阵风) └── 轮胎性能衰减
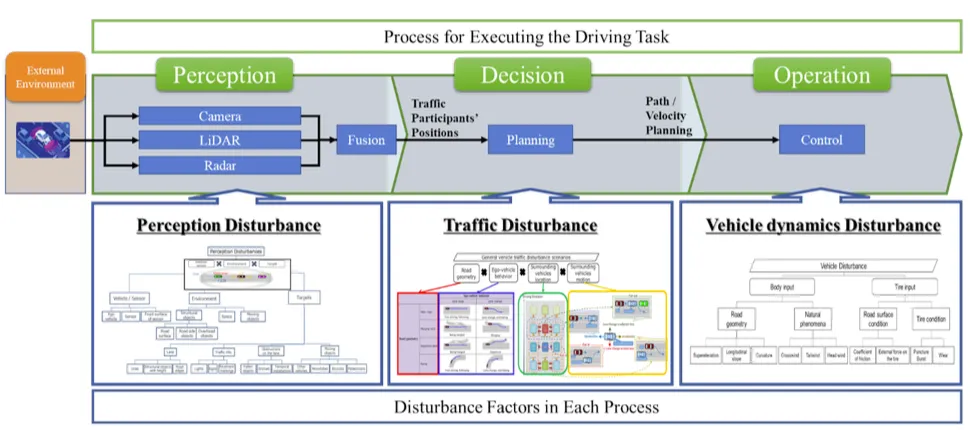 图3 驾驶任务与干扰要素
图3 驾驶任务与干扰要素这套方法的核心优势是:不依赖事故数据(数据驱动),而是从物理第一性原理正向推导(原理驱动)。因此可以论证场景集合的完备性——你能说清楚"为什么这些场景是够的"。
1.3 场景的数量
具体来说,ISO 34502为高速公路场景定义了24个交通干扰场景,通过以下维度的系统组合生成:
3 × 2 × 4 = 24个功能场景。
SAKURA V4.0在此基础上大幅扩展:58个车辆交通干扰模式 + 8个VRU模式,覆盖了高速、城市道路、弱势交通参与者等完整场景空间。V4.0还新增了城市行车场景和遮挡场景。
在这套框架下,每一个场景都有明确的物理依据,每一个参数都有可追溯的来源。
这是当前全球最系统、最严谨的基于场景的安全评价方法论。
二、端到端时代的五个结构性挑战
充分理解了场景方法之后,我们来看端到端架构给它带来的冲击。
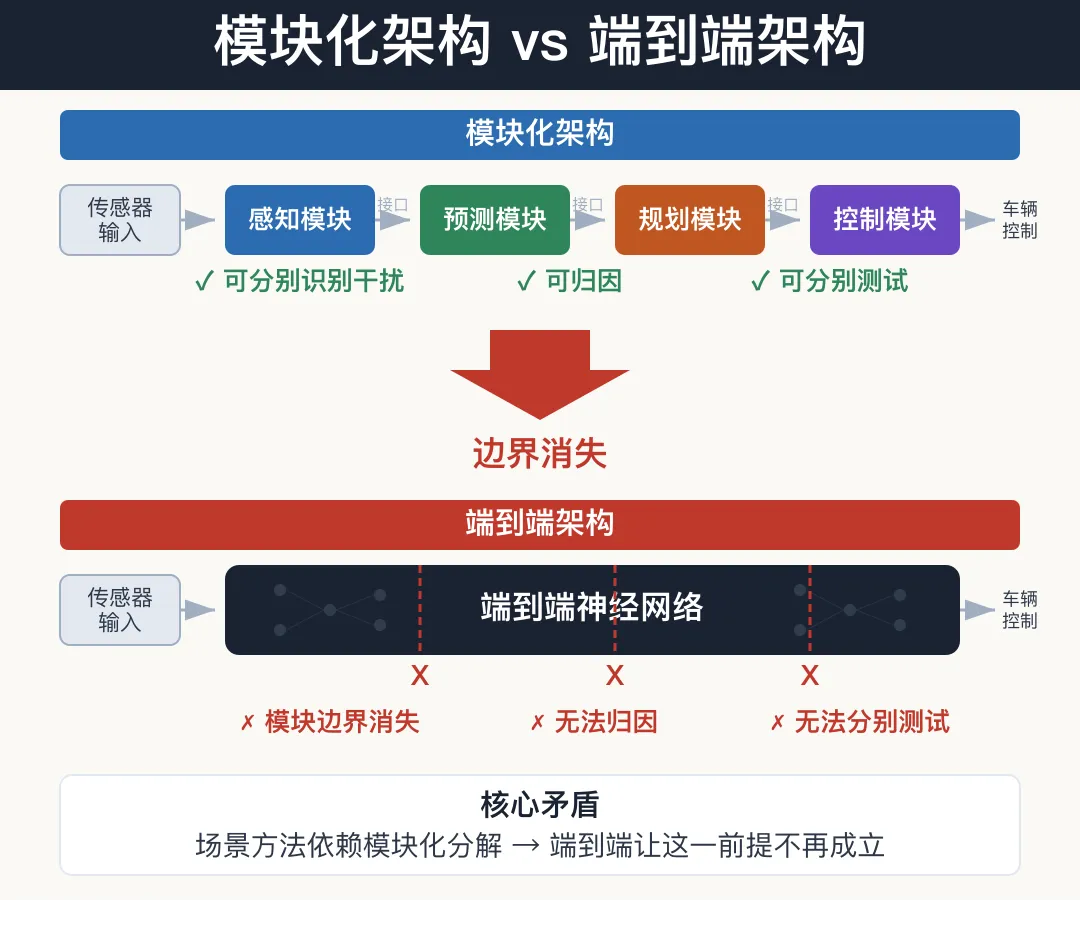 图4 模块化 vs 端到端架构对比
图4 模块化 vs 端到端架构对比2.1 模块边界消失:干扰无法归因
SAKURA的整个方法论建立在DDT三过程分解之上——感知干扰、交通干扰、动力学干扰分别识别、分别测试。
但端到端架构把感知、预测、规划甚至控制融合到一个神经网络中。UniAD、DriveTransformer这些模型的特点就是取消了中间模块的显式边界。
这意味着:当系统在某个场景中失败时,**你无法判断是"没看见"还是"看见了但判断错误"还是"判断对了但执行失败"**。SAKURA框架中清晰的"三类干扰"分类,在E2E系统上失去了对应的观测点。
2.2 因果链条断裂:归因成为难题
在模块化架构中:
碰撞 → 规划模块输出了错误的轨迹 → 因为预测模块低估了前车减速度 → 根因定位完成
在端到端架构中:
碰撞 → 神经网络输出了错误的控制信号 → ??? → 无法追溯到具体的失效机制
E2E系统的行为是涌现性的,而不是模块化的因果链条。这对安全论证是一个根本性挑战——当你无法回答"为什么会出事"时,如何论证"不会再出事"?
2.3 行为不确定性:同一场景不同输出
传统场景测试假设系统行为是确定性的:给定相同的输入场景,系统应产生相同的输出行为。
但基于扩散模型的E2E方案(如DiffusionDrive)本质上是概率性的——同一场景多次运行可能产生不同的轨迹规划。这使得传统的"场景Pass/Fail"判据需要重新思考:通过10次中的9次算Pass还是Fail?
2.4 二元交互的局限:真实世界的复杂性
这一点经常被忽视,但可能是最根本的问题。
ISO 34502定义的24个高速场景,核心模式是 "自车 + 一辆对手车"的二元交互 。即使加上Cut-out场景中的"被遮挡目标",也最多是三元交互。
但真实世界中,一辆车在任意时刻面对的交互对象通常是5-15个甚至更多:
这不是6个独立的二元交互,而是一个多交通参与者耦合场景。每个参与者的行为都受到其他参与者的影响,形成复杂的交互网络。
端到端系统恰恰试图处理这种复杂性——它直接从全场景的传感器输入映射到驾驶决策,不做交互对象的二元拆分。
但我们的测试框架,还在用二元交互来评价它。
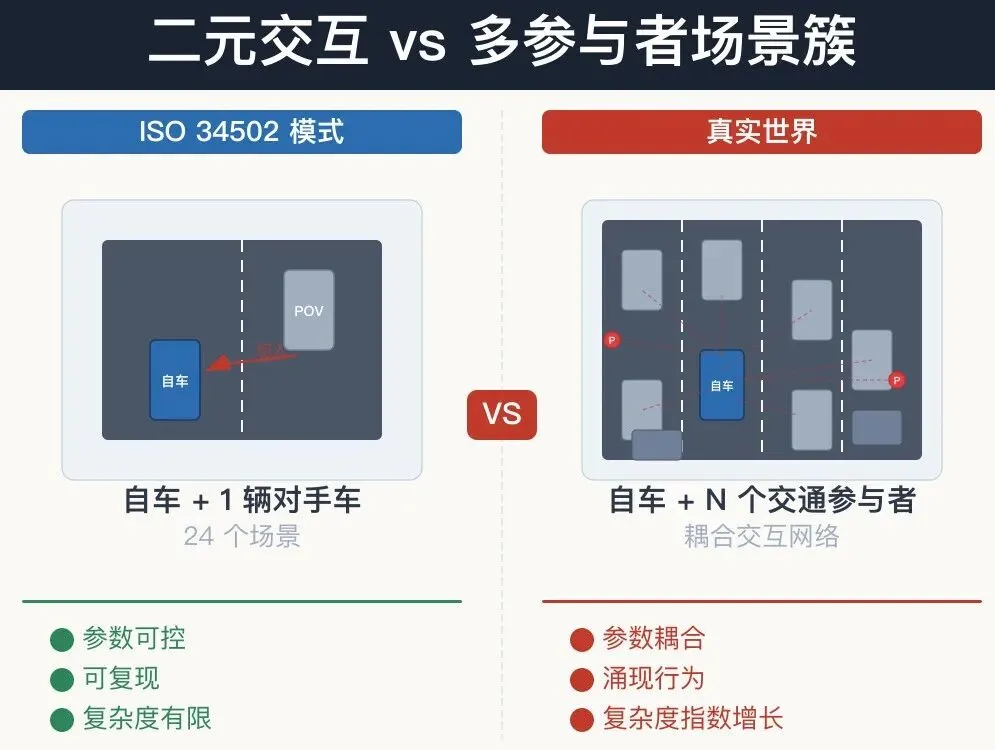 图5 二元交互 vs 多参与者场景簇
图5 二元交互 vs 多参与者场景簇2.5 覆盖幻觉:数量不等于安全
这是最深刻也是最少被讨论的挑战。
场景枚举本质上是在连续状态空间中采样离散点。即使你生成了100万个场景并全部通过,仍然无法排除在第100万零1个场景中出现致命故障。
更关键的是,安全违规往往发生在参数空间的结构化边界附近——而这些边界恰恰是标准场景容易遗漏的区域。
"生成了足够多场景"并不等同于"系统足够安全"。这不是场景方法本身的错,而是场景方法的能力边界。
三、场景方法仍有效——但需要补充
3.1 为什么不能放弃场景方法
以上五个挑战并不意味着场景方法过时了。恰恰相反,场景方法提供了其他方法无法替代的价值:
第一,结构化的需求定义。 ISO 34502的三层场景模型提供了从"模糊的安全需求"到"可测试的具体用例"的系统化路径。无论系统架构是模块化还是端到端,需求定义都需要这个结构。
第二,可操作的测试设计。 58个交通干扰模式 + 传感器干扰模型,为仿真测试和实车测试提供了清晰的起点。完全抛弃场景方法,测试工程师将无从下手。
第三,法规和标准的基石。 UN R157(全球首个L3法规)、中国L2强标和ADS强标、ISO 21448 SOTIF——这些正在实施或即将实施的法规,全部建立在场景方法之上。短期内不可能推翻。
第四,可追溯的安全论证。 场景方法的每一个测试用例都可以追溯到一个具体的安全需求和一个物理原理。这种可追溯性是监管机构日益要求的。
所以正确的问题不是"场景方法还要不要",而是"还需要补充什么"。
3.2 大规模自然驾驶数据的价值
答案指向一个方向:来自真实世界的大规模自然驾驶数据。
这类数据的价值在于它不是被"设计"出来的场景,而是真实交通环境中自然发生的一切——包括那些你想不到、标准没有定义、但确实存在的交互模式。
具体来说,大规模自然驾驶数据可以在三个层面补充场景方法:
层面一:全面覆盖所有典型场景的真实参数分布。
ISO 34502定义了24个高速交通干扰场景,SAKURA V4.0扩展到58个车辆交通模式和8个VRU模式。每一个场景都有明确的参数化定义——Cut-in场景的切入角度、相对速度、横向距离;跟车场景的TTC、THW;合流场景的汇入角度、间距等。
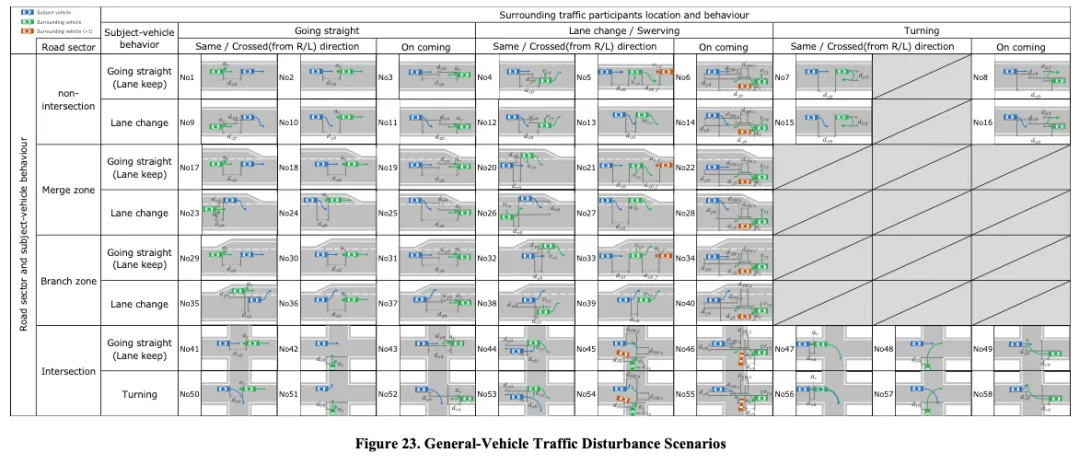 图6 SAKURA典型场景定义
图6 SAKURA典型场景定义但标准定义了参数,没有给出参数在中国道路上的真实分布。
这不是一个学术问题,而是直接影响OEM和Tier1日常工作的实际问题:
需求定义阶段:你在定义智能驾驶功能的ODD和性能指标时,Cut-in场景中"合理可预见的"最大切入速度差是多少?TTC的5th percentile是多少秒?这些数字直接决定了你的功能规格书里的量化指标。用日本的数据写中国产品的需求,等于拿东京的交通流标定长春的参数。
测试设计阶段:你在设计仿真测试矩阵时,场景参数的取值范围应该设多宽?如果参数范围设得太窄,遗漏了真实世界的极端案例;设得太宽,大量测试资源浪费在不切实际的组合上。真实分布数据可以帮你精准划定测试边界,显著提高测试效率。
安全论证阶段:SAKURA框架中"合理可预见性"是最关键的判据之一——你需要论证"这个参数范围覆盖了真实世界中X%的情况"。没有本土化的参数分布数据,这个X%无从计算。
大规模航测自然驾驶数据的价值恰恰在这里:它可以全面覆盖地提取ISO 34502和SAKURA V4.0中定义的所有典型场景类型——从高速的Cut-in/Cut-out/减速/合流/分流,到城市的交叉口冲突/VRU交互/遮挡场景——并针对中国目标市场,给出每一类场景的真实参数分布。
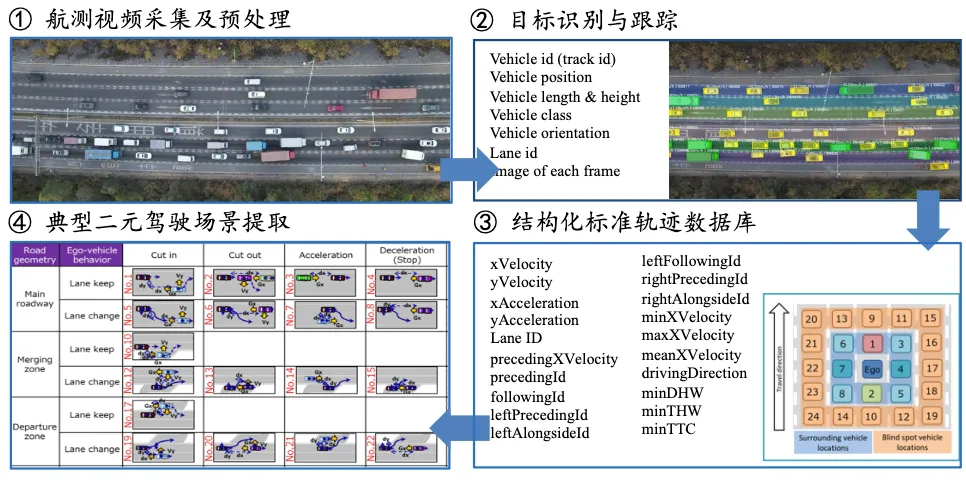 图7 从航测数据提取典型场景的过程
图7 从航测数据提取典型场景的过程
已有研究表明,中国驾驶员在Cut-in场景中的行为参数与欧洲和日本驾驶员存在显著差异。直接复用SAKURA基于日本数据标定的参数,对中国市场的产品既不准确,也不安全。
对OEM和Tier1来说,这意味着:在智能驾驶需求定义时有据可依的量化指标,在测试验证时有真实边界的效率保障,在安全论证时有本土化的统计支撑。
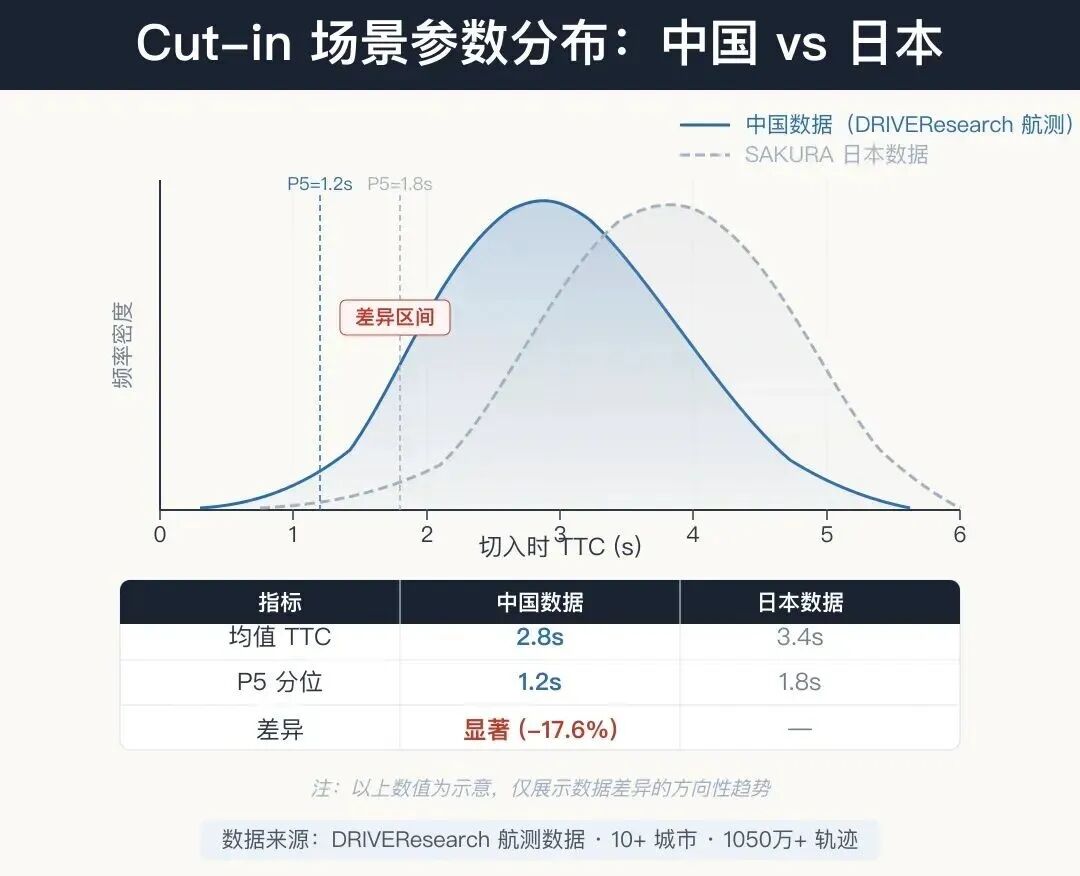 图8 场景参数分布对比(中国 vs 日本数据)
图8 场景参数分布对比(中国 vs 日本数据)层面二:超越二元交互的多参与者场景。
传统的传感器视角(车载摄像头/雷达/LiDAR)有一个天然局限:只能观测到本车传感器范围内的交通参与者。被遮挡的行人、远处正在博弈变道的车辆、本车视野之外但即将进入交互范围的车辆——都是盲区。
基于无人机航测的"上帝视角"自然驾驶数据集,可以同时观测整个交通流中的所有参与者。这带来了一个关键能力:
提取"多交通参与者场景簇"——不是孤立的二元交互,而是同一时空中所有参与者形成的耦合交互网络。
例如,当你从"上帝视角"观测一个高速合流区,你看到的不是"一辆车切入另一辆车",而是"五辆车在30秒内完成了一系列相互关联的加减速、变道和让行博弈"。这才是端到端系统实际面对的真实输入。
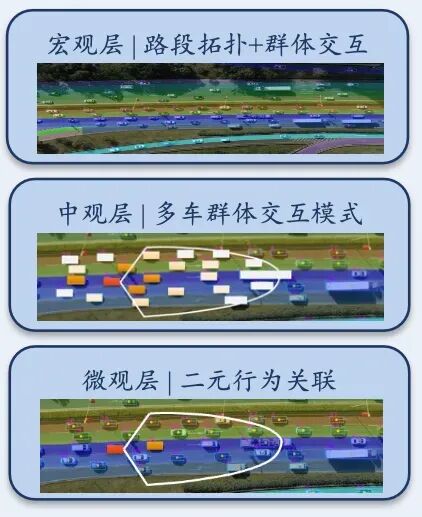 图9 从航测数据高效提取多车群体交互行为
图9 从航测数据高效提取多车群体交互行为层面三:驾驶员基础模型(DFM)的数据基础。
SAKURA的C&C Driver模型用"反应延迟0.75秒 + 最大减速度0.774G"来定义安全基准。这是一个确定性的二值模型:达到就Pass,达不到就Fail。
但基于1050万+条真实驾驶轨迹构建的驾驶员基础模型(DFM),可以提供概率化的多维度行为基准:在某个特定场景下,排名前5%的驾驶员的安全裕度分布是什么、效率分布是什么、舒适性分布是什么。
这不是用数据替代标准,而是为标准提供更坚实的数据基础。
3.3 航测数据的独特优势
为什么强调航测(无人机)数据?因为它解决了车载传感器数据无法解决的核心问题:
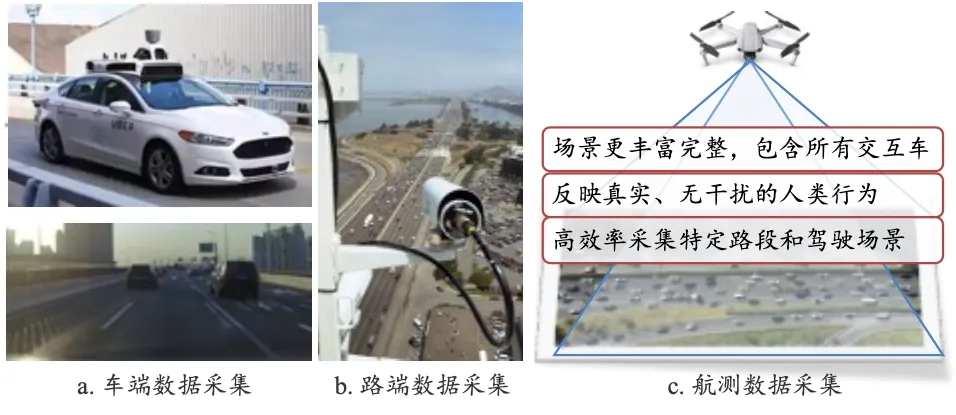 图10 不同的数据采集方式
图10 不同的数据采集方式最后一点特别关键:当你观测到一个场景中所有10辆车的完整轨迹时,其中任何一辆车都可以被设定为"本车",而其余9辆车就构成了它的交互环境。 一次采集,就获得了10个视角的场景数据。这对于端到端系统的训练和测试来说,数据效率是车载方案的N倍。
四、未来的方向:三层方法协同
我认为E2E时代的自动驾驶安全评价,需要三层方法协同工作:
第一层:结构化场景测试(ISO 34502 / SAKURA)。继续发挥其在需求定义、测试结构化和法规合规中的核心作用。物理原理方法提供的场景分类体系不会过时。
第二层:数据驱动的行为基准。用大规模自然驾驶数据,为场景参数提供真实分布,为安全判据提供概率化基准,弥补确定性模型的局限。这里的关键是:数据必须覆盖目标市场的ODD,而不是直接套用他国数据。
 图11 典型通勤场景驾驶循环
图11 典型通勤场景驾驶循环第三层:形式化方法的结构性保障。形式化验证和可达性分析回答的是"无论什么场景,什么不能发生"。它不依赖场景枚举,而是在结构层面提供安全保证。在E2E系统的不确定性面前,这一层尤为重要。
三层各有所长、各有所限。场景方法提供可操作的测试框架,数据方法提供真实世界的统计基准,形式化方法提供结构性的安全保证。
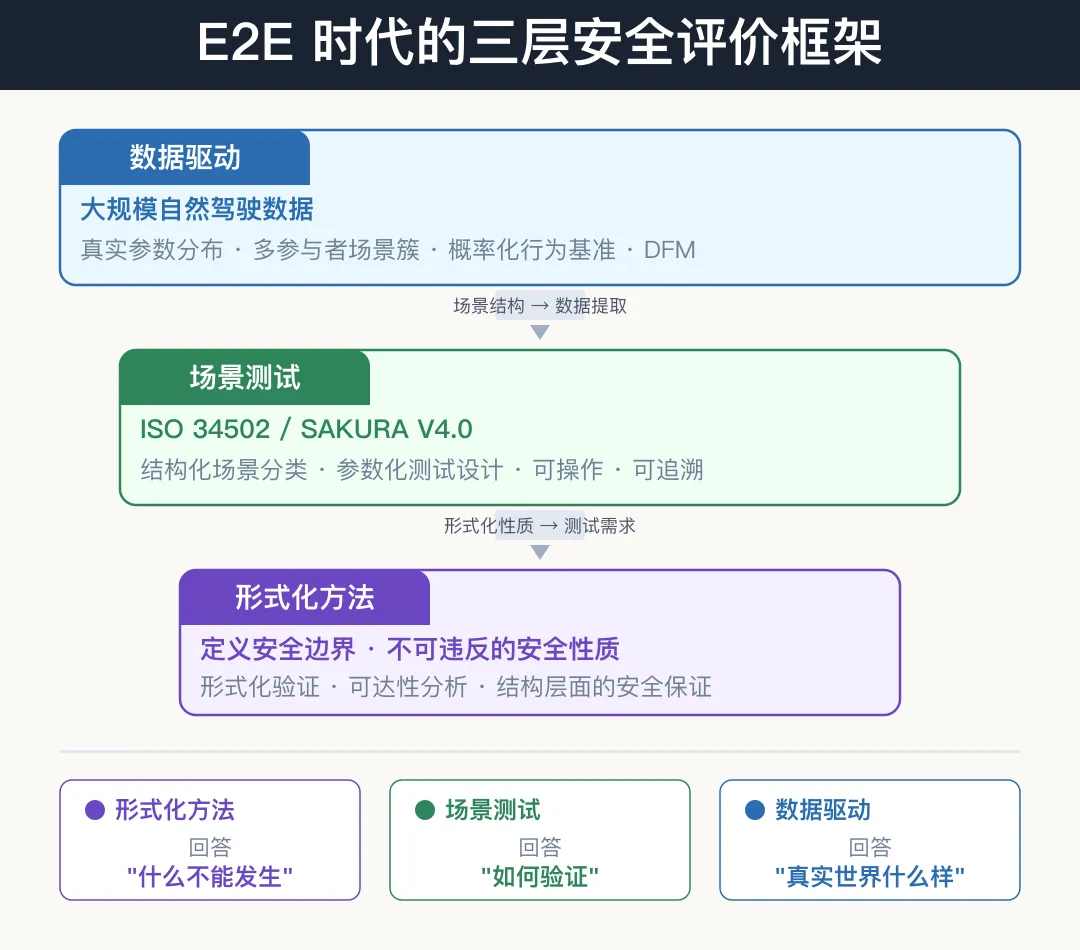 图13 三层方法协同框架
图13 三层方法协同框架在这个框架下,场景不再是安全性的独立"证据",而是"证人"——通过的场景见证了与安全性质的一致性,失败的场景见证了反例的存在。
五、总结
回到标题的问题:端到端时代,基于场景的安全评价还有效吗?
有效,但不够了。
ISO 34502和SAKURA V4.0构建了当前最严谨的场景驱动安全评价体系。它们的方法论——物理原理方法、三层场景抽象、系统性干扰识别——在E2E时代依然有效,且不可替代。
但端到端架构带来了模块边界消失、因果链断裂、行为不确定性、多参与者复杂交互等结构性挑战,场景方法需要大规模真实世界数据的补充。
特别是,基于航测的"上帝视角"自然驾驶数据集,凭借无遮挡的全场景观测能力,可以提取ISO 34502框架内的所有典型场景参数分布,更能突破二元交互的局限,捕捉真实世界中多交通参与者的耦合交互模式。
这种从"设计场景"到"发现场景"的转变,可能是E2E时代安全评价方法论演进的关键一步。
📌 投票
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
